

ClickHouse SIEM: The Ultimate Guide

Security telemetry is one of the heaviest log workloads any organization runs. A Fortune 500 environment generates tens of billions of events over a 90-day window, and the traditional SIEM platforms that grew up around this data have become economically painful at that scale. Per-GB-ingested pricing punishes verbose log sources, proprietary index formats lock data into one vendor's query engine, and the gap between hot and cold retention forces awkward tradeoffs between investigation depth and budget.
A pattern has emerged in response: build the SIEM on a columnar analytics engine, with ClickHouse as the most common choice. The pattern is mature enough now to be visible in production at security vendors, in-house security teams, and managed SIEM platforms. This post walks through how it works. It covers why ClickHouse fits the workload, what the architecture looks like, how ingestion and scaling are handled, and how a semantic layer turns raw tables into entity-based detection.
What Is ClickHouse SIEM?
A SIEM (Security Information and Event Management) system collects, normalizes, and analyzes security-relevant logs and events from across an organization, with the goal of detecting and responding to threats. The framing ClickHouse uses is a useful one: observability tools tell you what's broken through metrics, traces, and general logs, while SIEM tells you what's malicious by analyzing security data such as authentication events, network flows, audit trails, and endpoint telemetry.
"ClickHouse SIEM" is best understood as a pattern, not a product. The pattern uses ClickHouse as the storage and query engine for security telemetry, with ingestion, detection, alerting, and visualization layers built around it. The pattern shows up in two forms. Some teams build the entire stack on top of a ClickHouse cluster they operate, wiring up their own collectors, schemas, and detection rules. Others adopt managed SIEM products built on ClickHouse, which package the ingestion and detection layers and can be configured to write into a customer-owned ClickHouse cluster, preserving the customer's ownership and queryability of the underlying data. ClickHouse's own security team uses the latter model, having migrated from a fully in-house Lambda-based pipeline to RunReveal writing into their own ClickHouse Cloud service.
This article focuses on the underlying ClickHouse layer in either case, since the architectural choices, schema design, and detection patterns apply to both.
Why Use ClickHouse for SIEM Workloads?
ClickHouse's own engineering content frames SIEM around five recurring challenges: data volume, data variety and normalization, cost management, scaling, and operational complexity. ClickHouse's design happens to address each of them directly, which is why the pattern has spread.
- Volume: Security telemetry is one of the heaviest log workloads in any organization, with Fortune 500 environments generating tens of billions of events over a 90-day window. ClickHouse's columnar storage and per-column compression codecs typically deliver 10x to 100x compression ratios on log data, and the MergeTree family of table engines is purpose-built for append-heavy time-series workloads. A single node routinely handles billions of rows. Production SIEM deployments running on ClickHouse cover millions of endpoints across thousands of customer environments, which is a useful existence proof that the engine holds up at scale.
- Variety: SIEM data arrives in syslog, JSON, CEF, Windows Event XML, and a long tail of vendor-specific formats. ClickHouse's native JSON, Map, and Array types absorb semi-structured fields without schema migrations, while materialized columns extract frequently-queried fields into typed storage for fast access. Schema-on-write keeps queries efficient, but the flexibility to add fields without rewriting tables matches the reality of constantly evolving log sources.
- Cost: Open-source licensing, columnar compression, and TTL-based tiering from local SSD to S3-backed object storage drive total cost of ownership well below traditional SIEMs. Teams routinely report an order-of-magnitude reduction in storage and compute spend after migrating off Elasticsearch or commercial SIEM platforms.
- Scaling: Distributed table engines, sharding, and ReplicatedMergeTree provide horizontal scaling and high availability without a separate coordination service beyond ClickHouse Keeper. Read scaling comes from replicas, write scaling from shards, and both can be tuned independently as ingest and query loads grow.
- Complexity: A single engine handles ingest, storage, and query, which collapses the component count and failure surface compared to architectures that split hot storage, cold storage, and query engines across separate systems. Fewer moving parts means fewer integrations to maintain, fewer credentials to rotate, and fewer places for data to fall behind.
Key Features of a ClickHouse-Based SIEM
What makes the ClickHouse pattern distinct from traditional SIEM platforms, beyond raw performance, is a set of structural properties that change how a security organization operates. These are the characteristics teams notice after a few months of running on ClickHouse, the ones that come up in retros and migration write-ups.
