

Federated Database: Architecture & Benefits

In practice, enterprise data is rarely stored in one neatly organized place. Instead, data is scattered across cloud platforms, on-premises systems, SaaS tools, and legacy databases. As businesses grow, so does the complexity of accessing and integrating this data efficiently. Traditional approaches, such as centralizing all data into a warehouse, can introduce latency, duplication, and governance challenges.
A federated database offers an alternative paradigm. Rather than moving data into one place, it enables unified access across distributed data sources while leaving the data where it resides. This architectural approach has become increasingly relevant in the era of real-time analytics, multi-cloud environments, and data sovereignty requirements. In this article, we explore how federated databases work, their architecture, advantages, limitations, and when they make the most sense.
What is a federated database?
A federated database system consists of multiple independent data sources and a virtualization layer that provides a unified interface for querying and interacting with them as if they were a single system. Unlike centralized architectures, it does not require data to be physically consolidated into a single repository.
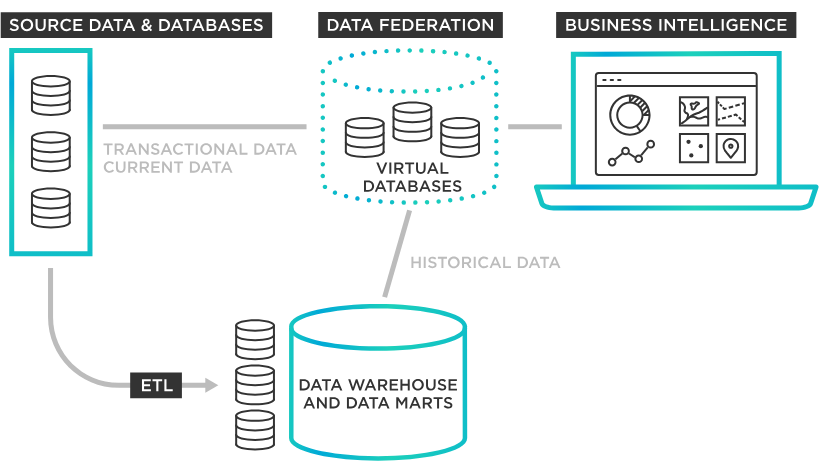
This concept is often referred to as data federation or virtual data integration. The key idea is abstraction: users or applications can query diverse data sources, such as relational databases, NoSQL stores, APIs, or cloud services, without needing to understand their underlying structures or locations.
Federated databases typically rely on a middleware layer that translates queries into source-specific operations. This layer handles schema mapping, query optimization, and data merging, allowing the system to present a cohesive result set.
The approach is especially useful in environments where data cannot or should not be moved, such as systems with strict compliance requirements, large-scale datasets, or frequently changing data sources. By avoiding replication, federated databases reduce storage overhead and ensure that users always access the most up-to-date data directly from the source.
How does a federated database work?
At its core, a federated database works by intercepting user queries and distributing them across multiple underlying data sources. The process begins when a user submits a query to the federated layer, typically using a standard query language like SQL.
The federated engine parses the query and determines which data sources are relevant. It then decomposes the query into smaller subqueries tailored to each source’s capabilities. These subqueries are executed independently on their respective systems.
Once the data is retrieved, the federated system performs operations such as joins, aggregations, and filtering to combine the results into a unified output. This process is often optimized to minimize data movement and reduce latency.
