

LLM Graph Database : All You Need To Know

Large language models (LLMs) have become central to modern AI applications. They can summarize documents, answer questions, and generate insights across vast amounts of text. Yet, they also have well-known limits: they hallucinate facts, lack persistent memory, and struggle with multi-step reasoning over structured data.
Graph technology offers a complementary strength. Graph databases and engines are designed to capture relationships and efficiently execute multi-hop queries. They reveal connections that would be difficult to uncover with text alone and are already used in domains such as fraud detection, cybersecurity, and enterprise knowledge graphs.
When combined, these two technologies form what we call in this article an LLM graph database. A more precise description is a graph RAG (retrieval-augmented generation) system — where an LLM interacts with graph data to ground its outputs in factual, structured relationships.
This article explores what that means in practice. We’ll look at the core concepts, the synergy between LLMs and graphs, the key features and challenges, and real-world use cases. Finally, we’ll show how PuppyGraph supports such systems with real-time, zero-ETL graph querying.
What is an LLM Graph Database?
The phrase LLM graph database does not refer to a brand-new type of database with its own standard definition. Instead, it describes an emerging pattern where large language models and graph technology are combined to solve problems that neither handles well on its own. A more precise way to think about it is as a graph RAG (retrieval-augmented generation) system — where an LLM draws on graph-structured data to provide grounded, reliable, and context-aware answers.
In such a system:
- The graph side captures entities and their relationships, supports efficient multi-hop traversals, and provides authoritative data.
- The LLM side interprets natural language, generates graph queries (for example, in openCypher or Gremlin), and turns the query results into readable responses.
This setup can take different forms. Sometimes the LLM translates user questions into graph queries. Other times, the graph database acts as a retrieval source inside a RAG pipeline, grounding the LLM’s outputs. In more advanced designs, embeddings, vector search, and graph traversals all work together.
The value of an “LLM graph database” lies in this synergy: the precision and structure of graphs combined with the interpretive and generative power of LLMs.
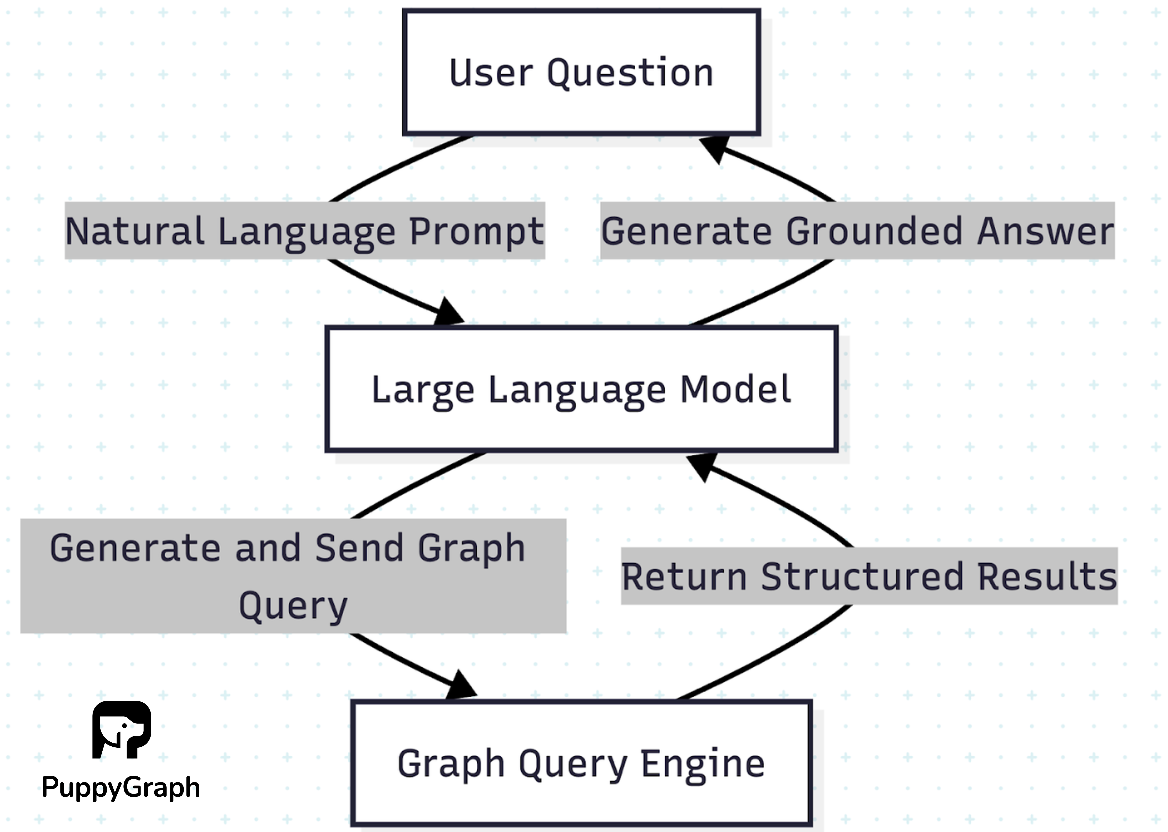
Core Concepts of an LLM Graph Database
An LLM graph database, or graph RAG system, is built on a few foundational ideas that explain how the two technologies complement each other:
1. Graphs as structured memory
Graphs model entities as nodes and their connections as edges. This makes them ideal for representing knowledge that involves relationships — whether between people, transactions, or concepts. Unlike flat tables, a graph can efficiently capture multi-hop dependencies and evolving networks.
