
What is DFS in Graph?
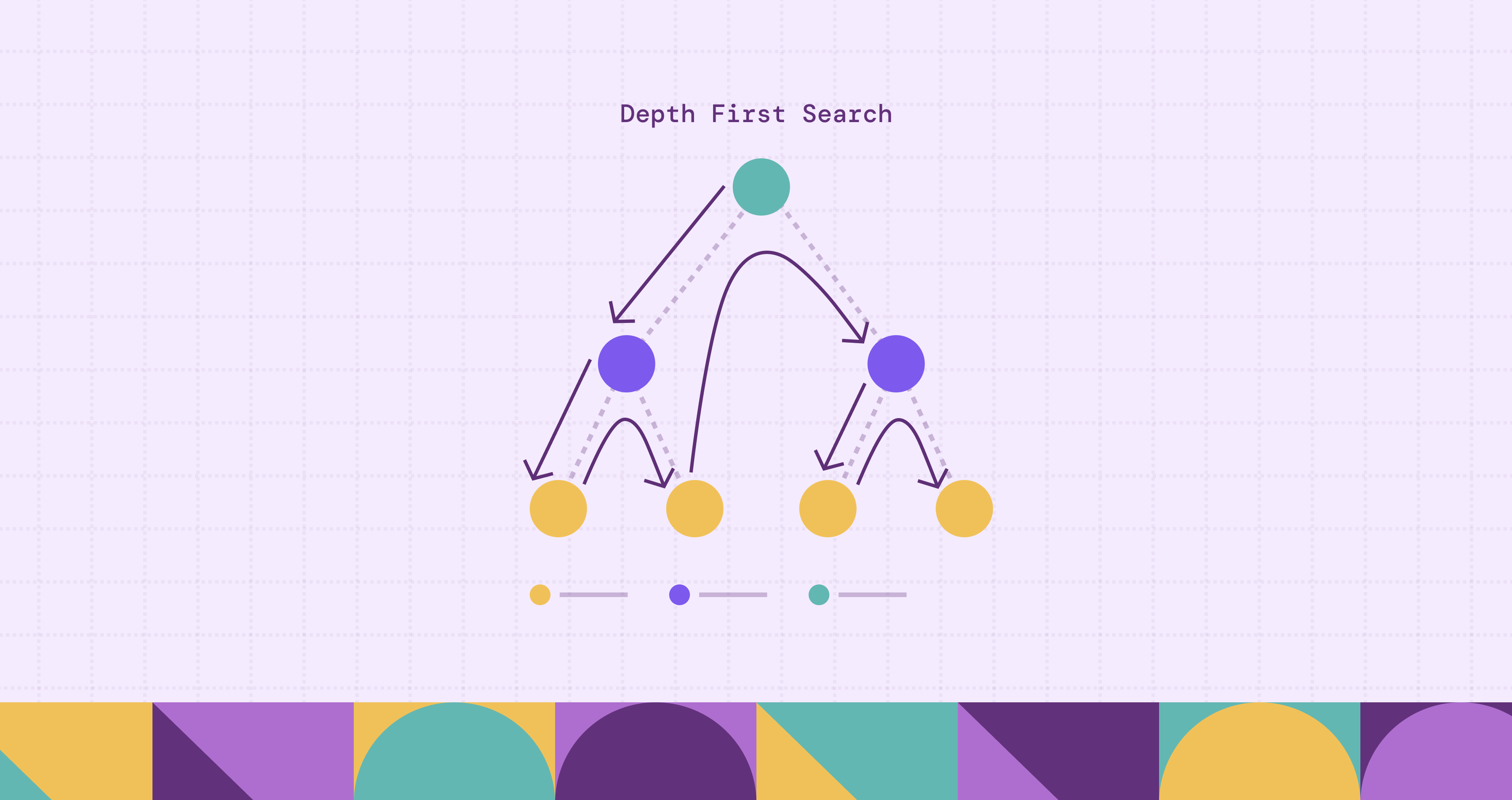
Depth-First Search (DFS) is one of the most fundamental techniques for exploring graphs. It works by traversing each branch as deeply as possible before backtracking. This strategy allows the algorithm to uncover structural properties of graphs efficiently, making it useful in a wide range of applications such as cycle detection, pathfinding, and strongly connected component analysis.
