

What Is OLTP? Complete Guide
Online Transaction Processing (OLTP) systems are fundamental to modern digital operations, supporting real-time transactions across industries such as banking, e-commerce, healthcare, and telecommunications. These systems are designed to process large volumes of short, fast, and concurrent transactions while ensuring accuracy, consistency, and reliability. As businesses increasingly depend on immediate data processing and uninterrupted services, OLTP databases have become essential components of operational infrastructure.
This article explores the core concepts, architecture, and functionality of OLTP systems, including their transaction workflows, key database features, and scalability mechanisms. It also examines the differences between OLTP and OLAP systems, discusses widely used OLTP databases, and analyzes challenges related to scalability, security, and compliance. Through this discussion, the article highlights the critical role OLTP systems play in enabling efficient and reliable real-time business operations.
What Is OLTP?
OLTP stands for Online Transaction Processing. It refers to a category of software systems that manage transaction-oriented applications in real time. An OLTP system processes a large number of small, fast database transactions simultaneously. These transactions usually involve inserting, updating, deleting, or retrieving records from a database.
A transaction in an OLTP environment represents a single unit of work. For example, when a customer purchases a product online, the system may perform several actions within one transaction. It verifies inventory, processes payment, updates order records, and generates confirmation details. All these operations must complete successfully together. If any step fails, the entire transaction is rolled back to preserve data integrity.
OLTP systems prioritize speed, concurrency, and reliability. They are optimized for applications where many users interact with the database at the same time. Banking systems, airline reservations, online shopping platforms, CRM systems, and ATM networks are common examples of OLTP applications.
The defining characteristic of OLTP systems is their ability to process transactions immediately. Users expect near-instant feedback, which means OLTP databases are built for low-latency operations. Most transactions take only milliseconds to complete, even under heavy workloads. This requirement drives the design of database structures, indexing strategies, and infrastructure architectures.
OLTP systems also emphasize consistency and accuracy. Data errors in operational environments can have serious financial and legal consequences. For example, duplicate banking transactions or inaccurate inventory updates may result in significant business disruptions. To prevent these problems, OLTP databases rely heavily on ACID properties: Atomicity, Consistency, Isolation, and Durability.
\(ACID = \{Atomicity, Consistency, Isolation, Durability\}\)
Atomicity ensures that transactions either fully complete or fully fail. Consistency guarantees that transactions move the database from one valid state to another. Isolation prevents simultaneous transactions from interfering with one another. Durability ensures committed transactions remain permanent even after system failures.
Unlike analytical systems that focus on complex queries and historical analysis, OLTP environments are designed for operational efficiency. Their main objective is to support day-to-day business activities without interruption.
How OLTP Systems Work
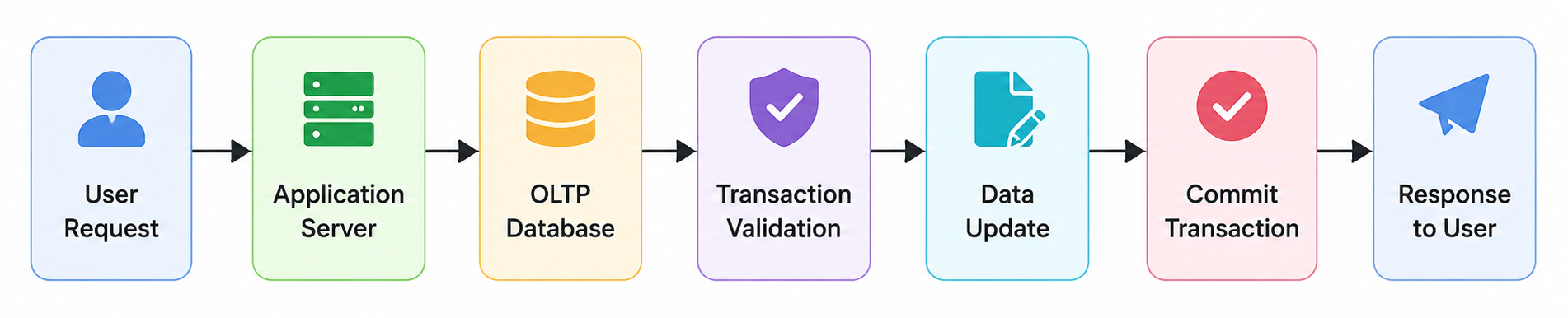
OLTP systems operate by continuously receiving, processing, and storing transactional data from users or applications. Every time a user interacts with an operational system, a transaction request is sent to the database server. The OLTP engine validates the request, applies business logic, updates relevant records, and confirms the transaction.
A typical OLTP workflow begins when a user initiates an action. Consider an online shopping scenario. When a customer clicks “Buy Now,” the application sends a transaction request to the backend database. The system first checks product availability, then validates payment credentials, creates an order entry, updates stock levels, and sends confirmation messages. These operations occur almost instantly.
The database management system coordinates all transaction processing activities. It uses locking mechanisms, transaction logs, memory buffers, indexes, and concurrency controls to maintain data accuracy while supporting thousands of simultaneous users. The database engine ensures that multiple transactions can occur concurrently without corrupting records.