2. LLMs as interpreters and generators
Large language models provide a natural interface to this structured data. They can translate human questions into graph queries and, in reverse, turn the often technical results of graph queries into fluent, readable answers.
3. Retrieval-augmented generation (RAG) with graphs
Instead of relying only on internal training data, an LLM can retrieve relevant information from a graph at query time. This ensures responses are grounded in current, verifiable data rather than probabilistic guesses.
4. Hybrid search with embeddings and graph traversals
LLMs excel at semantic similarity search via embeddings, while graphs excel at explicit relationship reasoning. Together, they support both “fuzzy” semantic lookups and precise multi-hop reasoning.
LLM + Graph Database: The Synergy
The strength of combining LLMs and graph databases comes from how each technology fills the other’s gaps.
On their own, LLMs are flexible but unreliable. They can parse ambiguous questions and generate natural-sounding responses, but they sometimes hallucinate or misrepresent facts. Graph databases, in contrast, are precise and reliable but require structured queries and schema knowledge that many users lack.
When the two are integrated, a natural synergy emerges:
- Flexible input, precise retrieval. The LLM interprets user intent from natural language and translates it into graph queries. The graph database then retrieves accurate, structured results.
- Multi-hop reasoning with explanation. Graphs handle the logic of traversing multiple relationships, while the LLM explains the results in plain language.
- Grounding and context. Graph data acts as a factual anchor that reduces hallucinations and makes the LLM’s output more trustworthy.
- Adaptive interaction. The LLM can refine queries based on user feedback, turning graph exploration into a conversational process.
The result is a system that is both easy to use and capable of deep, reliable reasoning. By letting LLMs and graphs play to their strengths, organizations can build tools that combine the accessibility of natural language with the rigor of structured analytics.
Key Features of an LLM Graph Database
An LLM graph database is more than just the idea of combining two technologies. It turns the synergy of LLMs and graphs into a workable system that can be deployed in real-world applications.
Query translation layer
Natural language questions are converted into formal graph queries such as openCypher, Gremlin, or SPARQL. This lowers the entry barrier for users unfamiliar with graph query languages.
Knowledge grounding for RAG
Structured graph results can be injected directly into an LLM’s context window, ensuring that responses are based on authoritative, up-to-date data rather than probabilistic guesses.
Hybrid retrieval
The system supports both embeddings-based similarity search and precise graph traversals. This allows fuzzy semantic matches (via vectors) to be combined with explicit relationship reasoning (via graphs).
