

Apache Hudi vs. Iceberg: Key Differences Explained

The data lakehouse idea took off in the late 2010s as new projects brought warehouse-style guarantees to file-based lakes. Apache Hudi and Apache Iceberg are two popular approaches. Both add ACID transactions, time travel, safe schema evolution, and provide a unified storage view. However, there are differences in offerings between these two popular projects.
Hudi packages a table format with services that operate the lake. It includes ingestion utilities like DeltaStreamer and built-in jobs for compaction, cleaning, clustering, and a metadata index. These services run in Hudi’s runtime and are scheduled as part of daily operations. This makes Hudi optimized for incremental data processing to transactional data lakes.
In contrast, Iceberg centers on an open table format and a catalog that multiple engines can share. Its table services are maintenance actions you invoke through engines such as Spark or Flink, including expiring snapshots, rewriting data files or manifests, and removing orphan files. Iceberg is designed for large-scale analytics and data warehousing.
With data lakehouses being a relatively new concept, this blog begins by answering the question, what is a data lakehouse, and why are they gaining popularity? We can then look at how Apache Hudi and Iceberg tackle these problems, understanding each project on its own terms. We then compare the two and provide a brief guide on which might be the best fit for your needs.
What is a Data Lakehouse?
A data lakehouse combines the flexibility of a lake with the management and performance guarantees of a warehouse. The goal is simple: store data in open file formats on low-cost object storage, then add a transaction layer so multiple engines can read and write safely. The data lakehouse architecture consists of three components: the storage layer, the transaction layer, and the compute layer.
Storage Layer
Low-cost, scalable cloud object storage is used to hold both the data files and the table-format metadata written by Hudi or Iceberg. Data can be structured, semi-structured, or unstructured, typically stored in open formats such as Parquet or ORC. Catalogs register tables and point to the active metadata file, while engines read the metadata in storage to plan queries, prune files, and honor ACID snapshots. Because storage is decoupled from compute, you can scale capacity independently and let multiple engines read the same files directly, whether raw or processed.
Transaction Layer
Both Hudi and Iceberg live primarily in the transaction layer. It is in this layer that files on object storage are turned into reliable tables that many engines can share safely.
- Table format: Defines how data and metadata are organized, how schemas and partitions evolve, and how readers see a consistent snapshot.
- Transaction manager: Coordinates commits, detects conflicts, and enforces isolation so concurrent writers do not corrupt the table. Often works with the catalog.
- Table services: Keep tables healthy and fast. This includes file and manifest rewrites, compaction for log-structured tables, clustering or sorting, snapshot expiry, orphan file cleanup, statistics and indexing.
- Catalog: Registry for tables and namespaces. Stores table metadata, exposes APIs for discovery and permissions, and often participates in transaction coordination.
Compute Layer
Query engines and processors run the work. Batch and interactive SQL engines, streaming systems, notebooks, and BI tools connect through connectors that understand the table format so they can read and write with ACID guarantees. In a lakehouse, multiple engines share the same tables without copying data. For example, run SQL analytics in Trino and use PuppyGraph for multi-hop graph analysis on the same Hudi or Iceberg tables, with no separate graph store or ETL required.
What is Apache Hudi?

