

What Is OLAP? Architecture, Cubes Explained
Online Analytical Processing (OLAP) has become a core technology in modern data analytics, enabling organizations to analyze large volumes of business data efficiently and derive meaningful insights for decision-making. As enterprises increasingly rely on data-driven strategies, OLAP systems provide the ability to perform multidimensional analysis across various perspectives such as time, geography, products, and customer behavior. Unlike traditional transactional databases that prioritize operational efficiency, OLAP platforms are specifically optimized for complex analytical queries, aggregations, and historical trend analysis.
This article explores the fundamental concepts, architecture, and operational principles of OLAP systems. It examines the characteristics of OLAP databases, the structure and function of OLAP cubes, and the major OLAP models including MOLAP, ROLAP, and HOLAP. In addition, the discussion highlights the distinctions between OLAP and OLTP systems, scalability challenges in large-scale analytics, and representative OLAP technologies used in modern cloud and enterprise environments. Through this analysis, the article demonstrates the continuing importance of OLAP in contemporary business intelligence and analytical infrastructures.
What Is OLAP?
Online Analytical Processing (OLAP) is a category of technologies designed to support fast, multidimensional analysis of large volumes of data. OLAP systems help organizations analyze historical and real-time business information from multiple perspectives, enabling decision-makers to discover trends, patterns, anomalies, and insights that are difficult to identify through traditional databases. OLAP has become a foundational technology for business intelligence, data warehousing, reporting platforms, and enterprise analytics applications.
The concept of OLAP emerged in the 1990s as organizations began accumulating enormous amounts of transactional data. Businesses needed systems capable of answering analytical questions such as monthly sales performance by region, customer purchasing behavior across different product categories, or profitability trends over several years. Traditional relational databases were optimized for transactions rather than analytical workloads, which created a demand for specialized analytical processing systems.
Unlike transactional systems that focus on inserting and updating records quickly, OLAP platforms are optimized for complex queries involving aggregations, calculations, filtering, slicing, and drill-down operations across millions or billions of records. Analysts can interactively explore datasets from different dimensions such as time, geography, product, or customer segment.
Today, OLAP technologies are widely used in finance, retail, healthcare, telecommunications, manufacturing, logistics, and modern cloud analytics platforms. As data volumes continue to grow exponentially, OLAP remains central to enterprise decision-making and advanced analytical architectures.
How OLAP Systems Work
At a high level, OLAP systems organize data into structures optimized for analytical queries instead of transactional operations. The goal is to allow users to retrieve summarized information rapidly, even when querying extremely large datasets.
Traditional relational databases store information in rows and tables designed for efficient transaction handling. OLAP systems, however, precompute aggregations and organize information multidimensionally. This allows analytical queries that would normally take minutes or hours to execute in seconds.
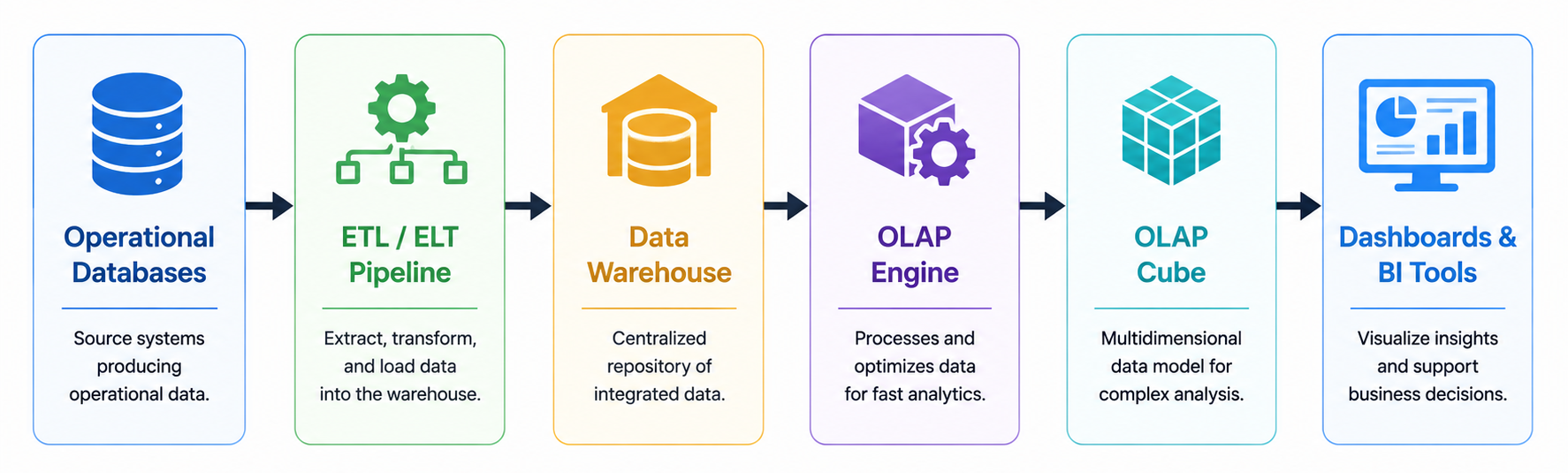
An OLAP workflow usually begins with data extraction from operational systems such as ERP platforms, CRM systems, financial software, web applications, or IoT devices. The data is cleaned, transformed, and loaded into a centralized data warehouse or analytical database through ETL (Extract, Transform, Load) or ELT pipelines.
