

Data Ontology: Definition, Examples, Benefits
A data ontology provides a structured way to define what data means, not just how it is stored. In modern systems where data flows across platforms, formats, and organizations, simply sharing data is no longer enough: systems must also share understanding. By formally describing entities, attributes, and relationships within a domain, ontologies establish a common semantic foundation that both humans and machines can rely on.
This semantic layer becomes increasingly important as organizations deal with heterogeneous data and complex analytical needs. From enabling interoperability to supporting AI-driven reasoning, data ontology transforms raw data into meaningful, connected knowledge. It serves as the backbone for knowledge graphs, intelligent systems, and scalable data architectures, making it a critical component of modern data ecosystems.
What is Data Ontology?
In the context of information science, a data ontology is a formal way of representing properties, entities, and the relationships between them within a specific domain of interest. According to the foundational principles of information science, an ontology provides a shared and common understanding of a domain that can be communicated between people and across heterogeneous application systems.
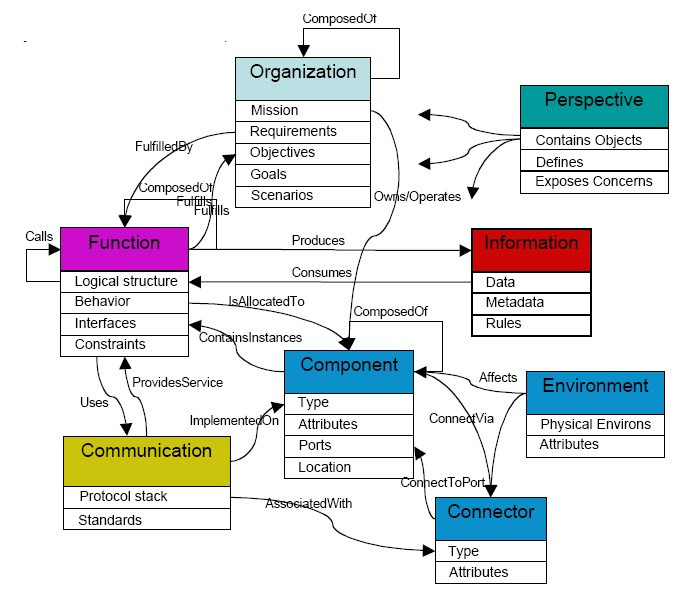
Unlike a simple database schema (which focuses on data storage) or a taxonomy (which focuses on hierarchical classification), an ontology models the "reality" of a domain. It consists of four fundamental components:
- Classes (Concepts): These are the abstract groups, sets, or types of objects. For example, in a medical ontology, "Disease" or "Symptom" would be classes.
- Attributes: These are the properties, features, or characteristics that objects in a class can have. For instance, a "Patient" class might have attributes like "Age" or "Blood Type."
- Relations: These define how classes and individuals interact with one another. A critical relation is the "is-a" relationship (e.g., a "Cardiologist" is-a "Doctor"), but it also includes complex associative relations (e.g., "Doctor" treats "Patient").
- Individuals (Instances): These are the basic, "ground-level" components of an ontology: the actual data points. "Dr. Smith" would be an individual instance of the "Doctor" class.
The primary goal of a data ontology is to achieve semantic interoperability: the ability for different systems to not only exchange data, but to interpret it with the same meaning. It uses logic-based languages, such as Web Ontology Language (OWL) or Resource Description Framework (RDF), to ensure that data is not just machine-readable, but machine-understandable. By explicitly defining the meaning of data through formal logic, ontologies allow systems to "reason" about the data, identifying contradictions or inferring new facts that were not explicitly stated in the raw dataset.
Essentially, while a data model tells a system how data is structured, a data ontology tells the system what the data actually means in the real world.
Why Data Ontology Matters
The necessity of data ontology arises from the fundamental challenge of managing knowledge in a way that is both human-readable and computationally processable. According to information science standards, an ontology is more than just a data organization tool; it is a critical framework for ensuring that information is consistent, reusable, and logically sound.
1. Enabling Semantic Interoperability
The primary reason ontologies are indispensable is their ability to facilitate semantic interoperability. Traditional data systems often suffer from "semantic friction," where different applications use different terms for the same concept or the same term for different concepts. By providing a formal, shared vocabulary, ontologies allow heterogeneous systems to exchange information without losing the intended meaning. This ensures that when data moves from one system to another, the underlying knowledge remains intact.