The following diagram illustrates a simplified OLTP workflow:
One important concept in OLTP systems is concurrency control. Since many users access the same database simultaneously, the system must prevent conflicts. For example, two customers should not purchase the last remaining airline seat at the same time. Concurrency mechanisms ensure only one transaction successfully updates the resource.
OLTP systems also rely heavily on transaction logging. Before changes are permanently written to the database, operations are recorded in transaction logs. If a system crash occurs, the database can recover by replaying or rolling back logged transactions. This mechanism guarantees durability and fault tolerance.
Indexes play a major role in OLTP performance optimization. Since transactional queries are usually simple and repetitive, indexes help databases retrieve records quickly. For example, searching customer information by account ID becomes much faster when indexed properly.
Modern OLTP environments often support distributed architectures and cloud-native deployments. Transactions may occur across multiple servers and geographic regions while still maintaining consistency and high availability. Technologies such as replication, clustering, and sharding help scale these systems for global applications.
Key Features of OLTP Databases
OLTP databases are specifically designed to support operational workloads with high transaction throughput and minimal latency. Several defining features distinguish them from other database systems.
One major feature is real-time processing capability. OLTP systems are built to process transactions immediately after requests are submitted. Users expect instant responses when transferring funds, purchasing products, or accessing online services. The system architecture minimizes delays and optimizes response times.
Another important characteristic is high concurrency support. OLTP databases can handle thousands or millions of simultaneous users. Multiple transactions may occur at the same time without compromising consistency. Sophisticated locking and isolation mechanisms coordinate access to shared data resources.
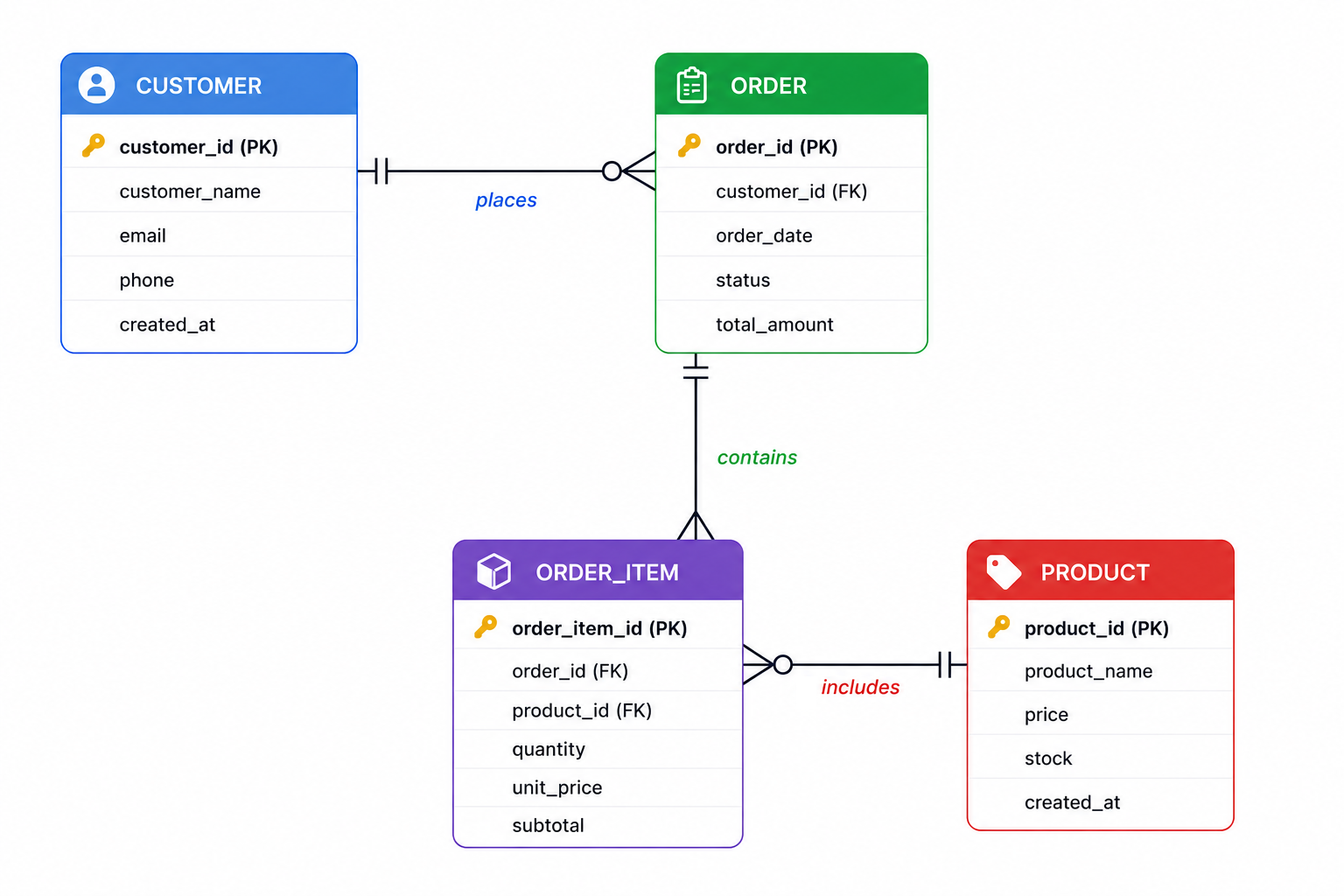
Data normalization is commonly used in OLTP databases. Tables are divided into smaller related structures to reduce redundancy and improve consistency. This design minimizes duplicate data storage and ensures updates occur efficiently across records.
