

Ontology-Driven Agents: How Do They Work?
Modern data systems are no longer limited by access: they are limited by understanding. As organizations accumulate increasingly complex and interconnected data, the challenge shifts from retrieving information to interpreting it correctly. Traditional approaches rely heavily on schemas and implicit relationships, which can be difficult for both humans and AI systems to navigate, especially at scale. This gap often leads to ambiguity, misinterpretation, and incorrect results, even when queries appear technically valid.
Ontology-driven agents address this problem by introducing an explicit semantic layer between users and data. By grounding data interaction in well-defined concepts and relationships, these agents enable more accurate reasoning, reliable query generation, and consistent interpretation across systems. This article explores what ontologies are, how ontology-driven agents work, and why they are becoming essential for building trustworthy, AI-powered data systems.
What Is an Ontology
An ontology is a formal representation of knowledge within a domain. Rather than describing how data is stored, it defines what the data means by modeling entities, relationships, attributes, and constraints in a structured and machine-readable way. This distinction is essential in modern data systems, where the challenge is no longer just accessing data, but understanding it correctly.
In a traditional database, meaning is implicit. Tables, columns, and foreign keys encode relationships, but they do not explicitly describe the real-world semantics behind them. As systems grow in complexity, this implicit structure becomes harder to interpret, especially for machines. An ontology makes this meaning explicit by elevating data from a structural representation to a semantic model. It provides a shared vocabulary that both humans and AI systems can use to reason about data consistently.
This semantic layer becomes particularly important in environments where data spans multiple systems, formats, and teams. In such settings, correctness depends not only on retrieving data, but on interpreting relationships in a way that aligns with real-world logic.
What Are Ontology-Driven Agents?
Ontology-driven agents are AI systems that use an ontology as the foundation for reasoning, query generation, and data interaction. Instead of directly operating on raw schemas or relying purely on statistical patterns, these agents interpret tasks through a structured semantic model of the domain.
This changes the behavior of the agent in a fundamental way. A conventional AI agent may generate queries that appear valid because they follow syntactic rules, yet still produce incorrect results due to misunderstandings of how data is connected. These errors are especially common in complex enterprise environments, where schemas encode intricate business logic that is not obvious from table structures alone.
By contrast, an ontology-driven agent is grounded in explicit knowledge. It understands not only which entities exist, but also how they relate to one another and what constraints govern those relationships. This grounding allows the agent to move beyond pattern matching and toward reasoning that aligns with the actual structure of the domain.
