

Announcing PuppyGraph on Google Cloud Lakehouse: Enforced Ontology for AI Agents on Iceberg

The open lakehouse has become the foundation for modern data infrastructure. Google Cloud's Lakehouse, built on Apache Iceberg, provides a managed, open, and high-performance lakehouse on Cloud Storage. With Lakehouse Runtime Catalog and its support for the Iceberg REST Catalog API, multiple engines can discover and operate on the same Iceberg data through a single, standard interface. As AI agents, LLM-powered applications, and GraphRAG pipelines become consumers of lakehouse data, a new challenge emerges: these systems need more than raw tables. They need to understand what entities exist, how they relate, and what the data means. They need an ontology that provides semantics, validated APIs, and structured, machine-readable feedback for self-correcting agent systems.
PuppyGraph provides this ontology layer without the overheads of a separate graph database. Connecting directly to Lakehouse Iceberg tables with zero ETL, PuppyGraph defines a graph schema over existing lakehouse data that serves as an enforced ontology for both human analysts and AI agents. PuppyGraph also includes a built-in AI agent that leverages this ontology to answer natural language questions directly over your tables.
Lakehouse: An Iceberg-Native Lakehouse on Google Cloud
Apache Iceberg has emerged as the open table format standard for building modern data lakehouses. It brings capabilities like ACID transactions, schema evolution, partition flexibility, and time-travel to data stored on object storage, enabling organizations to manage and query massive analytical datasets without being locked into a proprietary system. Its growing adoption across the industry reflects a clear trend: the future of data analytics is open.
To build an open lakehouse on this foundation, Google Cloud offers Lakehouse — a storage engine that unites Google Cloud and open-source services to create a unified interface for advanced analytics and AI. Lakehouse provides the foundation for building an open, managed, and high-performance lakehouse with automated data management and built-in governance using Apache Iceberg.
At the core of Lakehouse's Iceberg support are Lakehouse Iceberg tables. These tables store data in Apache Iceberg format on Cloud Storage, giving organizations full data ownership while benefiting from managed infrastructure. Lakehouse extends Cloud Storage management capabilities to Iceberg data, including storage Autoclass for efficient data tiering, customer-managed encryption keys (CMEK), and automated table maintenance such as compaction and garbage collection to keep tables optimized without manual intervention. Lakehouse Iceberg tables also integrate with BigQuery, enabling fully managed capabilities such as high-throughput streaming ingestion, auto-reclustering, and native integration with Vertex AI.