The following example demonstrates a simplified normalized structure:
OLTP systems also emphasize short transaction duration. Most operations involve simple reads or writes rather than complex analytical queries. Transactions typically complete within milliseconds, reducing system resource consumption and lock contention.
Reliability and fault tolerance are equally critical. OLTP environments implement backup strategies, failover systems, and recovery mechanisms to ensure uninterrupted service. Downtime can directly impact revenue and customer trust, especially in industries like finance and healthcare.
Security features are another defining aspect of OLTP databases. Since they often store sensitive customer and financial information, strong authentication, encryption, and access control mechanisms are essential. Compliance requirements such as PCI DSS, HIPAA, and GDPR further influence OLTP database security practices.
Scalability is increasingly important in modern applications. Traditional vertical scaling approaches are no longer sufficient for internet-scale systems. Many OLTP databases now support distributed architectures, cloud deployments, and horizontal scaling capabilities to accommodate growing workloads.
Finally, OLTP systems are highly optimized for operational efficiency. Query execution engines, caching layers, indexing strategies, and memory management components all work together to maximize transaction throughput while minimizing latency.
OLTP Architecture Explained
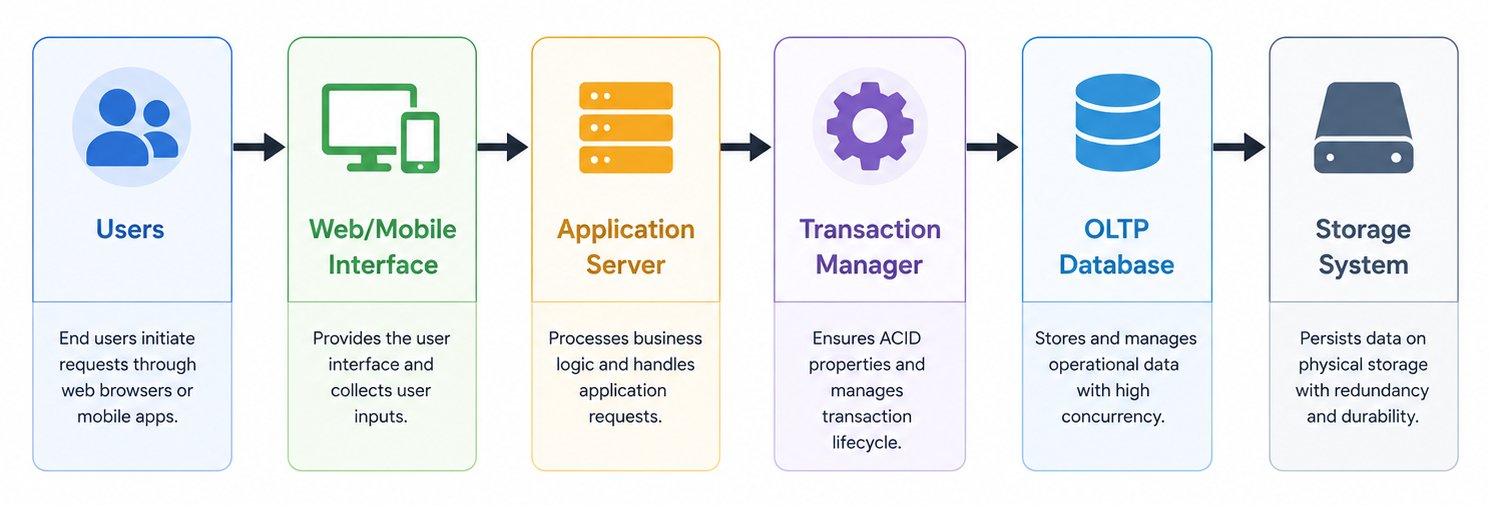
OLTP architecture refers to the structural design used to process and manage transactions efficiently. Although implementations vary depending on application requirements, most OLTP systems follow a multi-tier architecture consisting of presentation, application, and database layers.
The presentation layer represents the user interface where interactions occur. This could include websites, mobile applications, ATM terminals, or enterprise software dashboards. Users submit transaction requests through this layer.
The application layer processes business logic and coordinates interactions between users and databases. This layer validates transactions, enforces rules, handles workflows, and communicates with backend services. Application servers are responsible for scalability and load balancing in many modern OLTP environments.
