

Data Federation: How It Works, Benefits, Use Cases

Data is increasingly distributed across cloud platforms, on-premise systems, and specialized applications, making unified access a persistent challenge for modern organizations. Traditional integration approaches, such as data warehousing, rely on physically consolidating data through ETL pipelines, often introducing latency, duplication, and governance complexity. As the volume and diversity of data continue to grow, these limitations become more pronounced, especially in real-time and cross-domain scenarios.
Data federation addresses this challenge by enabling a virtual, unified view of data without moving it from its original sources. By abstracting underlying complexity through a global schema and intelligent query processing, federation allows organizations to access, combine, and analyze heterogeneous datasets on demand. This approach not only preserves local autonomy but also supports agility, real-time insights, and modern decentralized architectures.
What is Data Federation?
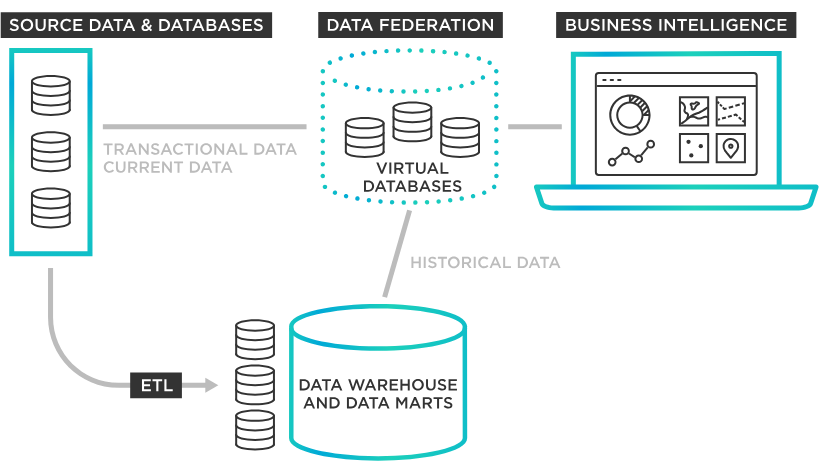
Data federation is a form of data virtualization where multiple autonomous database systems are mapped into a single federated database. Unlike traditional data warehousing, which physically consolidates data into a single central repository through Extract, Transform, Load (ETL) processes, data federation leaves the data in its source systems and retrieves it on demand.
According to the classification of distributed database systems, a federated database is a type of multidatabase system that balances local autonomy with global data sharing. It is characterized by three fundamental pillars:
- Distribution: Data is physically stored across multiple geographically or logically distinct platforms, such as relational databases, legacy systems, or cloud environments.
- Autonomy: Each component database remains independent. Local administrators retain control over their data, schemas, and access rights; the federated system does not "own" the data, but rather acts as a guest user with specific privileges.
- Heterogeneity: The underlying systems do not need to be identical. A federated system can bridge the gap between different hardware, operating systems, data models (e.g., SQL and NoSQL), and query languages.
In a federated environment, the system employs a Global Conceptual Schema: a unified "map" that hides the complexity of the underlying sources. When a user queries this global schema, the federation engine uses metadata to resolve semantic differences (such as different naming conventions for the same attribute) and handles the technical translation required to communicate with each unique source.
By providing a single point of access without moving the data, federation creates a "virtual" database that provides a holistic view of an organization’s information assets while respecting the operational independence of the original systems.
How Data Federation Works
Data federation operates by creating a virtual abstraction layer that sits above disparate data sources. Unlike traditional integration, it does not move data to a central hub; instead, it moves the query to the data. This process relies on a sophisticated multi-tier schema architecture and a specialized request-processing workflow.
1. The Multi-Tier Schema Architecture
According to the standard reference architecture for federated systems (notably the Sheth-Larson model), the "magic" of federation happens through a series of schema mappings:
- Local Schema: The original design of the individual component database.
- Component Schema: A translation of the local schema into a common data model (e.g., converting a NoSQL structure into a relational format).
- Export Schema: A subset of the component schema that defines exactly which data is available for federation, ensuring local autonomy and security.
- Federated Schema (Global Conceptual Schema): The unified view that integrates multiple export schemas. This is what the user interacts with.