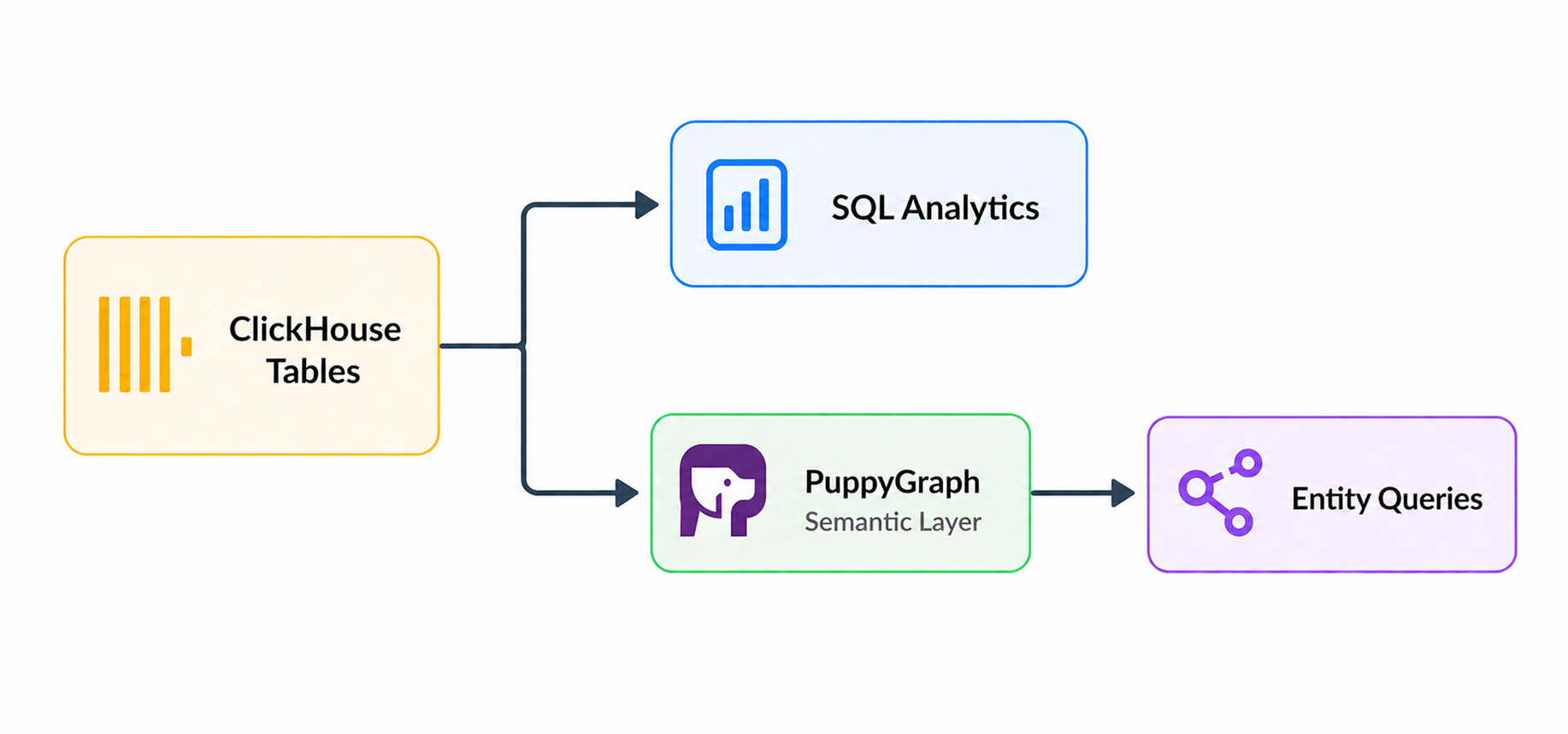
- Open engine, open data path. ClickHouse itself is open source, so the storage format is documented and inspectable rather than a vendor's black box. Teams that want open-format storage on top of that can land data in Apache Iceberg on object storage and use ClickHouse as the query engine, keeping the system of record in a format any tool can read. Either way, migrating off, sharing data with another tool, or running an external query engine against the same storage is a configuration change rather than a data export project. Traditional SIEM platforms, by contrast, treat the index as part of the product, which makes leaving expensive in both engineering time and contractual exit costs.