The database layer stores and manages transactional data. It ensures consistency, concurrency control, recovery, and persistent storage. OLTP databases are optimized for rapid insert, update, and delete operations.
The following architecture diagram illustrates a typical OLTP system:
Transaction managers play a central role in OLTP architectures. They coordinate transaction execution and ensure ACID compliance. If a transaction encounters errors, the manager initiates rollback procedures to preserve consistency.
Database replication is commonly integrated into OLTP architectures to improve availability and disaster recovery. In replicated systems, multiple database copies remain synchronized. If the primary database fails, secondary replicas can take over operations with minimal downtime.
Load balancing is another critical architectural component. Traffic is distributed across multiple application or database servers to prevent bottlenecks. Cloud-native OLTP systems often use container orchestration platforms such as Kubernetes to automate scaling and resource management.
Caching layers significantly improve performance in high-traffic environments. Frequently accessed data is temporarily stored in memory systems such as Redis or Memcached. This reduces database load and accelerates response times for repetitive queries.
Some large-scale OLTP systems also use microservices architectures. Instead of relying on a monolithic application, services are separated into independent components. Each microservice manages specific business functions and may maintain its own transactional database.
Cloud computing has transformed OLTP architecture significantly. Managed database services such as Amazon RDS, Google Cloud SQL, and Azure SQL Database provide automated scaling, backups, monitoring, and failover capabilities. These services reduce operational complexity while supporting enterprise-grade performance.
OLTP vs OLAP: Key Differences
OLTP and OLAP are two major categories of data processing systems, but they serve very different purposes. Understanding their differences is essential for designing effective data architectures.
OLTP focuses on operational transaction processing. It supports real-time business activities such as order processing, banking transactions, inventory updates, and customer interactions. OLTP databases prioritize speed, concurrency, and consistency for short transactional workloads.
OLAP, which stands for Online Analytical Processing, is designed for complex data analysis and decision support. OLAP systems process large historical datasets to identify trends, generate reports, and support business intelligence activities.
The main distinction lies in workload patterns. OLTP systems handle frequent small transactions, while OLAP systems execute fewer but more computationally intensive analytical queries. OLTP queries usually access small data subsets, whereas OLAP queries scan large volumes of aggregated information.
The following table summarizes key differences:
OLTP databases are updated continuously throughout the day. In contrast, OLAP systems typically receive periodic batch updates from operational databases through ETL pipelines.
For example, an e-commerce website uses OLTP systems to process customer orders in real time. Meanwhile, its analytics team uses OLAP systems to analyze sales trends, customer behavior, and regional performance over several years.
Another major difference involves concurrency. OLTP systems must support many simultaneous users performing transactions. OLAP environments usually serve smaller groups of analysts running resource-intensive queries.
Although OLTP and OLAP serve different purposes, they often work together in modern enterprise ecosystems. Operational data generated by OLTP systems is eventually transferred into OLAP platforms for analytical processing and strategic decision-making.
Popular OLTP Databases
Many database platforms are designed specifically for OLTP workloads. Each database offers different strengths in terms of scalability, consistency, cloud integration, and performance optimization.
MySQL is one of the most widely used OLTP databases globally. It powers countless web applications due to its simplicity, reliability, and open-source ecosystem. MySQL is commonly used in e-commerce platforms, CMS systems, and SaaS applications.
PostgreSQL is another highly popular relational database known for strong ACID compliance, extensibility, and advanced SQL support. It is widely adopted in enterprise-grade OLTP systems requiring high reliability and complex transactional logic.
Oracle Database remains a dominant solution in large enterprise environments. It offers advanced clustering, replication, security, and high-availability capabilities. Many banking and telecommunications companies rely on Oracle for mission-critical OLTP operations.
Microsoft SQL Server is extensively used in corporate environments integrated with Microsoft ecosystems. It provides robust transactional processing, analytics integration, and enterprise management tools.
The following diagram compares several popular OLTP databases:
NoSQL databases are increasingly used for transactional workloads as well. MongoDB supports high-speed document-based transactions for flexible data models. Cassandra emphasizes horizontal scalability and fault tolerance for distributed applications.
Cloud-native databases have also emerged as major OLTP solutions. Google Spanner, Amazon Aurora, and CockroachDB are designed to support globally distributed transactional systems with strong consistency guarantees.
Selection of an OLTP database depends on multiple factors, including workload size, consistency requirements, budget, scalability needs, and operational expertise. Organizations often combine multiple databases to optimize performance for different applications.
Scalability Challenges in OLTP Systems
Scalability is one of the biggest challenges facing OLTP systems. As user traffic and transaction volumes increase, databases must continue delivering fast response times without sacrificing consistency or reliability.
Traditional OLTP systems often relied on vertical scaling, where hardware resources such as CPU, memory, and storage were increased on a single server. While effective initially, vertical scaling has physical and financial limitations. Eventually, organizations need more flexible approaches.
Horizontal scaling distributes workloads across multiple servers or nodes. This strategy improves performance and fault tolerance but introduces significant architectural complexity. Maintaining consistency across distributed databases becomes increasingly difficult as systems scale globally.
