

What Is Data Lineage Tracking?
.png)
With data moving across multiple systems and platforms, keeping track of where it comes from, how it moves, and how it transforms has become increasingly difficult. This is where data lineage tracking plays a critical role. It provides a transparent view of how data evolves across its lifecycle, helping organizations trust their data and make better decisions.
Data lineage tracking is especially valuable in environments involving analytics, machine learning, regulatory compliance, and operational reporting. Without it, debugging data issues, ensuring compliance, or even answering simple questions about data origins can become time-consuming and error-prone. This guide explores the concept of data lineage tracking in depth, covering its importance, working principles, techniques, types, real-world examples, and implementation strategies.
What is Data Lineage Tracking
Data lineage tracking refers to the process of recording, visualizing, and analyzing the flow of data from its origin to its final destination. It captures how data is created, transformed, stored, and consumed across systems. This includes tracking data sources, transformations, dependencies, and usage patterns in a structured and interpretable way.
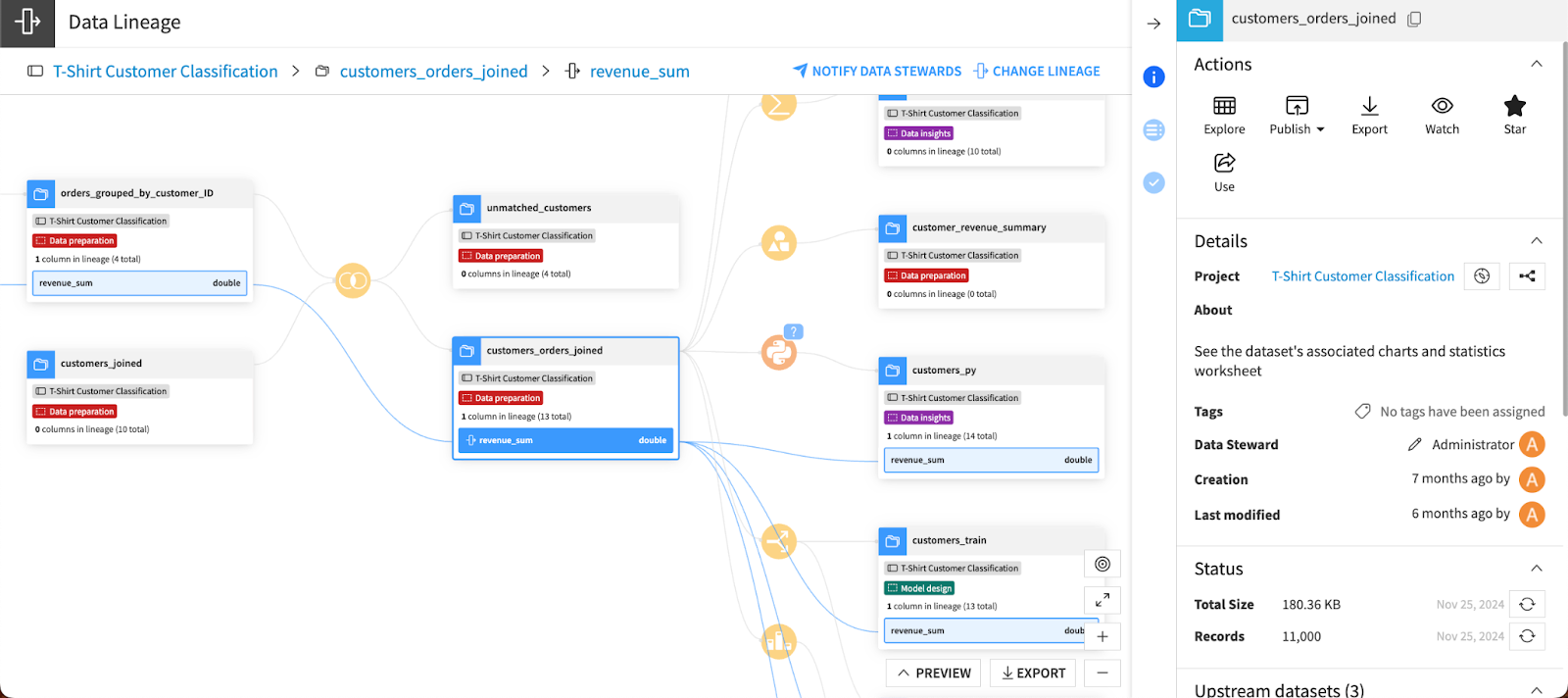
At its core, data lineage answers three fundamental questions: where did this data come from, how has it changed over time, and where is it being used. These answers are essential for data engineers, analysts, and governance teams who need to ensure accuracy and reliability in data systems. Without lineage, data becomes opaque, making troubleshooting and validation extremely challenging.