- SQL as the detection language. Detections are SQL queries, not Splunk SPL, Elastic KQL, or a vendor-specific rule DSL. Anyone on the security team who knows SQL can write, read, and review detection logic. Hiring is easier because the skill is generic. Migrations into and out of the platform are easier because rules can often be ported with mechanical adjustments rather than rewrites. Detection-as-code workflows fall out naturally: rules live in Git, change through pull requests, and run through CI before deployment.
- Real-time and historical in one engine. Recent events and long-term history are reachable through the same query language, whether the cold data lives in tiered MergeTree storage or in Iceberg tables that ClickHouse reads natively. There is no hot-warm-cold tier with separate query paths, no "rehydration" step to bring archived data back into a queryable state, and no awkward boundary where threat hunts that span the boundary become slow or impossible. Long-running incident investigations and live alerting use one query engine.
- Predictable cost model. Costs scale with the hardware actually used: CPU cores, local disk, and object storage. There is no per-GB-ingested or per-event pricing, which means an unexpected log spike from a misconfigured source produces an operational incident, not a billing incident. Capacity planning becomes a conversation about hardware, which security and infrastructure teams already know how to have.
- Open and extensible architecture. Because the query interface is standard SQL over JDBC and HTTP, the same ClickHouse cluster can serve workloads beyond core SIEM detections. Compliance reporting, data science notebooks, BI dashboards, and specialized analytic engines can all query the same underlying tables without ETL into a separate system. The SIEM stops being an isolated silo and becomes part of the broader data platform.
How ClickHouse SIEM Architecture Works
A ClickHouse-based SIEM organizes around five layers: data sources, collection, processing and storage, analysis and detection, and consumption. The underlying technology choices are well-trodden, but a few architectural decisions shape the rest of the system, including where the source of truth lives and how detections query the data.
Sources include endpoint logs (EDR agents), network telemetry (firewalls, VPC flow logs, NetFlow), cloud audit trails (CloudTrail, GCP audit logs, Kubernetes audit), identity providers (Okta, Active Directory), and application logs.
Collection uses lightweight collectors at the source to parse, enrich, and batch events close to where they originate, then ships them through a streaming buffer that decouples producers from ClickHouse. ClickHouse consumes from the buffer continuously. The buffer absorbs ingest spikes and lets detection rules be replayed against historical data when rules change.
Processing and storage lands data in MergeTree tables, partitioned by month and organized for time-range queries. Common fields (timestamp, source_ip, user_id, event_type) are extracted into typed columns at ingest, while the raw payload stays in a JSON or Map column for fields that have not yet been promoted. Storage tiering moves data from local SSD to S3-backed object storage as it ages, keeping years of retention affordable.
A common variant introduces Apache Iceberg on object storage as the system of record. Raw events land in Iceberg first, and ClickHouse loads from Iceberg into MergeTree as the serving layer for hot queries. The direct path is simpler and lower-latency; the lakehouse path costs an extra hop but gains an open format for long-term retention, the ability to replay history through new detection rules, and freedom from vendor lock-in on the storage tier. Compliance-driven retention windows of one to seven years make this trade-off attractive for many security teams.
Analysis and detection is where most SIEM logic lives. ClickHouse SQL handles the bulk of it well. Rate-based detections (failed logins per user per minute, DNS queries per host, outbound connections per IP) run against pre-computed counters that update as events arrive. Threshold rules compare current behavior to historical baselines computed from the same data. Time-window correlations join events across sources within a sliding window: a privilege escalation followed within five minutes by access to a sensitive resource, or a new device login followed by data egress.
Consumption closes the loop with Grafana dashboards, PagerDuty or Slack alerts, SOAR platforms for automated response, and threat-hunt UIs for analyst-driven investigation.
