

Agile Data Warehouse Design: What To Know?

Agile data warehouse design has emerged as a response to the growing complexity and pace of modern data environments. Organizations today must integrate diverse data sources, support real-time analytics, and adapt quickly to shifting business priorities. Traditional, rigid approaches to data warehousing struggle to meet these demands, often resulting in delayed delivery and systems that no longer reflect current needs. Agile principles offer a more flexible and responsive alternative.
By applying iterative development, continuous feedback, and close collaboration, agile data warehousing enables teams to deliver value incrementally. Rather than committing to a fixed design upfront, organizations can evolve their data platforms alongside business requirements. This article explores the core concepts, architecture, modeling techniques, and benefits of agile data warehouse design, highlighting how it supports scalable, adaptable, and insight-driven decision-making.
What Is Agile Data Warehouse Design?
Agile data warehouse design is an approach that applies agile software development principles to the creation and evolution of data warehouse systems. Instead of building a large, monolithic data warehouse upfront, teams deliver value incrementally through short iterations. Each iteration focuses on a specific business requirement, ensuring that the system evolves in alignment with real-world use cases rather than speculative design assumptions.

At its core, agile data warehousing emphasizes adaptability, collaboration, and continuous feedback. Business stakeholders, data engineers, and analysts work closely together, refining requirements as they gain insights from delivered data products. This approach contrasts with traditional methods that rely heavily on upfront planning and rigid schemas, often leading to delays and misalignment with business needs.
Another defining characteristic is iterative modeling. Data models are not treated as fixed artifacts but as evolving structures that can be adjusted as new data sources and requirements emerge. This allows organizations to respond quickly to changes in market conditions, customer behavior, or internal strategy, making the data warehouse a living system rather than a static repository.
Why Traditional Data Warehousing Falls Short
Traditional data warehousing methodologies, often rooted in waterfall development, assume that requirements can be fully defined at the beginning of a project. In reality, business needs are dynamic and frequently change during development. This mismatch leads to systems that are outdated by the time they are delivered, forcing organizations to either accept suboptimal solutions or invest heavily in rework.
Another limitation lies in the long delivery cycles. Traditional data warehouse projects can take months or even years before producing usable outputs. During this time, stakeholders have little visibility into progress, and feedback loops are minimal. As a result, errors in design or misunderstandings of requirements often go unnoticed until late stages, where they are costly to fix.
Scalability and flexibility also become challenges. Legacy architectures were not designed to handle the volume, variety, and velocity of modern data. With the rise of streaming data, unstructured sources, and real-time analytics, traditional systems struggle to keep up. They often require significant redesign or augmentation, which further increases complexity and maintenance overhead.
Finally, traditional approaches tend to create tight coupling between data ingestion, transformation, and storage layers. This rigidity makes it difficult to introduce new tools, integrate additional data sources, or adapt to evolving analytical requirements. In contrast, agile methodologies encourage modularity and loose coupling, enabling more sustainable growth over time.
Agile Data Warehouse Architecture
Agile data warehouse architecture is built around modular components that can be independently developed, deployed, and scaled. In contrast, traditional data warehouse architectures typically rely on tightly integrated pipelines, where ingestion, transformation, and storage are closely coupled into a single system. In traditional systems, a change in one part, such as modifying a schema or updating a transformation tool, often requires coordinated updates across multiple layers, increasing maintenance complexity and slowing delivery cycles.
Agile architectures address this by enforcing loose coupling between layers. Each layer, ingestion, storage, transformation, and serving, performs a distinct function and communicates through stable interfaces or data contracts. This design allows teams to replace tools, evolve schemas, or modify processing logic within a single layer without disrupting the rest of the platform. For example, a new data ingestion tool can be introduced, or a transformation schema adjusted, without requiring downstream changes in storage or serving layers.
Specifically:
- Ingestion Layer: Collects raw data from operational systems or external sources. In agile systems, ingestion can be updated or swapped independently. In traditional systems, ingestion changes often cascade through the ETL pipeline.
- Storage Layer: Preserves raw or lightly processed data. Agile architectures maintain raw data separately, enabling downstream transformations to evolve incrementally; traditional warehouses tightly couple storage with transformation, making changes riskier.
- Transformation Layer: Applies business logic to create curated datasets. Agile systems can evolve transformations without touching ingestion or storage, while in traditional systems, schema or transformation changes often require end-to-end adjustments.
- Serving Layer: Exposes data for analytics, dashboards, or AI. In agile architectures, this layer can adapt to new data models without upstream modifications.