Once data enters the analytical environment, OLAP engines organize it into dimensions and measures. Dimensions represent perspectives for analysis, such as time, region, department, or product category. Measures are numerical values that users want to analyze, including revenue, profit, quantity sold, or customer count.
A major strength of OLAP systems is their ability to perform multidimensional calculations efficiently. Users can perform operations like:
- Slice
- Dice
- Drill-down
- Roll-up
- Pivot
For example, a retail company may analyze total revenue by country, then drill down into individual cities, stores, and product categories. OLAP systems allow analysts to navigate these hierarchies interactively without manually writing complex SQL queries.
The following diagram illustrates a simplified OLAP workflow:
OLAP engines rely heavily on indexing, caching, aggregation tables, and query optimization techniques. Modern cloud-native OLAP systems also use distributed computing architectures to parallelize analytical workloads across multiple servers or clusters.
In many organizations, OLAP acts as the analytical layer sitting between raw enterprise data and business intelligence applications. Executives, analysts, and data scientists use OLAP-enabled tools to generate reports, forecasts, dashboards, and strategic insights.
Key Characteristics of OLAP Databases
OLAP databases differ significantly from operational databases because they are designed specifically for analytics rather than transactions. Several characteristics define OLAP systems and distinguish them from conventional data management technologies.
One of the most important characteristics is multidimensional data modeling. OLAP systems organize information into dimensions and measures rather than normalized transactional tables. This structure enables users to analyze data from multiple perspectives simultaneously. A sales analyst, for example, may evaluate performance by region, product category, and quarter in a single query.
Another defining feature is high query performance for aggregation-heavy workloads. OLAP databases are optimized for complex analytical calculations involving averages, totals, rankings, ratios, and historical comparisons. They often precompute aggregations to accelerate response times for frequently used queries.
OLAP databases also support hierarchical navigation. Users can move between different levels of granularity using drill-down and roll-up operations. A company may analyze revenue at the continent level, then move down to country, state, city, and individual store levels without restructuring the query.
Concurrency support is another essential capability. Large enterprises often have hundreds or thousands of analysts accessing analytical systems simultaneously. OLAP platforms are engineered to handle many concurrent read-heavy workloads efficiently.
Data consistency and historical retention are equally important. OLAP systems frequently store years of historical information, enabling trend analysis and long-term forecasting. Unlike transactional systems that focus mainly on current operational states, OLAP databases prioritize historical insights.