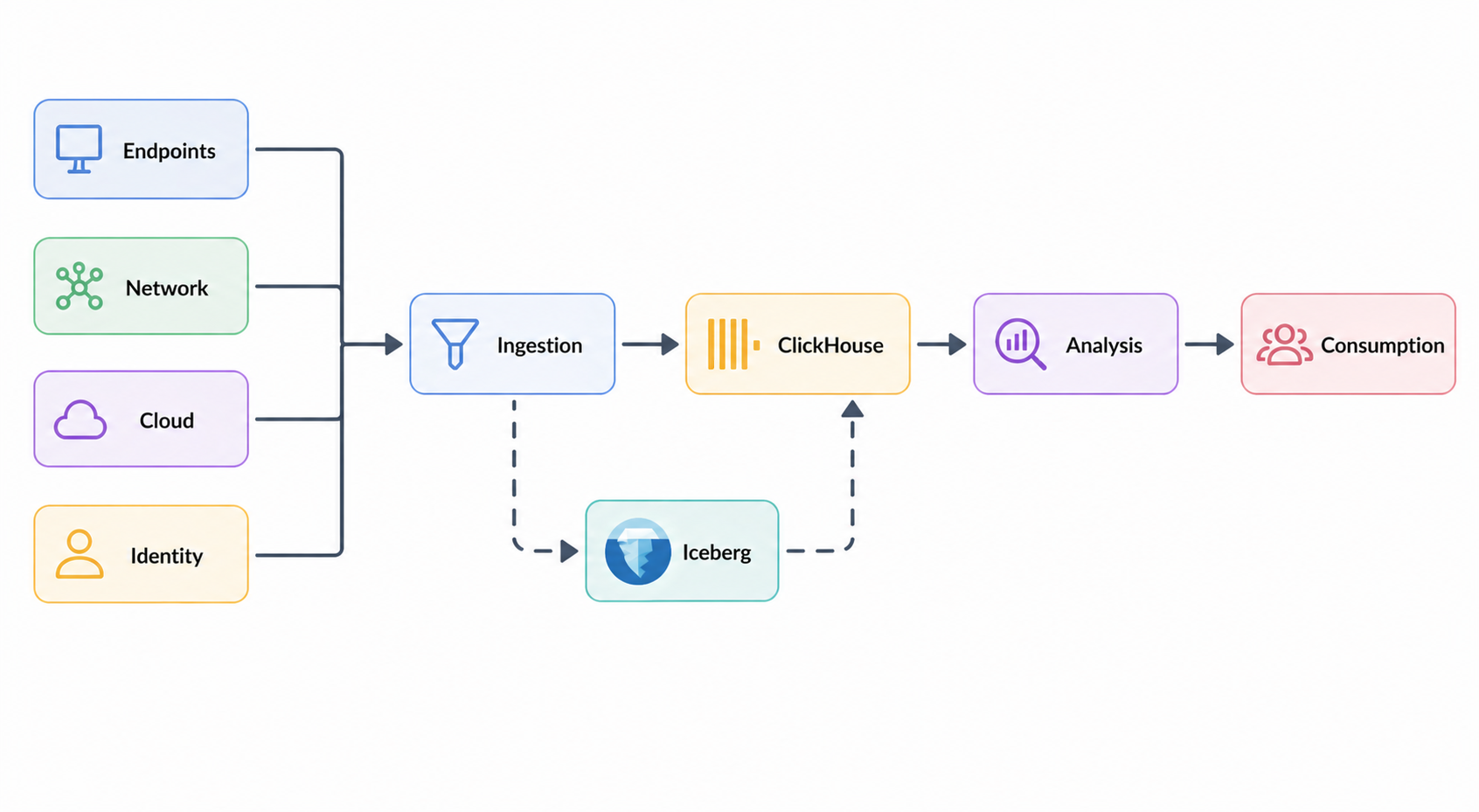
Beyond these five layers, there is a structural problem that recurs across SIEM workloads. Security data is fragmented across vendors and collection methods, but the things security teams actually reason about are not log rows. They are entities and relationships: a host runs a process, a process authenticates as a user, a user assumes a role, a role has access to a resource. Detection rules and investigations are written in this vocabulary even when the underlying tables are not, and minor disagreements about what an entity means become silent sources of false positives and missed alerts.
PuppyGraph addresses this by adding a semantic layer (formally, a data ontology) on top of ClickHouse. A JSON schema declares the entity classes and relationships that matter to the organization, mapping ClickHouse tables to entity classes and join keys to relationships. Detections and investigations are then written against the entity model rather than against raw tables, so underlying schemas can evolve without rewriting every detection rule.
PuppyGraph also enforces this ontology at query time. Queries are validated against the declared entity model before execution, which means a query referencing a relationship that does not exist in the model is rejected with a structured error rather than silently returning wrong results. This matters most for queries written by automated systems and AI assistants, which can produce queries that are syntactically valid but semantically nonsensical.
Built on this foundation, PuppyGraph also includes an AI assistant that lets security analysts and threat hunters explore SIEM data through natural-language questions. Because the assistant operates against the ontology-enforced model, the queries it generates remain semantically aligned with the underlying data, even for users who do not know the underlying schema.