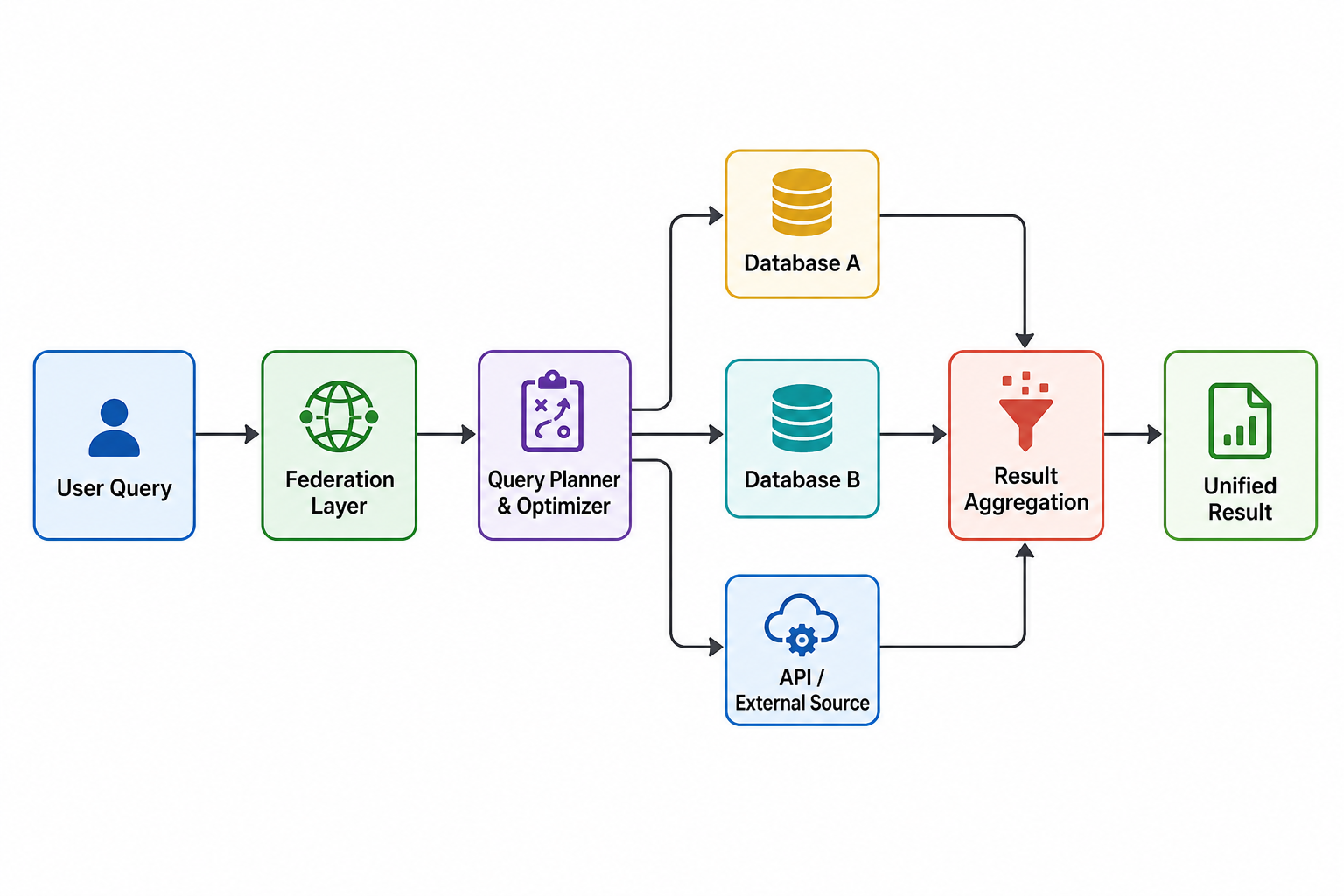
The federation layer is responsible for several critical functions, including schema translation, query optimization, and result integration. It often maintains metadata about each data source, such as schemas, capabilities, and connection details.
Performance optimization is a major challenge in federated systems. Techniques such as predicate pushdown and caching are commonly used to improve efficiency. These methods ensure that as much computation as possible happens at the data source rather than in the federation layer. Federated systems can also improve efficiency through parallel query execution, where queries are decomposed into independent subqueries that run concurrently across multiple data sources, or within a single source in some cases. Performance also depends heavily on the computational capabilities of the underlying sources, such as their indexing capabilities for accelerating scans.
Federated databases vs centralised databases
Assuming the data is already available across different sources, both architectures aim to provide efficient access to data, but they differ significantly in how they handle storage, execution, governance, and scalability. The table below highlights some of the key differences between centralized and federated database systems.
Benefits of using a federated database
One of the most significant advantages of federated databases is their ability to provide real-time access to distributed data. Because data is queried directly from its source, there is no need to wait for batch processing or ETL pipelines. This enables faster decision-making and more up-to-date insights.
Another key benefit is reduced data duplication. By avoiding the need to copy data into a central repository, organizations can save on storage costs and reduce the risk of inconsistencies. This is particularly valuable for large datasets or systems with strict data governance requirements.
Federated databases also offer greater flexibility. New data sources can be integrated without requiring extensive data migration or restructuring. This makes it easier to adapt to changing business needs and incorporate new technologies.
Federated databases can also improve scalability by distributing query execution across multiple systems. Queries against different data sources can often run in parallel, allowing the federation layer to take advantage of the compute capacity of each underlying source. Since filtering and scanning operations are typically pushed down to the source systems, performance can benefit from source-specific optimizations such as indexing, distributed execution engines, and local caching.
Data sovereignty and compliance are additional advantages. In many industries, regulations require data to remain within specific geographic or organizational boundaries. Federated databases allow organizations to comply with these requirements while still enabling unified access.