Data lineage tracking operates across multiple layers, including physical data movement, logical transformations, and business-level interpretations. Physical lineage focuses on actual data flows between systems, while logical lineage captures transformations like joins, aggregations, and filters. Business lineage connects data to business concepts, making it understandable for non-technical stakeholders.
In modern architectures such as data lakes and distributed pipelines, lineage tracking is often automated using specialized tools. These tools integrate with databases, ETL processes, and analytics platforms to continuously collect metadata. The result is a dynamic map of data flows that can be queried, visualized, and audited in real time.
Why Data Lineage Tracking is Important
Understanding the importance of data lineage is crucial for organizations aiming to maintain trust, ensure compliance, and optimize operations. Its impact can be observed in several key areas:
- Ensuring trust in data systems:
Stakeholders relying on dashboards or machine learning models must have confidence that the underlying data is accurate and consistent. Lineage provides the transparency needed to validate data sources and transformations, reducing uncertainty and improving decision-making quality. - Regulatory compliance:
Industries such as finance, healthcare, and telecommunications are subject to strict regulations that require traceability of data. Organizations must demonstrate how data is collected, processed, and stored. Data lineage tracking provides a clear audit trail, making compliance reporting more efficient and reliable. - Data quality management:
When data errors occur, lineage helps identify the root cause by tracing the issue back through the pipeline. Instead of manually investigating multiple systems, teams can quickly pinpoint where the problem originated, whether it was a faulty transformation, incorrect source data, or system failure. - Operational efficiency:
Data engineers often spend a significant amount of time understanding dependencies between datasets. Lineage tracking automates this understanding, allowing teams to assess the impact of changes before deployment. This reduces the risk of breaking downstream systems and accelerates development cycles. - Collaboration between technical and business teams:
By providing a shared understanding of data flows, lineage bridges the gap between engineering and analytics. Business users can better interpret data insights, while engineers gain clarity on how data is being used, creating a more aligned and effective data ecosystem.
How Data Lineage Tracking Works
Data lineage tracking works by collecting metadata from various components in a data ecosystem and linking them together to form a coherent representation of data flows. This metadata includes information about data sources, transformations, storage locations, and consumption points. The process typically involves integration with databases, ETL tools, data warehouses, and analytics platforms:
- Ingestion:
At the ingestion stage, lineage tracking systems capture information about incoming data sources. This includes details such as file origins, database tables, APIs, and timestamps. As data moves through pipelines, each transformation step is recorded, including operations like filtering, aggregation, enrichment, and joins. These steps form the backbone of lineage tracking. - Transformation:
The transformation layer is particularly important because it defines how raw data is converted into usable formats. Lineage systems track transformation logic either by parsing code (such as SQL or scripts) or by integrating directly with pipeline tools. This ensures that every modification to the data is documented and traceable. - Visualization:
Visualization plays a key role in making lineage understandable. Most lineage tools provide graphical interfaces that display data flows as directed graphs. Nodes represent datasets or systems, while edges represent transformations or dependencies. These visualizations allow users to explore data relationships interactively and identify upstream or downstream dependencies. - Evolvement:
Modern lineage systems also support real-time updates. As pipelines evolve, the lineage graph is automatically updated to reflect changes. This dynamic nature ensures that the lineage information remains accurate and relevant, even in rapidly changing environments.
Types of Data Lineage Tracking
When discussing data lineage tracking, it is useful to distinguish between several key types, particularly technical lineage, business lineage, and operational lineage, each offering a different perspective on how data flows through an organization.
- Technical lineage focuses on system-level details, including tables, files, schemas, transformation logic, and timestamps. It provides a detailed view of how data moves and changes across systems, making it especially valuable for data engineers who need to manage dependencies, troubleshoot pipelines, and maintain data infrastructure.