Scalable graph execution
The underlying engine can handle large graphs with billions of edges and complex multi-hop traversals efficiently, so the LLM can remain effective even when working with enterprise-scale data in real time.
Enterprise integration
The system connects with existing data sources and governance frameworks, making it easier to adopt without replacing infrastructure.
Challenges in LLM Graph Database
Pairing LLMs with graph databases opens up new possibilities, but it also introduces challenges from both sides of the system.
Graph-related challenges
- Data integration and modeling: Deciding how to represent entities and relationships in a graph schema that aligns with natural language queries is complex.
- Latency and performance: Large graphs with billions of edges require efficient traversals, and combining this with LLM inference can stretch response times.
- Evolving schemas and data freshness: Graphs must be kept up to date with changing source data to prevent outdated or misleading answers.
- Security and governance: Sensitive enterprise data in graphs needs to be protected with strict access control and auditing.
LLM-related challenges
- Hallucination risk: LLMs may fabricate connections or interpret results incorrectly if not properly grounded in graph data.
- Entity resolution: Translating natural language mentions (e.g., “Apple”) into the correct graph entity (company vs. fruit) is error-prone.
- Query translation quality: LLMs may generate inefficient or invalid graph queries, requiring guardrails and optimization.
- Context management: Injecting graph results into the LLM’s context window has limits; long or complex query results can exceed token budgets.
Together, these challenges show why building an effective LLM graph database is more than just connecting two technologies. It requires careful design to ensure accuracy, speed, and trust.
Use Cases in LLM Graph Database
Pairing LLMs with graph databases opens opportunities across domains where language flexibility and structured reasoning both matter.
Enterprise knowledge management
Teams can query internal knowledge graphs through natural language, retrieving precise answers grounded in company data rather than sifting through documents.
Semantic search and question answering
Beyond keyword search, graphs let systems explain relationships. For example, instead of just listing reports about two firms, an LLM graph database can show how those firms are connected.
Fraud detection and cybersecurity
Attack paths, suspicious identities, or abnormal transactions can be represented as graphs. Analysts can then query them conversationally, turning complex multi-hop analysis into accessible insights.
Customer 360 and personalization
Graphs capture interactions across products, channels, and services. An LLM interface makes these graphs easy to explore and provides tailored insights for customer engagement.
Scientific research and healthcare
Graphs of proteins, genes, treatments, or citations enable multi-step reasoning over complex domains. An LLM front end makes these connections intelligible to a wider audience.
LLM Example with PuppyGraph
To illustrate how an LLM graph database works in practice, let’s look at the architecture of a PuppyGraph-powered RAG system.
The system integrates three main layers into a conversational workflow:
- User interface: A chat-based front end where users type natural language questions.
- RAG system: Combines embeddings, a vector store (ChromaDB), and an LLM (Claude Sonnet 4.0) to translate user intent into Cypher queries. The RAG pipeline improves query generation by retrieving similar examples and refining queries across multiple rounds if needed.
- Graph execution layer: PuppyGraph executes the generated Cypher queries directly on the connected data source, returning accurate results in real time without ETL or data duplication.
