

Cypher Programming Language: A Practical Guide

Cypher is a declarative query language designed for working with graph data. It was introduced by Neo4j to make it easier to describe complex relationships between entities, and has since become one of the most recognized languages for graph querying. Unlike SQL, which focuses on tables and joins, Cypher works directly with nodes, relationships, and properties, the essential components of a property graph. This allows users to express questions about connected data in an intuitive, pattern-based form such as MATCH (a)-[r]->(b).
The language’s design focuses on readability and clarity. Even complex traversals, like finding multi-hop relationships or analyzing paths between entities, can be expressed concisely without procedural code. Because of this, Cypher has been adopted well beyond Neo4j through the openCypher initiative, and it influenced standards like SQL:2023 Graph and the emerging ISO Graph Query Language (GQL).
Today, Cypher is used in a wide range of applications, from recommendation systems and fraud detection to cybersecurity and knowledge graphs. This guide provides a practical introduction to Cypher, including its data model, syntax, and advanced capabilities, and shows how graph query programming reveals patterns that traditional relational queries often overlook.
What is the Cypher Programming Language?
Cypher is a declarative graph query language created to describe patterns in connected data. It was originally developed for Neo4j, where it became the standard way to work with the property-graph model. In Cypher, users express what data they want to retrieve or manipulate rather than how to perform the retrieval. The system’s query engine then determines the optimal execution plan. This declarative approach, familiar to users of SQL, makes Cypher intuitive for both developers and analysts.
At its core, Cypher operates on nodes, relationships, and properties, the three elements of a property graph. A node represents an entity such as a person, device, or account. Relationships capture how those entities are connected, and properties store key–value attributes on both nodes and relationships.
For example, consider the “Modern” graph provided by Apache TinkerPop, with person nodes and software nodes. Arrows between person nodes represent "know" relationships, while arrows from person nodes to software nodes indicate that someone created specific software.
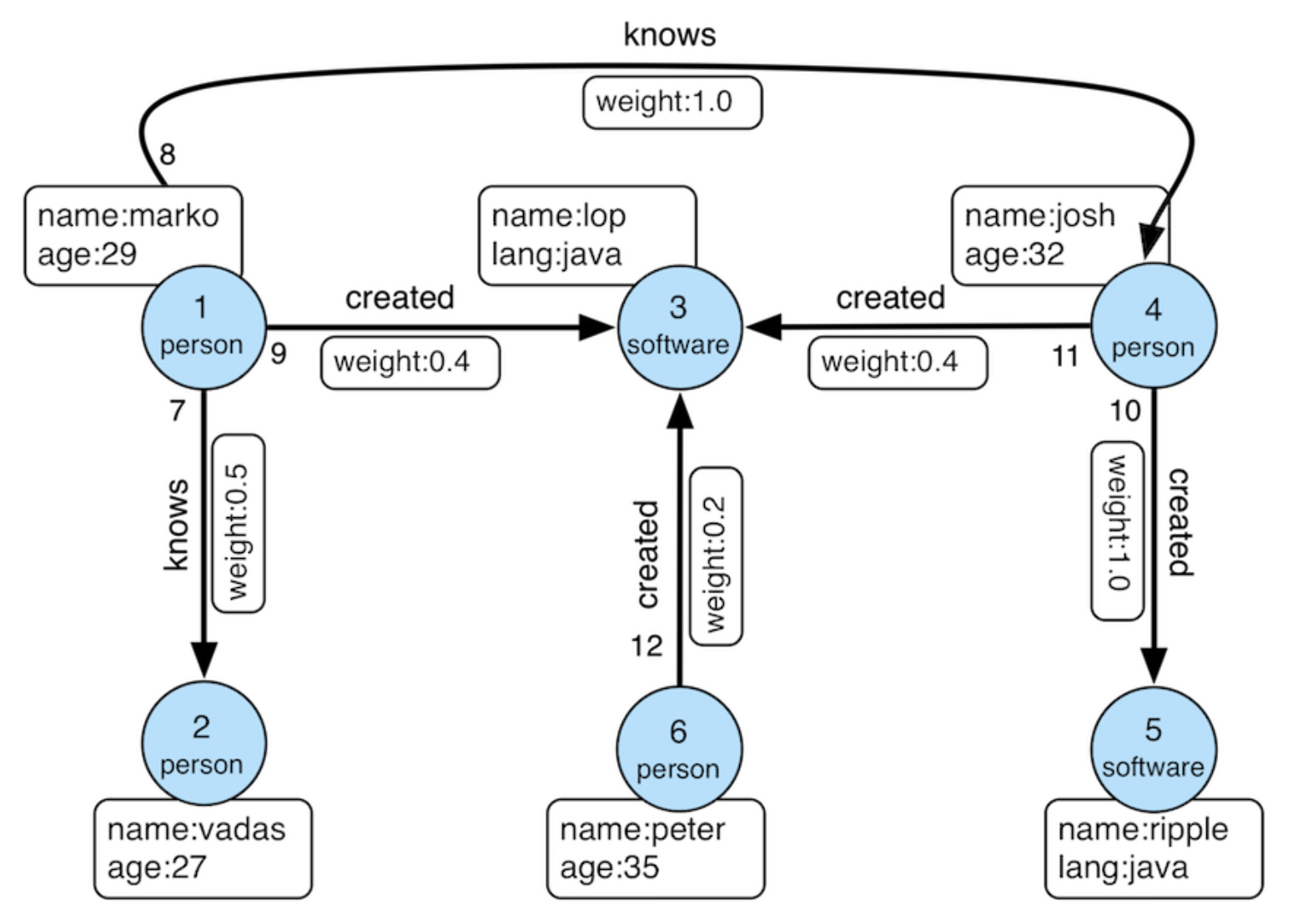
To find who created software “ripple”, we just write down the intuitive pattern, person nodes with “created” arrow pointing to the ripple node. The query result would be “josh”.
MATCH (p:person)-[:created]->(s:software {name:'ripple'})
RETURN p.nameCypher’s simplicity lies in its visual correspondence between syntax and graph structure. Parentheses represent nodes, arrows represent relationships, and square brackets describe relationship types or properties. This compact notation allows users to express complex traversals, aggregations, and filters in just a few lines of code.