In this guide, we will explore how DFS works in detail. We will examine the core concepts behind the algorithm, walk through its step-by-step traversal process, implement it using both recursion and an explicit stack, and analyze its time and space complexity. We will also discuss real-world applications and highlight the advantages and limitations of this essential graph algorithm.
What Is DFS in Graphs?
Depth-First Search (DFS) is a graph traversal algorithm used to visit all vertices of a graph in a systematic way. The key idea behind DFS is simple: start from a chosen node and explore as far as possible along each branch before backtracking to explore other branches.
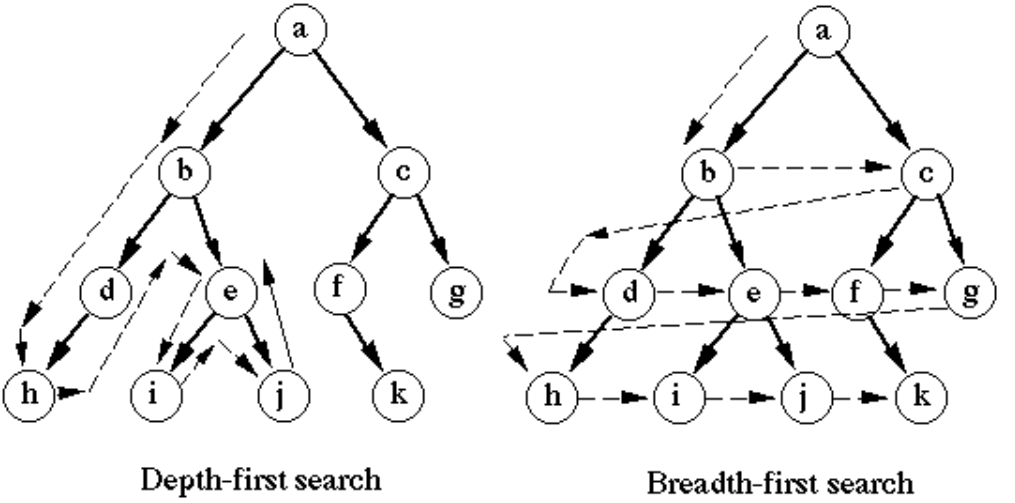
Unlike breadth-first search (BFS), which explores nodes level by level, DFS prioritizes depth over breadth. When the algorithm visits a node, it immediately moves to one of its unvisited neighbors and continues this process until it reaches a node with no unvisited neighbors. At that point, the algorithm backtracks to the previous node and continues exploring other unexplored paths.
DFS can be applied to both directed graphs and undirected graphs, and it works equally well for graphs represented as adjacency lists or adjacency matrices. Because it follows paths deeply before exploring alternatives, DFS naturally produces traversal trees that reflect the deep structure of the graph.
The algorithm is fundamental in graph theory and computer science because many advanced graph algorithms rely on DFS as a building block. Examples include topological sorting, strongly connected component detection, and articulation point analysis.
Core Concepts of Depth-First Search
To understand DFS fully, it is important to examine several core ideas that define how the algorithm behaves. These concepts explain how the algorithm keeps track of visited nodes and how it explores graph structures efficiently.