One major challenge is transaction contention. When many users attempt to access or update the same records simultaneously, locking conflicts can occur. Excessive contention reduces throughput and increases latency.
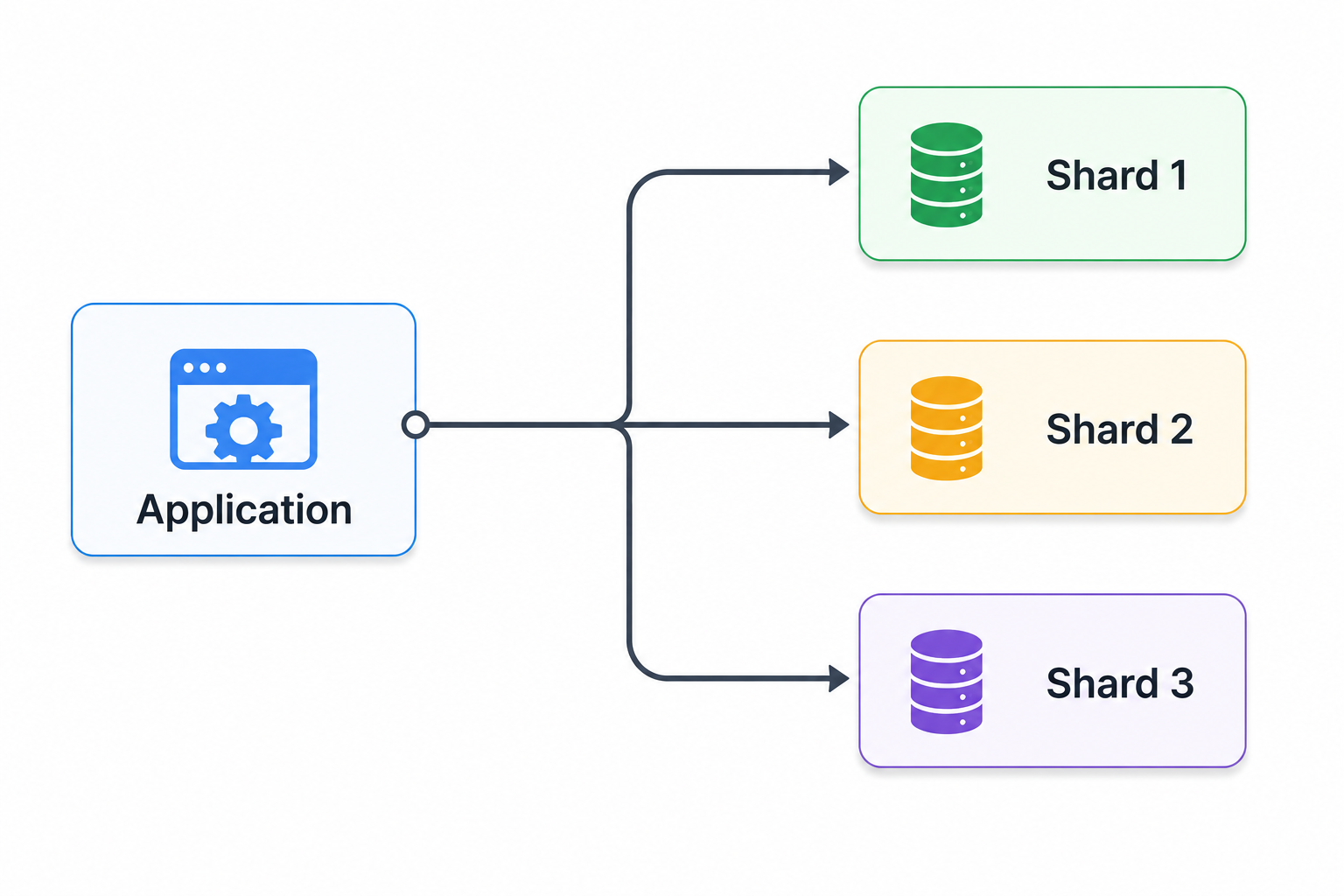
Database sharding is commonly used to improve scalability. Data is partitioned across multiple database instances, allowing workloads to distribute evenly. However, sharding introduces operational challenges related to query routing, cross-shard transactions, and data balancing.
The following diagram illustrates a simplified sharding model:
Replication also introduces trade-offs. While replicas improve read scalability and fault tolerance, synchronizing distributed nodes can increase complexity and network overhead. Systems must balance consistency, availability, and partition tolerance.
Latency becomes especially problematic in globally distributed environments. Applications serving international users may experience delays due to geographic distances between data centers. Distributed OLTP systems often use regional replication and edge infrastructure to minimize response times.
Infrastructure costs rise significantly as OLTP workloads scale. High-performance storage systems, low-latency networking, backup infrastructure, and monitoring tools all contribute to operational expenses.
Cloud-native architectures partially address these challenges through automated scaling and managed services. However, organizations still need careful database optimization, workload management, and architectural planning to sustain large-scale OLTP performance.