2. Facilitating Knowledge Reuse
In information science, the ability to reuse domain knowledge is a cornerstone of efficiency. Ontologies allow organizations to codify complex domain knowledge into a modular format. Once an ontology for a specific domain (such as medicine or finance) is developed, it can be integrated into multiple projects. This prevents "reinventing the wheel" and ensures that different teams are working from the same foundational "truth."
3. Formalizing Domain Assumptions
Much of the data in modern enterprises is based on implicit assumptions held by subject matter experts. Data ontology makes these assumptions explicit. By defining the formal constraints and axioms of a domain, ontologies reduce ambiguity. For example, an ontology can explicitly state that "a person cannot be both a buyer and a seller in the same transaction," allowing the system to automatically flag data entry errors or logical inconsistencies that a standard database might miss.
4. Automated Reasoning and Inference
Unlike a static database, a data ontology is "executable" via formal logic. Because ontologies use standardized languages like OWL (Web Ontology Language), they enable machines to perform automated reasoning. This means the system can infer new relationships and facts that were never explicitly entered into the database. This capability is vital for complex tasks like fraud detection, clinical diagnosis, and advanced search, where the computer must "connect the dots" between disparate pieces of information.
5. Separating Domain Knowledge from Operational Logic
Ontologies provide a layer of abstraction that separates the knowledge of a domain from the software code used to process it. In traditional software development, hard-coding business rules into the application makes the system brittle and difficult to change. By moving these rules into an ontology, organizations can update their business logic or domain definitions without rewriting the entire software stack, leading to much higher architectural flexibility.
6. Bridging the Gap Between Humans and Machines
Finally, ontologies serve as a bridge between human conceptualization and machine processing. They represent a domain in a way that is intuitive for experts to define, yet structured enough for algorithms to parse. This shared understanding is the backbone of the "Semantic Web" and is essential for the development of intelligent agents that can navigate and interpret the vast, unstructured landscape of modern digital information.
How Data Ontology Works
Data ontology operates by transforming raw data into a machine-executable knowledge base through a layered approach of semantic modeling and formal constraints. Unlike a traditional database that stores values in rows and columns, an ontology functions by defining a formal specification of a conceptualization.
1. Establishing the Conceptual Framework (Classes and Hierarchy)
The process begins by identifying the "Classes" (or Concepts) within a domain, forming a structured hierarchy. For example, in a financial ontology, a "Transaction" may be a general class, while "Wire Transfer" is a more specific subclass. This hierarchy enables inheritance, where subclasses automatically acquire properties from their parent concepts.
2. Defining Semantics through Properties and Relationships
To express how entities interact, ontologies define relationships and attributes. These can be represented in different underlying data models:
- In RDF-based systems, relationships are typically expressed as triples (Subject → Predicate → Object), forming a graph of linked data.
- In labeled property graph (LPG) systems, the same semantics are represented using nodes, edges, and properties, where both nodes and relationships can carry attributes.
Both approaches capture the same core idea: entities are connected through well-defined relationships, forming a semantic graph. The choice between RDF and LPG is therefore an implementation decision, not a conceptual requirement of ontology itself.
3. Applying Formal Constraints and Axioms
What distinguishes an ontology from a simple graph model is the use of axioms: formal rules that constrain how data can be structured and interpreted. These rules encode domain logic, such as:
- Symmetry (if A is related to B, then B is related to A)
- Transitivity (if A relates to B, and B to C, then A relates to C)
- Exclusivity constraints between concepts
These constraints can be enforced regardless of the underlying representation, whether RDF-based or property-graph-based.
4. Reasoning and Inference
A key capability of ontologies is enabling systems to derive new knowledge from existing data:
- Consistency checking: ensuring no data violates defined rules
- Classification: assigning entities to appropriate classes
- Relationship inference: uncovering implicit connections
In RDF ecosystems, this is typically handled by OWL reasoners. In property graph systems, similar capabilities can be implemented through rule engines, graph algorithms, or application-level logic. While the mechanisms differ, the goal remains the same: making data logically interpretable and extensible.
5. Identity and Global Referencing
To maintain consistency across systems, ontologies require stable identifiers for entities and concepts:
- RDF commonly uses URIs for global uniqueness
- Property graph systems may use internal IDs or externally managed identifiers
The key principle is not the identifier format itself, but ensuring that each concept maps unambiguously to a real-world meaning across systems.
Types of Data Ontologies
According to foundational principles in information science, ontologies are typically categorized into a hierarchy based on their level of abstraction and the scope of the domain they cover. Understanding these types is essential for determining how knowledge can be shared or reused across different systems.