Goals of Apache Hudi
Apache Hudi is both a table format and a data management framework, built at Uber in early 2016 to make lake data usable for fast decisions at scale. Trip events were captured in operational databases, but analytics ran offline with roughly day-old freshness while a typical ride lasted minutes. Ingestion failures also caused cascading retries and cleanup. These issues would form the guiding principles in Hudi’s design:
- Incremental processing: Consume and process only new or changed records instead of recomputing entire tables, cutting latency and compute.
- Efficient upserts: Absorb upstream changes to records and process them faster in place.
- Snapshot isolation: Provide the latest committed state. Readers should see a consistent, committed snapshot rather than inflight or corrupted data.
Architecture of Apache Hudi
Apache Hudi goes beyond just a table format, offering users with open compute services for ingesting, optimizing, indexing and querying data.
Table Format
Hudi’s table format defines how data and metadata are organized so engines can read consistent snapshots, apply updates efficiently, and time-travel to past states. It tracks schema, partitions, files, and table-level statistics, and provides the structures that make upserts and deletes practical at scale.
Data is grouped into file groups with stable IDs. Each group evolves through file slices, which are logical pointers to the physical files that represent that group at a specific instant. It references a base file in Parquet or ORC, plus zero or more delta log files that capture changes since that base file was written. A delta log file is an append-only .log file. It contains a sequence of log blocks that are Avro by default but can be configured to Parquet. Hudi supports two types of tables: Copy-on-Write (CoW) and Merge-on-Read (MoR). CoW tables rewrite base files on update, while MoR tables append changes to logs and later compacts them into new base files that form new slices.
The timeline under .hoodie/ is an ordered event log of actions such as commits, deltacommits, compaction, cleaning, savepoints, and rollbacks. Alongside it, the metadata table at .hoodie/metadata centralizes metadata in a Merge-on-Read layout to reduce write amplification, storing file listings, column statistics, bloom filters, a record index, and functional indexes.
Storage Engine
The storage engine adds database-like functionality to the lake: ACID transactions, efficient upserts and deletes, and query optimization. Hudi’s indexes allow for faster upserts and deletes, offering various index types of the box such as simple indexes, bloom indexes and secondary indexes. Concurrency control commits changes atomically and provides snapshot isolation, so readers and table services see a consistent, committed snapshot while writers publish new versions in parallel. Built-in table services keep operations healthy by cleaning old file slices, compacting log files, clustering data for better locality, and maintaining indexes.