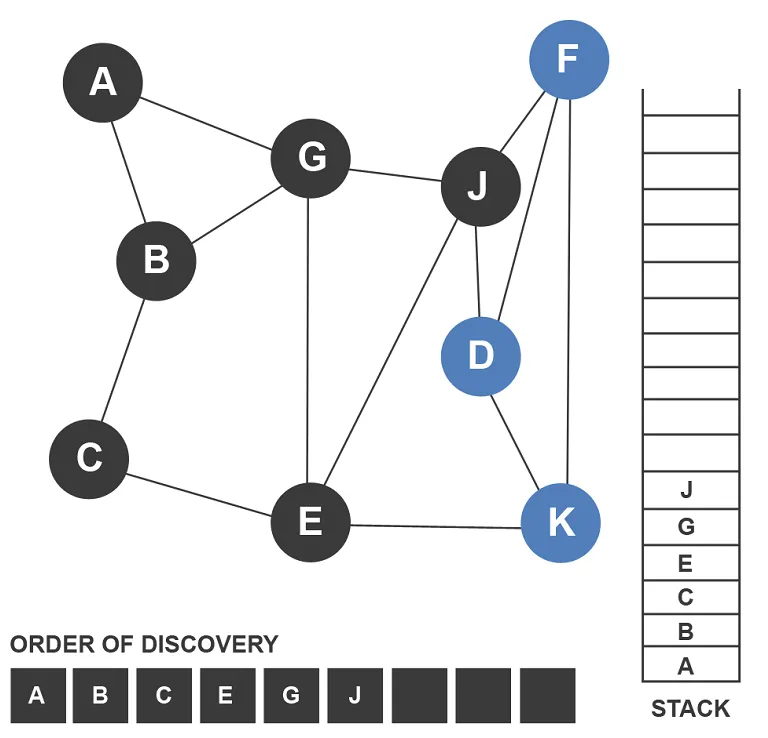
One important concept is the visited set. Since graphs may contain cycles, a DFS algorithm must remember which nodes it has already explored. Without this mechanism, the algorithm could enter an infinite loop by repeatedly visiting the same vertices.
Another essential concept is backtracking. DFS continues exploring a path until it cannot go any deeper. When a dead end is reached, the algorithm backtracks to the previous node and explores alternative branches. This process continues until every reachable vertex has been visited.
DFS also implicitly or explicitly maintains a stack structure. When implemented recursively, the programming language's call stack automatically handles this. In iterative implementations, a manual stack data structure is used to track which nodes should be explored next.
Finally, DFS naturally generates DFS trees or forests. When the algorithm begins at a starting node, the edges used during traversal form a tree. If the graph is disconnected, running DFS from multiple starting nodes creates a forest of DFS trees.
How the DFS Algorithm Works
The DFS algorithm operates by systematically exploring nodes and edges while ensuring that each vertex is visited exactly once. The algorithm typically begins by selecting a starting vertex and marking it as visited.
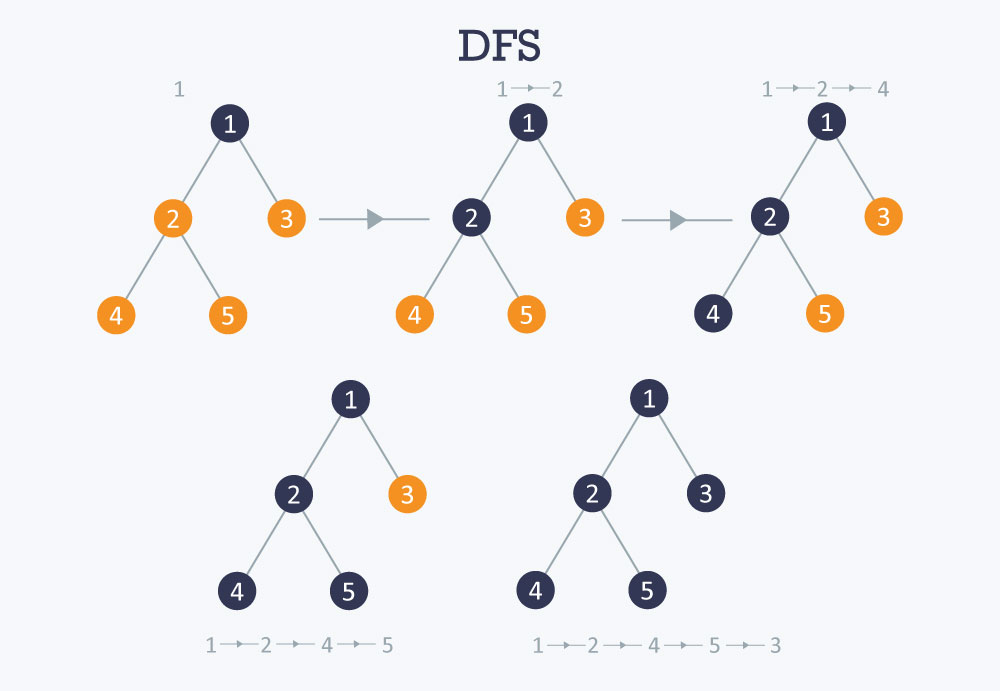
From this starting node, DFS chooses one of its adjacent vertices that has not yet been visited. It then moves to that vertex and repeats the process. This recursive exploration continues deeper and deeper into the graph structure.