2. The Query Execution Process
When a user submits a query to the federated system, the engine follows a rigorous technical workflow:
- Query Transformation and Decomposition: The federation engine receives a global query and breaks it down into sub-queries tailored for each specific source database. It uses the metadata repository to identify which fragments of the query belong to which source.
- Semantic Resolution: The engine resolves "schematic heterogeneities." For example, if one database identifies a customer by Cust_ID and another by Client_No, the engine maps these to a single attribute in the global schema.
- Distributed Query Optimization: This is the most critical step. The engine calculates the most efficient way to execute the query. It decides whether to perform joins at the source or to pull raw data into the federation engine’s memory for processing, aiming to minimize network traffic and latency.
- Translation and Execution: Using wrappers or adapters, the engine translates the sub-queries into the native languages of the source systems (e.g., SQL, GraphQL, or specific API calls).
- Result Merging: Once the source systems return their results, the federation engine performs any final filtering, joins, or formatting before presenting a single, unified result set to the user.
3. Maintaining Autonomy through Wrappers
The system relies on "Wrappers" (also known as Mediators). These software components hide the technical details of the underlying sources. Because the federation engine acts as a client rather than an owner, the source databases remain autonomous. They can continue their local operations (updates, maintenance, and local queries) without interference from the federated layer, fulfilling the "Pillar of Autonomy" essential to the definition of a federated database.
Benefits of Data Federation
Data federation offers a strategic alternative to physical data consolidation, providing several technical and operational advantages by maintaining the "Pillar of Autonomy" while enabling "Global Sharing."
Preservation of Local Autonomy
One of the primary benefits is that component databases remain autonomous. Local administrators retain full control over their data schemas, security protocols, and update cycles. Since the federated system acts as a "guest" rather than an owner, it does not interfere with the local operations or the integrity of the source systems. This is particularly critical in multi-organizational collaborations where data owners are unwilling to relinquish control to a central authority.
Elimination of Data Redundancy and Latency
Unlike traditional Data Warehousing, which relies on periodic ETL (Extract, Transform, Load) processes, data federation provides real-time access.
- Reduced Storage Costs: Because data is not copied into a central repository, organizations save on the overhead costs of storing redundant datasets.
- Data Freshness: Users query the "live" source. This eliminates the "data latency" inherent in ETL pipelines, ensuring that analytical results reflect the most current state of the operational databases.
Flexibility and Heterogeneity
Federated systems are designed to bridge the gap between "Heterogeneous" systems. They allow organizations to integrate disparate data types, such as relational SQL databases, NoSQL document stores, and legacy flat files, into a single conceptual view. This abstraction allows developers to write a single query against the global schema without needing to learn the specific query languages or technical nuances of every underlying platform.
Improved Security and Governance
By keeping data in its original location, federation minimizes the "attack surface" created by moving sensitive information across networks into a central hub.
- Centralized Access Control: Administrators can implement security policies at the federated layer, providing a single point of governance.
- Compliance: For industries governed by strict data residency laws (like GDPR or HIPAA), federation allows data to remain in its legally required geographic or logical location while still being available for global analysis.
Cost-Effective Scalability and Agility
Implementing a full-scale data warehouse is often a multi-month or multi-year project. Data federation allows for incremental integration. New data sources can be added to the federated schema by simply developing a new "wrapper" or "adapter," rather than re-engineering an entire ETL pipeline. This agility allows organizations to respond rapidly to new business requirements or integrate data from newly acquired subsidiaries during mergers.
Reduced "Data Friction"
Data federation lowers the barrier to data exploration. By providing a Global Conceptual Schema, it hides the complexity of distribution. Users can perform complex joins across geographically dispersed servers as if they were querying a single table on their local machine, significantly reducing the technical friction involved in cross-departmental reporting.
Common Use Cases of Data Federation
The common use cases of data federation share a core characteristic: the data is too massive, too sensitive, or changing too quickly to be physically consolidated. By maintaining data at the source, federation enables dynamic, runtime access across distributed systems, making it more agile than traditional warehousing for cross-system workloads that require real-time visibility.