Security and Compliance in OLTP Environments
Security is a critical priority in OLTP systems because they often handle highly sensitive information, including customer records, payment data, healthcare information, and business transactions. A single breach can result in severe financial losses, reputational damage, and regulatory penalties.
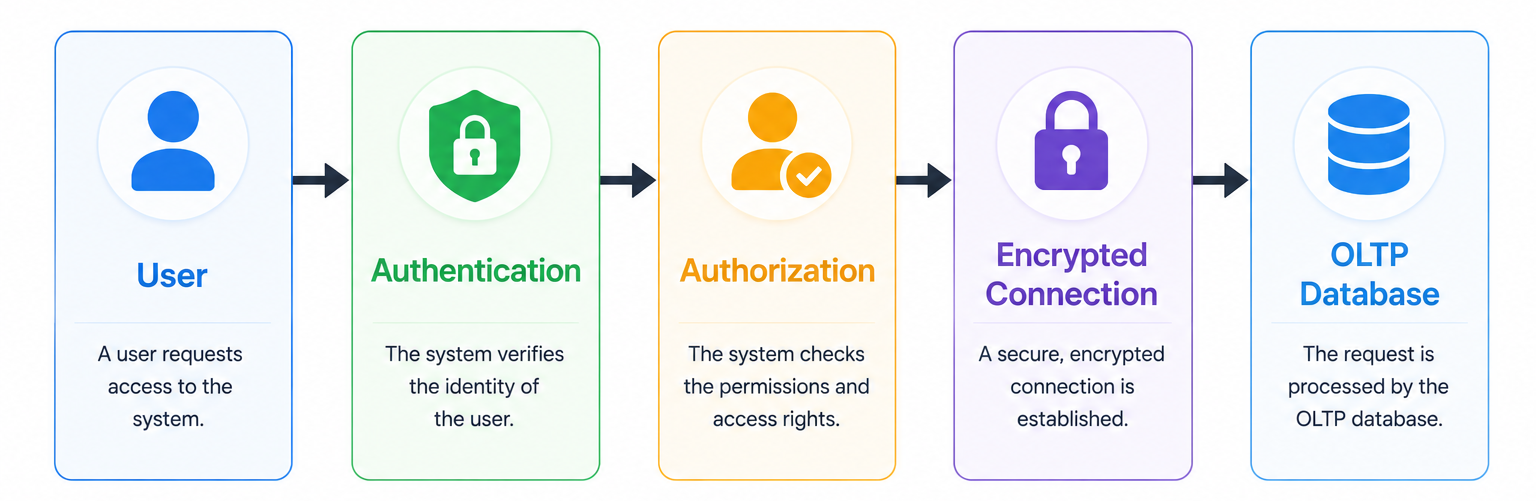
Authentication mechanisms ensure only authorized users can access transactional systems. Multi-factor authentication is widely adopted to strengthen account protection and reduce unauthorized access risks.
Role-based access control helps organizations manage permissions effectively. Different users receive access privileges based on their responsibilities. For example, customer support representatives may view account information without having permission to modify financial records.
Encryption plays a major role in OLTP security. Data encryption protects information both in transit and at rest. Secure communication protocols such as TLS prevent attackers from intercepting transactional data during network transmission.
The following diagram demonstrates a simplified OLTP security model:
Database auditing and logging provide visibility into system activity. Security teams monitor logs to identify suspicious behavior, failed login attempts, or unauthorized data access. Audit trails are also essential for regulatory compliance investigations.
Compliance requirements significantly influence OLTP security strategies. Financial organizations must comply with PCI DSS standards for payment data protection. Healthcare providers follow HIPAA regulations for patient privacy. Companies operating internationally must address GDPR requirements related to personal data handling.
Backup and disaster recovery planning are equally important. Data loss or ransomware attacks can disrupt operations and compromise customer trust. OLTP systems require regular backups, failover mechanisms, and tested recovery procedures to ensure business continuity.
Modern cybersecurity threats continue evolving rapidly. Organizations increasingly adopt zero-trust security models, behavioral analytics, AI-driven threat detection, and endpoint monitoring to strengthen OLTP environments against sophisticated attacks.
Cloud deployments introduce additional security considerations. Shared infrastructure environments require careful configuration management, identity controls, and network segmentation to prevent vulnerabilities.
Ultimately, securing OLTP systems requires a multi-layered strategy that combines technology, governance, monitoring, and employee awareness to protect operational data and maintain regulatory compliance.
Advantages and Limitations of OLTP
OLTP systems provide numerous benefits for organizations operating digital services and real-time applications. Their ability to process transactions rapidly and reliably makes them essential for modern business operations.
- Real-time transaction processing
Users receive immediate responses, improving customer satisfaction and operational efficiency. Fast processing enables businesses to support high-volume activities such as online shopping, digital payments, and reservation systems. - High concurrency support
OLTP databases are specifically engineered to maintain consistency even during heavy workloads. This capability is critical for large-scale applications serving millions of users globally. - Data integrity
ACID-compliant transaction management ensures reliable and accurate operations. Organizations can trust that critical records remain consistent even during failures or concurrent updates. - Enhanced automation
Business processes such as billing, order fulfillment, inventory management, and customer onboarding can operate continuously with minimal manual intervention.