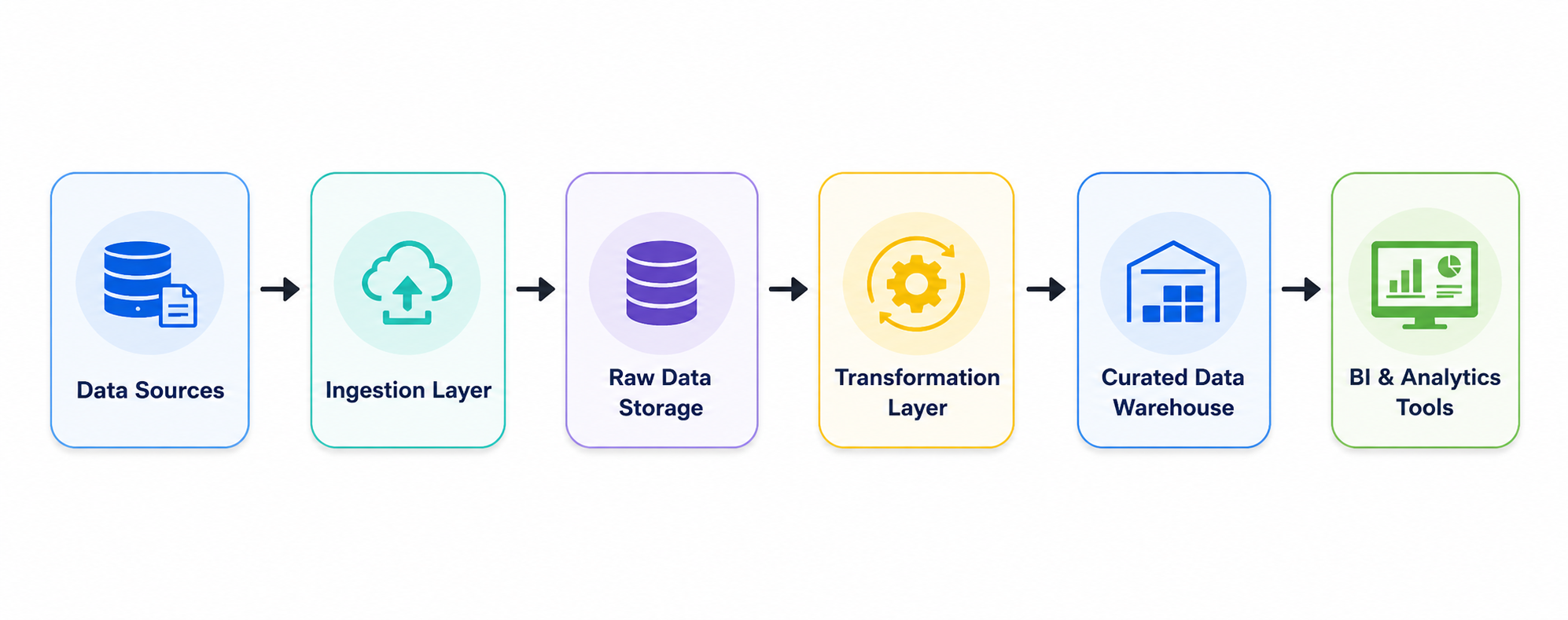
By decoupling components and maintaining modular boundaries, agile data warehouses achieve faster iteration, reduced system-wide dependencies, and incremental evolution over time, capabilities that traditional tightly coupled architectures struggle to provide.
Data Modeling in Agile Environments
Data modeling in agile environments shifts away from rigid, upfront schema design toward a more iterative and adaptable approach. Instead of attempting to model the entire enterprise data landscape in advance, teams focus on building models that address immediate business requirements and refine them incrementally over time. This evolutionary approach allows the data warehouse to adapt continuously as new data sources, metrics, and analytical needs emerge.
One widely used technique is dimensional modeling, which organizes analytical data into fact tables and dimension tables. Fact tables store measurable business events, such as sales transactions or user activity, while dimension tables provide descriptive context such as customer, product, or time information. This structure is optimized for reporting and business intelligence because it simplifies analytical queries, improves query execution efficiency, and enhances readability for downstream users.

In agile environments, dimensional models are often developed incrementally rather than designed as a complete enterprise-wide schema upfront. Teams may initially create a small star schema to support a specific dashboard or business question, then gradually extend the model as new requirements emerge. This allows organizations to deliver analytical value quickly while avoiding excessive upfront modeling effort.