From a customer perspective, federated systems simplify application design by providing a single interface to multiple data sources. Customers can focus on business logic rather than data integration, improving productivity and reducing complexity.
Challenges of federated databases
Federated databases also introduce several challenges. Query optimization is one of the primary challenges in federated systems. Each data source may have different capabilities, indexing strategies, and query languages. The federated layer must account for these differences when generating execution plans, which can be complex and resource-intensive.
This complexity can also lead to performance challenges. Because queries are executed across multiple distributed systems, network latency and bandwidth limitations can become major bottlenecks, especially when transferring large intermediate result sets or performing complex cross-source joins and aggregations.
Data consistency is also a concern. Since data remains distributed, ensuring that all sources are synchronized can be difficult. This can lead to inconsistencies in query results, particularly in systems with frequent updates.
Security and governance add another layer of complexity. Federated systems must coordinate access controls, auditing, and compliance policies across multiple independent data sources, each with its own permission model and credential mechanism. Enforcing fine-grained policies such as role-based access control (RBAC), row-level security, or column-level masking consistently across heterogeneous systems can be difficult. Any mismatch between federation-layer policies and source-level enforcement can introduce security gaps or compliance risks.
When should you use a federated database?
A federated database is particularly useful in scenarios where data is inherently distributed and cannot be easily centralized. This includes organizations with multiple departments managing independent systems, companies operating across regions with strict data residency requirements, or businesses going through mergers and acquisitions where existing infrastructures need to remain in place. In these environments, federation provides a unified view of data without requiring immediate consolidation or large-scale migration.
It is also well-suited for real-time analytics use cases. When timely insights are critical, federated databases allow organizations to query live data without waiting for it to be replicated or transformed. This can be especially valuable in industries such as finance, healthcare, and e-commerce.
Federated databases are also beneficial for exploratory analysis. Data scientists can access multiple sources without needing to build complex pipelines, enabling faster experimentation and discovery.
The Semantic Layer: Ontology on the Virtual Layer
While a federated database provides a unified way to access distributed data, it does not inherently ensure that the data is interpreted consistently. Different systems may describe similar entities in incompatible ways, leading to ambiguity when queries span multiple sources. To address this limitation, a semantic layer can be introduced on top of the virtual federation layer.