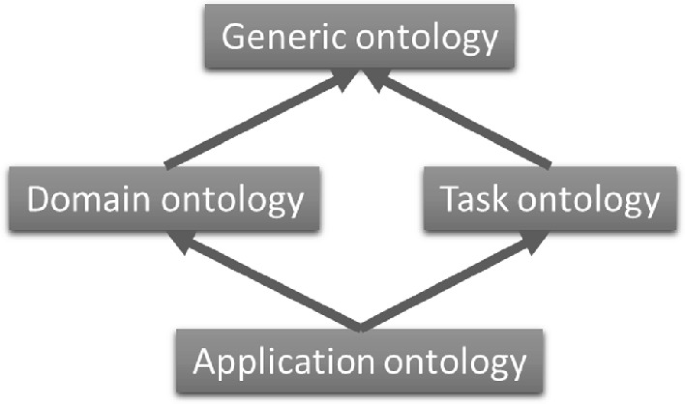
1. Upper Ontologies (Top-Level/Generic Ontologies)
Upper ontologies describe very general concepts that are common across all domains. They provide a foundational structure for more specific ontologies to build upon. These ontologies define abstract entities such as "Object," "Event," "Time," "Space," and "Process."
- Purpose: To support broad semantic interoperability between different domain-specific systems.
- Examples: Suggested Upper Merged Ontology (SUMO) and Basic Formal Ontology (BFO).
2. Domain Ontologies
A domain ontology represents knowledge within a specific area of interest, such as healthcare, finance, or engineering. It defines the vocabulary related to that specific part of the world, including the particular classes and relationships that exist within it.
- Purpose: To provide a shared understanding of a specific industry or field so that data can be exchanged between specialized organizations.
- Examples: SNOMED CT (for clinical terminology) or Gene Ontology (for biological research).
3. Task Ontologies
Task ontologies describe the vocabulary related to a specific activity or task. While a domain ontology describes the "what" (entities), a task ontology describes the "how" (processes). For instance, a "diagnosis task" ontology would define the steps and logic required to identify a disease, regardless of whether the domain is medical or mechanical.
- Purpose: To formalize the logic of problem-solving and workflow processes.
4. Application Ontologies
These are the most specific types of ontologies. An application ontology contains the concepts necessary to support a particular software application or specific use case. It often combines elements from both domain and task ontologies to suit a very narrow purpose.
- Purpose: To function as the semantic layer for a specific piece of software or a local business process.
5. Interface Ontologies
Often used in complex systems, interface ontologies sit between two different software modules. They define the concepts required for these two specific points of contact to communicate, often acting as a translation layer between different internal data structures.
Summary Table: Comparison of Ontology Types
By utilizing this hierarchical approach, organizations can ensure that their data is not only understood within a single application but can also be mapped upward to broader standards, facilitating global data integration.
Real-World Examples of Data Ontology
To appreciate the impact of ontologies, we must look at industries where semantic precision is a matter of life, death, or global financial stability. By moving beyond simple storage into Knowledge Management, these sectors allow computers to reason about the information they hold.
Healthcare: SNOMED CT & Gene Ontology
In medicine, integrating data from disparate sources is a non-negotiable requirement. SNOMED CT provides a multilingual, ontological framework for clinical terms (e.g., linking "Infection" to its "Causative Agent"). This ensures a patient's record is interpreted identically by a local GP or a specialist across the globe. Similarly, the Gene Ontology (GO) standardizes biological functions across species, enabling researchers to link genetic data to specific cellular processes globally.
Finance: FIBO
Financial markets often suffer from "semantic friction" where different banks define the same asset differently. The Financial Industry Business Ontology (FIBO) serves as the authoritative model for financial instruments and entities. By providing a shared semantic layer, FIBO ensures regulatory transparency and allows institutions to track systemic risk: a direct response to the data silos that exacerbated the 2008 financial crisis.
The Semantic Web: Schema.org
Perhaps the most ubiquitous example is Schema.org. Collaborative efforts by Google, Bing, and Yahoo! created this ontology to help search engines understand web content. When you see a "rich snippet", like a recipe's rating or a product's price, you are seeing an ontology in action, explicitly telling machines what a string of numbers actually represents.
Data Ontology in AI and Machine Learning
In the AI landscape, data ontology acts as the formal bridge transitioning systems from simple pattern recognition to deep semantic understanding. It provides the logical scaffolding that allows machines to handle information in a way that mimics human conceptualization.