Underlying Lakehouse Iceberg tables is the Lakehouse Runtime Catalog, which serves as a unified, managed, serverless, and scalable metadata service built on Google's planet-scale infrastructure. Lakehouse Runtime Catalog supports the Apache Iceberg REST Catalog API, providing a standard interface that enables true openness and interoperability across data engines. External engines, including Apache Spark, Apache Flink, and Trino can all discover and operate on the same Iceberg tables through this single catalog. This is the open foundation that PuppyGraph builds on, adding an enforced ontology layer that makes lakehouse data meaningful to AI agents
PuppyGraph: The Ontology Layer for AI Agents
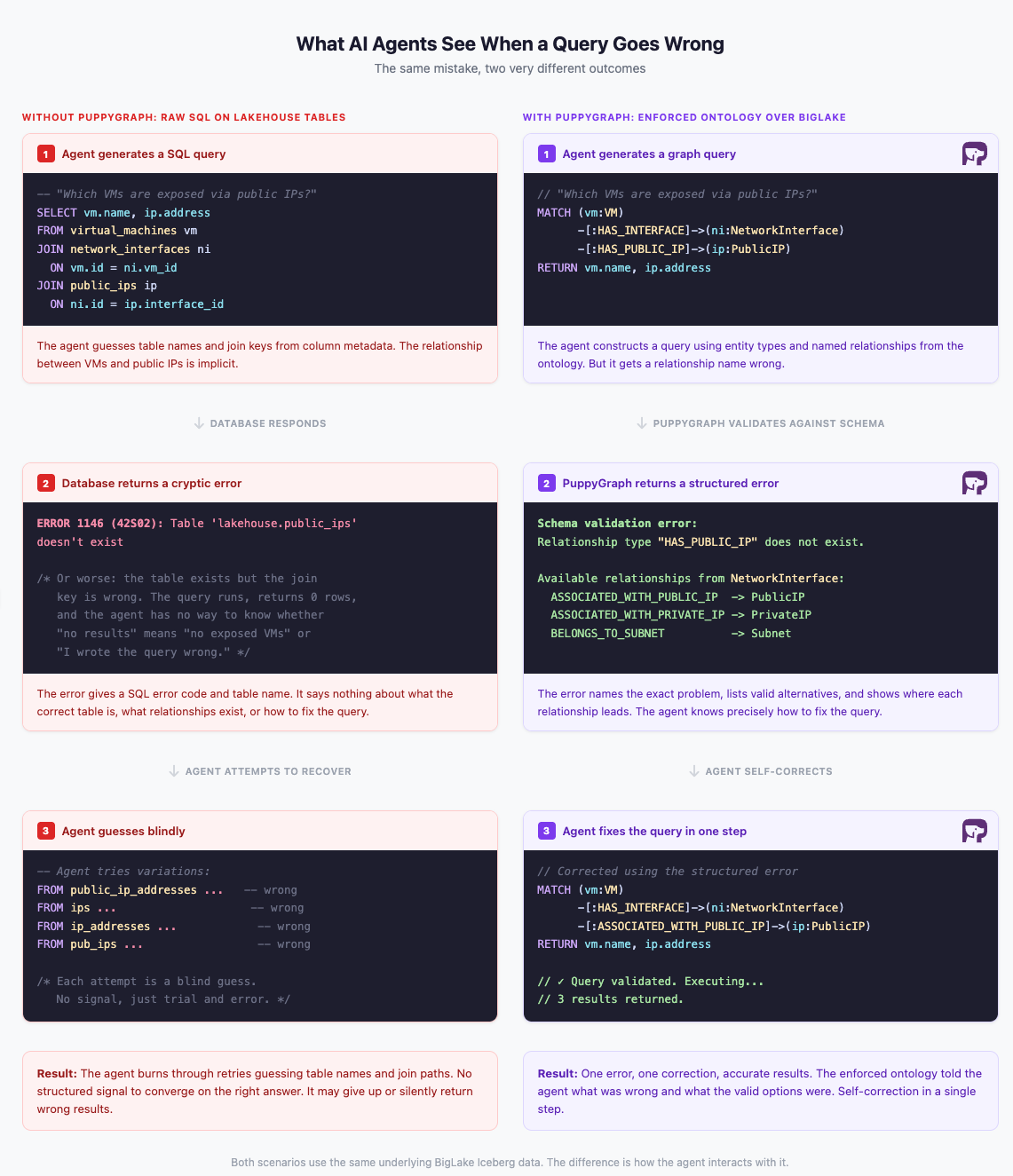
The open lakehouse stores data at scale, but AI agents need more than access to tables and columns. They need to understand the topology of the data: what entities exist, how they connect through explicit, named relationships, and what paths can be traversed to answer a question. Relational schemas encode relationships implicitly through foreign keys and join logic, leaving agents to guess at structure. A graph model makes these relationships first-class and traversable, but how that model is delivered to agents matters.
Storing an ontology in a separate graph database gives agents a reference they can consult, but it does not enforce correctness at query time. An agent can still construct a query referencing a relationship that doesn't exist, and the database will attempt to execute it. A separate graph database also introduces the complexity the open lakehouse was designed to eliminate: data extraction pipelines, a second store to keep in sync, and duplication that undermines data openness. What agents need is an ontology that is not just readable but enforced, one that validates every query, rejects invalid references, and returns structured feedback the agent can use to self-correct, all while keeping the data in place without additional ETL or duplication.
PuppyGraph provides the missing ontology layer. As a distributed graph query engine, PuppyGraph connects directly to the data in your Lakehouse with zero ETL and no data duplication. You define a graph schema over your existing tables, declaring vertex types, edge types, and their properties. This schema is not merely a query convenience; it is an ontology that captures the semantic structure of your data, making it accessible and meaningful to both humans and machines.