Cybersecurity and Threat Detection
In cybersecurity, logs, network traffic, and authentication events are distributed across cloud and on-premise systems. Data federation enables security teams to query live telemetry across these heterogeneous sources in real time. This allows analysts to detect and correlate attack patterns or active breaches without waiting for batch ETL pipelines or centralized ingestion.
Financial Anti-Fraud Analysis
Financial institutions often store transaction data, customer profiles, and behavioral signals in separate systems across business units. Data federation allows real-time joins across these siloed datasets, enabling investigators to detect suspicious patterns and coordinated fraud rings. At the same time, it preserves strict data residency and regulatory compliance requirements by avoiding unnecessary data movement.
Cross-Organizational Collaborative Research
In domains such as healthcare and genomics, data federation supports collaboration across independent institutions. Researchers can query a unified “virtual dataset” spanning multiple organizations while ensuring that sensitive raw data remains within each institution’s secure environment. This enables large-scale joint studies without violating privacy or governance constraints.
Modern Observability and System Analytics
Modern infrastructure is highly distributed across multi-cloud and microservices environments. Data federation enables querying across logs, metrics, traces, and deployment events generated at high scale. This provides a holistic system view while avoiding the high cost and latency of centralizing massive observability datasets.
Data Federation Architecture
The architecture of a Federated Database System (FDBS) is defined by its ability to manage distribution, autonomy, and heterogeneity. It relies on the Sheth-Larson Five-Level Schema model to map data from local sources into a unified global view without physical movement.
The Five-Level Schema Mapping
This tiered approach ensures seamless access while respecting local control:
- Local Schema: This is the native conceptual schema of an individual component database (e.g., a relational table in MySQL or a collection in MongoDB). It is expressed in the source's own data model.
- Component Schema: The system translates the Local Schema into a "canonical" or common data model (typically the Relational Model). This step resolves syntactic heterogeneity, ensuring all data speaks the same technical language.
- Export Schema: This layer defines the specific subset of data that the local system is willing to share with the federation. By restricting access at this level, the architecture preserves local autonomy and enhances security.
- Federated Schema (Global Conceptual Schema): This is the integration of multiple Export Schemas. It resolves semantic heterogeneity: for instance, merging "Client_ID" from one source and "Cust_No" from another into a single "CustomerID" field.
- External Schema: The top-most layer defines specific views for end-users or applications, tailored to their particular needs (e.g., a Marketing view vs. an Accounting view).
Functional Components
The system’s "nervous system" consists of three core elements:
- The Federation Engine (Mediator): The brain that receives global queries, decomposes them into optimized sub-queries for local sources, and decides where processing should occur to minimize latency.
- Wrappers (Adapters): The translators. They sit between the engine and the source, converting global commands into native SQL or API calls in real-time.
- Metadata Repository: The system’s "map," storing all transformation rules and data locations.
Coupling Degrees
Architectures are either Tightly Coupled, where a central administrator maintains a rigid global schema for high consistency, or Loosely Coupled, allowing domains to build flexible, on-the-fly federations.
Challenges in Data Federation
While data federation provides immense agility by avoiding physical data movement, it introduces several technical hurdles rooted in the "Pillar of Heterogeneity" and the reliance on real-time networking.
Performance and Distributed Query Latency
Performance is the most common bottleneck. Since data remains at the source, the system is at the mercy of network speeds and remote processing power.
- The "Weakest Link" Problem: A federated query is only as fast as its slowest source. If one autonomous database is under heavy load, the entire global result waits.
- The Join Problem: Joining massive tables across different cloud regions or on-premise systems can lead to significant egress costs and latency, as large datasets may need to be moved to the federation engine for final processing.
Semantic and Schematic Heterogeneity
Bridging the gap between disparate data models is complex. The engine must resolve naming conflicts (e.g., mapping Cust_ID to Client_No) and data scaling (e.g., converting currencies or units) in real-time. Additionally, mapping hierarchical NoSQL structures to flat relational schemas often causes impedance mismatch, where some data context is lost.