If the algorithm reaches a vertex whose neighbors have all been visited, it backtracks to the previous vertex in the path. It then checks whether that vertex has other unexplored neighbors. If it does, DFS continues along the new branch. If not, it continues backtracking.
The traversal ends when every vertex reachable from the starting node has been visited. If the graph contains multiple disconnected components, DFS must be restarted from an unvisited node to ensure the entire graph is explored.
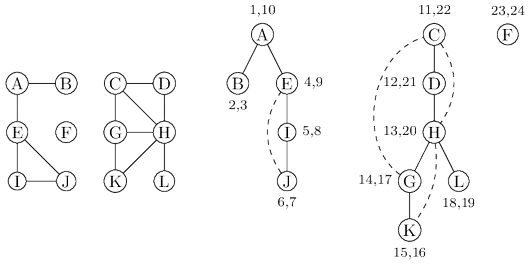
DFS Graph Traversal Step-by-Step
To better understand DFS, consider how the algorithm explores a graph step by step. Suppose we start from a node labeled A in a graph with several connected vertices.
Initially, the algorithm marks node A as visited. It then examines its neighbors and chooses one that has not yet been visited. Suppose the next node is B. DFS moves to B and marks it as visited.
From node B, the algorithm again selects an unvisited neighbor, such as D, and continues deeper into the graph. This process repeats until the algorithm reaches a node with no unvisited neighbors. At that moment, DFS begins to backtrack.
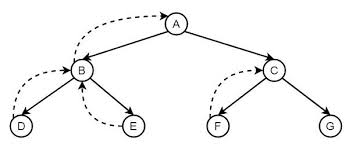
Backtracking occurs when the algorithm returns to the most recent node with unexplored neighbors. From that node, DFS selects a new neighbor and continues the traversal. This strategy ensures that every path in the graph is explored thoroughly.
The traversal continues until all reachable nodes have been visited. If some vertices remain unvisited because the graph is disconnected, the algorithm restarts from one of those vertices. The overall result is a complete exploration of the graph structure.
Recursive Implementation of DFS
One of the most common ways to implement DFS is through recursion. Recursive DFS leverages the call stack of the programming language to automatically manage the exploration of graph paths.
In a recursive implementation, the algorithm defines a function that processes a node and then recursively calls itself on each unvisited neighbor. The function first marks the node as visited and then iterates through its adjacency list.
Here is a simple Python implementation of recursive DFS:
def dfs_recursive(graph, node, visited=set()):
if node not in visited:
visited.add(node)
print(node) # Process the node
for neighbor in graph.get(node, []):
dfs_recursive(graph, neighbor, visited)In this implementation, the visited set prevents the algorithm from revisiting nodes. The recursion naturally handles the depth-first behavior because each function call explores deeper into the graph before returning.
Recursive DFS is elegant and easy to implement. However, it relies on the call stack, which may cause stack overflow errors if the graph is extremely deep. For very large graphs, an iterative implementation is often preferred.
Iterative DFS Using Stack
DFS can also be implemented iteratively using an explicit stack data structure. This approach avoids the limitations of recursion and provides greater control over memory usage.
In the iterative version, a stack is used to track which nodes should be explored next. The algorithm begins by pushing the starting node onto the stack. While the stack is not empty, the algorithm pops a node, processes it, and pushes its unvisited neighbors onto the stack.
Below is an example implementation in Python:
def dfs_iterative(graph, start):
# Non-recursive DFS where stack maintains current path from root
visited = set()
stack = [start] # Stack represents current path from root
while stack:
node = stack.pop() # Pop current node
if node not in visited:
visited.add(node)
print(node) # Process node
stack.append(node) # Push back to maintain path
# Find first unvisited neighbor
for neighbor in reversed(graph.get(node, [])):
if neighbor not in visited:
stack.append(neighbor) # Push to extend path
# If already visited, node is already popped (backtrack)This implementation produces the same traversal behavior as recursive DFS. The stack ensures that the most recently discovered node is explored first, preserving the depth-first exploration pattern.