Programming API
The programming API gives direct access to Hudi’s core functions. It is a low-level integration point that lets you handle complex data scenarios, implement custom logic, and fine-tune both write and read paths. Typical extension points include custom key generators, merge logic, and indexing strategies.
User Access
These tools and languages are compatible with Hudi, allowing you to leverage Hudi’s data management capabilities while working with what you’re familiar with.
Shared Platform Components
Hudi’s shared components provide the pipeline and catalog services that allow it to function as a comprehensive data lakehouse platform, rather than just a storage format. Hudi Streamer handles streaming ingestion and synchronization with Kafka, so you can keep tables current without building custom consumers. For metadata, Hudi works with Hive Metastore and AWS Glue to register tables, manage schemas, and make datasets discoverable across engines.
For administration, Hudi offers a command-line interface for day-to-day operations and metrics integration for monitoring health and performance. A timeline metaserver exposes the table timeline over a remote API, which cuts down on direct cloud storage calls and improves the responsiveness of metadata-heavy operations. Together, these components let teams run streaming and batch pipelines, manage catalogs, and operate Hudi tables consistently across environments.
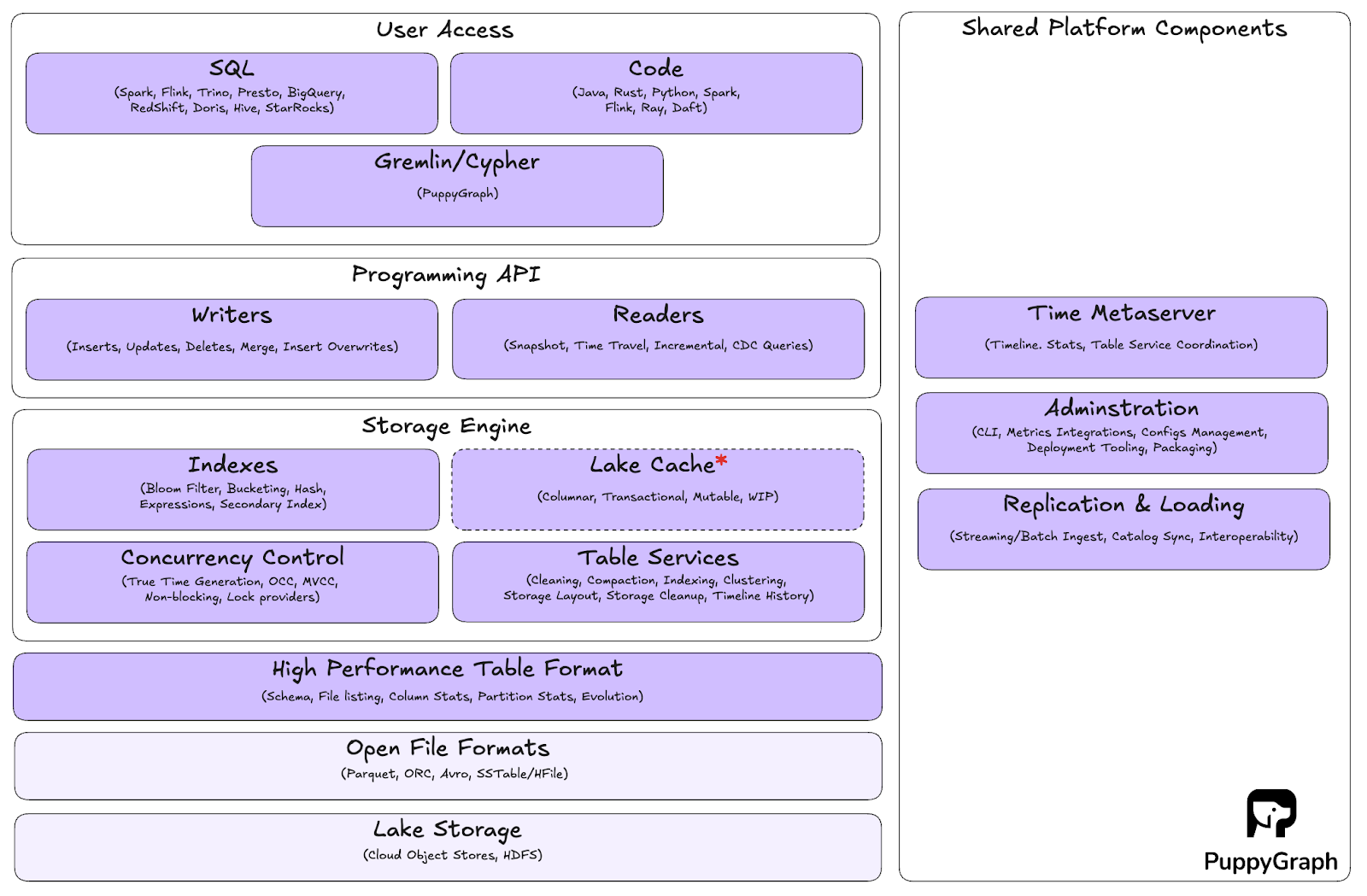
Key Features of Apache Hudi
With both Hudi and Iceberg introducing a transaction layer to the traditional data lake, they share many common features such as ACID transactions, time-travel queries and data versioning.
More unique to Hudi is its built-in ingestion and streaming capabilities. DeltaStreamer lets you load data without building custom pipelines. It can read from Kafka or files, apply deduplication and precombine logic, generate keys, and write in continuous or batch modes using insert, upsert, and delete. You can also run bulk loads to bootstrap large tables, then switch to incremental pulls to keep them fresh.
Hudi also comes with pluggable indexing for fast writes, aligning with its goal of optimizing for real-time query processing. It offers multiple index types to find target rows quickly and avoid scanning whole files. These indexes live alongside table metadata, which cuts shuffle and reduces write amplification during upserts and deletes. You choose the index strategy per table to balance speed and cost.
Of course, one of Hudi's greatest strengths lies in bringing incremental processing to both batch and streaming. Each run reads only what changed since the last commit and updates results instead of rebuilding everything. The timeline records every commit, so jobs can scan just new instants and checkpoint progress. This cuts compute cost, shortens pipelines, and improves freshness at large scale.
What is Apache Iceberg?

