

Knowledge Graph Memory: How It Works?
Artificial intelligence systems have become significantly better at reasoning, language generation, and decision-making. Yet one challenge remains central to building truly useful AI systems: memory. Most AI applications can process large amounts of information in a single interaction, but many still struggle to remember what happened before, connect facts over time, or build durable knowledge from repeated experiences. This limitation becomes increasingly visible as organizations move from single-turn chatbots toward persistent AI agents expected to support long-running workflows.
Knowledge graph memory addresses this problem by introducing structured, relationship-aware memory into AI systems. Instead of storing isolated text chunks or vectors, it organizes information as connected entities and relationships, allowing machines to retrieve context based not only on similarity, but also on meaning and structure. This enables richer recall, better reasoning, and more reliable long-term context management. In this article, we explore how knowledge graph memory works, what architectural components make it effective, and why it is becoming foundational for next-generation AI systems and autonomous agents.
What Is Knowledge Graph Memory?
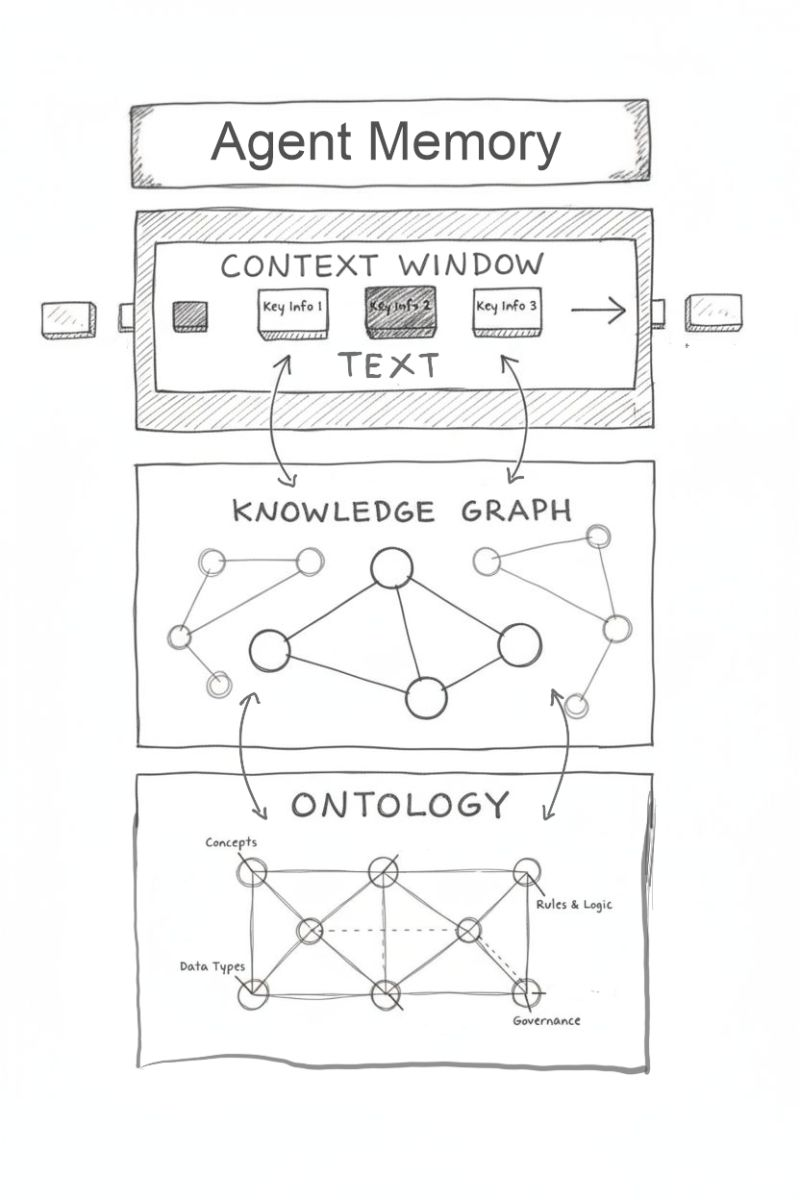
Knowledge graph memory is a memory architecture that stores information as a graph of entities, relationships, and attributes rather than as isolated documents or embeddings. In this model, each node represents an entity such as a customer, product, event, or concept, while edges describe how those entities are connected. This turns memory into a structured network that AI systems can traverse, query, and continuously update.
Traditional memory systems often treat information as independent records. A document store may know that a user mentioned a project, and a vector database may retrieve semantically similar notes, but neither inherently understands the relationships among people, actions, deadlines, and dependencies. A knowledge graph preserves those links explicitly, making contextual reasoning more precise.