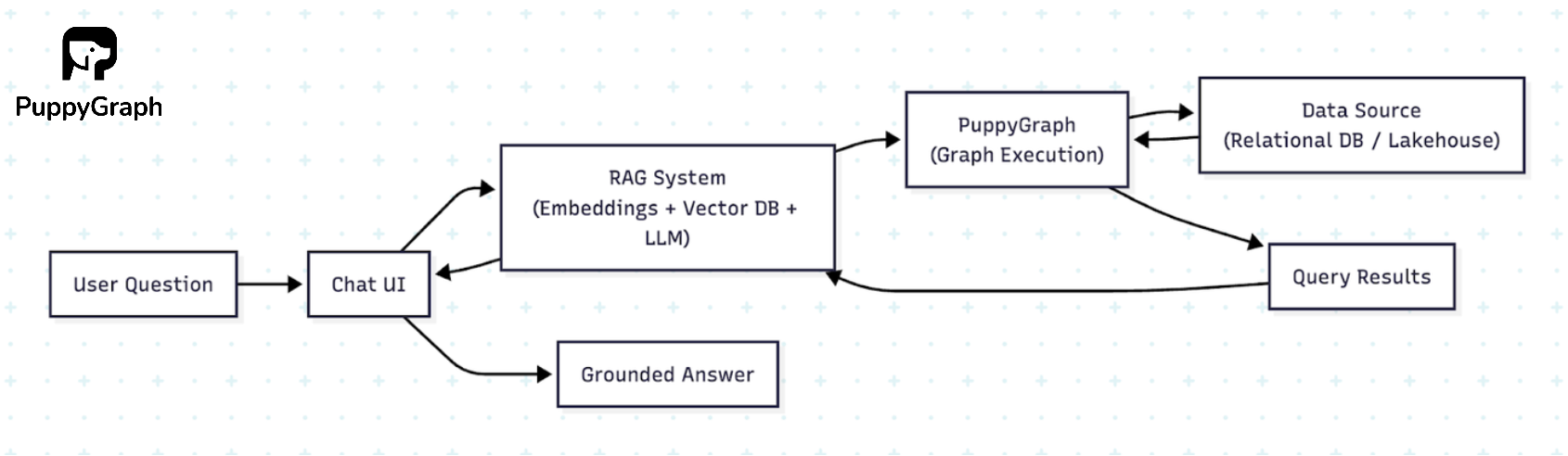
This design shows the essence of an LLM graph database with PuppyGraph executing the graph queries on live data. The LLM interprets intent, the RAG system ensures high-quality query generation, PuppyGraph provides precise graph execution, and the user receives a grounded, conversational answer.
To make this more tangible, PuppyGraph provides a demo using the classic Northwind dataset. In this demo, relational tables such as Customers, Orders, Products, and Employees are modeled as a graph in PuppyGraph. Customers become nodes, Orders link them to Products, and Employees form another relationship layer.
With this schema in place, the RAG system enables the chatbot to accept natural language queries and generate Cypher statements that PuppyGraph executes directly on the Northwind data. For example:
User question: “Which employees have managed the most orders?”

After processing, we obtained the final answer and its explanation. We can click to view the detailed processing steps.

When asked the question, the chatbot breaks the process down clearly:
- Step explanation: The system first explains its plan — it will count the orders assigned to each employee, order them by count in descending order, and then return the top employees.
- LLM request: The model reformulates the user’s question and confirms what it is trying to solve.
- LLM response: The model produces a Cypher query along with a short rationale. For example, it identifies that Orders are connected to Employees via the AssignedTo relationship, so counting those edges will reveal who handled the most orders.
Generated Cypher query:
MATCH (e:Employee)<-[:AssignedTo]-(o:Order)
WITH e, count(o) AS order_count
RETURN e.first_name + ' ' + e.last_name AS employee_name, e.title, order_count
ORDER BY order_count DESC- Execution: PuppyGraph runs the query on the Northwind dataset and returns the ranked results.
- Final answer: The LLM summarizes the outcome in plain language, noting for instance that Margaret Peacock handled the most orders, followed by other top employees.
Conclusion
Large language models are powerful, but they work best when grounded in reliable data. Graph databases excel at representing and querying relationships, but they are often difficult for non-experts to use. Combining the two creates an LLM graph database, or graph RAG system, where users can ask questions naturally, the LLM generates queries, and the graph engine delivers accurate results.
The example with PuppyGraph shows how this works in practice. By translating natural language into Cypher and executing queries directly on existing datasets, PuppyGraph enables LLMs to provide answers that are both conversational and precise. This approach removes the need for complex ETL pipelines, scales to enterprise data sizes, and gives organizations a way to make their connected data usable through AI.
PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


If you want to try this out, welcome to request a demo from the team!

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install