- Business lineage abstracts away technical complexity and represents data in terms of business concepts such as “Customer,” “Order Value,” or “Revenue.” This perspective helps business analysts, compliance teams, and decision-makers understand how data relates to business processes and outcomes, enabling clearer communication and more informed decisions.
- Operational lineage captures runtime metadata such as data volumes, processing performance, latency, freshness, error logs, and historical execution records. It focuses on how data pipelines behave in practice, helping teams monitor system health, identify bottlenecks, detect failures, and resolve data quality issues more efficiently.
In practice, effective data governance relies on a combination of all three types. Technical lineage provides structural clarity, business lineage delivers semantic understanding, and operational lineage ensures visibility into real-time performance. Together, they offer a comprehensive and actionable view of data across its entire lifecycle.
Data Lineage Tracking Techniques
There are several techniques used to implement data lineage tracking, each with its own advantages and limitations.
- Metadata-based tracking:
Metadata-based tracking relies on collecting metadata from systems and linking it together. This approach is efficient and scalable, making it suitable for large data environments. - Query parsing:
In this approach, lineage is derived by analyzing SQL queries or transformation scripts. By parsing queries, the system can determine how data is transformed and which datasets are involved. This method provides detailed lineage but can be complex to implement, especially when dealing with dynamic or non-standard queries. - Log-based tracking:
Log-based tracking is another approach that captures lineage information from system logs. Many data processing systems generate logs that record data movements and transformations. By analyzing these logs, lineage systems can reconstruct data flows without requiring deep integration with the underlying systems. - Instrumentation-based tracking:
Instrumentation-based tracking involves embedding lineage collection directly into data pipelines. This technique provides high accuracy because lineage is captured at runtime. However, it requires modifications to existing pipelines, which can be challenging in legacy systems.
Data Lineage Tracking Examples
Data lineage tracking allows organizations to trace data through its lifecycle, ensuring accuracy, accountability, and compliance. The following are some examples:
How to Implement Data Lineage Tracking
Implementing data lineage tracking requires a structured approach that aligns with organizational goals and technical capabilities:
- Defining the scope of lineage tracking:
Organizations must decide which systems, datasets, and processes need to be tracked. Starting with critical data pipelines is often the most practical approach. - Selecting the appropriate tools and technologies:
There are many lineage tracking solutions available, ranging from open-source frameworks to enterprise platforms. The choice depends on factors such as scalability, integration capabilities, and ease of use. It is important to choose a tool that integrates seamlessly with existing data infrastructure. - Integration:
Lineage tracking systems must connect to data sources, ETL pipelines, and analytics tools to collect metadata. This often involves configuring connectors, APIs, or agents that capture lineage information automatically. Proper integration ensures comprehensive and accurate lineage coverage. - Data governance:
Organizations should establish policies and standards for data management, including naming conventions, documentation practices, and access controls. These practices enhance the effectiveness of lineage tracking and ensure consistency across systems. - Training and adoption:
Teams must understand how to use lineage tools and interpret lineage information. Providing training and documentation helps ensure that lineage tracking becomes an integral part of daily workflows rather than an afterthought. - Continuous monitoring and improvement:
Data ecosystems evolve over time, and lineage tracking systems must adapt accordingly. Regular reviews, updates, and optimizations ensure that lineage information remains accurate and useful for decision-making.
Conclusion
Data lineage tracking is essential for ensuring transparency, accuracy, and accountability in modern complex data ecosystems. By capturing the flow of data from origin to consumption, organizations gain the ability to validate sources, monitor transformations, and understand dependencies across systems. This visibility not only strengthens trust in analytics and machine learning outputs but also supports regulatory compliance, data quality management, and operational efficiency.
Implementing effective lineage tracking requires a combination of appropriate tools, clear governance policies, and team adoption. Whether through metadata collection, query parsing, or other approaches, organizations can create a dynamic, interpretable map of their data flows. Ultimately, data lineage transforms opaque pipelines into actionable insights, enabling informed decision-making, reducing risks, and fostering collaboration between technical and business teams across the enterprise.
Explore more with the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install