Key Components of Ontology-Driven Agents
An ontology-driven agent is composed of several tightly connected components that work together to ensure semantically grounded data interaction.
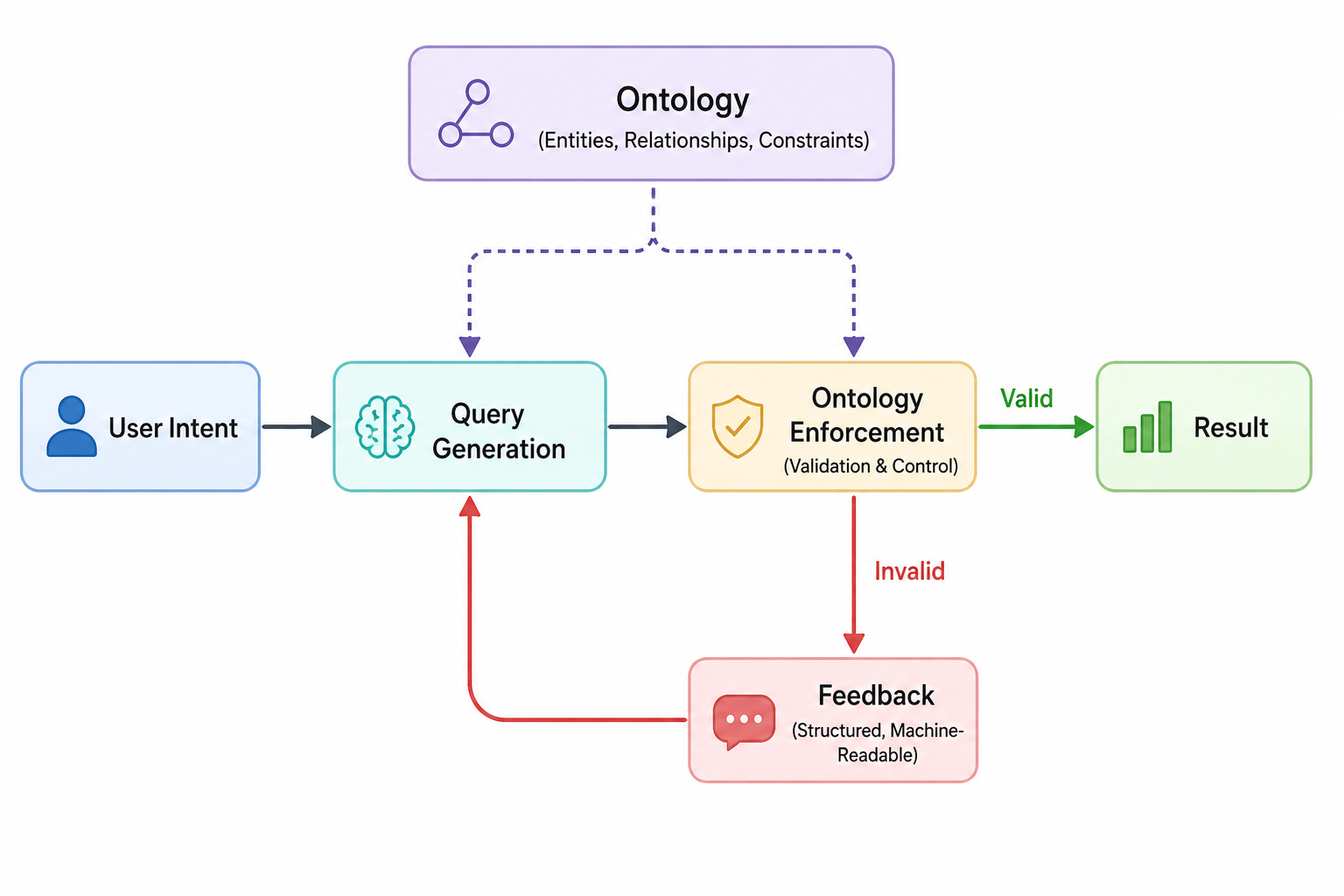
Ontology (semantic foundation)
The ontology defines the domain in terms of entities, relationships, and constraints. It serves as the semantic source of truth, making explicit what the data represents and how different elements are connected.
Query generation (intent → query translation)
Typically powered by a large language model, this component translates user intent into executable queries. Instead of relying on schema inference, it maps requests onto the concepts and relationships defined in the ontology, reducing ambiguity during query construction.
Ontology enforcement layer (validation and control)
This layer acts as a gatekeeper, ensuring that generated queries conform to the ontology. It validates entities, relationships, and constraints before execution, preventing semantically invalid operations from reaching the data layer.
Feedback mechanism (self-correction loop)
When a query fails validation, the system returns structured, machine-readable feedback that explains the violation in semantic terms. This enables the agent to iteratively refine its queries and improve over time, and can also serve as a training signal for fine-tuning or reinforcement learning.
How Ontology-Driven Agents Work
The operation of an ontology-driven agent begins with a user request, often expressed in natural language. In simple scenarios, a language model can map this request directly to a query. However, in real-world enterprise environments, this process is far more complex. Databases may contain a large number of tables with deeply interconnected relationships and implicit business rules. In such settings, language models frequently misinterpret the underlying context.
These misinterpretations typically fall into two categories. In some cases, the agent generates queries that are syntactically correct and executable but produce incorrect results because they rely on relationships that do not exist in reality. In other cases, the generated queries fail entirely due to structural or logical inconsistencies. When failures occur, traditional database systems return error messages that lack sufficient semantic context, making it difficult for the agent to understand what went wrong or how to correct it.
Ontology-driven systems address these challenges by introducing an explicit semantic layer between the agent and the data. Instead of inferring meaning from schemas, the agent maps user intent onto well-defined concepts and relationships from the ontology. This significantly reduces ambiguity and helps prevent semantic hallucination during query generation.
Once a query is produced, it is passed through the ontology enforcement layer. This layer validates the query against the ontology, ensuring that all entities, relationships, and operations are logically valid. If the query violates the ontology, it is rejected before execution, preventing incorrect results and unnecessary system errors.
