

Top 4 Cassandra Alternatives of 2026

Top 4 Cassandra Alternatives of 2026
Apache Cassandra cemented its position as a go-to distributed NoSQL database for handling massive datasets with remarkable availability. For years, its masterless architecture and linear scalability represented the pinnacle of distributed systems for companies like Netflix and Apple. This widespread adoption established Cassandra as the default choice for services demanding constant uptime and massive write throughput.
However, the very design that gives Cassandra its strength also introduces significant operational friction. Its complex data modeling, challenging repair and maintenance processes, and limited query flexibility create substantial overhead. Modern apps, in addition to raw storage, increasingly demand real-time analytics, flexible queries, and lower operational complexity.
As a result, we have observed the development of a new wave of specialized databases. These alternatives aim to provide the high availability and scale of Cassandra while addressing its core limitations. This article explores the top four Cassandra alternatives of 2026, each offering a unique synthesis of features designed to meet the evolving demands of modern data infrastructure.
What is Cassandra?
Apache Cassandra is an open-source, wide-column NoSQL database engineered for scalability and high availability across multiple commodity servers and cloud infrastructure. Though initially developed at Facebook, it was later open-sourced.
Unlike relational databases,Cassandra doesn't enforce a rigid schema, making it highly adaptable for applications with evolving data structures. This flexibility in combination with its robust architecture has made it a popular choice for companies like Netflix, X (formerly Twitter), and Apple for their mission-critical services.
Cassandra uses a ring architecture for clusters. All nodes in a Cassandra cluster are equal, communicating with each other through a peer-to-peer gossip protocol. This decentralization eliminates single points of failure; if one node goes down, others can seamlessly take over its responsibilities. This design also gives Cassandra exceptional fault tolerance and continuous availability.
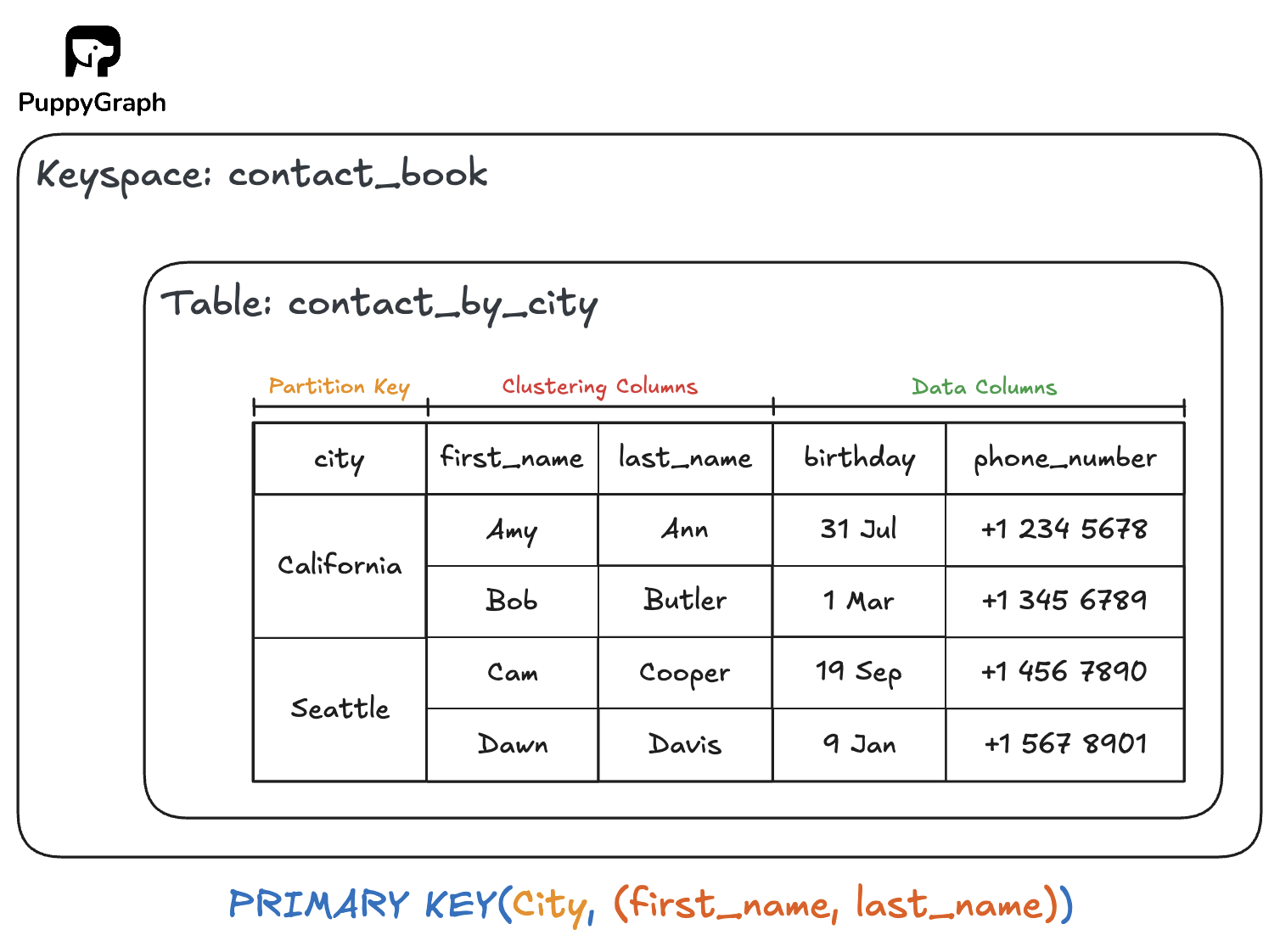
Data in Cassandra is organized into keyspaces; you can think of them as schemas in a relational database. Here’s how it works:
- Within a keyspace, data is stored in tables.
- Each row in a table is uniquely identified by a primary key.
- Each primary key has one or more partition keys.
And on this partition key, Cassandra applies a consistent hashing algorithm, to determine which node in the ring is responsible for that piece of data. This allows an even distribution of data across the cluster, and consequently, its linear scalability. Doubling the nodes can double the throughput.
To ensure data durability and availability, Cassandra employs a replication strategy. You define a replication factor: the number of copies of your data you want stored on different nodes across the cluster. When a write request comes in, the designated coordinator node sends the write to all replicas. This replication builds the foundation of Cassandra's fault tolerance.
Cassandra also offers tunable consistency. For any read or write operation, you can specify the consistency level: the number of replica nodes that must acknowledge the operation before it's considered successful. This allows for a flexible trade-off between consistency and performance based on the specific needs of your application.