Another modeling approach commonly used in agile systems is data vault modeling. Unlike dimensional models, which focus primarily on analytics and reporting, data vault modeling is designed to support scalability, flexibility, and long-term schema evolution. A data vault separates data into three core structures: hubs, which represent core business entities; links, which capture relationships between entities; and satellites, which store descriptive attributes and historical changes.
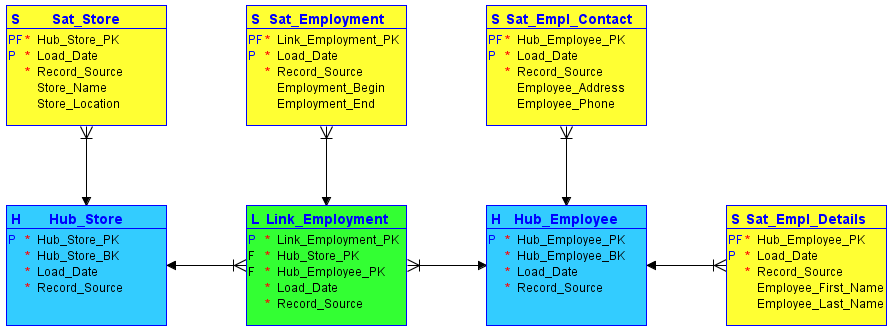
This separation makes the model highly adaptable to change. New data sources or attributes can often be added by introducing additional satellites or links without modifying existing structures. As a result, data vault models reduce the impact of schema evolution and minimize disruptions to downstream systems. This characteristic makes them particularly suitable for agile environments where requirements and source systems evolve continuously.
Beyond specific modeling techniques, agile data warehousing also emphasizes how models evolve over time. A key principle is schema evolution, where data models are treated as continuously evolving structures rather than fixed designs defined at the start of a project. Modern cloud-native platforms increasingly support flexible schemas and incremental transformations, allowing teams to introduce new attributes, relationships, or data sources without requiring full system redesigns. This enables organizations to adapt quickly to changing business requirements while reducing long-term technical debt.
Agile modeling also depends heavily on collaboration and continuous feedback. Because requirements often change during development, data engineers, analysts, and business stakeholders work together iteratively to refine models based on real analytical needs. Regular feedback loops ensure that the data warehouse remains aligned with evolving business objectives and continues to deliver meaningful insights as the system grows
Modern Data Stack and Agile Warehousing
The modern data stack extends agile data warehousing by operationalizing two key capabilities: cloud-native infrastructure and CI/CD-driven delivery practices, both of which enable continuous and controlled evolution of data systems in production environments.
Cloud-native technologies provide the foundational environment for faster and more flexible system evolution. Cloud-native platforms offer elastic scalability, managed services, and automated operations, allowing teams to provision and adjust resources on demand with minimal overhead. This significantly reduces the cost and risk of change, making it practical to iterate in small increments and deliver updates continuously. As a result, cloud-native architectures directly support agile principles by enabling rapid experimentation, continuous delivery, and efficient adaptation to changing business needs.
In addition to infrastructure flexibility, the modern data stack emphasizes observability, automation, and continuous delivery through CI/CD practices. Because data pipelines, transformation logic, and analytical requirements change frequently, teams rely on automated testing, deployment, and monitoring to manage these changes safely and efficiently. Each incremental update is validated before release, ensuring early detection of issues and reducing the risk of breaking downstream analytics. Continuous observability further strengthens this process by providing real-time feedback on system behavior, data quality, and pipeline execution after each deployment. This iterative operational model helps ensure that the data platform can evolve alongside changing analytical and business needs.
Together, cloud-native infrastructure and CI/CD practices transform data platforms into continuously evolving systems rather than periodically updated ones. Instead of relying on large, infrequent redesign cycles, changes are delivered in small, controlled increments with fast feedback loops. This iterative operational model ensures that the data platform can evolve in step with changing analytical and business needs, while maintaining reliability, stability, and delivery speed at scale.
Benefits of Agile Data Warehousing
Agile data warehousing offers several advantages that make it well-suited for modern data-driven organizations. One of the most significant benefits is faster time to value. By delivering data products incrementally, teams can provide insights to stakeholders much sooner than with traditional approaches.
Another major benefit is the ability to adapt continuously to changing business and data requirements. Through iterative development, close collaboration, and regular feedback loops, agile data warehouses evolve alongside organizational needs rather than relying on assumptions made at the beginning of a project. This reduces the risk of delivering outdated or low-value solutions while allowing teams to respond quickly to new data sources, analytical demands, and shifting business priorities.