Importantly, the system provides more than just rejection. It returns structured, LLM-readable feedback that explains why the query is invalid in terms of the domain model. This transforms error handling into a learning signal. The agent can use this feedback to revise its query and attempt again, forming an effective self-correction loop. Over time, this feedback can also be incorporated into model training, enabling continuous improvement and better alignment with the domain.
Benefits of Ontology-Driven Agents
The adoption of an ontology shifts data interaction from a structure-based approach to a semantics-driven model. Instead of navigating tables and fields, both humans and AI agents operate on clearly defined concepts and relationships.
This shift brings several practical benefits:
Reduced semantic hallucination
In complex environments, AI-generated queries often appear valid but rely on relationships that do not actually exist. By grounding query generation in explicitly defined entities and relationships, ontology-driven agents significantly reduce this type of semantic hallucination, ensuring that outputs align with the real structure of the domain.
Meaningful, machine-readable feedback and self-correction
Traditional database systems return low-level error messages that lack semantic context. Ontology-driven systems instead provide structured feedback that explains violations in terms of the domain model. This makes errors understandable to both humans and AI systems, rather than just signaling failure. This feedback also enables a self-correction loop, allowing the agent to iteratively refine queries and converge on valid, meaningful operations without manual intervention.
Support for continuous learning
Structured feedback can also serve as a training signal for long-term improvement. It can be incorporated into fine-tuning or reinforcement learning pipelines, enabling the agent to internalize domain constraints and improve performance over time.
Ontology-Driven Agents vs Traditional AI Agents
The key difference between ontology-driven agents and traditional AI agents lies in how they interpret and validate data interactions. Traditional agents rely heavily on learned patterns and schema-level cues, which can be effective in simple scenarios but often break down in complex environments. Without explicit grounding, these agents are prone to generating plausible but incorrect results.
Ontology-driven agents, on the other hand, are anchored in a formal representation of the domain. This grounding ensures that all queries and operations are consistent with real-world semantics. It also enables stronger guarantees around correctness and explainability, since every decision can be traced back to the ontology. In this sense, ontology-driven agents combine the flexibility of statistical AI with the rigor of symbolic reasoning.
Knowledge Graphs in Ontology-Driven Agents
In ontology-driven systems, data originates from existing sources, while the ontology defines its meaning in terms of entities, relationships, and constraints. Based on this semantic model, the data is organized into a knowledge graph, where entities and relationships reflect the structure defined by the ontology.
This alignment allows agents to reason about data in a more intuitive way. Instead of constructing complex joins across tables, the agent can traverse relationships that directly reflect real-world connections. This simplifies both query generation and result interpretation, while also enabling more advanced capabilities such as inference and context-aware reasoning.
In practice, knowledge graphs serve as the operational layer where the semantic model defined by the ontology is applied to real data, making them a key enabler of ontology-driven systems.
When Should You Use Ontology-Driven Agents?
AI agents are particularly valuable in systems that rely on AI-driven data access, such as natural language interfaces or autonomous data exploration tools. However, when data is spread across many tables without an explicit semantic model, AI systems often misinterpret how the data is connected. While generated queries may appear syntactically correct, they may rely on relationships that do not actually exist, leading to incorrect results.
Ontology-driven agents are best suited for this scenario. By making the underlying semantics explicit and enforcing them during query generation and execution, they ensure that agent behavior remains consistently aligned with domain logic, even as data and business logic grow in complexity.
Data Access with AI Assistant
PuppyGraph offers a seamless, agent-driven interface that enables direct interaction with data through its built-in AI assistant. With this assistant, both developers and business users can explore complex datasets using intuitive, conversational queries.