Over time, Cypher evolved from a Neo4j-specific language into a broader open standard through the openCypher project. This initiative defined a public language specification that other systems could adopt. Many graph platforms implement openCypher to ensure compatibility and portability. Cypher’s influence also extends to newer standards such as SQL:2023 Graph and ISO GQL, both of which adopt similar pattern-matching semantics.
The Graph Data Model Behind Cypher
Cypher is built on the property graph model, a flexible way to represent entities and their relationships. Instead of storing data in tables, a property graph models the world as nodes, relationships, and properties, giving equal importance to the entities and the connections between them.
- Nodes represent entities such as people, organizations, or products. Each node can optionally carry one or more labels, which serve as lightweight tags that categorize nodes into groups. Labels are not required by the property-graph model itself, but Cypher uses them to make queries more structured and efficient. For instance, a node might have the label :Person or :Software.
- Relationships represent directed links between nodes. Each relationship has exactly one type, which defines the kind of connection, such as :KNOWS and :CREATED.
- Properties are key–value pairs that describe attributes of both nodes and relationships, such as name: "marko" or weight: 0.4.
The "Modern" graph is an example of this model.
Cypher Programming Language Basics
The foundation of Cypher lies in pattern matching, which allows users to describe graph structures visually and retrieve the nodes and relationships that match those patterns. Combined with filtering using the WHERE clause, these two features form the core of Cypher’s declarative approach.
Pattern Matching
Cypher’s MATCH clause defines the graph pattern to search for. Patterns are written using parentheses for nodes, brackets for relationships, and arrows to indicate direction. Each node or relationship can include labels, types, and properties. For example, using the “Modern” graph:
MATCH (p:person)-[:created]->(s:software)
RETURN p.name, s.nameThis query finds all people who created software and returns their names.
- (p:person) represents a node labeled person and bound to the variable p.
- [:created] describes an outgoing relationship of type created.
- (s:software) represents the connected node labeled software.
Filtering with WHERE
The WHERE clause refines the results of a pattern match by specifying conditions that must be true for the matched data. It can filter based on properties, relationships, or even structural criteria such as path length.
MATCH (p:person)-[:created]->(s:software)
WHERE s.lang = 'java'
RETURN p.name, s.nameThis retrieves only the software written in Java and the people who created it.