Unlike an ontology that agents can only read, PuppyGraph's ontology is enforced. Every query is validated against the graph schema before execution. Reference an entity type that doesn't exist? PuppyGraph rejects the query and tells the agent exactly what is invalid and what the valid options are. This turns the ontology into a two-way contract between the system and the agent: the schema provides the context for the agent to generate accurate queries, and when it gets something wrong, the structured errors give it precisely the signal it needs to correct itself. PuppyGraph's own built-in AI agent demonstrates this in practice, using the enforced ontology to answer natural language questions directly over the graph, self-correcting in real time when needed.
Under the hood, PuppyGraph is built for performance at scale. Its distributed architecture uses native sharding and shuffling to partition graph data efficiently across compute nodes, with a scale-out massively parallel processing (MPP) engine and vectorized execution that delivers subsecond response times even on complex multi-hop traversals. A query optimizer built specifically for graph complexity ensures that deeply connected queries are planned and executed efficiently.
PuppyGraph also supports data federation, querying across multiple data sources without consolidating them into a single store. It speaks openCypher and Gremlin, the two most widely adopted graph query languages. And its metadata-driven schema approach allows teams to create multiple graph views from the same underlying data, iterating on models quickly without rebuilding data pipelines.
Integrating PuppyGraph with Lakehouse
PuppyGraph connects to Lakehouse Iceberg tables through Lakehouse Runtime Catalog's Iceberg REST Catalog API. In PuppyGraph's Web UI, you select Google Lakehouse REST as the metastore type and provide the REST catalog endpoint, your GCS bucket path, and your Google Cloud project ID. For more details, see the Getting Started and Connection guides in the PuppyGraph documentation.
For authentication, PuppyGraph uses Google Cloud's Application Default Credentials (ADC). When running on a Google Cloud VM, PuppyGraph automatically uses the attached service account. Outside of GCP, a service account key file can be provided by setting the GOOGLE_APPLICATION_CREDENTIALS environment variable and mounting the key file into the PuppyGraph container.
Once connected, you define a graph schema over the Lakehouse Iceberg tables, mapping them to vertex types, edge types, and their properties. This schema becomes the enforced ontology described in the previous section. PuppyGraph's built-in AI assistant leverages this ontology directly: it accepts natural language questions, generates graph queries against the schema, self-corrects using structured error feedback when needed, and iteratively explores related queries to build up a comprehensive answer. Rather than returning a single query result, the assistant synthesizes its findings into a summary or report, making it a practical tool for AI-driven investigation and analysis on Lakehouse Iceberg data.
Demo: Cloud Security Analytics with AI Agents on Lakehouse
The full demo, including code, data, and setup instructions, is available on GitHub.
The demo uses a synthesized cloud security network dataset stored as Lakehouse Iceberg tables. The dataset models infrastructure entities such as users, VPCs, subnets, security groups, VMs, network interfaces, public and private IPs, internet gateways, roles, resources, and ingress rules, along with the relationships between them. PuppyGraph defines a graph schema over these tables with 12 vertex types and 13 edge types, creating an ontology that captures the structure of the cloud security environment.
Any AI agent connecting to PuppyGraph can leverage this ontology. The schema tells the agent what entity types and relationships exist, the query API validates every request against the schema, and structured errors guide the agent to self-correct when a query is invalid. PuppyGraph's built-in AI assistant demonstrates this workflow end to end.