However, Cassandra also poses significant architectural constraints, most notably its query-first data model. In SQL databases, you can flexibly query data after it's stored, whereas Cassandra demands that you design your database schema around the specific queries you intend to run. This forces a high degree of denormalization (data duplication) and makes it difficult to evolve your application or ask new questions of your data without performing costly and complex data migrations.
This design philosophy means that while Cassandra is excellent at high-throughput writes and predefined read patterns, the benefits come at a cost.
How Cassandra Works
To understand the trade-offs that lead businesses to seek alternatives, let’s discuss the core mechanics of how Cassandra handles data.
The Write Path
When a write request is sent to Cassandra, the node that receives it acts as the coordinator. The coordinator determines the write path, deciding which replica nodes should store the data and forwards the write to them. Each replica writes the data to its own on-disk commit log, which is append-only for durability, and to an in-memory structure called a memtable. Once the number of replicas specified by the consistency level have completed both actions, the coordinator acknowledges the write as successful to the client.
This process is exceptionally fast because it avoids the slow, random disk I/O associated with updating data in place. However, the memtable has a finite size. When it becomes full, Cassandra flushes its entire sorted contents to a new, immutable file on disk called an SSTable (Sorted String Table). This design is the foundation of Cassandra's high write throughput. But it also means that a single piece of data can end up scattered across multiple SSTable files as it's updated over time. Cassandra addresses this through compaction, which merges SSTables and removes outdated or deleted data.
The Read Path
The read path is more complex because Cassandra is optimized for writes. To fulfill a read request, the coordinator must find the correct data by checking several sources. It first looks in the memtable for the most recent writes. Then, it uses data structures such as bloom filters to quickly determine whether an SSTable might contain the requested data, before potentially accessing multiple SSTables on disk.
Because updates can leave multiple versions of a row across different SSTables, the compaction strategy has a direct impact on read performance. Each strategy determines how often SSTables are merged, which in turn affects how much data Cassandra must read and reconcile during a query. If compaction is not frequent enough for the workload, Cassandra may need to read from several SSTables and merge the results in memory. When merging, Cassandra resolves conflicts by keeping the version with the most recent timestamp.
Background Processes: Gossip and Compaction
Two critical background processes keep a Cassandra cluster functioning: gossip and compaction. The gossip protocol is a peer-to-peer communication mechanism where nodes constantly exchange information about their own state and the state of other nodes they know about. This is how the masterless cluster maintains a unified view of node availability and health without a central authority. Gossip messages are relatively lightweight, and the predictable, low-volume background traffic they generate is negligible compared to application data traffic, so it rarely impacts performance.
Compaction addresses the sprawl of SSTables created by the write path. It runs in the background, merging related SSTables and reclaiming space from updated or deleted data. While necessary for maintaining read performance and managing disk space, compaction is a resource-intensive operation. It consumes significant disk I/O and CPU, and if you don’t tune correctly, it can severely degrade the performance of the entire cluster.