Agile methodologies also enhance quality and reliability. Automated testing, monitoring, and deployment processes help ensure that data pipelines are robust and maintainable. Issues can be identified and resolved, minimizing disruptions to business operations.
Finally, cloud-native technologies provide the operational foundation that makes agile data warehouse architectures practical at scale. By offering elastic scalability, managed services, and automation, they reduce the overhead of infrastructure management and enable teams to iterate and deploy changes more frequently. This directly supports continuous delivery and the incremental evolution of data systems, strengthening the overall agility and responsiveness of the data warehouse.
Ontology and Ontology Enforcement in Agile Data Warehousing
Agile approaches are highly effective at supporting scalable analytics and rapid data delivery. However, the underlying analytical queries are often still built on complex schemas, joins, and business-specific logic that do not naturally reflect business semantics. This creates a growing need for an ontology layer that defines business entities, relationships, and meaning in a more natural and consistent way across the data warehouse.
Ontology: Bridging Data and Meaning
An ontology provides a formal, semantic representation of the business domain. It sits above physical data models and abstracts technical schemas into meaningful entities and relationships.
In an agile data warehouse context, ontology plays a crucial role by:
- Mapping raw tables and fields into business concepts such as Customer, Order, Product, or Revenue
- Defining relationships between entities (e.g., “Customer places Order” or “Order contains Product”)
- Creating a shared vocabulary across teams, tools, and data products
Unlike static schema definitions, ontology aligns naturally with agile principles. It evolves incrementally as new data sources and business requirements emerge, ensuring that semantic meaning keeps pace with system changes.
Importantly, ontology also helps reduce semantic hallucination in both human and AI-generated queries. By explicitly defining valid entities and relationships, it narrows the space of possible interpretations and prevents logically invalid assumptions about how data connects.
Ontology Enforcement: Ensuring Consistency at Scale
While ontology defines meaning, ontology enforcement ensures that this meaning is consistently applied.
In a decoupled, cloud-native architecture, where data lakes, warehouses, and multiple compute engines coexist, different users or tools may interpret the same data differently. This leads to semantic drift, where inconsistent joins, metrics, or assumptions produce conflicting insights.
Ontology enforcement introduces a validation layer at query time:
- Queries are checked against the ontology before execution
- Relationships must conform to defined semantic rules
- Invalid or ambiguous logic is rejected or corrected
This acts as a semantic guardrail, ensuring that all queries, whether written by analysts or generated by AI, are not only syntactically correct but also logically valid.
Supporting Agile Iteration and AI-Driven Workflows
Ontology enforcement is particularly valuable in agile environments where rapid iteration can otherwise introduce inconsistencies. As new datasets and models are added incrementally, the ontology acts as a stabilizing layer that maintains coherence without slowing down development.
It also plays a critical role in enabling AI-assisted analytics. In modern data stacks, AI agents increasingly generate queries or explore datasets autonomously. Without semantic guidance, these agents often produce results that are syntactically correct but semantically wrong, a common form of semantic hallucination.
Ontology enforcement addresses this by:
- Preventing invalid joins or relationships
- Providing structured, human- and machine-readable feedback when queries fail, and enabling a feedback loop for self-correction
- The feedback signal can be further used for fine-tuning or reinforcement learning
This transforms error handling from opaque system messages into actionable semantic guidance, improving both usability and system intelligence.
AI-Assisted Data Access on Top of Ontology
Building on this foundation, ontology and enforcement also enable a more intuitive way to interact with data. Instead of requiring users to understand complex schemas and join logic, modern systems increasingly provide AI-driven interfaces for data access.
Systems such as PuppyGraph demonstrate this pattern by combining ontology enforcement with a built-in AI assistant that translates natural language into semantically valid queries. Grounded in the ontology, the assistant can interpret user intent, generate correct query logic, and return consistent results.