Fundamental Operations in Cypher Query language
Cypher operations primarily revolve around CRUD (Create, Read, Update, Delete) actions on the graph. The basic structure usually involves a MATCH (or CREATE) followed by an action like RETURN, SET, or DELETE.
Advanced Programming in Cypher
Beyond the fundamentals, Cypher provides powerful constructs for complex data manipulation, analytical queries, and efficient traversal across large graphs. These capabilities let users move from basic pattern matching to reasoning about entire graph structures.
Aggregation and Sorting
Cypher supports grouping and summarizing data using SQL-like clauses and functions.
- WITH acts as a pipeline break, passing intermediate results between parts of a query and preparing data for aggregation.
- Aggregation functions such as count(), sum(), avg(), min(), max(), and collect() allow summarizing or restructuring results.
- ORDER BY, SKIP, and LIMIT control result sorting and pagination.
The following query counts the creators for each software, filters to include only software with at least one contributor, and returns the top software by the total number of contributors. The query result would be “lop” and 3.
MATCH (p:person)-[:created]->(s:software)
WITH s, count(p) AS creators
WHERE creators >= 1
RETURN s.name, creators
ORDER BY creators DESC
LIMIT 1Working with Paths
Cypher excels at expressing multi-hop traversals and exploring how entities connect through chains of relationships. Paths are first-class objects in Cypher, meaning they can be matched, inspected, and returned directly.
- Variable-length paths: The * operator defines how many hops Cypher should traverse.
- Path functions: Functions like length(path), nodes(path), and relationships(path) allow users to analyze each path’s structure.
The following query finds all people reachable from Marko within one or two knows relationships, returning each person’s name, the number of hops, and the nodes along the path. It’s an intuitive way to explore direct and indirect friendships in a network.
MATCH path = (a:person {name:'marko'})-[:knows*1..2]->(b:person)
RETURN b.name, length(path) AS hops, nodes(path) AS path_nodes
ORDER BY hopsThe following can reveal shared projects between collaborators. It identifies people who have created the same software as Marko, showing how Cypher captures indirect connections such as collaboration, co-authorship, or shared dependencies in just one concise pattern. The query returns all paths and we can see the visualization of the results via PuppyGraph UI.
MATCH path = (a:person {name:'marko'})-[:created]->(:software)<-[:created]-(b:person)