This approach is especially useful when memory must persist over time. If an AI agent learns that a customer works for a particular company, manages a specific project, and previously raised a support issue, graph memory stores those facts as connected knowledge rather than disconnected notes. When the customer returns weeks later, the system can reconstruct context instantly.
Another defining feature is incremental learning. Knowledge graph memory is not static storage. It evolves as new facts arrive, relationships change, and entities are updated. This makes it ideal for dynamic environments where context is constantly shifting, such as enterprise workflows, digital assistants, and autonomous agents.
Why Memory Matters in AI Systems
Memory gives intelligence continuity. Without it, an AI system behaves like a highly capable but forgetful assistant that must relearn context in every conversation. With memory, the system can build understanding over time, recognize patterns, and improve decision quality through accumulated experience.
Large language models already have powerful short-term reasoning abilities. Their context windows allow them to process thousands of tokens at once. However, context windows are not memory. They only hold what is explicitly inserted into a prompt. Once that interaction ends, the information disappears unless an external system stores it.
This creates problems in real-world applications. A customer support agent that forgets prior tickets forces users to repeat themselves. A research assistant that loses earlier assumptions cannot sustain long analytical workflows. A coding assistant without persistent memory cannot understand project history, architecture decisions, or earlier bugs.
Memory also improves personalization. Systems that remember preferences, habits, and prior interactions can tailor recommendations and responses. This makes interactions feel more natural and reduces repetitive clarification.
Most importantly, memory supports reasoning across time. Intelligence often depends on recognizing that today’s event relates to something from yesterday, last month, or last year. That requires durable memory, not just transient context. Knowledge graph memory enables exactly that by preserving relationships across events and timelines.
How Knowledge Graph Memory Works
At a high level, knowledge graph memory transforms incoming information into structured graph data, stores it, and later retrieves relevant subgraphs to support reasoning or response generation. This process usually involves ingestion, extraction, graph construction, retrieval, and update cycles.
When new information arrives, the system first performs entity extraction. Natural language input is analyzed to identify important objects such as people, organizations, dates, goals, or events. For example, a sentence like “Alice approved the budget for Project Aurora on Friday” contains multiple meaningful entities.
The next step is relationship extraction. The system determines how those entities connect. In the example above, Alice is linked to approval, the budget is linked to Project Aurora, and the event occurred on a specific date. These relationships become graph edges.
Once entities and relationships are identified, the graph is updated. Existing nodes may be enriched with new properties, duplicate nodes may be merged, and new edges may be added. Over time, the graph becomes a living representation of accumulated knowledge.
When an AI system needs context, it queries the graph. Instead of searching only for similar words, it can ask structured questions such as: Which projects has Alice approved? What dependencies exist between these teams? Which past events relate to this issue?
The retrieved subgraph then becomes input to downstream reasoning, often inside a large language model prompt. This gives the model structured context grounded in real relationships rather than loosely matched text.
Core Components of Graph-Based Memory
A knowledge graph memory system is built from several tightly integrated components. Each contributes to making memory persistent, queryable, and useful for reasoning.
The first component is the entity model. This defines what kinds of things the system remembers. In enterprise environments, entities may include users, documents, workflows, products, and policies. In consumer applications, they might include preferences, contacts, purchases, and locations. Clear entity definitions create consistency.
The second component is the relationship schema. Relationships give memory structure. Examples include “owns,” “reports_to,” “depends_on,” “purchased,” and “mentioned_with.” These links transform isolated facts into networks of meaning.
A third component is attribute storage. Nodes and edges often carry metadata such as timestamps, confidence scores, provenance, and status. This helps systems evaluate freshness and trustworthiness.
Retrieval logic forms another critical layer. Efficient graph traversal, semantic filtering, and hybrid search methods determine what memory is surfaced at the right moment. Poor retrieval can make even a rich graph useless.
Finally, update and maintenance mechanisms keep the graph accurate. Deduplication, conflict resolution, versioning, and forgetting policies ensure the memory remains relevant instead of becoming noisy over time.
Together, these components turn graph memory into a dynamic knowledge substrate rather than a passive database.
Knowledge Graph Memory Architecture
A typical knowledge graph memory architecture contains multiple layers that work together to ingest, organize, retrieve, and reason over information.
At the ingestion layer, raw inputs arrive from conversations, documents, APIs, sensors, or application events. These inputs may be structured or unstructured. The system must normalize them before storage.
The processing layer performs natural language understanding, entity recognition, relation extraction, and canonicalization. This is where text becomes graph-ready data. Advanced systems may also assign confidence scores and detect ambiguity.