Scalability has become increasingly critical as organizations process petabytes of analytical data. Modern OLAP systems use distributed storage, parallel query execution, and cloud-native architectures to support large-scale analytics across massive datasets.
The following table summarizes core OLAP database characteristics:
These characteristics make OLAP indispensable for business intelligence and enterprise analytics environments where rapid insight generation is essential.
OLAP Architecture Explained
OLAP architecture refers to the structural design that enables analytical processing systems to manage, organize, and query multidimensional data efficiently. Although implementations vary across vendors and platforms, most OLAP architectures share several common layers and components.
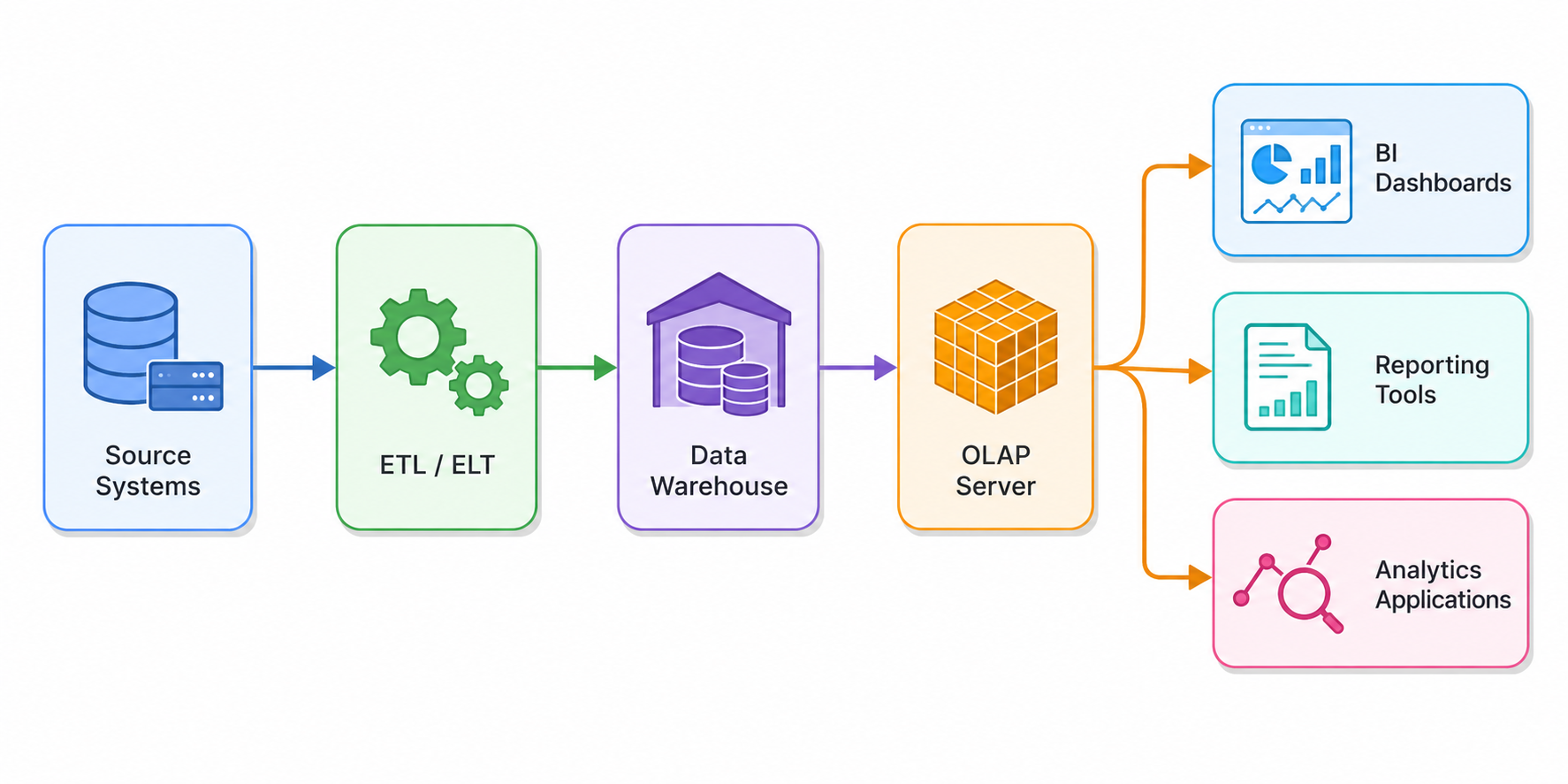
At the bottom of the architecture are the source systems. These include transactional databases, ERP systems, CRM platforms, cloud applications, spreadsheets, logs, and external datasets. Source systems continuously generate raw operational data.
The next layer consists of ETL or ELT pipelines. These pipelines extract data from source systems, transform it into consistent formats, cleanse inaccuracies, and load it into analytical storage systems. Data integration is essential because enterprise data often originates from heterogeneous systems with different schemas and formats.
The data warehouse layer serves as the centralized repository for structured analytical data. Warehouses consolidate information from multiple departments and business processes into a unified environment optimized for querying and reporting.
Above the warehouse sits the OLAP server or OLAP engine. This component processes analytical queries, manages multidimensional structures, performs calculations, and handles aggregation logic. The OLAP engine is the core computational layer responsible for delivering fast query responses.
Finally, presentation and visualization tools provide user access to analytical insights. These include dashboards, reporting systems, BI tools, spreadsheets, and data visualization platforms.
The architecture can be visualized as follows:
There are several architectural approaches to OLAP implementation. Some systems store data in multidimensional databases, while others rely on relational databases with specialized indexing strategies. Cloud-native architectures increasingly combine distributed storage engines with massively parallel query processing frameworks.
Modern OLAP architectures must also support hybrid workloads involving streaming data, real-time analytics, machine learning integration, and distributed cloud environments. As organizations demand faster and more scalable analytics, OLAP architectures continue evolving beyond traditional cube-based implementations.
Understanding OLAP Cubes
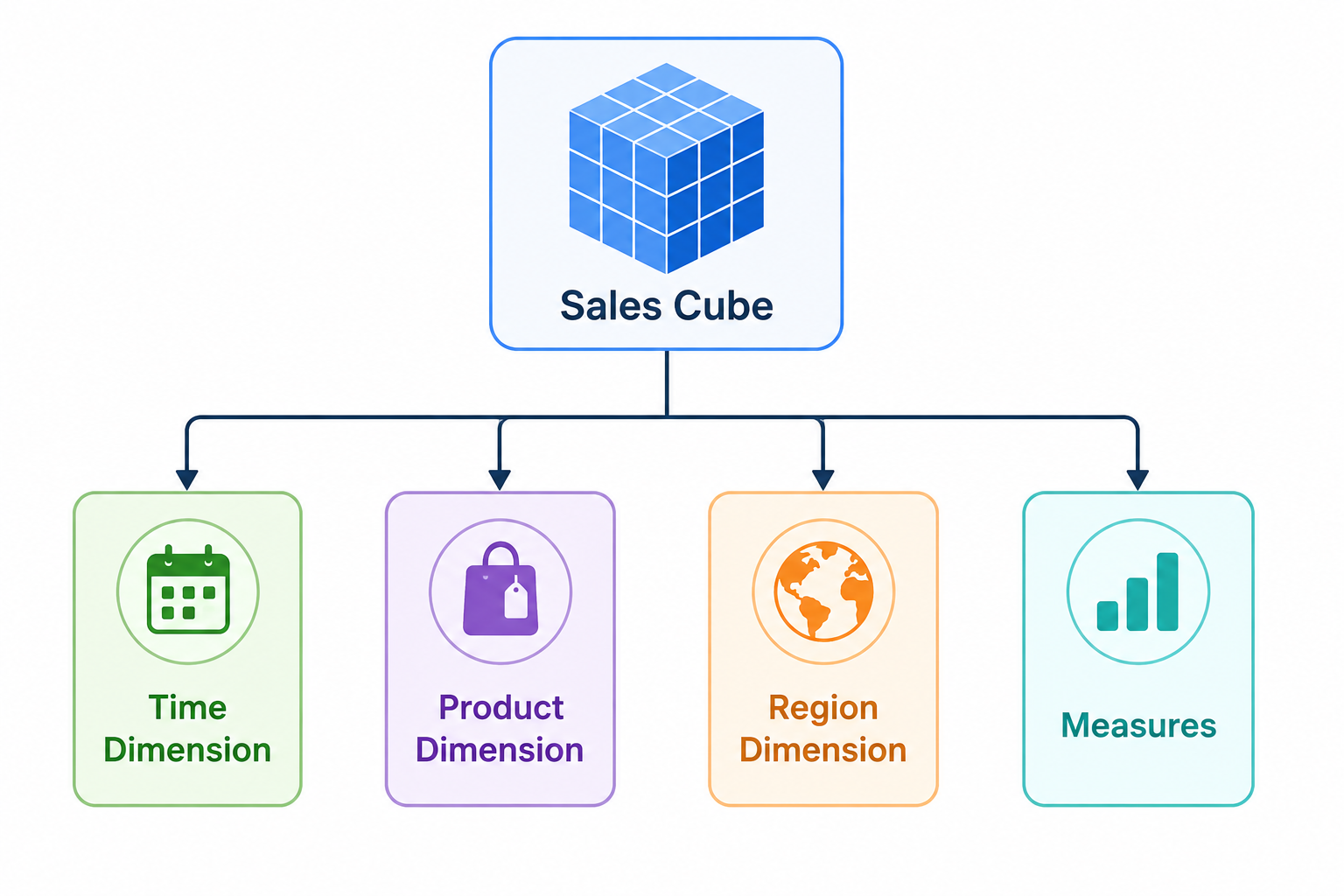
An OLAP cube is a multidimensional data structure designed to enable rapid analytical queries across multiple dimensions. Despite the name, OLAP cubes are not always literal cubes with three dimensions. In practice, they may contain many dimensions representing various business perspectives.