Vulnerability of Local Autonomy
The system is highly sensitive to changes it does not control. If a local administrator alters a schema (e.g., changing a column name) without notice, the Wrapper breaks, causing immediate query failures. Furthermore, unlike a warehouse that offers a static snapshot, federation requires every source to be "up" and accessible to complete a request.
Governance and Security Complexity
Managing security across a heterogeneous landscape is difficult. Administrators must map a single "Global Identity" across multiple local systems with different protocols (LDAP, OAuth), ensuring consistent row-level security and data masking without owning the underlying infrastructure.
Data Federation in Modern Data Architecture
Modern data is spread across multiple systems, making unified access difficult. In this setting, data federation goes beyond simple integration by providing a consistent query layer over fragmented systems, allowing teams to access and combine data without moving it. It fits naturally with decentralized models like data mesh, where data remains owned by domain teams but can still be queried in a unified way. In hybrid and multi-cloud environments, federation also reduces the cost and latency of data movement by pushing computation closer to the source. Rather than replacing data warehouses or lakes, it complements them by enabling flexible, real-time access to distributed data.
However, while data federation unifies access at the structural level, ensuring consistent understanding still requires additional semantic alignment.
The Semantic Layer: Ontology on the Virtual Layer
In a federated system, the virtual layer unifies access to data, but it does not guarantee a unified understanding of that data. This is where ontology on the virtual layer becomes essential: it introduces a semantic model that sits above the federated schema and defines what the data means, not just how it is accessed.
Consider a real-world example. Developer information may reside in an HR system, code contributions in a version control platform, and project metadata in an issue tracking system. Each system uses its own schema and identifiers. At the virtual layer, these appear as separate tables (e.g., employee, commits, and issues), and queries must manually reconcile them, such as mapping different identifiers (e.g., employee_id, author_email, or assignee) and resolving which records correspond to the same person across systems.