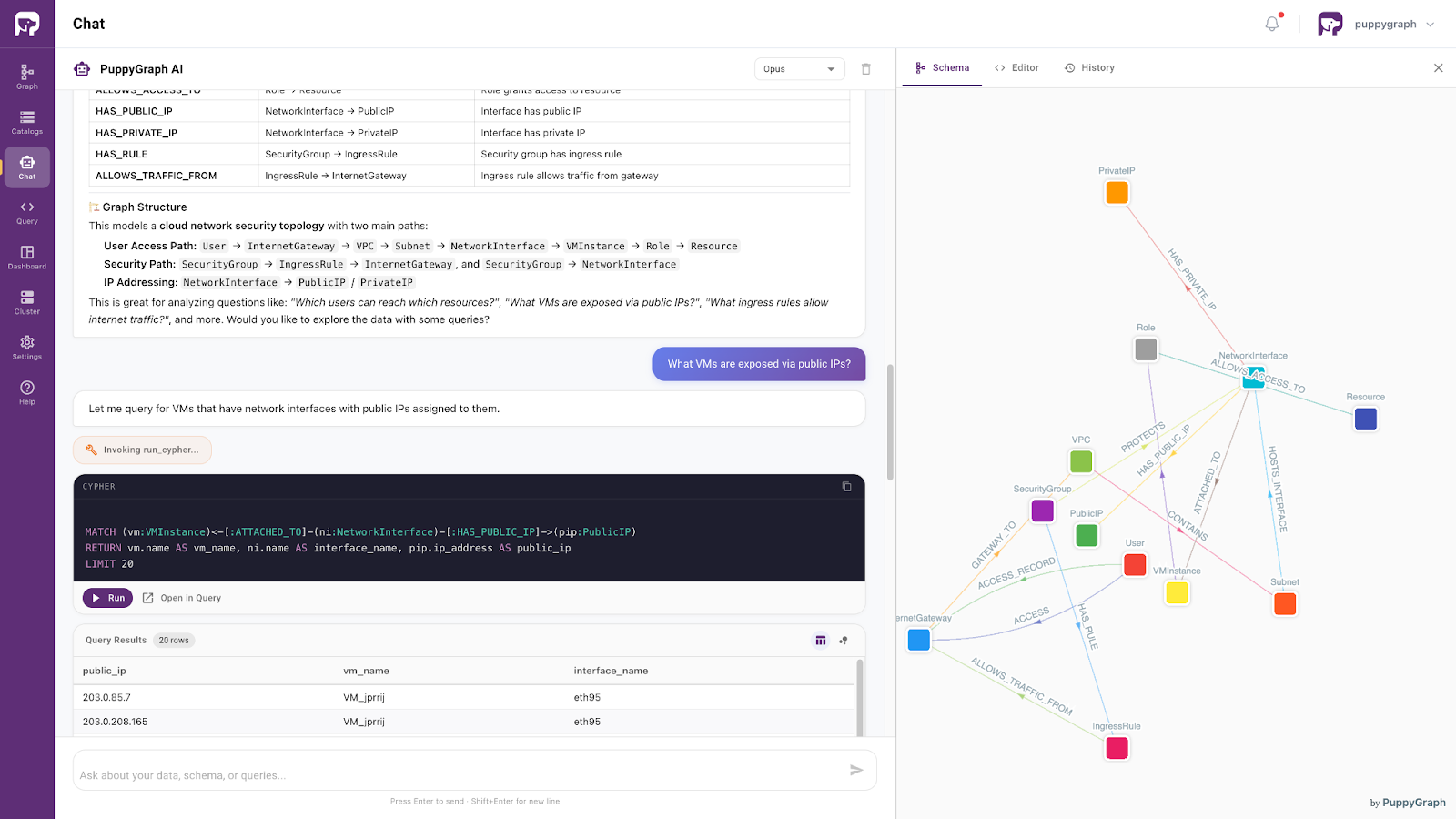
Built on an ontology-enforced foundation, the assistant enables precise data access through natural language. By interpreting user intent within a well-defined semantic framework, it retrieves relevant information with accuracy and consistency. As a result, the database evolves from a static, technically complex system into an interactive and responsive knowledge layer, one that preserves semantic integrity while delivering clear, human-readable insights.
Conclusion
Ontology-driven agents represent a fundamental shift from structure-based to meaning-based data interaction. By combining the flexibility of language models with the rigor of explicit semantic models, they reduce ambiguity, prevent invalid reasoning, and enable more reliable access to complex data. The addition of validation and feedback mechanisms further strengthens their ability to self-correct and continuously improve over time.
As data ecosystems continue to grow in scale and complexity, approaches that rely solely on implicit structure or pattern recognition will struggle to maintain accuracy. Ontology-driven systems provide a path forward by ensuring that both humans and AI agents operate within a shared, well-defined understanding of the domain. This makes them a critical foundation for the next generation of intelligent, trustworthy data platforms.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see how ontology-driven agents bring semantic validity to your data workflows.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install