The purpose of an OLAP cube is to organize and preaggregate data in ways that allow analytical queries to execute efficiently. Each dimension represents a category used for analysis, while measures contain numerical values such as revenue, quantity, or profit.
Consider a retail company analyzing sales performance. The cube may include dimensions such as:
- Time
- Product
- Geography
- Customer Segment
Measures inside the cube could include sales revenue, units sold, profit margin, and discount rate.
The following simplified diagram illustrates a conceptual OLAP cube:
OLAP cubes allow users to perform multidimensional analysis intuitively. Analysts can slice the cube to isolate a single dimension value, such as revenue in 2025. They can dice the cube by selecting multiple dimensions simultaneously, such as electronics sales in Asia during Q1.
Drill-down functionality allows movement from summarized data into finer levels of detail. For example, users may begin with annual revenue, then drill into quarters, months, weeks, and individual transactions.
Roll-up operations perform the opposite action by aggregating detailed data into higher-level summaries. Pivoting enables analysts to rotate dimensions and change perspectives dynamically.
Historically, OLAP cubes were physically materialized structures stored in multidimensional databases. However, modern cloud analytics platforms increasingly implement virtual cubes or semantic layers that generate multidimensional views dynamically without requiring precomputed physical cube storage.
Although cube technology remains influential, many modern analytical systems are moving toward flexible distributed query engines capable of handling multidimensional analysis directly on large-scale datasets.
Types of OLAP
OLAP technologies can be categorized into several architectural models based on how data is stored and processed. The three primary types are MOLAP, ROLAP, and HOLAP, although newer cloud-native variations also exist.
MOLAP (Multidimensional OLAP)
MOLAP stores data in specialized multidimensional databases designed specifically for analytical workloads. Data is preaggregated and organized into cube structures, enabling extremely fast query performance.
Because aggregations are calculated in advance, MOLAP systems can deliver subsecond responses for complex analytical queries. This makes them highly effective for interactive business intelligence applications.
However, MOLAP systems often face scalability limitations because cube storage grows rapidly as dimensions and data volumes increase. Rebuilding large cubes can also become time-consuming and resource-intensive.
ROLAP (Relational OLAP)
ROLAP stores analytical data in relational databases instead of multidimensional storage engines. Queries are translated into SQL and executed directly against relational tables.
This approach offers better scalability because relational databases can manage extremely large datasets efficiently. ROLAP systems are also easier to integrate with existing enterprise infrastructure.
The tradeoff is query performance. Since aggregations may be calculated dynamically rather than precomputed, some complex analytical queries execute more slowly compared to MOLAP systems.
