

Recursive SQL: A Complete Guide

Recursive SQL, standardized in SQL:1999, enables a query to iteratively reference its own results, transforming relational databases from flat data processors into engines capable of hierarchical and algorithmic computation. Through Recursive Common Table Expressions (CTEs), it replaces application-level loops with a declarative, set-based approach within the query engine, improving efficiency, reducing network overhead, and preserving transactional consistency when traversing complex structures such as organizational hierarchies or Bills of Materials.
In the era of Agentic AI, however, the challenge shifts from expressing recursion to ensuring semantic correctness. In large enterprise schemas, agents often generate syntactically valid but logically incorrect queries due to missing business context. Ontologies address this by providing a semantic abstraction over fragmented tables, while ontology enforcement validates queries against business rules, ensuring accurate and reliable data access.
What is Recursive SQL
Recursive SQL refers to a specific type of query execution that allows a statement to reference its own output. While standard SQL queries operate on fixed sets of data, recursive SQL enables the processing of hierarchies and graphs that have an arbitrary or unknown depth. This capability was formally introduced into the SQL:1999 standard (also known as SQL3) through the implementation of Common Table Expressions (CTEs) using the WITH RECURSIVE clause.
The fundamental purpose of recursive SQL is to solve problems that relational algebra, specifically the original version proposed by E.F. Codd, could not easily address: transitive closure. In mathematical terms, finding a transitive closure means identifying all elements reachable from a starting point through any number of intermediate steps. In a database context, this allows a developer to query data structures such as:
- Trees: Navigating organizational charts (manager to employee) or folder structures.
- Acyclic Graphs: Processing a Bill of Materials (BOM) where parts are composed of sub-parts.
- Cyclic Graphs: Identifying routes in a transportation network or links between social media profiles.
Prior to the SQL:1999 standard, developers often relied on proprietary extensions (such as Oracle’s CONNECT BY syntax, introduced in the 1970s) or application-level loops. Recursive SQL standardized this process by defining a specific execution model: starting with an initial subquery (the seed) and then applying a recursive subquery that runs repeatedly until no new rows are produced. This approach allows SQL to be "Turing-complete" in its computational power, meaning it can theoretically perform any calculation that a general-purpose programming language can.
How Recursive SQL Works
Before the elegant syntax of Modern SQL, traversing hierarchical data was a significant limitation of relational databases. Since E.F. Codd’s original relational algebra was not inherently designed for recursion, the industry underwent a decades-long evolution to find a way to solve the transitive closure problem, the ability to find all connected nodes in a graph or tree.
1. The Pre-Standard Era: Procedural and Proprietary Loops
In the earliest days of relational databases, there was no native "recursive" way to query data. If a developer needed to navigate an organizational chart, they generally had two options:
- Application-Level Iteration: The "N+1" approach. The application would query a row, look at the parent_id, and then fire a separate, subsequent query to the database for every child. This was slow, resource-heavy, and created massive network overhead.
- Procedural Code: Databases like Oracle or IBM DB2 allowed for stored procedures (PL/SQL or SQL/PL). Developers wrote manual WHILE loops and used temporary tables to store intermediate results. While this kept the data inside the engine, it was verbose and difficult to maintain.
2. Early Proprietary Implementations
Recognizing the demand for tree traversal, vendors began introducing specialized, non-standard syntax.
- Oracle’s CONNECT BY: Introduced in the late 1970s, this was the first major breakthrough. It allowed developers to define a hierarchy using START WITH and PRIOR keywords. While revolutionary, it was a "black box" operation: proprietary to Oracle and structurally different from the set-based logic of standard SQL.
- IBM’s Early CTEs: In the 1980s and 90s, IBM began experimenting with the concept of a "Common Table Expression" (CTE) that could reference itself, laying the logical groundwork for what would eventually become the industry standard.
3. The Unified Idea: The Fixpoint Logic
Despite the different syntax (whether it was Oracle's keywords or IBM's early loops), the underlying mathematical goal was always the same: reaching a fixpoint. The core design principle of any recursive SQL implementation is the seed-and-grow philosophy:
- Identify the Seed: Find the starting point (the root of the tree).
- Iterate: Join the current results back to the source table to find the "next level" of data.
- Accumulate: Add the new results to the existing set.
- Terminate: Stop only when an iteration returns zero new rows (the fixpoint).
4. The Modern Solution: Recursive CTEs (SQL:1999)
The evolution culminated in the SQL:1999 standard, which formally introduced the WITH RECURSIVE Common Table Expression. This was a transformative moment: it took the iterative power of procedural code and the tree-traversal capabilities of proprietary syntax and wrapped them into a single, declarative, set-based framework.