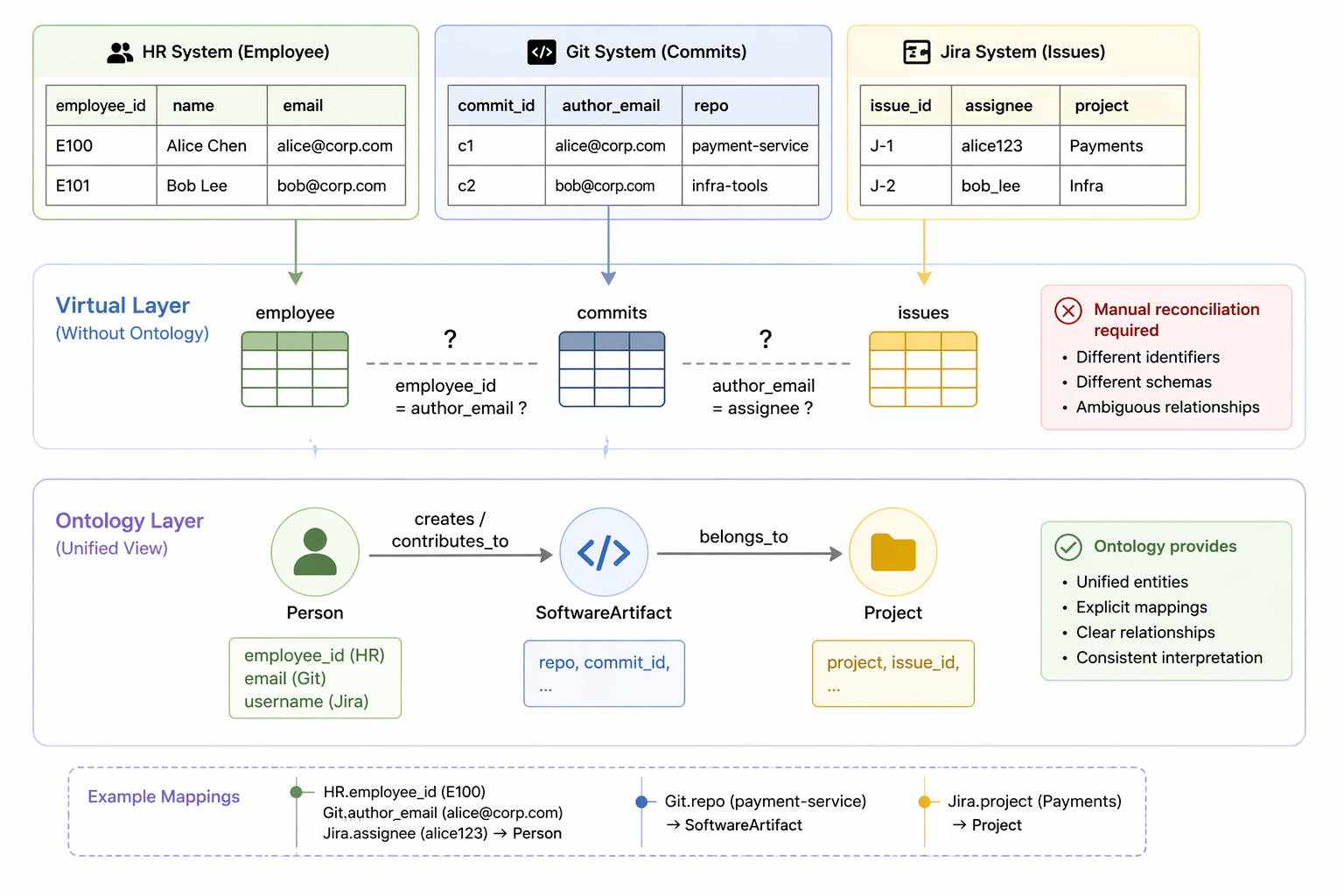
With an ontology on top, these datasets are mapped to unified conceptual entities such as Person, SoftwareArtifact, and Project, along with relationships like creates or contributes_to, with explicit mappings that link fields such as employee_id, author_email, or assignee to the same Person entity across systems. Instead of dealing with source-specific schemas, users and applications interact with these unified concepts, ensuring that data across systems is consistently interpreted.
Ontology Enforcement
Defining an ontology is only part of the solution. To ensure consistency in practice, the system must enforce it. Ontology enforcement means that all queries are validated and executed against the ontology, rather than directly against the underlying virtual tables. Users (or AI agents) no longer query source-specific tables; they query ontology-defined entities such as Person or SoftwareArtifact. The system then translates this into the appropriate federated queries behind the scenes.
This approach provides the following key benefits:
- Eliminating Semantic Hallucinations
In complex data environments, AI agents may produce queries that are syntactically correct yet semantically flawed. For instance, an agent might successfully join two tables but base the operation on a relationship that does not exist in practice. Ontology enforcement acts as a safeguard by restricting queries to a validated representation of how data is truly interconnected, thereby preventing these subtle but consequential mistakes. - The "Feedback Loop" for Self-Correction
Conventional database error messages typically lack sufficient semantic detail. With ontology enforcement, invalid queries generate structured, machine-interpretable feedback that clearly explains how the request violates the data model. This allows the agent to refine its behavior and gradually internalize the system’s logic, whether through fine-tuning or reinforcement learning.
Data Access with AI Assistant
Beyond architectural improvements, PuppyGraph provides a seamless, agent-driven interface for interacting with data. Built on top of the ontology-enforced semantic layer, its built-in AI assistant allows users to query data using natural language, while automatically grounding requests in a consistent conceptual model.