HOLAP (Hybrid OLAP)
HOLAP combines features from both MOLAP and ROLAP architectures. Frequently accessed aggregations are stored in multidimensional cubes, while detailed granular data remains in relational storage.
This hybrid approach balances performance and scalability. Organizations can achieve rapid query responses for common analytical workloads while still maintaining access to massive detailed datasets.
The following table compares the three main OLAP types:
In recent years, cloud-native analytical systems have introduced new architectural patterns beyond traditional OLAP classifications. Distributed query engines, columnar databases, lakehouse platforms, and real-time analytics systems increasingly blend OLAP concepts with modern big data technologies.
OLAP vs OLTP: Key Differences
OLAP and OLTP represent two fundamentally different approaches to data processing. Although both involve databases, they are designed for distinct purposes and workloads.
OLTP, or Online Transaction Processing, focuses on managing operational transactions efficiently. Examples include banking systems, e-commerce checkouts, reservation systems, and inventory management applications. OLTP systems prioritize fast inserts, updates, deletes, and transactional consistency.
OLAP, by contrast, is designed for analytical processing. Its primary objective is to support complex queries, aggregations, historical analysis, and decision-making.
The differences begin with workload characteristics. OLTP systems handle many small transactional operations involving individual records. OLAP systems process fewer but much larger analytical queries involving millions of rows.
Database design also differs significantly. OLTP databases typically use normalized schemas to reduce redundancy and maintain transactional integrity. OLAP databases often use denormalized schemas such as star schemas or snowflake schemas to optimize query performance.
Another key distinction involves data freshness and historical retention. OLTP systems focus primarily on current operational data, whereas OLAP systems maintain historical datasets spanning months or years.
Performance optimization strategies vary as well. OLTP systems optimize for low-latency transactions and concurrency control. OLAP systems optimize for aggregation speed, query execution efficiency, and analytical flexibility.
The following comparison summarizes major differences:
A retail business provides a useful example. The checkout system processing customer purchases is an OLTP application. Meanwhile, the analytical dashboard showing monthly sales trends, customer retention, and regional performance is powered by OLAP technologies.
Modern data architectures often combine both OLTP and OLAP systems. Transactional databases capture operational events, while analytical platforms ingest and process data for reporting and strategic analysis.
Scalability Challenges in OLAP Systems
As organizations generate larger volumes of data, scalability has become one of the most significant challenges facing OLAP systems. Traditional OLAP architectures were originally developed for enterprise datasets measured in gigabytes or terabytes. Modern analytics environments, however, increasingly involve petabyte-scale data processing.
One major challenge involves cube explosion. In multidimensional systems, the number of possible aggregations grows exponentially as dimensions increase. A cube containing dozens of dimensions may require enormous storage capacity if all aggregations are precomputed.
Query performance degradation is another concern. Complex analytical queries involving joins, aggregations, and filtering across massive datasets can strain CPU, memory, and storage resources. High concurrency workloads amplify these challenges further.