Today, almost every major relational engine (PostgreSQL, SQL Server, MySQL 8.0+, MariaDB, and Oracle) supports this standard. By shifting from proprietary hacks to Recursive CTEs, the industry moved from "how do I loop through these rows?" to "what does the final connected set look like?", allowing the database optimizer to handle the heavy lifting of memory management and execution planning.
Recursive Common Table Expressions
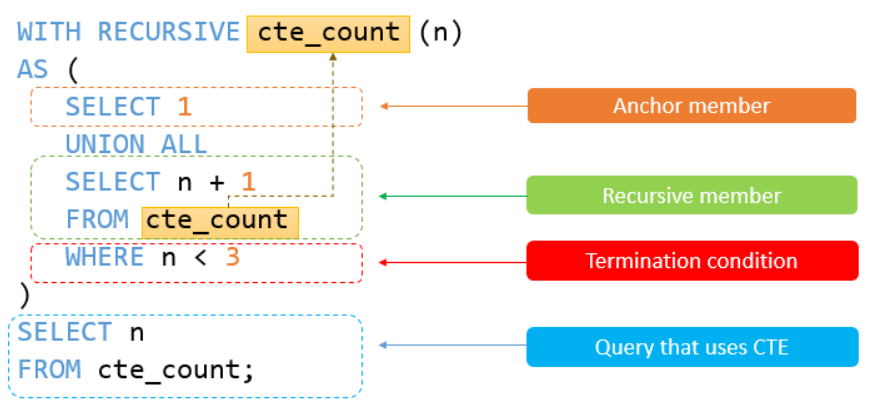
To understand how Recursive SQL works, we must look at the Recursive CTE. Think of a CTE as a temporary result set that exists only for the duration of the query. A "Recursive" CTE is special because it is defined in three parts that work together to "climb" through your data.
The Anatomy of the Query
A recursive CTE follows a strict three-part structure within a WITH RECURSIVE block:
- The Anchor Member (The Seed): This is a standard query that returns the starting point of your recursion (e.g., the CEO of a company or the root folder of a drive). It runs exactly once.
- The Recursive Member (The Iteration): This query references the CTE itself. It tells the database how to find the "next level" of data based on the current level.
- The Termination Condition: Recursion stops automatically when an iteration produces no new rows (reaching what mathematicians call a Fixpoint).
A Concrete Example: The Org Chart
Imagine an employees table where each person has an id, a name, and a manager_id. We want to find everyone who works under "Alice" (ID: 1), no matter how deep the hierarchy goes.
WITH RECURSIVE org_chart AS (
-- 1. ANCHOR MEMBER: Find the starting person
SELECT id, name, manager_id, 1 AS level
FROM employees
WHERE id = 1 -- Alice
UNION ALL
-- 2. RECURSIVE MEMBER: Join the table to the CTE
SELECT e.id, e.name, e.manager_id, oc.level + 1
FROM employees e
INNER JOIN org_chart oc ON e.manager_id = oc.id
)
SELECT * FROM org_chart;The Output:
Understanding the Engine: Working Set vs. Accumulator
To grasp how the database processes this without crashing, you need to understand two conceptual "buckets":
- The Working Set: This is the physical buffer containing only the rows produced by the immediately preceding iteration. According to the SQL standard, the recursive reference within the CTE does not look at the entire result set accumulated so far; it looks specifically at this "new" data. This ensures the query moves forward to explore new branches of the hierarchy rather than re-processing the same rows infinitely.
- The Accumulator (A Logical Concept): Unlike the Working Set, the Accumulator is not a state that the recursive engine needs to "read" or manage to perform the next step. It is a logical distinction representing the final collection of all rows (the union of the Anchor and every Working Set) that will be returned once the query finishes.
Fixpoint Semantics: The Stopping Logic
The execution of a recursive CTE is based on Fixpoint Semantics. The database continues to evaluate the recursive member, using the output of iteration \(n\) as the input for iteration \(n+1\).
The process terminates when an iteration produces an empty set. This is the "fixpoint": the mathematical state where no further information can be derived from the data. At this point, the recursion safely shuts down, and the logical Accumulator is materialized as your final result.
Step-by-Step Execution:
- Iteration 0 (Anchor): The engine finds Alice.
- Working Set: {Alice}
- Accumulator: {Alice}
- Iteration 1: The engine looks for anyone whose manager_id is in the current Working Set (Alice). It finds Bob and Charlie.
- Working Set: {Bob, Charlie}
- Accumulator: {Alice, Bob, Charlie}
- Iteration 2: The engine looks for anyone whose manager_id is in the current Working Set (Bob or Charlie). It finds David.