However, OLTP systems also have limitations.
- Scalability complexity
As workloads increase, maintaining low latency and strong consistency across distributed systems becomes difficult. - High operational costs
High-performance infrastructure, replication systems, monitoring tools, and security frameworks require significant investment. Large enterprises often spend heavily on database optimization and availability engineering. - Limited analytical capability
OLTP databases are not optimized for analytical workloads. Complex reporting queries can negatively affect transactional performance. Organizations therefore separate OLTP and OLAP systems to avoid resource contention. - Schema rigidity
Highly normalized structures improve consistency but may reduce flexibility when handling rapidly changing data models. - Consistency trade-offs in distributed systems
Achieving global scalability while maintaining strict ACID guarantees can introduce latency and architectural complexity.
Despite these challenges, OLTP remains indispensable for operational computing. Continuous advancements in cloud technologies, distributed databases, and automation tools are helping organizations overcome many traditional limitations.
Beyond Database Choice: Adding Semantics to Existing OLTP Systems
Choosing the right OLTP database is only the first step.
Even when organizations deploy scalable transactional systems such as PostgreSQL, MySQL, Oracle Database, or distributed cloud-native databases, another challenge remains: making operational data easier to understand, govern, and access consistently, especially for AI applications.
OLTP systems are fundamentally optimized for transactional efficiency, concurrency control, low-latency updates, and ACID consistency rather than semantic understanding. Tables, foreign keys, and indexes are designed to support transaction processing and operational correctness, but they do not always express the higher-level business meaning behind the data.
As enterprises increasingly adopt AI assistants, autonomous agents, and natural language interfaces for operational systems, the gap between transactional correctness and semantic understanding becomes more significant.
A semantic layer helps bridge this gap by introducing a business-oriented representation of operational data alongside existing transactional systems.
The Role of a Semantic Layer
A semantic layer sits above existing OLTP databases and exposes business concepts directly, such as Customer, Order, Product, Payment, or Transaction.
Instead of forcing applications or AI systems to reason through raw tables and joins, the semantic layer provides a higher-level logical model aligned with business meaning.
This allows developers and AI agents to work with operational data more naturally without changing the underlying OLTP systems.
Importantly, the transactional databases remain the system of record. Existing OLTP platforms continue handling inserts, updates, deletes, concurrency control, and ACID guarantees exactly as before.
Ontology and Ontology Enforcement
At the core of many semantic layers is an ontology: a formal definition of entities, relationships, and rules across the operational data environment.
An ontology defines:
- what entities exist,
- how they relate to one another,
- and what relationships are valid.
For example, a Customer may place an Order, an Order may contain a Product, and a Supplier may provide that product.
Ontology enforcement helps ensure that queries and interactions across OLTP systems follow these semantic rules. Whether requests originate from applications, analysts, or AI agents, operations can be validated against the semantic model to reduce inconsistent or logically invalid relationships.
In practice, this becomes increasingly important as AI systems begin interacting directly with operational enterprise data.
Why It Matters: From Semantic Fog to Agentic Clarity
Without a semantic layer, working directly with OLTP schemas often shifts complexity into application logic and integration code, making systems harder to maintain as they scale.
For AI systems, this challenge becomes even greater. Large language models and autonomous agents can become trapped in semantic fog: navigating inconsistent schemas, ambiguous joins, and unclear relationships across transactional tables.
This often leads to operations that are syntactically correct but logically wrong. An AI agent may successfully generate a SQL query or connect two entities, yet create a relationship that does not exist in the real business environment.
Ontology enforcement acts as a semantic guardrail, helping AI-generated operations follow a validated model of how entities interact. This improves reliability and reduces silent logical failures in AI-assisted operational systems.
It also creates a valuable feedback mechanism for self-correction. Instead of returning only low-level database errors, ontology-aware systems can provide semantic feedback explaining why a query or relationship violates business logic. This allows AI systems to refine their behavior through iteration, learning the rules of the data environment over time. Over the longer term, this feedback can also serve as a reward signal for fine-tuning or reinforcement learning.
Data Access with AI Assistants
Moving beyond architectural considerations, PuppyGraph provides a graph-based way to access and query existing transactional databases as connected knowledge without requiring organizations to migrate data into a native graph database.
Importantly, PuppyGraph works directly on top of existing databases in place and operates as a read-only layer. The underlying OLTP systems remain fully authoritative and continue managing transactional writes, updates, consistency guarantees, and operational workflows.
This enables developers and AI systems to explore operational data through graph-style reasoning and relationship-aware retrieval while preserving the integrity and performance of the source transactional systems.