Why Explore Cassandra Alternatives
The decision to look beyond Cassandra arises from the cumulative weight of its operational burdens and development constraints, which directly impact budgets, timelines, and a company's ability to innovate. Let’s discuss some of these aspects.
The High Cost of Operational Complexity
It might seem that you need specialized expertise to manage a Cassandra cluster for its continuous, resource-intestive nature. A primary driver of this complexity is the manual anti-entropy repair process. To maintain data consistency, operators must regularly execute nodetool repair on every node. If you don’t complete this process within the grace period of the tombstone, deleted rows can reappear on some nodes after tombstones are removed, resulting in silent data corruption. The maintenance also consumes significant I/O and CPU, so teams must schedule it carefully during off-peak hours to avoid degrading production performance.
Then consider the compaction strategy operators must choose and tune, a choice with permanent performance implications. The default SizeTiered Compaction Strategy (STCS) is optimized for write throughput but can significantly increase read latency and lead to high space amplification. The alternative, Leveled Compaction Strategy (LCS), improves read performance but at the cost of much higher I/O on writes. For the best decision, you need an upfront understanding of a workload's characteristics. A wrong choice can severely handicap cluster efficiency, inflating the total cost of ownership through engineering overhead and infrastructure spend.
Inflexible Querying
Cassandra's rigid, query-first data model poses the most significant architectural drawback for many. The Cassandra Query Language (CQL) mimics SQL syntax but lacks its most powerful features. You don’t have server-side JOIN operations, as performing JOINs across distributed nodes is computationally infeasible. Consequently, teams have to handle data relationships either in the application layer, which is inefficient, or through extensive denormalization. Denormalizing data means duplicating it across multiple tables, which dramatically increases storage costs and write amplification.
This lack of flexibility directly inhibits business agility. When product requirements change, engineering teams cannot simply write a new query to access data in a new way. They must often provision a new table and execute a complex, slow data migration to structure the data for that specific query. This friction makes it nearly impossible to support ad-hoc analytical queries. You must invest in separate, complex ETL pipelines to move data into a proper data warehouse simply to generate business insights.
The Performance Cost of Deletes and Updates
When a row is deleted or updated, Cassandra does not remove the old data. Instead, it inserts a deletion marker called a tombstone. During a read request, the database must scan and process these tombstones in memory just to determine what data to exclude in the result set. A query that scans a data partition containing thousands of tombstones can consume excessive CPU and memory, resulting in high read latencies or even query failures.
The compaction process eventually evicts tombstones. However, workloads with frequent updates or deletes can generate them far faster than compaction can clean them up. This creates unpredictable performance degradation that is difficult to diagnose and resolve.
Top 4 Cassandra Alternatives of 2026
The best alternatives offer Cassandra's scale and uptime without its operational burden and query restrictions. The following alternatives each present a unique approach to solving those challenges.
MongoDB