- Working Set: {David}
- Accumulator: {Alice, Bob, Charlie, David}
- Iteration 3: The engine looks for anyone reporting to David. It finds nothing.
- Working Set: {Empty}
- STOP: The Fixpoint is reached.
Constraints: Why "Linear" Recursion?
Most databases require linear recursion. This is a safety rule to keep the query predictable and performant.
- Single Reference: You can only reference the CTE name once inside the Recursive Member. You can't join the CTE to itself.
- No Aggregates in Recursion: You generally cannot use SUM(), GROUP BY, or DISTINCT inside the recursive part. Because the Working Set is constantly changing, the database wouldn't be able to calculate a "final" sum until the very end anyway.
- Set-Based Efficiency: By following these rules, the database can treat the recursion as a high-speed "semi-join" in memory, making it far faster than an application-level loop.
Recursive SQL vs Iterative Approaches
To fully appreciate the power of Recursive SQL, it must be compared against the traditional alternative: Iterative Approaches. This usually involves application-layer loops (like a while loop in Python or Java) that repeatedly query the database to "crawl" through a hierarchy.
The Recursive SQL Performance Profile
Recursive SQL operates under a set-based paradigm within the database engine itself. Its performance and behavior are defined by several key factors:
- Reduced Network Latency: Because the entire traversal logic lives on the database server, there is only one round-trip between the application and the database. The "heavy lifting" of finding the next level of data happens internally.
- Execution Plan Optimization: Modern query optimizers (like those in PostgreSQL or SQL Server) can create an execution plan that treats the recursion as a specialized join. This allows the engine to use indexes effectively and manage memory buffers for the "Working Set" efficiently.
- Declarative Simplicity: The developer defines what the connected set looks like, rather than how to loop through it. This results in more concise, maintainable code.
The Iterative Approach Profile
In an iterative or procedural approach, the application code acts as the "brain," while the database acts as a simple "storage locker." This leads to a very different performance footprint:
- The N+1 Problem: For every node discovered, the application must send a new query to find its children. If an organizational chart has 1,000 employees, the application might execute 1,000 separate SELECT statements, leading to massive network overhead.
- Memory Overhead on the Client: The application must maintain the state of the traversal (which nodes are visited, which are pending) in its own memory. For very large graphs, this can lead to memory exhaustion in the application tier.
- Consistency Risks: Because the data is retrieved in multiple steps over time, there is a risk that the underlying data might change (an employee is moved or deleted) midway through the loop, leading to an inconsistent "snapshot" of the hierarchy.
Comparison Summary: SQL vs. Application Logic
In short, while iterative approaches provide more granular control and are sometimes easier for developers to debug using standard programming tools, they almost always fall short in terms of scalability and performance. Recursive SQL transforms the database from a passive data store into an active computational engine, allowing for high-speed traversal that remains efficient even as hierarchies grow deeper.
As we will explore in the When to Use Recursive SQL section, choosing the right tool depends largely on the depth of your data and your tolerance for network latency.
Common Errors in Recursive SQL
While recursive CTEs are powerful, they introduce specific logical and performance risks that do not exist in standard flat queries. Understanding these common pitfalls is essential for maintaining database stability and data integrity.
1. Infinite Loops and Termination Failures
The most frequent error in recursive SQL is the failure to reach a fixpoint, the state where an iteration produces no new rows. This typically happens when the data contains cycles (e.g., in a graph where Node A points to B, and B points back to A).
- The Cause: If the recursive member continues to find "new" rows because of a circular reference, the engine will loop indefinitely until it exhausts memory or hits a system timeout.
- The Fix: Use UNION instead of UNION ALL to automatically discard duplicate rows, or maintain a "depth" counter and a "path" array to detect and stop the recursion if a node is revisited.
2. Violating Linear Recursion Constraints
The SQL:1999 standard generally mandates linear recursion for stability. Many developers encounter "Invalid Recursive Reference" errors by attempting complex joins within the CTE.
- The Cause: Including the recursive CTE name more than once in the FROM clause, or attempting to use the recursive reference inside a subquery or on the right side of a LEFT OUTER JOIN.
- The Consequence: Most database optimizers (like those in PostgreSQL or SQL Server) cannot resolve the execution plan for non-linear recursion, leading to syntax or runtime errors.
3. Improper Use of Aggregate Functions
A common logical error is attempting to use GROUP BY, DISTINCT, or aggregate functions like SUM() or COUNT() inside the recursive member of the CTE.
- The Restriction: According to standard SQL semantics, the recursive member cannot contain grouping or aggregation because it operates on the "working set" of the previous iteration, not the entire accumulated set.