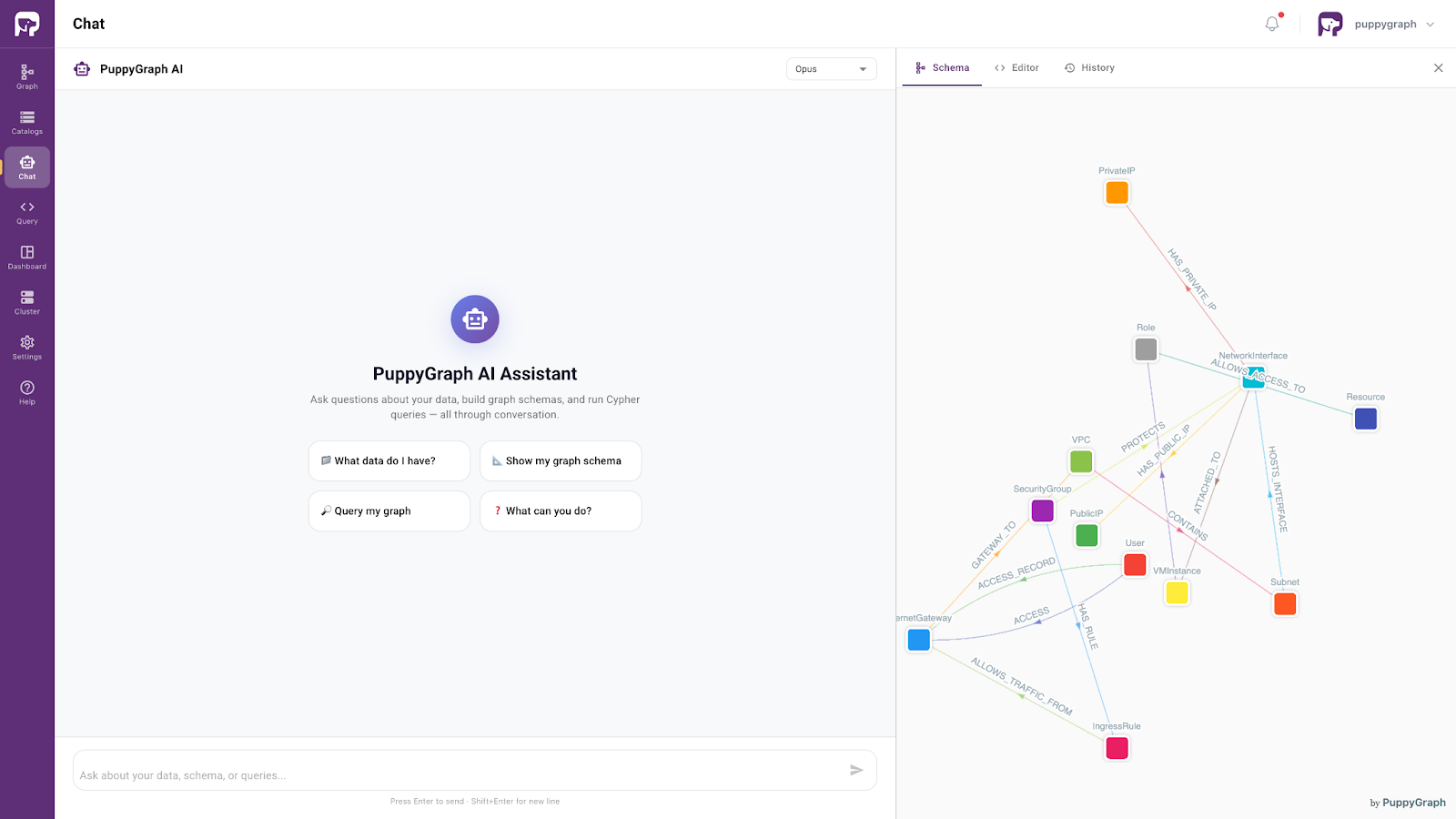
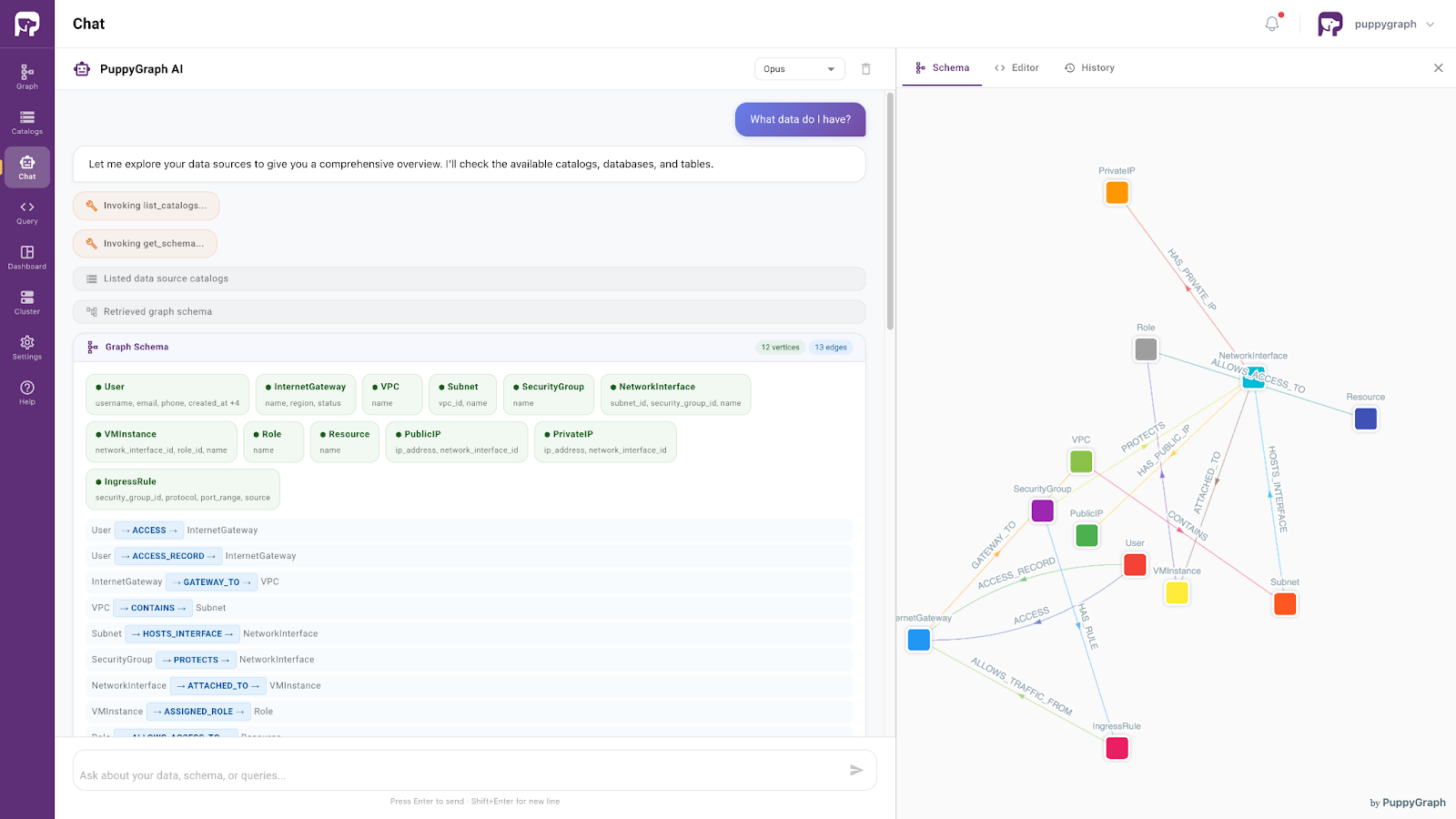
When you open the assistant, it displays the graph schema alongside the chat interface. Start by asking "What data do I have?" The assistant invokes the schema, lists the available entity types and relationships, and explains the graph structure, including the main traversal paths through the security topology.