Goals of Apache Iceberg
Apache Iceberg is a table format that was created in 2017 by Netflix’s Ryan Blue and Daniel Weeks. It was designed as a modern replacement for Hive tables, which struggled with schema evolution, partition management, and safe concurrent writes. At large scale, these gaps made pipelines fragile and analytics unreliable. Iceberg addresses these issues with five core goals:
- Consistency: Provides reliable query results through ACID transactions and snapshot isolation, even when multiple engines access the same table.
- Performance: Improves efficiency with optimized metadata handling, partition pruning, and scan planning that reduce the cost of queries at scale.
- Ease of use: Reduces complexity with features like hidden partitioning and familiar SQL commands for table creation and management.
- Evolvability: Supports schema changes and adapts to new execution engines with minimal disruption to downstream workloads.
- Scalability: Designed to manage petabyte-scale datasets and handle concurrent access in distributed environments.
Structure of Apache Iceberg
Unlike Apache Hudi, which doubles as a data management framework with ingestion and table services, Apache Iceberg is simply a table format with a catalog interface. This separation keeps responsibilities clear and makes it easier to run the same tables across multiple engines.

Data Layer
The data layer consists of the files that hold the actual table content, typically stored in cloud or on-premises object storage. For handling deletes and updates, Iceberg’s default strategy is CoW, where new data files are created when changes occur. If a table is frequently updated, Iceberg can also use MoR. In this mode, the data layer may include delete files that track row- or position-level deletes. This approach allows updates without rewriting large datasets while still maintaining consistent query performance.
Metadata Layer
The metadata layer tracks the structure and version history of a table. These files are stored in Avro format, which is compact, schema-driven, and widely supported across languages and platforms. Because Avro embeds its own schema and has strong compatibility rules, engines can all parse the same files consistently, making the metadata layer engine-agnostic.
It is built from three key components:
- Metadata files: Define table properties, schema, partition specs, and pointers to the current snapshot.
- Manifest lists: Record which manifest files belong to a snapshot, enabling snapshot isolation and time travel.
- Manifest files: Contain detailed information about data files, such as partition values, row counts, and file-level statistics.
This layered design makes features like schema evolution, time travel, and atomic operations possible. Query engines like Trino and PuppyGraph rely on these metadata files to plan queries efficiently, pruning unnecessary files and ensuring consistent results without scanning the entire dataset.
Catalog Layer
The catalog tracks table definitions and the pointer to the current metadata file. Iceberg uses optimistic concurrency for commits: a writer reads the current pointer, stages a new metadata file, then performs an atomic compare-and-swap. If another commit wins, the update is rejected and the writer retries against the latest snapshot.
This delivers atomic commits and snapshot isolation for a single table, so readers see either the old state or the new state, never a partial write. Iceberg supports Hive Metastore, AWS Glue, JDBC, Nessie, and REST catalogs. This means that Iceberg can support custom catalogs via pluggable Java APIs or the REST Catalog protocol.
Key Features of Apache Iceberg
Iceberg uses hidden partitioning, which lets you define transforms like day(ts), bucket(id, N), or truncate(col, k) while queries keep filtering on the original columns. Engines use the stored metadata to prune partitions automatically, so SQL stays simple and user error drops. Iceberg also supports partition evolution, letting you move from day(ts) to hour(ts) or add bucket(user_id, 16) as needs change, with both layouts coexisting in one table.
Its REST Catalog API standardizes table and namespace operations over HTTP. Create, alter, list, and commit behave the same across engines, which makes multi-engine setups cleaner, reduces custom glue, and avoids tight coupling to a single metastore.
Planning is fast because engines read a metadata tree before touching data files. A manifest list points to manifests, and each manifest summarizes many data files with partition ranges and column statistics such as min, max, and null counts. Planners can skip whole manifests and files up front, and the same metadata is queryable for debugging and governance.
Apache Hudi vs Iceberg: Feature Comparison
When to Choose Apache Hudi vs Iceberg
Both Apache Hudi and Iceberg work well if you need ACID transactions, time travel and schema evolution on object storage. However, there are certain cases when you might want to choose one over the other.
When to Choose Apache Hudi
- Your workloads benefit from incremental processing. Hudi processes only what changed, so late arrivals, corrections, and backfills land quickly without full recomputes. Incremental queries, key-centric upserts, and Hudi Streamer make continuous ingestion straightforward while keeping cost and latency down.
- You need low-latency writes and can schedule background jobs. Merge-on-Read lets you append to logs and compact later.
- You want writer-side indexing to speed updates, deletes, and point lookups at large scale. Hudi’s record, Bloom, and column-stats indexes map keys to file groups, so engines touch fewer files and updates land faster.
- You prefer runtime table services in the project itself: compaction, cleaning, clustering, archival, and a timeline with savepoints.
When to Choose Apache Iceberg
- Your workloads are primarily analytical and read-heavy. Large scans and joins benefit from Iceberg’s metadata tree, per-file stats, and hidden partitioning, which let engines prune files early and plan fast.
- You run multiple engines and want consistent behavior across Spark, Flink, Trino, and others. The REST catalog and spec make interoperability predictable.
- You want simple partitioning and evolution. Hidden partitioning with transforms reduces SQL friction and lets you change the spec safely.
- Your updates are mixed append and row-level changes handled by the engine. Equality and position delete files keep one table layout and avoid log-structured data.
- You prefer maintenance as procedures in engines: expire snapshots, rewrite data files or manifests, and remove orphans.
Conclusion
Hudi and Iceberg both make lakes feel database-like, but they take different paths. Hudi packages ingestion and table services into the runtime, while Iceberg standardizes the table and catalog so many engines can share the same data safely. That scope difference explains why Hudi often feels operational and more service-rich, and Iceberg often feels interoperable and predictable across tools.
Choosing between them comes down to your workload and team shape. Pick Hudi if your pipelines benefit from incremental processing, you want native ingestion, and you can schedule background jobs to run table services. If you run multiple engines and want simple partitioning and clean governance, Iceberg is a good fit.
With the modern-day data lakehouses, compute and storage are separate, so you can pick the right engine for each workload instead of being locked to whatever ships with your storage. If you’ve wanted graph analytics but balked at the cost and overhead of a graph database, try PuppyGraph. It runs multi-hop graph queries directly on your existing Hudi or Iceberg tables, keeping one set of data. You add paths, relationships, and entity linking without extra ETL.
PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


Ready to try graph analytics on your lakehouse? Download the forever-free Developer edition or book a free demo to get started.

Jaz Ku is a Solution Architect with a background in Computer Science and an interest in technical writing. She earned her Bachelor's degree from the University of San Francisco, where she did research involving Rust’s compiler infrastructure. Jaz enjoys the challenge of explaining complex ideas in a clear and straightforward way.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install