- The Fix: Perform calculations by passing running totals as columns through the recursion (e.g., parent_total + current_value) rather than calling SUM() within the recursive block.
Advanced Recursive SQL Examples
To truly master recursive SQL, one must look beyond simple parent-child lookups and explore how these queries solve complex structural problems. Based on the logical framework established by the SQL:1999 standard and the implementations seen in systems like PostgreSQL, IBM DB2, and SQL Server, here are three definitive examples of recursive logic in action.
1. The Bill of Materials (BOM) Problem
One of the most common applications of recursive SQL is the Bill of Materials (BOM) explosion. In manufacturing, a product (like a car) is composed of sub-assemblies (engine), which are composed of parts (pistons), which are made of raw materials. To calculate the total cost or quantity of materials, one must traverse an acyclic graph of unknown depth.
The Logic:
The anchor member selects the top-level product. The recursive member then joins the "working set" of parts with the parts table to find all sub-components.
WITH RECURSIVE BOM_Explosion AS (
-- Anchor Member: Start with the final product
SELECT part_id, name, quantity, 1 AS level
FROM parts
WHERE part_id = 'CAR_001'
UNION ALL
-- Recursive Member: Find all sub-components
SELECT p.part_id, p.name, p.quantity, b.level + 1
FROM parts p
INNER JOIN BOM_Explosion b ON p.parent_id = b.part_id
)
SELECT * FROM BOM_Explosion;Insight: In this example, the level column acts as a depth-tracker. This allows the database to keep track of how many steps away from the root each part is, which is essential for visual rendering or indentation.
2. Pathfinding
In networked data, such as flight maps, social networks, or logistics grids, the definitive challenge is finding the shortest path (minimum hops) between two nodes. Because a Recursive CTE naturally processes data in a manner similar to a Breadth-First Search (BFS), it is uniquely suited to identify the most efficient route from a source to a destination.
The Logic:
- The Anchor Member: Initializes the journey at the starting node (e.g., 'New York'), setting the hop count to zero and creating an array to track the traversed path.
- The Recursive Member: Joins the current "working set" of locations with the flights table to find all possible next destinations. It increments the hop counter and appends each new city to the path array.
- Cycle Prevention: A critical filter (ANY(path)) ensures the engine does not revisit a node already present in the current traversal, preventing infinite loops in cyclic networks.
WITH RECURSIVE Travel_Path (current_node, hops, full_path) AS (
-- 1. ANCHOR MEMBER: Start at the origin city
SELECT
destination,
1,
source || ' -> ' || destination
FROM flights
WHERE source = 'New York'
UNION ALL
-- 2. RECURSIVE MEMBER: Discover the next "hop"
SELECT
f.destination,
tp.hops + 1,
tp.full_path || ' -> ' || f.destination
FROM flights f
JOIN Travel_Path tp ON f.source = tp.current_node
WHERE tp.full_path NOT LIKE '%' || f.destination || '%'
AND tp.hops < 10
)
-- 3. FINAL QUERY: Extract the shortest path to the target
SELECT full_path, hops
FROM Travel_Path
WHERE current_node = 'London'
ORDER BY hops ASC
FETCH FIRST 1 ROW ONLY;Key Technical Features in these Examples:
- Depth-First vs. Breadth-First: While standard SQL recursion is naturally breadth-first (it processes all children of the current level before moving deeper), advanced implementations in DB2 and PostgreSQL allow for SEARCH DEPTH FIRST or BREADTH FIRST clauses to control the order of the result set.
- Termination via Predicates: Note how the WHERE NOT is_cycle or WHERE level < max_depth clauses act as safety valves, preventing the "infinite loop" error common in poorly structured recursive CTEs.
By applying these patterns, developers can transform flat relational tables into dynamic, navigable structures that reflect the true complexity of real-world hierarchies.
When to Use Recursive SQL
Choosing between Recursive SQL and an iterative application-layer approach is a strategic decision that hinges on where you want the "computational gravity" of your application to reside. While iterative loops offer a familiar procedural flow for developers, recursive SQL is generally the superior choice for performance, consistency, and data locality.
The Case for Recursive SQL Over Iterative Loops
The shift from iterative logic to Recursive SQL is essentially a shift from "micro-managing" data retrieval to "declaring" a result set. You should favor Recursive SQL in the following scenarios:
- Leveraging the Query Optimizer: Modern database engines are built to handle large-scale joins. When you use a Recursive CTE, the optimizer can utilize indexes on foreign keys (like parent_id) far more effectively than a series of disconnected SELECT statements.