Iterative DFS is particularly useful when working with large graphs or environments where recursion depth is limited.
To try out the the Python code above, you can add on the following code snippet:
if __name__ == "__main__":
graph = {
'A': ['B', 'C'],
'B': ['D', 'E'],
'C': ['E'],
}
print("dfs_iterative:")
dfs_iterative(graph, 'A')
print("dfs_recursive:")
dfs_recursive(graph, 'A')Time and Space Complexity of DFS
Analyzing the complexity of DFS helps us understand its efficiency and scalability. In most graph representations, DFS runs in linear time relative to the size of the graph.
For a graph with \(V\) vertices and \(E\) edges, the time complexity of DFS is:
\[O(V + E)\]
This is because each vertex is visited at most once, and each edge is considered at most once during the traversal. This complexity holds regardless of whether DFS is implemented recursively or iteratively.
The space complexity of DFS is generally \(O(V + E)\), corresponding to the storage needed for the graph representation itself. Additionally, DFS requires memory for a "visited" marker for each vertex (or edge, in some applications), which uses \(O(V)\) space. The stack used in DFS (explicit or recursive) adds at most \(O(V)\) extra space, but this does not dominate the overall memory usage in most graph representations.
It is worth noting that DFS on a graph differs from general search problems, such as solving the N-Queens problem. In general search problems, the state space forms a tree, so no “visited” marker is needed, and each path is explored independently. In contrast, DFS on a graph must mark each vertex once to avoid revisiting nodes, which adds extra memory overhead for the visited set and affects stack usage.
Applications of DFS in Graph Algorithms
DFS serves as the foundation for many advanced algorithms used in graph theory and computer science. Because the algorithm systematically explores paths in depth, it reveals structural properties that are difficult to detect using other traversal methods.
One important application of DFS is cycle detection. In directed graphs, DFS can detect cycles by tracking nodes currently in the recursion stack. This technique is widely used in dependency analysis and scheduling problems.
DFS is also essential for computing strongly connected components in directed graphs. Algorithms such as Kosaraju’s and Tarjan’s rely heavily on DFS traversal to group vertices that are mutually reachable.
Another important application is topological sorting, which orders the vertices of a directed acyclic graph according to dependency relationships. DFS makes it possible to compute this ordering efficiently.
Beyond theoretical algorithms, DFS is used in practical systems such as maze solving, puzzle generation, network analysis, and file system traversal. Its ability to explore paths deeply makes it particularly effective in search and exploration problems.
Advantages and Limitations of DFS
Depth-First Search offers several important advantages that make it widely used in graph algorithms. First, the algorithm is conceptually simple and easy to implement. Both recursive and iterative implementations require only a few lines of code.
Another advantage is its low memory overhead compared to breadth-first search in many cases. Because DFS explores one branch at a time, it may store fewer nodes simultaneously, especially in graphs with high branching factors.
DFS is also highly adaptable. Many complex algorithms in graph theory are built on top of DFS, making it a powerful foundation for solving advanced problems.
However, DFS also has some limitations. Because the algorithm dives deeply into the graph before exploring alternatives, it does not guarantee the shortest path between nodes. For shortest-path problems in unweighted graphs, BFS is usually the better choice.
Another limitation arises in extremely deep graphs. Recursive implementations may exceed the call stack limit, leading to runtime errors. Iterative implementations can mitigate this issue, but they still require careful memory management.
Conclusion
Depth-First Search (DFS) is a fundamental and versatile graph traversal technique that explores nodes by following each path as deeply as possible before backtracking. Through concepts such as the visited set, backtracking, and stack-based execution, DFS provides a systematic way to fully explore graph structures. Its linear time complexity and flexibility in both recursive and iterative forms make it an efficient and practical choice for a wide range of problems.
Beyond basic traversal, DFS serves as a cornerstone for many advanced graph algorithms, including cycle detection, topological sorting, and strongly connected component analysis. While it does not guarantee shortest paths and may face limitations in very deep graphs, its simplicity and power make it an essential tool in both theoretical and real-world applications.
Explore more with the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.