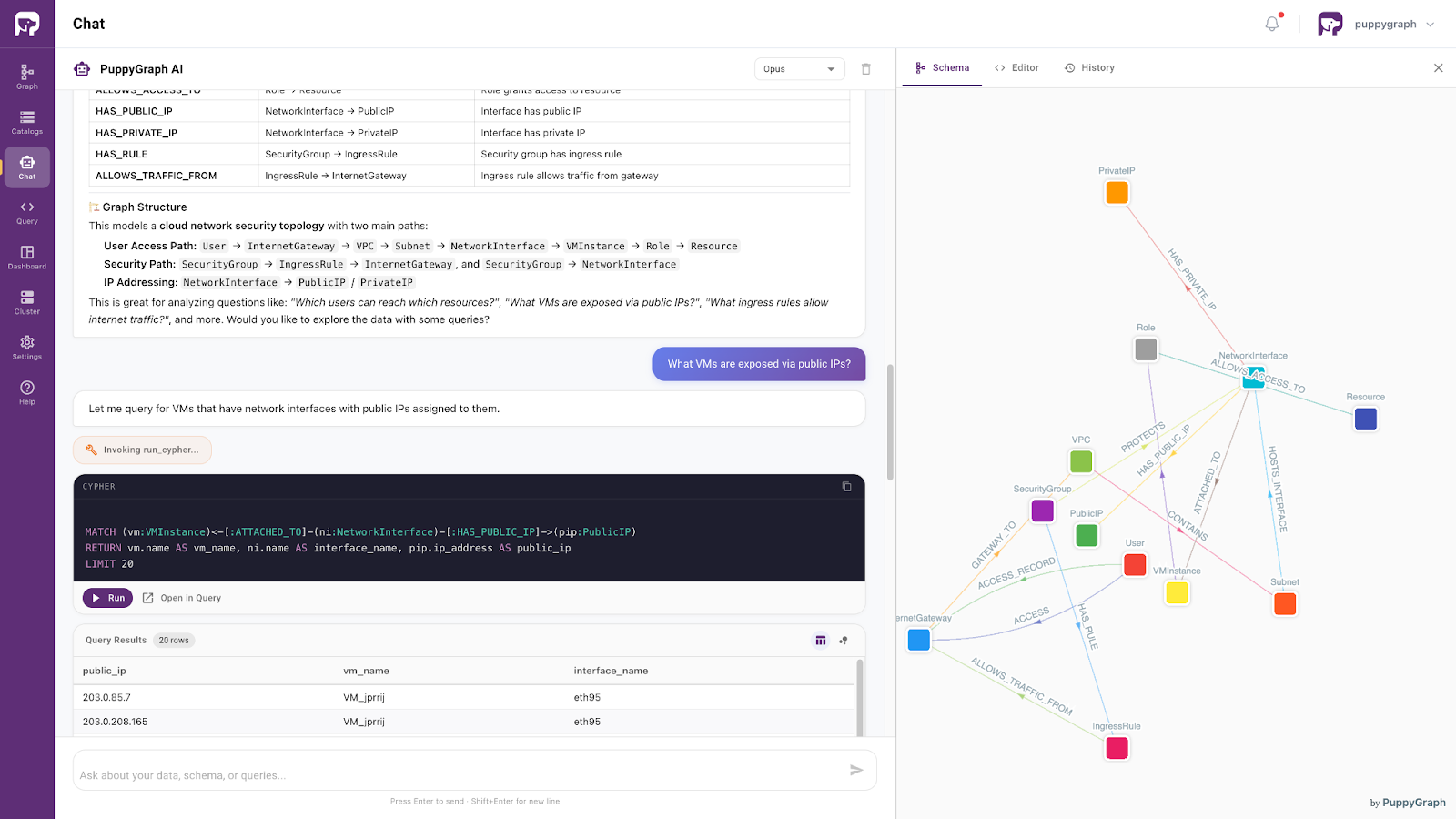
As a result, the data warehouse evolves from a technical system into an interactive layer: one that preserves semantic consistency while making data access more accessible to both technical and non-technical users.
Conclusion
Agile data warehouse design provides a practical response to the limitations of traditional data warehousing in modern, fast-changing data environments. By emphasizing iterative development, modular architecture, flexible data modeling, and continuous feedback, it enables organizations to deliver analytical value faster while adapting continuously to new business and technical requirements. Combined with cloud-native infrastructure and CI/CD practices, agile data warehouses become scalable, resilient, and continuously evolving systems.
As data ecosystems grow more complex, agility alone is not enough. Semantic consistency also becomes essential. Ontology and ontology enforcement extend agile principles by ensuring that rapidly evolving data systems remain logically coherent and aligned with business meaning. Together, agile architecture, modern data platforms, and semantic governance create a stronger foundation for reliable analytics, AI-assisted data access, and long-term data-driven decision-making.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see how ontology and ontology enforcement bring semantic consistency and agility to your modern data warehouse.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install