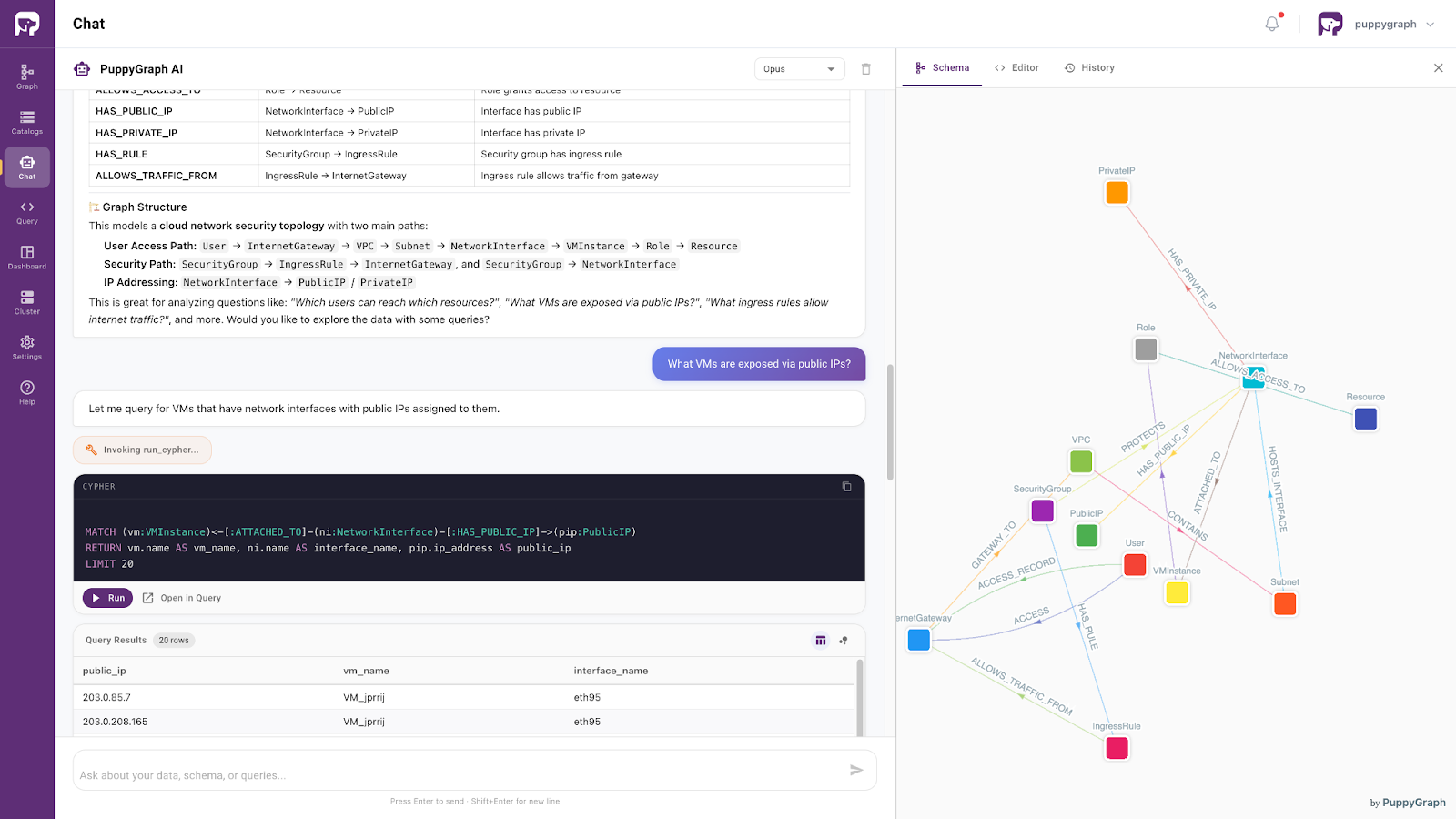
From there, you can ask follow-up questions in natural language. For example, "What VMs are exposed via public IPs?" The assistant generates a Cypher query against the ontology, executes it, and presents the results. It then continues with related analysis, identifying the most exposed VMs, shared network interfaces, and key observations, and delivers a structured summary of its findings.