RETURN path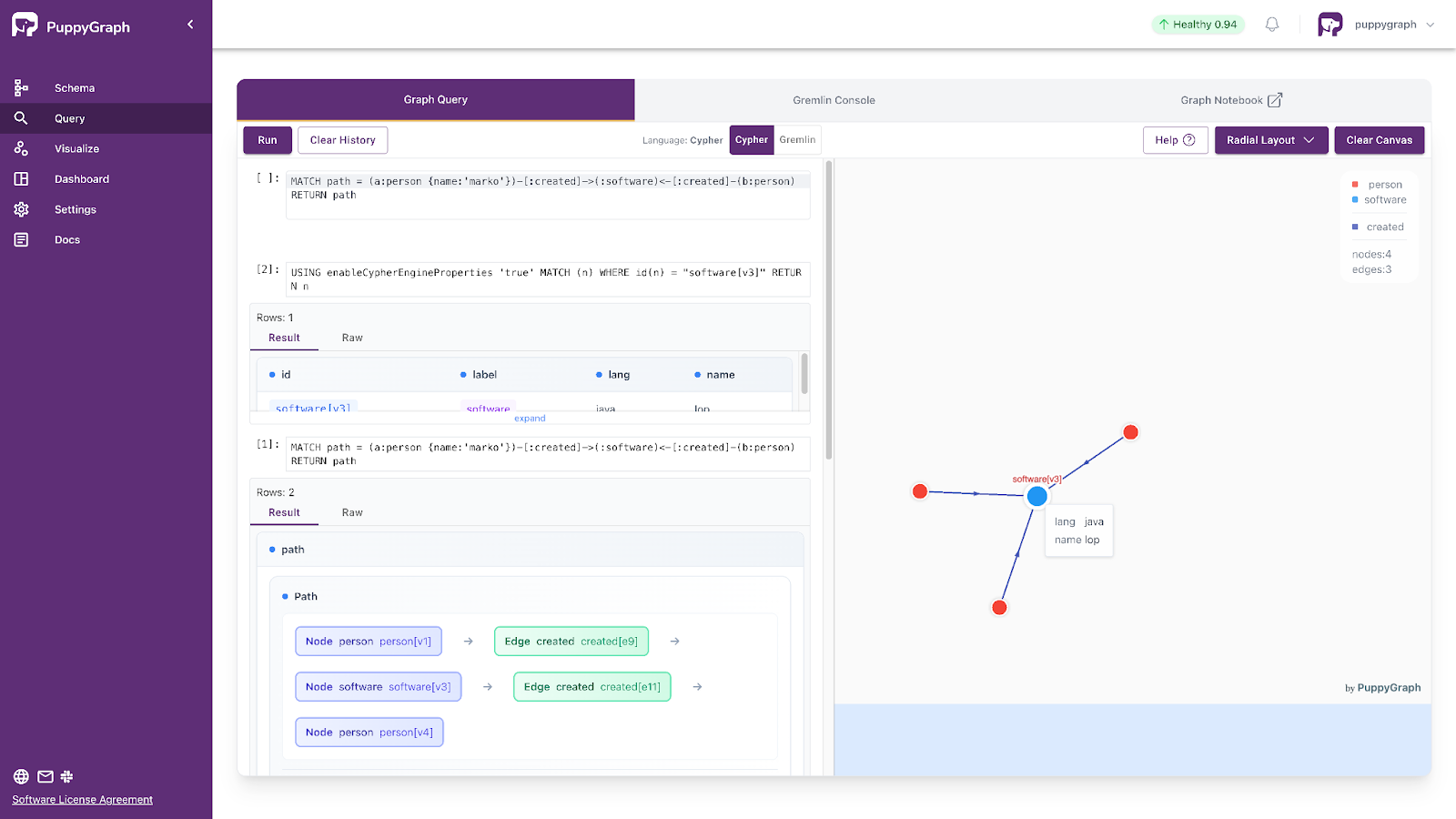
Procedures and Functions
Many Cypher implementations include built-in or extended procedures for advanced processing, such as executing algorithms, performing data transformations, or expanding paths under specific constraints.
In Neo4j, the Graph Data Science (GDS) library provides a pageRank procedure with configurable parameters such as node labels, relationship types, and damping factor:
CALL gds.pageRank.stream({
nodeLabels: ['Page'],
relationshipTypes: ['LINKS'],
relationshipWeightProperty: 'weight',
maxIterations: 20,
dampingFactor: 0.85
})
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).id AS id, score
ORDER BY score DESC;In PuppyGraph, a similar PageRank procedure can be called directly through Cypher:
CALL algo.paral.pagerank({
labels: ['Page'],
relationshipTypes: ['LINKS'],
relationshipWeightProperty: 'weight',
maxIterations: 20,
dampingFactor: 0.85
})
YIELD id, score
RETURN id, score;Both examples demonstrate how Cypher extends beyond querying to serve as an interface for analytical computation.
Cypher as a Programming Paradigm
Cypher represents a declarative programming paradigm for connected data, similar to how SQL operates on relational data. Users describe the data patterns they want to retrieve rather than defining procedural steps for how to access them. The query engine automatically decides the most efficient way to execute the pattern. This declarative approach allows Cypher to remain simple, readable, and accessible even when describing complex relationships.
At the same time, Cypher is graph-native by design. It treats entities and their relationships as first-class elements of computation, not as derived constructs from tables or joins. Nodes, relationships, and paths are all addressable objects within the language, allowing queries to naturally express connectivity, hierarchy, and recursion. This graph-first model enables analyses such as multi-hop traversals and dependency exploration to be written directly as patterns, without the overhead of reconstructing connections through joins.
Together, these two characteristics, declarative logic and graph-native modeling, make Cypher more than a query language. It is a way to think and program in terms of relationships, allowing users to express real-world structures in their most natural form.
Practical Use Cases of Cypher Query Programming
Cypher’s expressiveness makes it well suited for modeling and analyzing real-world systems where relationships carry meaning. Here are some practical examples.
Cybersecurity Analytics
Security teams often need to understand how user identities and sessions interact with sensitive resources.