Data refresh latency also presents scalability issues. Many OLAP systems require periodic cube rebuilding or batch updates. As datasets grow larger, refresh operations become slower and may delay analytical availability.
Distributed architectures introduce additional complexity. Data partitioning, network communication, synchronization, and fault tolerance become critical considerations in large-scale distributed OLAP systems.
Cloud analytics platforms have introduced new approaches to addressing scalability limitations. Columnar storage formats improve compression and query efficiency by storing values column-wise rather than row-wise. Distributed query engines parallelize workloads across clusters, enabling faster execution on massive datasets.
The following diagram illustrates a distributed OLAP architecture:
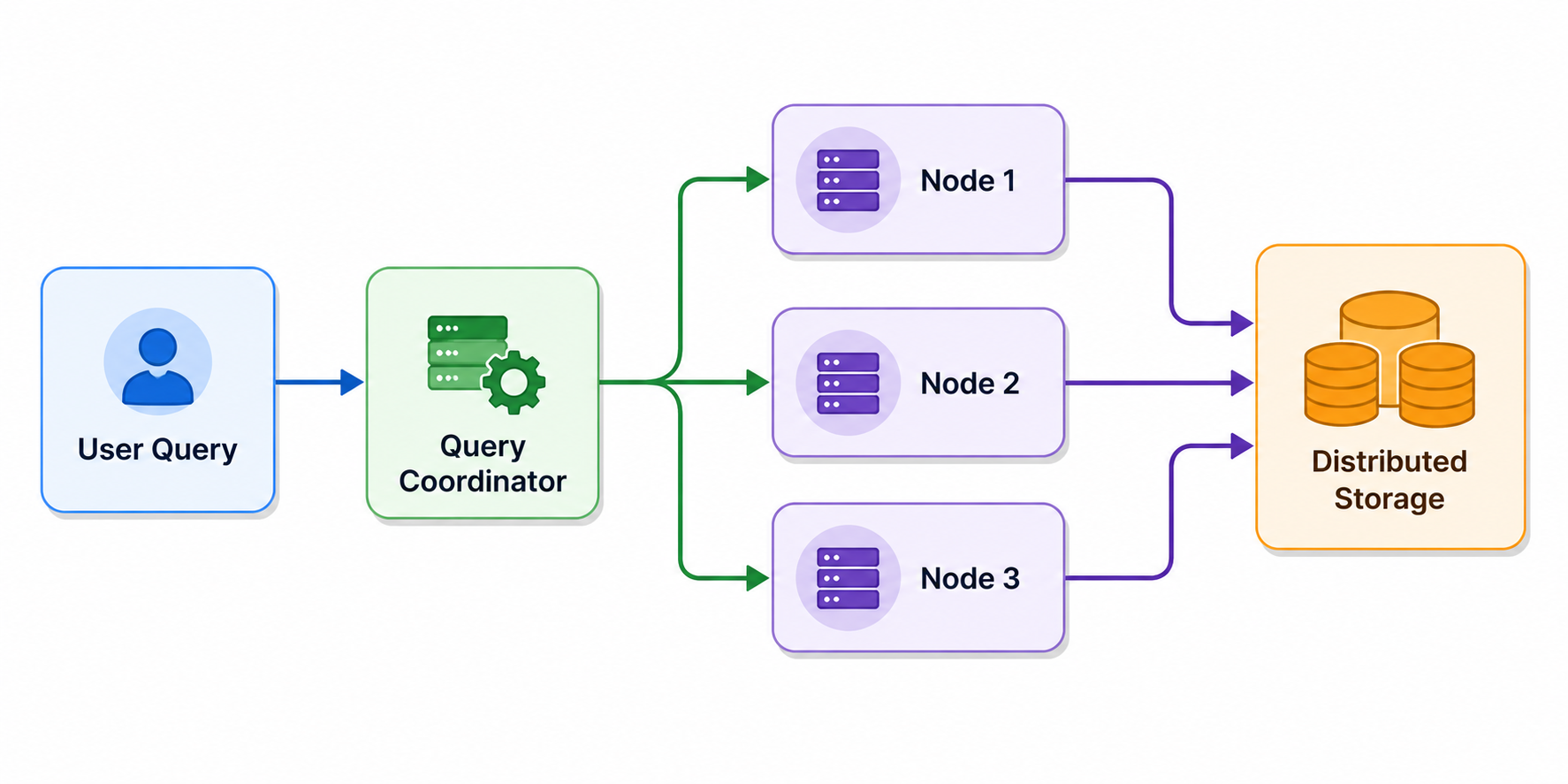
Modern cloud-native OLAP systems increasingly separate storage and compute layers. This allows organizations to scale computational resources independently from storage infrastructure, improving flexibility and cost efficiency.
Another emerging challenge involves real-time analytics. Businesses increasingly demand immediate insights from streaming data sources such as IoT sensors, application logs, clickstreams, and financial transactions. Supporting low-latency analytics at scale requires architectures capable of incremental updates and continuous query processing.
Scalability remains a central focus area in modern OLAP innovation as enterprises continue expanding their analytical ambitions.
OLAP Database Examples
Many database technologies and analytical platforms support OLAP workloads. These systems vary widely in architecture, scalability, deployment model, and performance characteristics.
Microsoft SQL Server Analysis Services (SSAS) has historically been one of the most widely adopted enterprise OLAP platforms. It provides multidimensional cube functionality and integrates closely with the Microsoft BI ecosystem.
Oracle Essbase is another well-known OLAP engine used extensively in financial planning, budgeting, and enterprise reporting applications. Essbase specializes in multidimensional analysis and hierarchical calculations.
SAP BW and SAP HANA support enterprise-scale analytics across large business environments. SAP HANA combines in-memory computing with columnar storage to accelerate analytical queries significantly.
Apache Druid is an open-source real-time analytics database optimized for low-latency OLAP queries on event-driven datasets. It is commonly used for operational analytics and streaming applications.
ClickHouse has gained popularity as a high-performance columnar analytical database capable of processing massive datasets with exceptional query speed. It is widely used for observability, log analytics, and business intelligence workloads.
Google BigQuery, Amazon Redshift, and Snowflake represent modern cloud-native analytical platforms. These systems provide scalable distributed OLAP capabilities through managed cloud services.
The following table highlights several major OLAP technologies:
Modern analytical ecosystems increasingly combine multiple technologies rather than relying on a single OLAP platform. Organizations may use cloud warehouses for large-scale storage, real-time engines for streaming analytics, and semantic layers for multidimensional business modeling.
The evolution of OLAP databases reflects broader trends in distributed systems, cloud computing, and big data architecture.
Advantages and Limitations of OLAP
OLAP systems provide substantial analytical benefits for organizations seeking data-driven decision-making capabilities. However, they also introduce limitations and tradeoffs that enterprises must consider carefully.