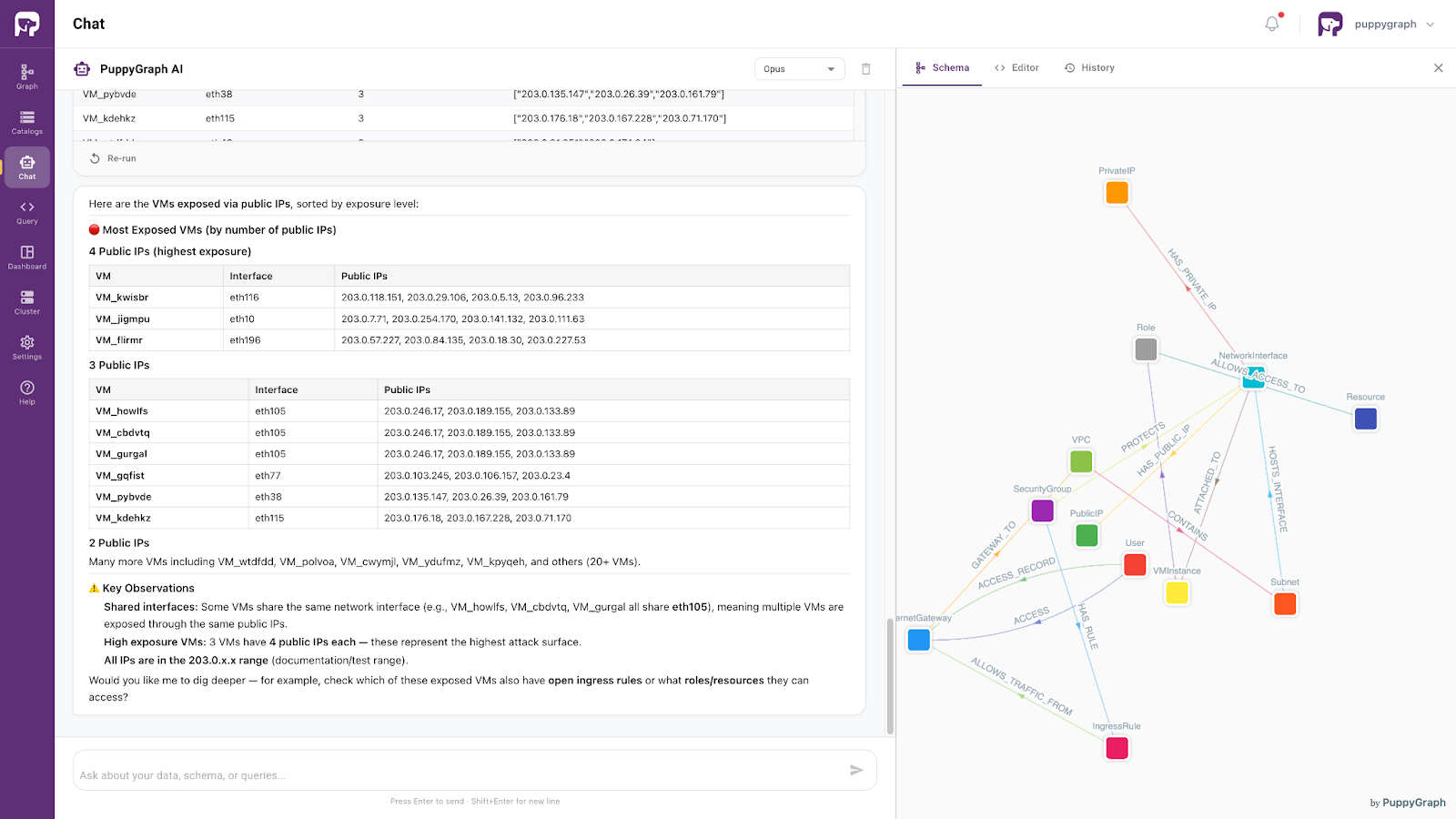
This workflow is not limited to PuppyGraph's built-in assistant. Any LLM-powered application, GraphRAG pipeline, or autonomous agent can follow the same pattern: read the ontology, generate queries, and use structured error feedback to self-correct.
Get Started
Google Cloud's Lakehouse provides the open, managed, Iceberg-native lakehouse foundation. PuppyGraph adds the enforced ontology layer that makes this data consumable by AI agents, with structured feedback that turns every invalid query into a self-correcting step toward the right answer. Together, they close the gap between raw lakehouse data and reliable AI-driven analytics.
Ready to try it? Explore the full cloud security demo on GitHub, complete with code, data, and setup instructions. To learn more about building an Iceberg-native lakehouse, visit Google Cloud Lakehouse. To run PuppyGraph on your own data, download the forever-free Docker edition. And if you'd like to see how enforced ontology works on your lakehouse at scale, book a demo with our team.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install