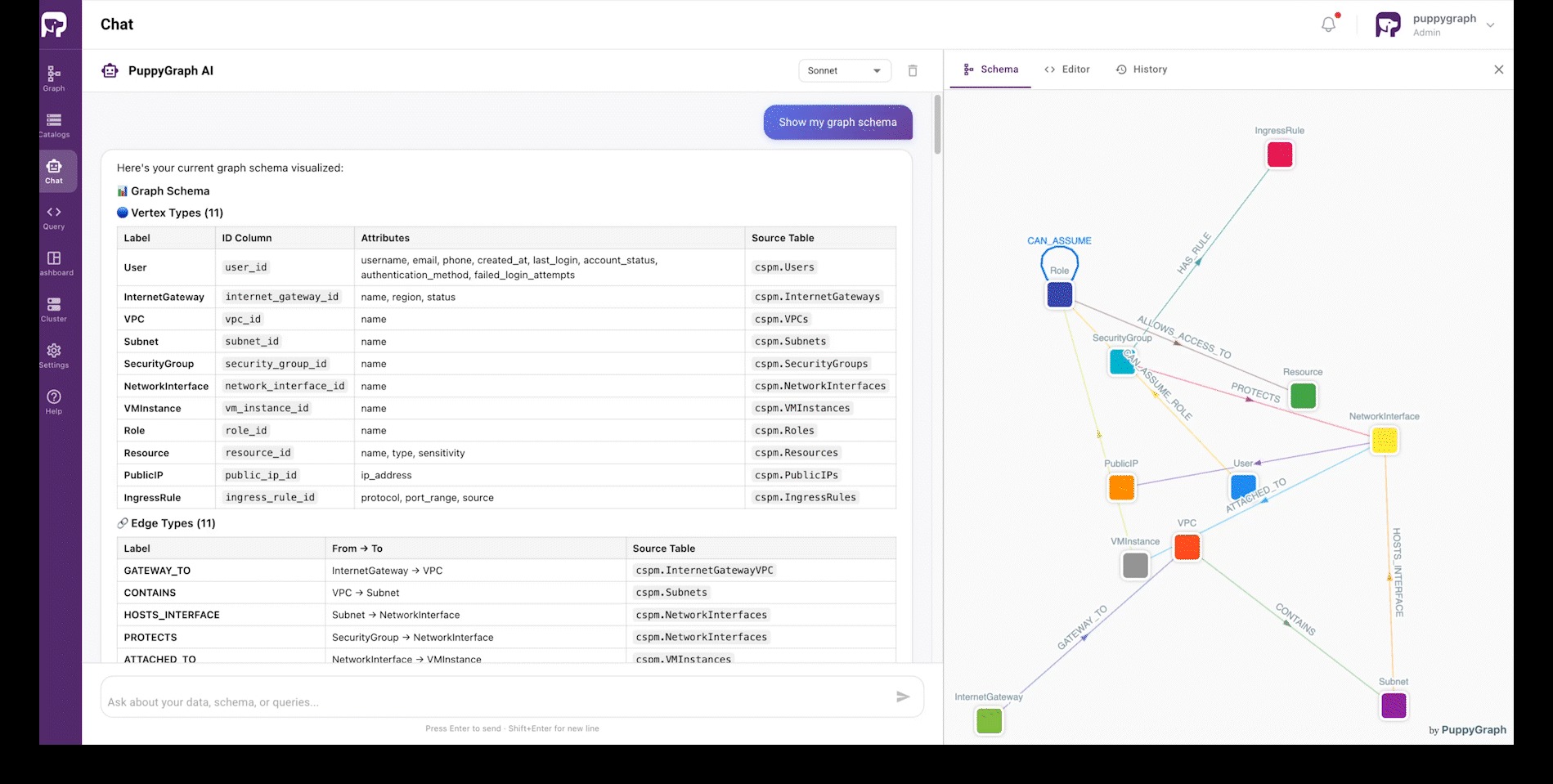
PuppyGraph reads open table formats like Apache Iceberg and Delta Lake natively as well, so the same ontology can span hot ClickHouse data and cold lakehouse history without an ETL pipeline between them.
Data Ingestion Strategies for ClickHouse SIEM
Ingestion is where most of the operational headaches in a SIEM live, since detection logic is bounded by what data arrives, in what shape, and how reliably. The good news is that the patterns have largely converged.