Enhancing Context and Feature Engineering
Traditional Machine Learning models often treat data as isolated vectors: numbers without inherent meaning. Ontologies infuse these models with domain context through "semantic feature engineering." By knowing that a "Chronic Cough" is a subclass of "Respiratory Symptoms," a model doesn’t have to learn basic domain logic from scratch. This significantly reduces the volume of training data required for high accuracy.
Enabling Neuro-Symbolic AI
A major trend in modern AI is Neuro-Symbolic AI, which pairs the statistical power of neural networks with the logical rigor of ontologies. While the neural network identifies patterns, the ontology acts as a "rational guardrail," using formal axioms to ensure that the AI’s predictions are logically consistent with real-world knowledge and business constraints.
A Unified Foundation for Training
By acting as a semantic mediator, ontologies aggregate heterogeneous data into a consistent Knowledge Graph. This ensures that AI models are trained on normalized, high-quality data, preventing the "noise" caused by conflicting definitions across different data silos.
Ultimately, ontologies represent the shift from Data-Centric AI to Knowledge-Centric AI, enabling systems to move beyond mere correlation toward robust, explainable intelligence.
Data Ontology in Knowledge Graphs
While the terms are often used interchangeably, an ontology and a knowledge graph (KG) represent two different layers of a data ecosystem: the schema and the data itself.
In a Knowledge Graph, the ontology serves as the semantic blueprint or "intellectual scaffolding." If the Knowledge Graph is a library of interconnected facts, the ontology is the classification system and the rules of logic that govern how those facts can be combined.
The Relationship: Schema vs. Instance
An ontology defines the classes (e.g., Company, Person) and relationship types (e.g., works_at). The Knowledge Graph populates this structure with instances (e.g., Alice \(\rightarrow\) works_at \(\rightarrow\) AMD).
Why Ontologies are Critical for Knowledge Graphs
- Data Validation: The ontology acts as a "guardrail," ensuring that data ingested into the graph adheres to predefined logical constraints (e.g., a City cannot be a Person).
- Inferencing and Discovery: By using the formal logic within an ontology (like transitivity), a Knowledge Graph can uncover "hidden" relationships. If \(A\) is a subsidiary of \(B\), and \(B\) is a subsidiary of \(C\), the graph can infer that \(A\) is also a subsidiary of \(C\) without manual entry.
- Unified Querying: Ontologies allow users to query the graph using high-level concepts rather than specific database keys, making complex data accessible to both human analysts and AI agents.
In essence, a Knowledge Graph without an ontology is just a collection of links; with an ontology, it becomes a smart, self-describing network capable of automated reasoning.
Benefits of Using Data Ontology
Applying an ontology turns data interaction from low-level, structure-based access into a semantics-driven model, shifting both humans and AI agents away from manually navigating tables and fields toward working with well-defined concepts, relationships, and constraints.
Building on this foundation, Ontology Enforcement introduces real-time validation of queries against the defined ontology, acting as a gatekeeper to ensure that both human-written and AI-generated queries conform to the structural and logical rules of the security domain.
Ontology Enforcement for AI Agents
In complex data environments, AI agents can generate queries that are syntactically valid but semantically incorrect. For example, an agent may correctly join two tables while relying on a relationship that does not exist in reality. Ontology enforcement serves as a guardrail by constraining queries to a validated model of how data is actually connected, preventing these subtle but critical errors.
Standard database error messages often lack meaningful semantic context. With ontology enforcement, invalid operations return structured, LLM-readable explanations that describe why a query violates the data model. This enables the agent to adjust its behavior and progressively learn the underlying logic of the environment through fine-tuning or reinforcement learning.
Data Access with AI Assistant
With these capabilities in place, PuppyGraph provides a seamless, agent-driven interface for interacting directly with data through its built-in AI assistant. This assistant allows both developers and business users to explore complex datasets through intuitive, conversational queries.