MongoDB is a document-oriented database built for speed and flexibility. Its JSON-like document model, stored as BSON, allows related data to be embedded in a single document, reducing the need for joins and improving read efficiency. Cassandra’s wide-column model also supports schema flexibility, but its design is typically driven by predefined queries and partitioning. MongoDB’s approach works well when record structures change often, since each document can have its own fields without affecting others.
Both MongoDB and Cassandra support replication for high availability and sharding for scale. Cassandra is often stronger in write-heavy workloads at large scale, while MongoDB offers richer querying through indexes, aggregation pipelines, and ad hoc queries. Multi-document ACID transactions introduced in version 4.0 provide MongoDB with strong consistency when needed, making it a versatile alternative for teams that prioritize flexible data models and expressive queries.
ScyllaDB

ScyllaDB is a high-performance NoSQL database designed as a drop-in replacement for Cassandra, using the same CQL interface and wide-column data model. Built in C++ with a thread-per-core architecture, it offers significantly lower latency and higher throughput, often requiring fewer nodes to support large-scale workloads. For use cases like time-series ingestion, real-time analytics, and distributed services that demand consistent performance, ScyllaDB provides a more efficient alternative to Cassandra with minimal application changes.
To sustain that performance, ScyllaDB relies on careful schema and partition key design. While many operations are automated, background tasks such as repairs and compactions consume system resources and are best scheduled to avoid interfering with live traffic. This reflects a practical trade-off: higher performance and better hardware efficiency in exchange for some operational planning. For teams familiar with Cassandra’s model, ScyllaDB delivers greater speed and scalability without requiring a new way of thinking.
Amazon DynamoDB

Amazon DynamoDB is a fully managed NoSQL database built for predictable, low-latency performance at scale. It automatically handles replication, sharding, scaling, and backups, allowing teams to support high-throughput workloads without managing infrastructure. With a key-value and document data model, DynamoDB integrates tightly with AWS services and supports global tables for multi-region replication, automatic failover, and ACID-compliant transactions when needed.
Like Cassandra, DynamoDB is built around predefined access patterns and requires careful alignment of queries with partition and sort keys. Its query model is limited to primary keys and secondary indexes, with restrictions on filtering, joins, and more flexible querying. While Cassandra provides more control over consistency and data layout, DynamoDB offers a simpler, serverless experience for teams operating within the AWS ecosystem. It is a strong choice for applications with well-defined workloads and clear access patterns, as long as the data model is carefully planned in advance.
Google Cloud BigTable

Google Cloud Bigtable is a fully managed NoSQL database built for applications that require high write throughput, low-latency access, and the ability to scale seamlessly with data growth. It uses a wide-column data model and is especially well suited for storing time-series data, telemetry, and operational metrics. Bigtable is a strong choice for teams building analytics pipelines or machine learning systems on Google Cloud, as it integrates closely with services like BigQuery, Dataflow, and Vertex AI.
While Cassandra provides more control over consistency and replication strategies, Bigtable focuses on simplicity and reliability. It delivers strong consistency for single-row operations and supports multi-cluster replication within a region to ensure high availability. Queries are designed around efficient access by row key and range scans, which works well when access patterns are clearly defined. For teams operating in the Google Cloud ecosystem and prioritizing performance with minimal operational overhead, Bigtable offers a dependable alternative to Cassandra for high-scale, read and write-intensive workloads.
Conclusion
Choosing the right NoSQL database is a critical architectural decision that shapes how your systems scale, adapt, and support future growth. Cassandra has earned its place for large-scale deployments, but its operational complexity, rigid query patterns, and maintenance demands make it less appealing for certain workloads. The alternatives discussed here each address these challenges in different ways, whether by simplifying operations, improving performance, or offering more flexible consistency models.
No single database is perfect. The best choice depends on your workload, your team’s expertise, and the trade-offs you are willing to accept. Understanding how each option handles scale, fault tolerance, query flexibility, and operational overhead will help you make a decision that aligns with both current needs and long-term plans.
Once you choose the right database, PuppyGraph can help you go further. It is the first and only graph query engine that can connect to your existing relational and NoSQL data stores and let you explore them as a unified graph, deployed in under 10 minutes.
PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


Try the free PuppyGraph Developer Edition or book a demo to see how graph queries can uncover the hidden relationships in your data.

Jaz Ku is a Solution Architect with a background in Computer Science and an interest in technical writing. She earned her Bachelor's degree from the University of San Francisco, where she did research involving Rust’s compiler infrastructure. Jaz enjoys the challenge of explaining complex ideas in a clear and straightforward way.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install