- Rapid analytical querying
OLAP systems allow users to analyze massive datasets interactively with low latency. Executives and analysts can explore trends, compare metrics, and generate reports quickly without waiting for long-running database operations. - Multidimensional analysis
OLAP enables flexible exploration of data across numerous dimensions and hierarchies. This improves analytical depth and supports sophisticated business intelligence workflows. - Enhanced decision-making quality
OLAP provides historical context and trend visibility. Organizations can identify patterns, forecast future outcomes, and evaluate strategic performance more effectively. - Scalability improvements in modern distributed OLAP systems
Cloud-native platforms now support large-scale enterprise analytics involving billions of records and thousands of concurrent users. - High analytical flexibility
OLAP systems support flexible data exploration and complex analytical workflows across different business dimensions.
Despite these advantages, OLAP systems also have limitations.
- Implementation complexity
Designing multidimensional schemas, building ETL pipelines, and managing analytical infrastructure can require specialized expertise. - High storage requirements
Storage costs may become significant, particularly in systems relying heavily on preaggregated cube structures. Large multidimensional datasets consume substantial storage and computational resources. - Real-time challenges
Real-time data processing can be difficult for traditional OLAP architectures. Many systems were designed primarily for batch analytics rather than continuous streaming workloads. - Maintenance overhead
Cube rebuilding, schema evolution, performance tuning, and data synchronization introduce operational complexity. - Scalability constraints in legacy systems
Traditional OLAP platforms may struggle with extremely large-scale or highly concurrent analytical workloads compared with modern distributed architectures.
Organizations must balance these tradeoffs carefully when selecting analytical architectures. Modern cloud platforms increasingly address many traditional OLAP limitations through distributed computing, elastic scaling, and managed infrastructure services.
Beyond OLAP: Adding Semantics to Analytical Systems
While OLAP systems provide powerful capabilities for large-scale analytics and multidimensional querying, another challenge remains: making enterprise data easier to understand, govern, and access consistently, especially for AI-driven applications.
Many enterprises already store their most critical business data in OLAP platforms, cloud data warehouses, lakehouse systems, and other SQL-based analytical systems. These systems provide strong performance, scalability, and mature analytical tooling.
However, OLAP systems are optimized for computation and aggregation, not necessarily for representing business meaning. Their schemas often reflect physical storage design and analytical structures rather than real-world business relationships. Tables, dimensions, measures, and joins describe how data is organized and queried, but not always what the data means.
For human analysts, this ambiguity is often manageable because domain knowledge fills the gaps. Analysts usually understand which joins are valid, which metrics belong together, and what a given identifier represents.
For AI systems, however, this challenge becomes much more significant.
Large language models and autonomous agents interact with analytical systems through schemas, metadata, and generated queries. Without explicit semantic guidance, they often struggle to interpret the underlying business meaning of analytical data.
A semantic layer addresses this gap.
The Role of a Semantic Layer
A semantic layer sits above existing analytical systems and exposes business concepts directly, such as Customer, Order, Product, or Transaction. Instead of forcing applications or AI systems to reason through raw tables, dimensions, and joins, the semantic layer provides a higher-level logical model aligned with business meaning.
This allows developers and AI agents to work with data more naturally, without changing the underlying analytical infrastructure.
Ontology and Ontology Enforcement
At the core of many semantic layers is an ontology, a formal definition of entities, relationships, and rules across the analytical data environment. An ontology defines:
- what entities exist,
- how they relate to one another,
- and what relationships are valid.
For example, a Customer may place an Order, an Order may contain a Product, and a Supplier may provide that product.
Ontology enforcement ensures that queries and updates across analytical systems respect these rules. Whether data originates from an application, an analyst, or an AI agent, operations are validated against the semantic model to prevent inconsistent or logically invalid relationships.
Why It Matters: From Semantic Fog to Agentic Clarity
Without a semantic layer, working directly with analytical systems often shifts complexity into application code, making systems harder to maintain as they grow. For AI systems, this challenge is even greater.
Large language models and autonomous agents can become trapped in semantic fog: navigating inconsistent schemas, ambiguous joins, and unclear relationships across analytical datasets. This often leads to operations that are syntactically correct but logically wrong.
An AI agent may successfully generate a query or connect two entities, yet create a relationship that does not exist in the real world.
Ontology enforcement acts as a semantic guardrail, ensuring that AI-generated reads and writes follow a validated model of how data entities interact. This reduces silent failures and improves trust in automated systems.
It also creates a valuable feedback loop for self-correction. Instead of returning only technical database errors, ontology-aware systems can provide structured semantic feedback, explaining why a query or update violates business logic. This allows AI systems to refine their behavior through iteration, learning the rules of the data environment over time.
Over the longer term, this feedback can also serve as a reward signal for fine-tuning or reinforcement learning.
Data Access with AI Assistants
Moving beyond architectural considerations, PuppyGraph provides a graph-based way to access and query existing analytical infrastructures as connected knowledge, without requiring organizations to migrate everything into a native graph database.
This enables developers and AI systems to explore existing analytical data through graph-style reasoning and relationship-aware retrieval.