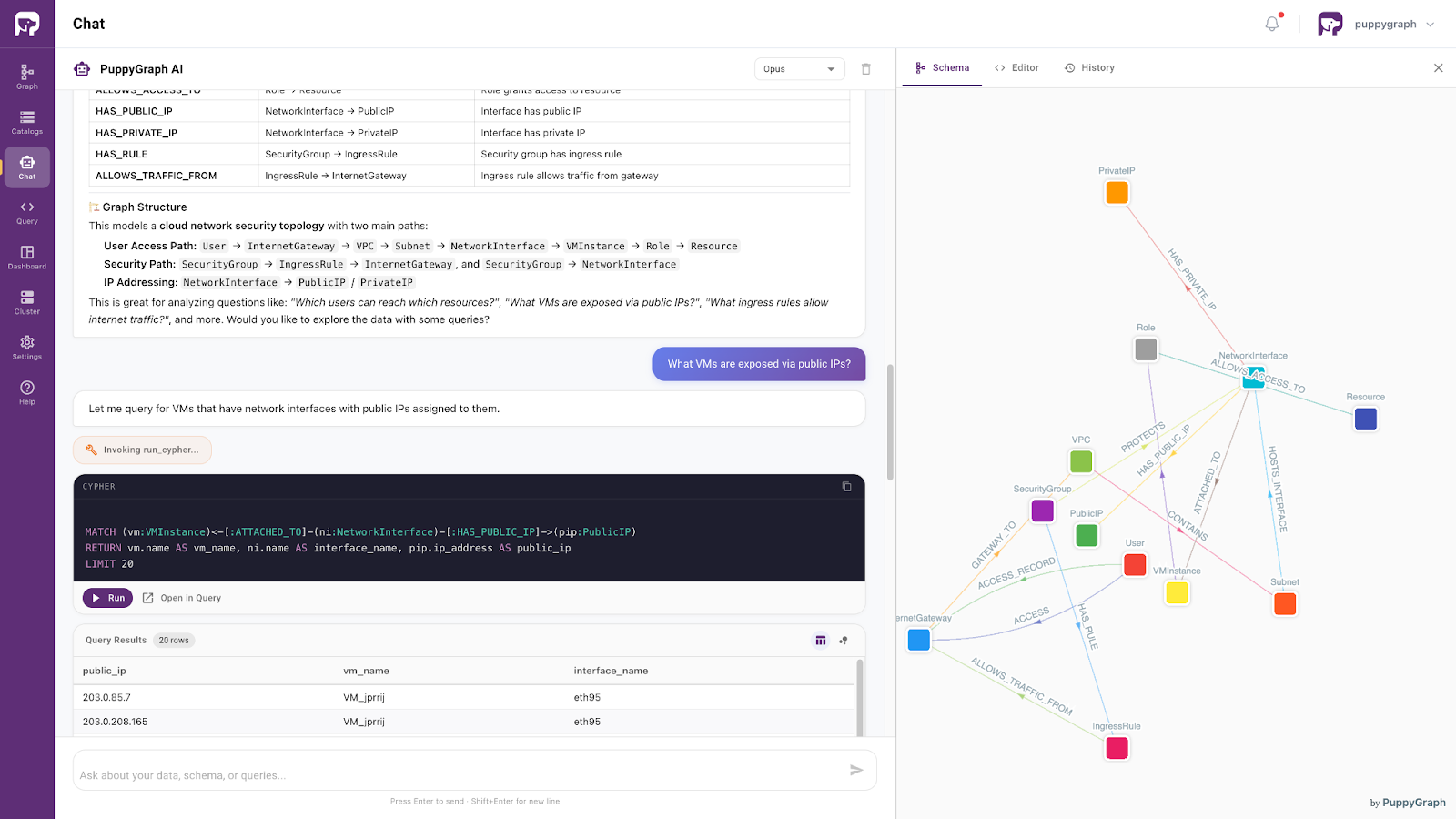
Built on an ontology-enforced foundation, the assistant enables precise, natural language-based data access. By interpreting user intent within a well-defined semantic context, it retrieves relevant information accurately and consistently. As a result, the database is transformed from a static, technically complex system into an interactive and responsive knowledge layer, one that maintains semantic integrity while delivering clear, human-readable insights.
Conclusion
Data ontology provides the semantic foundation that transforms fragmented, heterogeneous data into a unified and meaningful knowledge system. By explicitly defining entities, relationships, and constraints, it enables systems not only to exchange data, but to interpret it consistently. This shared understanding is critical for supporting interoperability, knowledge reuse, and automated reasoning, especially in complex, multi-source environments.
As data ecosystems evolve toward AI-driven and knowledge-centric architectures, ontology becomes a key enabler of both accuracy and scalability. From powering knowledge graphs to guiding AI agents through ontology enforcement, it ensures that data interactions remain logically sound and context-aware. Ultimately, data ontology bridges the gap between human understanding and machine intelligence, turning raw data into actionable insight.
Explore more with the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install