MATCH (a:Account)-[:HasIdentity]->(i:Identity)-[:HasSession]->(s:Session)
-[:RecordsEvent]->(e:Event)-[:OperatesOn]->(r:Resource)
WHERE r.resource_type = 'S3Bucket'
RETURN a.account_id AS Account,
r.resource_name AS S3BucketName,
e.event_id AS EventID
LIMIT 50This query identifies accounts that have operated on S3 buckets, linking identities, sessions, and access events into one path. It highlights how Cypher’s multi-hop traversals make it easy to correlate actions across different security entities.
Fraud Detection
Graphs can reveal hidden transactional connections that indicate risk or collusion.
MATCH (src:Account {id: 'ACC123456'})<-[e1:transfer]-(mid:Account)-[e2:transfer]->(dst:Account {isBlocked: true})
WHERE src.id <> dst.id
AND datetime('2024-10-01T00:00:00Z') < e1.timestamp < datetime('2025-10-01T23:59:59Z')
AND datetime('2024-10-01T00:00:00Z') < e2.timestamp < datetime('2025-10-01T23:59:59Z')
RETURN collect(dst.id) AS dstIdThis query finds all blocked destination accounts that share a common intermediary account with a given source account, within a specific time range. It’s a typical example of how Cypher uncovers indirect relationships that may suggest coordinated fraudulent activity.
Knowledge Graphs
In knowledge graphs, Cypher can model semantic relationships among entities like people, movies, or concepts.
MATCH (actor:Person {name: 'Tom Hanks'})-[:ACTED_IN]->(movie:Movie)
RETURN movie.title, movie.year, movie.rating
ORDER BY movie.rating DESCThis retrieves all movies featuring Tom Hanks, ordered by rating. The same pattern can extend to other relationships such as directors, genres, or production studios, enabling flexible querying across interconnected information.
Across these examples, Cypher demonstrates a consistent logic: it models entities as nodes and their interactions as relationships, allowing users to write intuitive, multi-hop queries that reflect the structure of real-world data. From monitoring access patterns to detecting financial anomalies or querying knowledge networks, Cypher provides a unified way to reason about connected systems.
Strengths of Cypher Programming Language
Cypher stands out for its clarity, adaptability, and enduring influence on graph data management. Its strength is not just in how it works, but in how it shapes the way users think about connected data.
Readable and Expressive
Cypher’s pattern-based syntax is simple enough for newcomers yet expressive enough for complex analytics. The language mirrors the graph structure itself, allowing queries to communicate intent clearly. This readability has helped Cypher become the most recognizable graph query language in practice.
Portable Across Systems
What began as Neo4j’s query language has evolved into a community standard through the openCypher initiative. Many modern graph engines and query platforms now implement or interoperate with it, enabling a consistent developer experience across ecosystems.
Foundation for Graph Standards
Cypher’s concepts have directly shaped SQL:2023 Graph and the upcoming ISO Graph Query Language (GQL). Its influence ensures that the principles of pattern matching and declarative traversal will continue to guide future graph query standards.
Bringing Cypher to Your Relational Data with PuppyGraph
Traditionally, using Cypher has required moving data into a dedicated graph database like Neo4j, a process that introduces data duplication, complex ETL pipelines, and high operational overhead. PuppyGraph eliminates that barrier.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.


Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Cypher has become the most widely adopted language for querying and reasoning about graph data. Its declarative and graph-native design makes it both intuitive and powerful, which is capable of expressing complex relationships in patterns that are easy to read and maintain.
From exploring connections in social and financial networks to analyzing cybersecurity and knowledge graphs, Cypher provides a consistent way to represent real-world systems as they naturally exist: as networks of relationships. Its influence now extends beyond any single platform, forming the foundation for emerging standards such as openCypher, SQL:2023 Graph, and ISO GQL.
As data grows increasingly interconnected, the need for languages that can express and analyze relationships directly will only become more critical. Cypher continues to meet that need, serving as both a practical tool for today’s graph applications and a guiding model for the future of graph query languages.
PuppyGraph empowers users to query existing relational data using openCypher without ETL. Get started with our forever-free Developer Edition to take a try, or book a free demo with our team to see how PuppyGraph helps with your data analytics strategy.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install