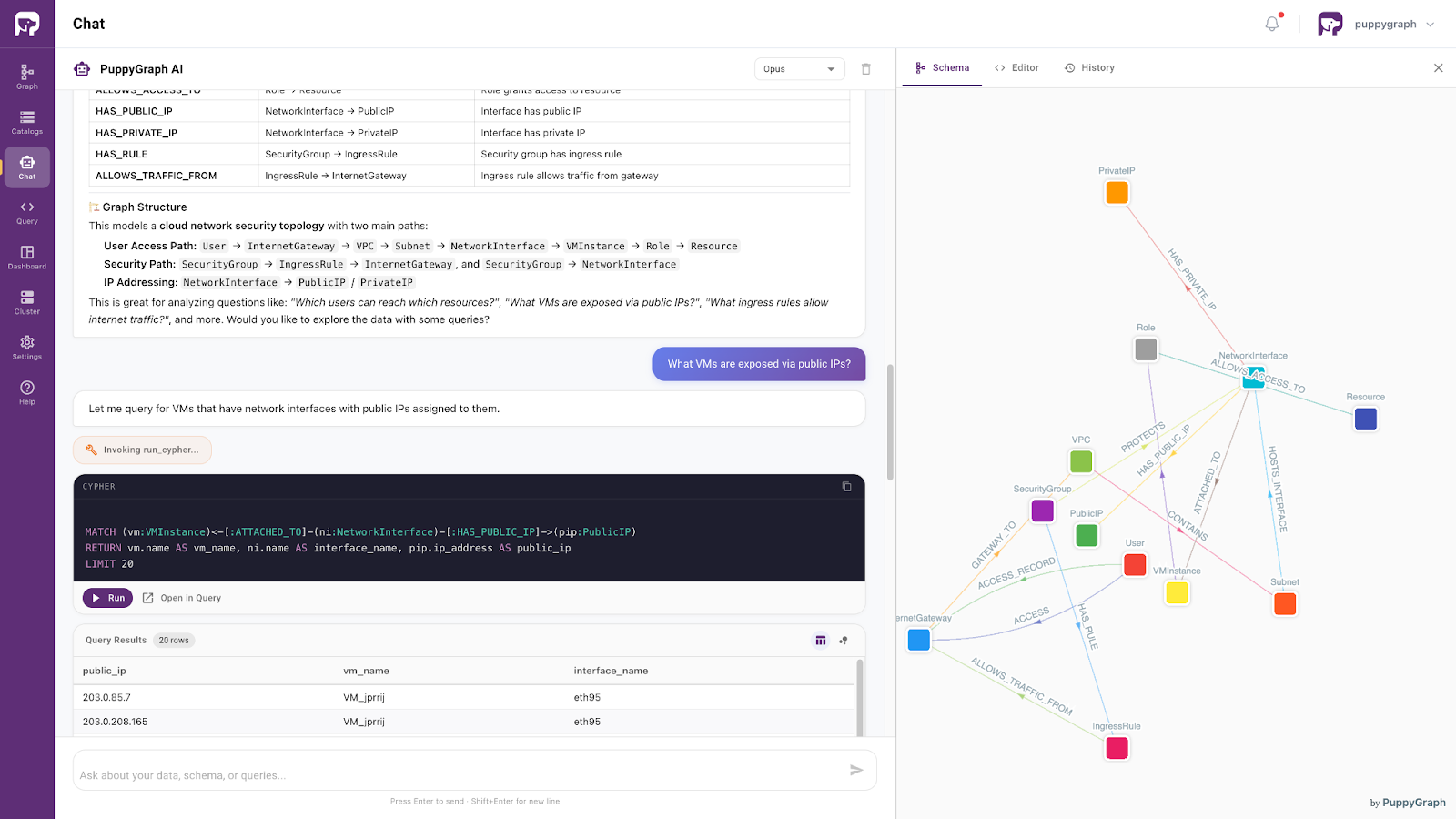
Figure: PuppyGraph AI assistant handling natural language questions
Powered by the same ontology-enforced foundation, this approach supports more precise and context-aware access to enterprise operational data. It allows AI systems to interpret user intent within a well-defined semantic framework and retrieve relevant information accordingly.
As a result, enterprise OLTP data evolves from a purely transactional storage layer into a semantically connected operational knowledge layer, enabling more reliable search, analytics, and next-generation AI applications without disrupting existing systems.
Conclusion
In conclusion, OLTP systems remain essential for modern digital operations because they enable fast, reliable, and real-time transaction processing across industries such as banking, e-commerce, healthcare, and telecommunications. Their emphasis on ACID properties, concurrency control, scalability, and security ensures that operational data remains accurate and continuously available even under heavy workloads. As businesses increasingly depend on immediate data access and uninterrupted services, OLTP databases continue to serve as the backbone of day-to-day enterprise activities.
At the same time, the evolution of AI-driven applications and distributed cloud environments has introduced new challenges related to scalability, semantic understanding, and operational complexity. Semantic layers and ontology enforcement provide an effective solution by improving how AI systems interpret and interact with transactional data while preserving the integrity of existing OLTP infrastructures. Together with PuppyGraph, these advancements help transform traditional OLTP systems into intelligent, semantically connected operational platforms for the next generation of enterprise applications.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see how semantic graph querying can simplify and accelerate access to your enterprise operational data.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install