The storage layer holds the graph itself, often inside a graph database. Popular implementations use labeled property graphs or RDF-based stores. The choice depends on scale, query patterns, and interoperability requirements.
The retrieval layer exposes graph access through traversal queries, semantic search, and hybrid ranking methods. Some architectures combine graph retrieval with vector search, using embeddings to identify candidate nodes before graph expansion.
The orchestration layer determines when and how memory is used. It decides whether a current request needs prior context, what graph neighborhood should be retrieved, and how much information to pass to the reasoning model.
At the reasoning layer, a large language model or decision engine consumes retrieved graph context and produces responses, actions, or recommendations.
This layered design separates concerns while allowing each part of the system to evolve independently.
Role of Knowledge Graphs in Long-Term Memory
Long-term memory requires persistence, relevance, and adaptability. Knowledge graphs support all three more naturally than flat storage systems.
Persistence comes from durable storage. Once a relationship is captured, it remains available until explicitly updated or removed. Unlike prompt-based memory, it does not disappear after a session ends.
Relevance comes from structure. When a user asks a question, the system can retrieve only the most connected and contextually meaningful subgraph rather than entire documents. This reduces noise and improves precision.
Adaptability comes from graph evolution. New information can modify old understanding. If an employee changes teams, the graph updates that relationship without losing history. Temporal edges can preserve both past and present states.
Long-term memory also depends on abstraction. Humans do not remember every sentence; they remember relationships, events, and concepts. Graph memory mirrors this principle by storing distilled meaning rather than raw transcripts.
This makes it especially powerful for applications requiring continuity over months or years, including customer support systems, digital coworkers, enterprise assistants, and personal AI companions.
As AI systems become more autonomous, long-term memory shifts from optional enhancement to essential infrastructure.
Knowledge Graph Memory in AI Agents
AI agents are perhaps the strongest use case for knowledge graph memory because agents operate over time. They receive tasks, make decisions, observe outcomes, and must learn from those experiences.
A sales agent may remember past customer interactions, product interests, and open opportunities. A support agent may track unresolved issues, affected systems, and escalation paths. A research agent may preserve hypotheses, evidence chains, and previous conclusions.
Without memory, each agent session starts from zero. With graph memory, agents gain continuity.
This continuity improves planning. An agent can understand dependencies between actions and avoid repeating failed strategies. It can also personalize decisions using historical context.
Graph memory also enables explainability. Because relationships are explicit, developers can inspect why an agent made a decision. This is harder in purely embedding-based systems where reasoning paths are often opaque.
As multi-agent systems grow, shared graph memory becomes even more valuable. Multiple agents can contribute to and read from the same evolving knowledge base, enabling coordination and collective intelligence.
PuppyGraph for Knowledge Graph Memory
Knowledge graph memory offers a powerful way to give AI systems long-term, relationship-aware memory. The practical challenge, however, is implementation. In many organizations, memory already exists inside relational databases, data lakes, or data lakehouses. These systems can store large amounts of useful historical context, but they typically represent memory as rows in tables rather than as connected knowledge.
Transforming that existing memory into a usable knowledge graph traditionally requires building a separate graph database pipeline. Data must be extracted, transformed into nodes and edges, and continuously synchronized into a dedicated graph store. While effective, this approach adds architectural complexity, duplicates storage, and makes it harder to keep graph memory aligned with the latest source data.
This is where PuppyGraph offers a simpler path.
Instead of moving data into a new graph database, PuppyGraph builds a real-time knowledge graph directly on top of existing data sources, including PostgreSQL, MongoDB, and modern data lakes or lakehouse systems. Existing records can be mapped as graph nodes and edges without ETL or data duplication, turning operational storage directly into graph-structured memory.
This means organizations can preserve their existing storage architecture while exposing that same data as knowledge graph memory for AI systems. A record that was previously just a row or document becomes part of a connected memory graph that AI agents can traverse, query, and reason over in real time.