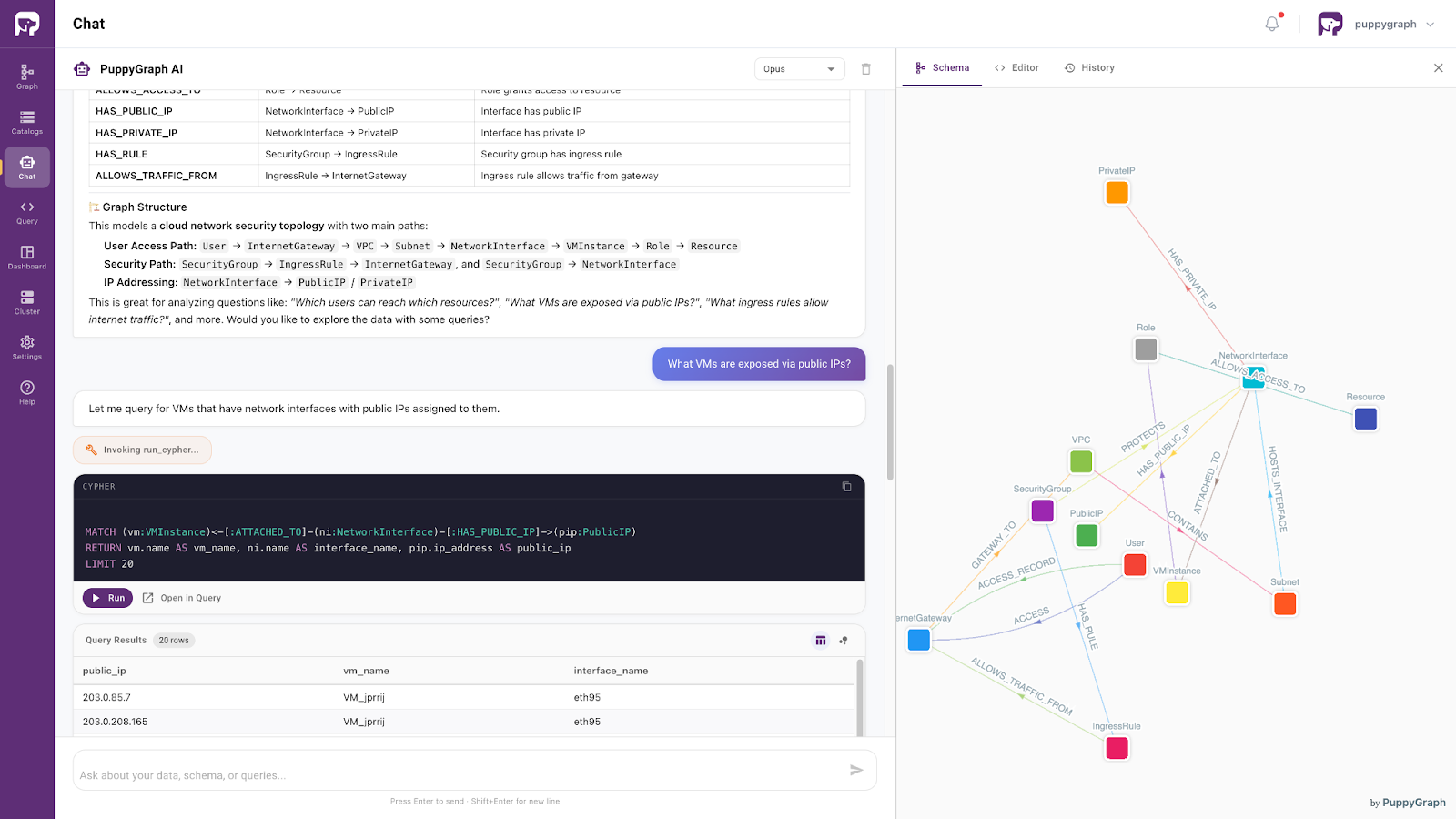
In the cybersecurity use case shown above, the ontology models a cloud network security topology, capturing how entities such as users, virtual machines, network interfaces, public IPs, and security controls are connected.
Instead of reasoning about source-specific schemas, users and AI agents interact directly with these unified, semantically meaningful entities and relationships. This transforms the federated system from a collection of loosely connected data sources into a coherent and semantically consistent data layer.
Conclusion
Data federation provides a powerful way to unify access to distributed data without physical consolidation, addressing the scalability, latency, and governance limitations of traditional ETL-based approaches. By introducing a virtual layer with a global conceptual schema, it enables real-time, on-demand querying across heterogeneous and autonomous systems. This allows organizations to preserve local control while achieving a holistic view of their data, supporting modern architectures such as data mesh and multi-cloud environments.
However, structural unification alone is not sufficient. By adding an ontology-driven semantic layer with enforcement mechanisms, systems can ensure consistent interpretation and prevent semantic errors in both human and AI-generated queries. Combined with natural language interfaces such as AI assistants, this approach transforms data federation into a more intelligent, reliable, and user-friendly data access paradigm.
Explore more with the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install