The dominant approach is streaming through a buffer. Lightweight collectors at the source handle parsing, enrichment, and batching close to the data, then forward to a streaming buffer that decouples producers from ClickHouse. ClickHouse consumes from the buffer and lands data into MergeTree tables. The buffer absorbs spikes, smooths over ClickHouse maintenance windows, and makes replay possible when detection rules change and history needs to be rescored.
A second ingestion path matters for teams running the lakehouse variant introduced earlier, where Apache Iceberg on object storage holds the long-term system of record. ClickHouse can read Iceberg tables directly through built-in support for the format, which makes historical data queryable without first loading it into MergeTree. When a new detection rule needs to be replayed across a year of data, or when an investigation reaches further back than the hot retention window, the same query can pull from MergeTree for recent events and from Iceberg for cold history. Selectively materializing slices of Iceberg data into MergeTree through a bulk load query covers cases where the cold data needs to participate in performance-sensitive queries.
Schemas tend to converge on a wide events table with common fields (timestamp, source, user, IP, event type) materialized into typed columns and the rest of the payload kept in JSON or Map columns. New fields from upstream sources become queryable on arrival, and high-frequency ones can be promoted to materialized columns later. Keeping the raw payload around is worth the storage cost: most incident investigations eventually need a field that was not anticipated when the schema was designed.
Scalability and Distributed Processing in ClickHouse
ClickHouse scales horizontally along three independent axes, which is part of what makes it manageable at SIEM volumes.
- Sharding. Writes and storage distribute across nodes, with the cluster topology hidden from detection rules and dashboards. Capacity grows by adding shards rather than vertically scaling a single machine.
- Replication. Multiple replicas of each shard provide high availability and fault tolerance. Failover is automatic, and adding replicas is a runtime operation rather than a migration.
- Tiered storage. Data ages from local SSD to object storage automatically as it gets older, and the cold tier remains queryable through the same interface. Multi-year compliance retention becomes a budget question rather than an engineering project.
Query parallelism uses CPU cores within a node and shards across the cluster, which lets detection workloads benefit from horizontal scaling for the common SIEM patterns of filtering and aggregating over time windows.
The semantic layer scales alongside the data layer. PuppyGraph follows the same separation of compute and storage that ClickHouse does, but at a different level: it does not duplicate data, and its compute nodes can be added independently of ClickHouse cluster sizing. Heavy parts of an ontology query (traversal, intermediate result handling, ontology enforcement, result assembly) execute across PuppyGraph's distributed compute nodes, while ClickHouse handles bulk data access through OLAP scans. The two layers scale on independent budgets: more ClickHouse shards for ingest and SQL detection load, more PuppyGraph compute nodes for ontology query performance and concurrency.
Security and Access Control in ClickHouse
A SIEM is one of the most sensitive systems in any organization. It aggregates security data from every other system, which means a breach of the SIEM exposes the security state of the entire infrastructure. ClickHouse provides the controls needed to protect itself in that role.
- Role-based access control. Roles separate analyst access (read-only on detection tables), administrative access (schema and infrastructure changes), and ingest service accounts (write-only on specific tables), so each user and process holds the minimum privileges its job requires.
- Row policies. In multi-tenant deployments, row-level policies restrict each tenant or team to their own data automatically, without splitting tables along organizational lines.
- Column-level grants. Sensitive fields such as PII and credentials can be authorized per column, so analysts running detection queries see aggregate counts while only authorized roles see the underlying identifiers.
- TLS everywhere. Client connections require TLS, and traffic between cluster nodes is encrypted as well.
- Audit logging. Every query executed against the cluster is recorded with the user, query text, and access pattern. Access to the SIEM itself becomes monitorable with the same query engine.
- Network and storage protections. Private endpoints and VPC peering keep the cluster off the public internet, and disk-level encryption combined with object-storage server-side encryption protects data at rest across hot and cold tiers.
Conclusion
ClickHouse gives security teams a viable path to running SIEM workloads with the cost and performance characteristics of a columnar analytics engine, on infrastructure they own and in formats they control. The pattern is mature enough that it shows up in production across security vendors, in-house security teams, and managed SIEM platforms. The interesting questions now are not whether ClickHouse works as a SIEM backend, but how far the architecture can be extended.
A semantic layer is one direction worth taking seriously. Detections written against entity models rather than raw tables are easier to author, easier to audit, and more resilient to schema change. PuppyGraph provides this layer on top of ClickHouse without copying data and enforces the ontology at query time, which matters as more queries get generated by automated systems and AI assistants.
The integration pattern shown above is straightforward to set up against ClickHouse tables. Explore more with the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install