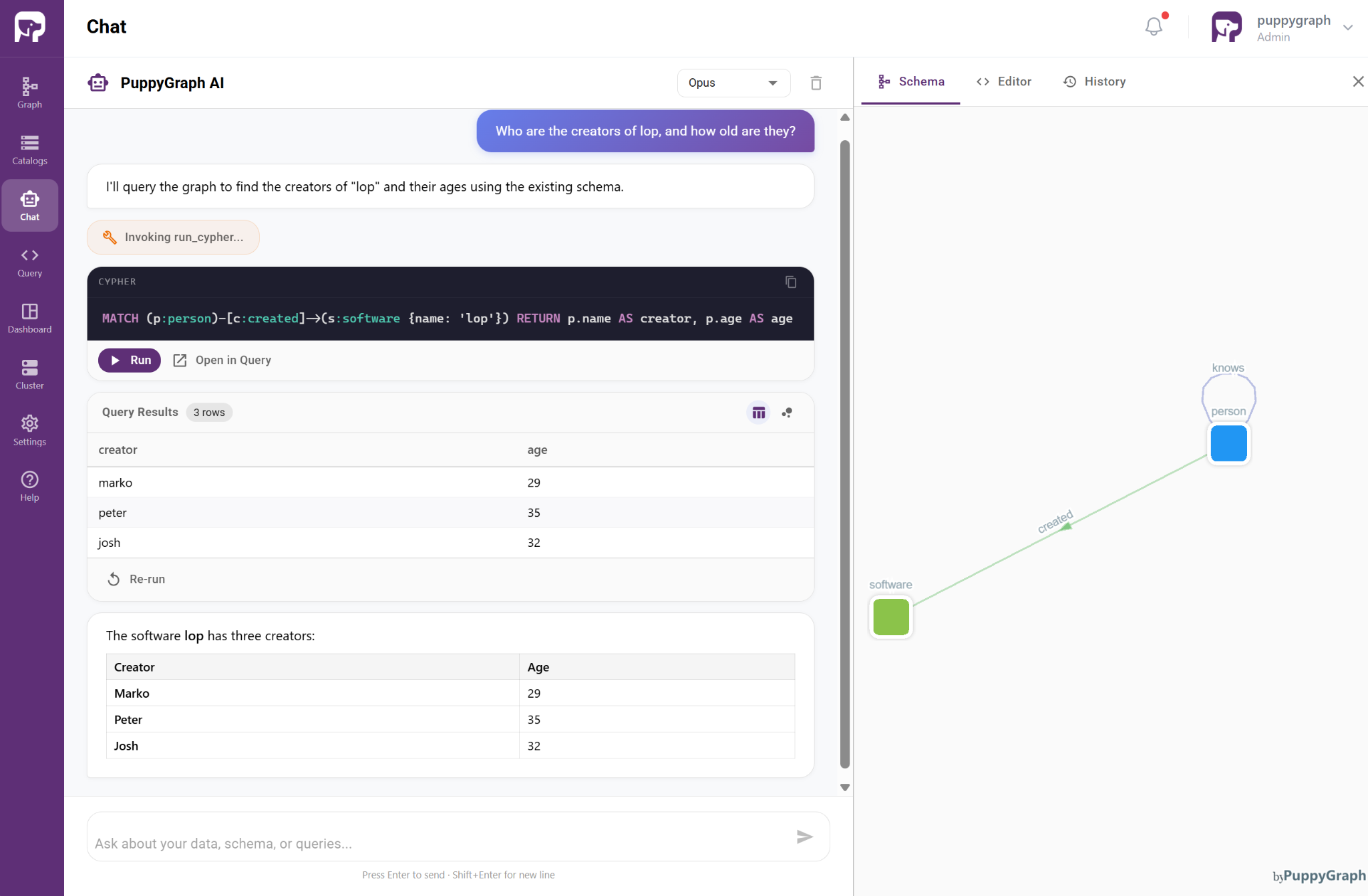
As a concrete example, assume the memory is stored in relational tables such as Person, Software, Created, and Knows, where records in Person and Software represent entities, while records in Created and Knows represent relationships between them. Together, these records can naturally be modeled as a graph: a connected representation of knowledge in which information is not viewed as isolated facts, but as a network of meaningfully related entities.
PuppyGraph turns this data into a live knowledge graph by applying a graph ontology layer on top of the underlying tables. This layer maps records into nodes and edges, making relationships directly accessible and queryable without moving or duplicating data. This allows users and AI systems to retrieve context, traverse connections, and reason over linked information in a more natural and intuitive way.
Conclusion
Knowledge graph memory represents a fundamental shift in how AI systems store and use information. By structuring memory as interconnected entities and relationships rather than isolated text or embeddings, it enables richer context retention, more accurate reasoning, and continuity across time. This makes it especially valuable for persistent AI agents, long-running workflows, and applications that require understanding evolving contexts rather than single-turn interactions. As AI systems move toward greater autonomy, the ability to maintain durable, structured memory becomes a core requirement rather than an optional enhancement.
In practice, this approach bridges the gap between raw data sources and intelligent reasoning by turning existing information into a navigable knowledge substrate. PuppyGraph further simplifies this by exposing graph memory directly on top of existing databases and data lakes, avoiding costly data duplication or ETL pipelines. Together, these advances make knowledge graph memory a practical foundation for next-generation AI systems that must reason, remember, and act consistently over time.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see how knowledge graph memory can be built and queried directly on your existing data in real time.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install