At the core of this semantic layer is an ontology, a structured representation of concepts, entities, and relationships that defines the meaning of data rather than just its structure. Instead of interacting directly with source-specific schemas, users and applications operate on a shared conceptual model that abstracts away underlying differences.
Consider a practical scenario. Information about developers may be stored across several systems: employee records in an HR platform, code activity in a version control system, and task assignments in an issue tracking tool. Each system represents identities differently, using fields such as employee IDs, email addresses, or usernames. Within a standard federated layer, these appear as separate tables, and queries must manually reconcile them, often requiring complex joins and assumptions about how records relate.
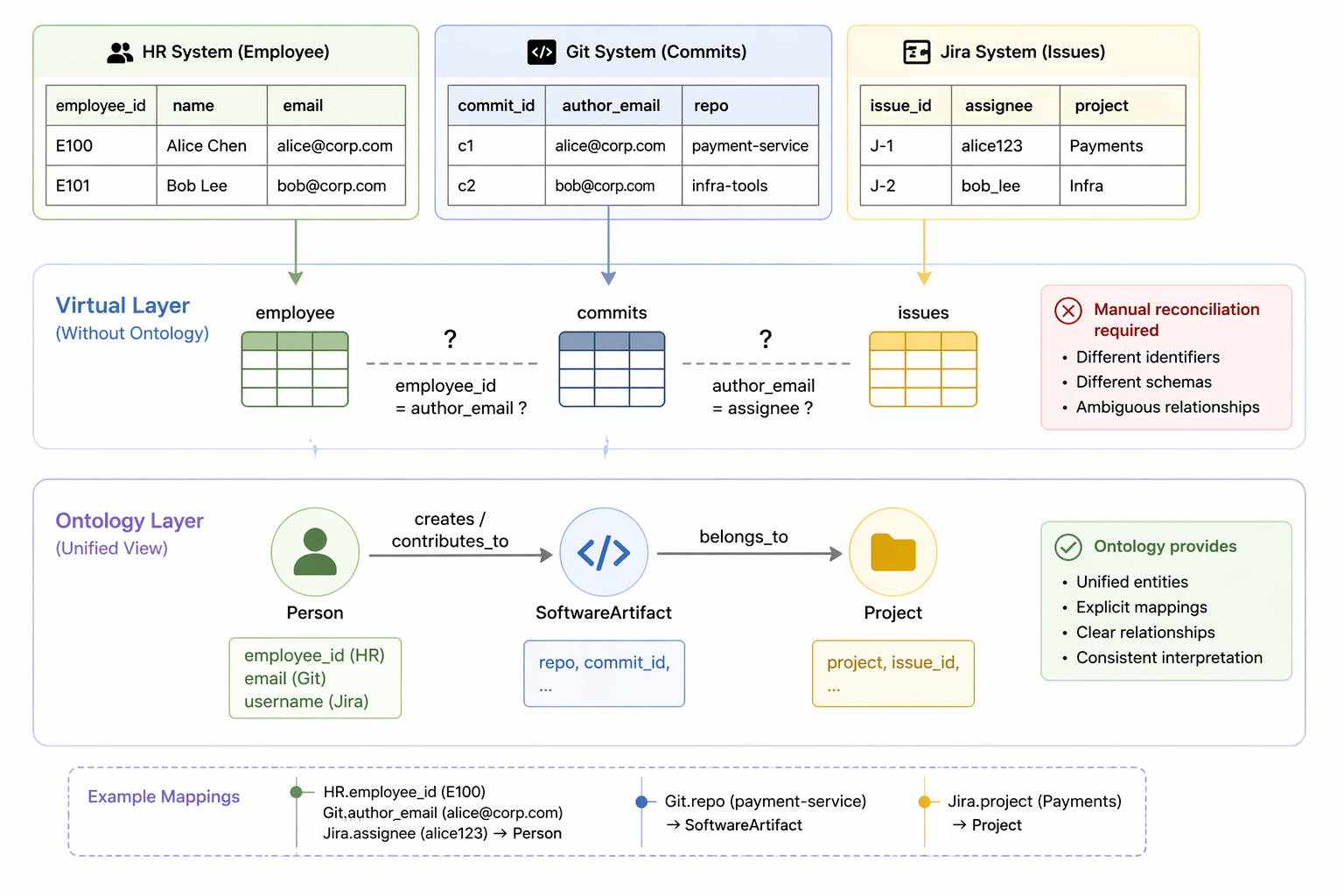
With an ontology in place, these disparate datasets are mapped into unified entities such as Person, Project, or Software Artifact, along with clearly defined relationships like contributes_to or creates. The ontology explicitly connects fields like employee IDs, emails, and usernames to a single conceptual identity. As a result, users no longer need to reason about how data is structured in each source: they interact with consistent, high-level concepts.
Ontology Enforcement
Defining a semantic model alone is not sufficient; it must also be actively enforced. In an ontology-driven system, queries are validated against the semantic layer rather than executed directly on the federated schema. Users, and increasingly, AI-driven agents, issue queries in terms of ontology-defined entities, and the system translates them into the appropriate underlying operations.
This enforcement mechanism brings several important advantages.
First, it reduces the risk of semantic errors. In distributed environments, it is possible to construct queries that are technically valid but logically incorrect: for example, joining datasets based on fields that do not represent the same real-world relationship. By constraining queries to a predefined semantic model, the system ensures that only meaningful relationships are used.
Second, it enables a feedback-driven improvement loop. When a query violates the ontology, the system can return structured, machine-readable feedback explaining the issue. This is particularly valuable for AI systems, which can use this feedback to refine future queries and better align with the underlying data model over time. These feedback signals can also be leveraged for fine-tuning or reinforcement learning, further improving model performance through continuous learning.
AI-Assisted Data Access
Building on top of the semantic layer, some modern platforms such as PuppyGraph integrate AI-driven query interfaces that allow users to interact with data using natural language. These systems rely on the ontology to ground user intent in a consistent conceptual framework, ensuring that generated queries remain accurate and meaningful.