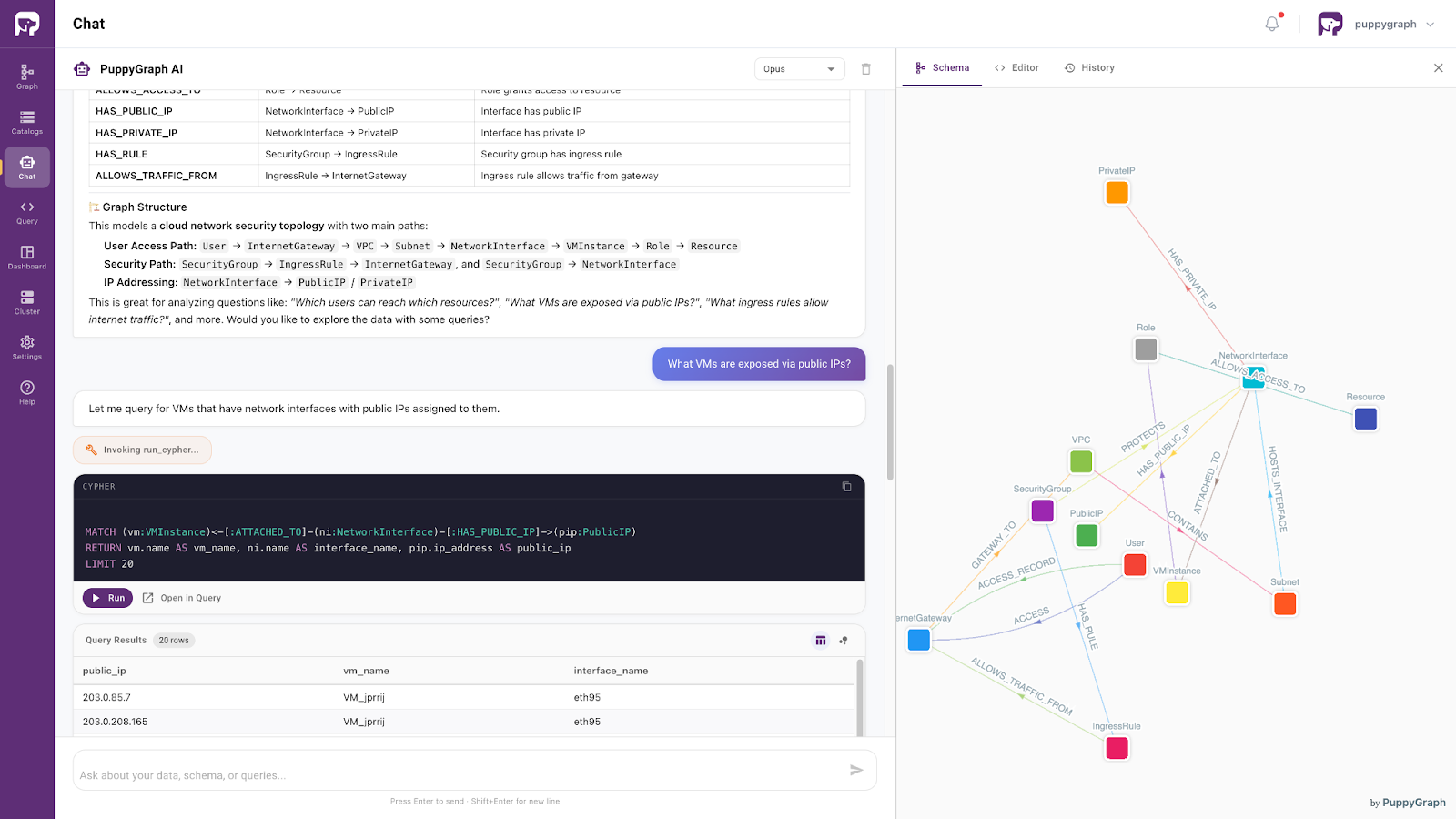
Figure: PuppyGraph AI assistant handling natural language questions
Powered by the same ontology-enforced foundation, PuppyGraph supports precise, context-aware access to enterprise analytical data. It allows AI systems to interpret user intent within a well-defined semantic framework and retrieve relevant information accordingly.
By connecting directly to existing analytical infrastructures, PuppyGraph enables organizations to add semantic understanding and graph-based reasoning capabilities on top of their current analytical environments while preserving existing storage systems and operational workflows.
As a result, enterprise data evolves from a passive analytical storage layer into an active semantic layer: one that preserves consistency while enabling more reliable search, analytics, and next-generation AI agents.
Conclusion
In conclusion, OLAP remains a fundamental technology for modern business intelligence and large-scale analytics. By enabling multidimensional analysis, fast aggregations, and interactive exploration of historical data, OLAP systems help organizations transform raw information into actionable insights. From traditional MOLAP architectures to modern cloud-native analytical platforms, OLAP continues to evolve to meet the growing demands of scalability, concurrency, and real-time analytics.
At the same time, the rise of AI-driven analytics has revealed the importance of adding semantic understanding on top of existing OLAP infrastructures. Semantic layers and ontology enforcement improve data consistency, contextual understanding, and AI reliability when interacting with enterprise data. PuppyGraph demonstrates how graph-based semantic reasoning can extend traditional OLAP systems, enabling more intelligent, context-aware, and trustworthy analytical applications in the era of AI and autonomous agents.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to discover how semantic graph analytics can unlock deeper insights from your existing OLAP infrastructure.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install