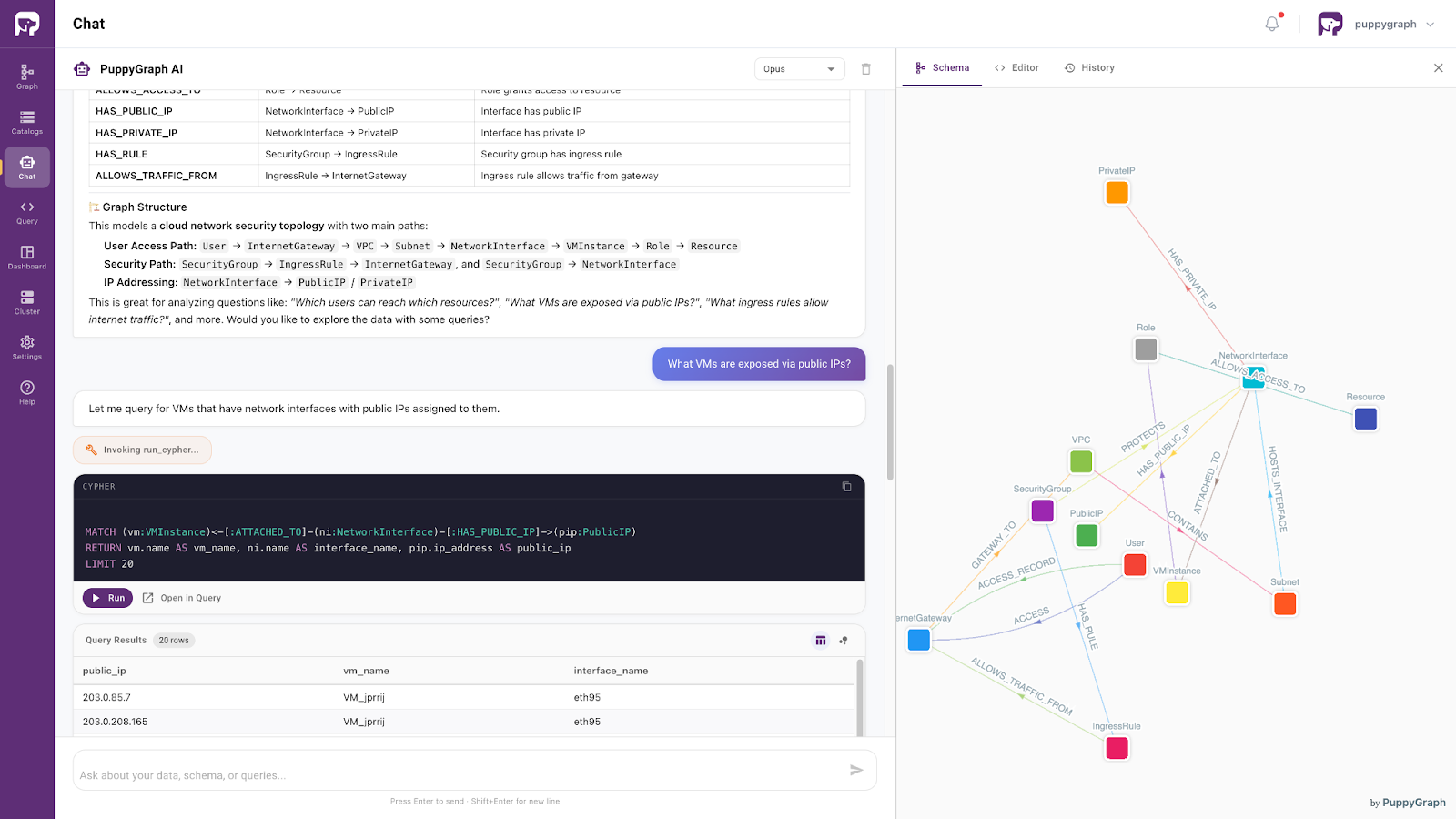
For example, in a cybersecurity context, an ontology might model relationships between users, virtual machines, network interfaces, and security controls. Rather than navigating multiple schemas, users can simply ask questions about how these entities are connected. The system interprets the request through the semantic model and executes the necessary federated queries behind the scenes.
By introducing an ontology-enforced semantic layer, federated databases evolve from a purely technical integration mechanism into a more coherent and intelligent data platform. This approach not only simplifies data access but also ensures that insights derived from distributed systems are both accurate and contextually meaningful.
Conclusion
Federated databases offer a practical alternative to traditional centralized architectures by enabling unified access to distributed data without requiring physical consolidation. This approach is increasingly important in modern data environments where information is spread across cloud platforms, on-premises systems, and third-party services. By querying data directly at its source, federation reduces duplication, improves freshness, and supports real-time analytics, while also introducing challenges around performance, query optimization, and governance.
To address ambiguity across heterogeneous systems, an ontology-driven semantic layer can be built on top of federation to provide a consistent conceptual model for data interpretation. This ensures that queries are grounded in shared business meaning rather than isolated schemas, reducing errors and improving usability. When combined with AI-assisted query interfaces, federated systems evolve into intelligent data platforms that not only unify access but also enhance understanding, enabling more accurate, scalable, and context-aware analytics across complex distributed environments.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see how ontology-driven federation can bring clarity and consistency to your distributed data.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install