- Minimizing Network Latency: If your hierarchy is deep (e.g., a complex parts catalog with 15+ levels), an iterative approach creates a "chatty" interface. Each level requires a new round-trip between the application and the server, accumulating significant network latency. Because a Recursive CTE executes as a single block of code, it reduces these network round-trip costs to near zero, regardless of the tree's depth.
- Efficient In-Memory Processing: Unlike application-side loops that demand substantial memory for buffering intermediate results, Recursive SQL optimizes memory utilization both internally and externally. By processing working sets directly within the engine's internal structures, it eliminates the need for large memory buffers on the application side while maintaining a compact internal memory footprint.
- Ensuring Transaction Consistency: Recursive SQL ensures that the entire hierarchical traversal is wrapped in a single, atomic transaction. This guarantees a consistent view of the data at the moment the query begins, leveraging the database’s isolation levels to maintain strict data integrity throughout the operation. By executing as a unified statement, it prevents inconsistencies such as phantom reads or partial updates, ensuring the final result remains logically sound.
The New Frontier: SQL:2023 and the Rise of Graph Queries
While Recursive SQL has been the standard for decades, the landscape is shifting. The SQL:2023 standard recently introduced Property Graph Queries (SQL/PGQ), allowing users to query relational data using graph-native logic (like the MATCH clause).
However, because this standard is relatively recent, native support across major database vendors remains in its early stages. For instance, while it is a major focus for future releases of PostgreSQL (targeted for version 19), full enterprise-ready implementations are currently rare.
Data Querying in the Agentic AI Era
Writing complex recursive CTEs used to be a human bottleneck; now, we delegate it to AI agents. However, we’ve traded one challenge for another. When dealing with enterprise-scale databases containing hundreds of tables, an agent often struggles to navigate the "semantic fog." Without a clear understanding of how data relates to real-world business logic, agents frequently produce syntactically wrong or even syntactically valid but logically "hallucinated" results. To solve this, we must move beyond raw schema mapping and adopt ontology and ontology enforcement.
The Semantic Foundation: Ontology and Ontology Enforcement
1. What is Ontology?
In the context of data engineering, an ontology is a formal representation of a set of concepts within a domain and the relationships between those concepts. It acts as a semantic abstraction layer that sits above your physical tables, turning fragmented technical schemas into meaningful business entities (e.g., "Customer," "Transaction," "Product").
2. What is Ontology Enforcement?
Ontology enforcement is the active validation of queries against the defined ontology. It ensures that any query generated, whether by a human or an AI agent, strictly adheres to the structural and logic rules defined in the semantic layer. It serves as a real-time gatekeeper for data integrity.
3. Why These Matter for AI Agents
- Contextual Clarity: Ontologies provide the "why" behind the "what," allowing agents to understand business rules rather than just table joins.
- Reduced Hallucination: By providing an explicit roadmap of relationships, the agent is less likely to invent non-existent paths between data points.
- Improved Self-Correction: Instead of cryptic SQL syntax errors, ontology enforcement provides structured, LLM-readable feedback to the agent for better self-correction loops.
The Solution for Reliable AI Agents
PuppyGraph addresses the limitations of standard LLM-to-SQL workflows by utilizing an ontology-enforced architecture. In complex enterprise environments where databases are intricate and relationships are buried, PuppyGraph acts as the vital bridge between raw data and intelligent agents.
PuppyGraph uses an ontology as a semantic backbone: It provides a formal blueprint that defines exactly how different entities and relationships in your data interact. Rather than forcing an agent to guess how to join thirty different tables, the agent interacts with ontology, which accurately reflects the underlying business context. Ontology enforcement then acts as a validation layer:
- Abstracting Complexity from Massive Schemas: Instead of overwhelming an LLM with hundreds of fragmented tables, PuppyGraph abstracts these into rich, manageable entities and relationships. This reduces the cognitive load on the agent, preventing it from getting lost in intricate join logic or missing business context.
- Eliminating "Silent Failures" and Semantic Hallucinations: In multi-table environments, LLMs often generate "Syntactically Correct, Logically Wrong" queries. PuppyGraph’s explicit semantic layer acts as a source of truth, ensuring the agent doesn't just write valid SQL, but writes the right business logic.
- Bridging the "Feedback Gap" for Self-Correction: Standard database errors (like Column not found) are too cryptic for agents to fix. PuppyGraph converts these into Structured, LLM-Readable Feedback. When an agent violates a business rule, PuppyGraph tells the agent why in semantic terms, enabling an effective, autonomous self-correction loop.
- Fueling Continuous Model Improvement: The structured violation feedback provided by PuppyGraph isn't just for immediate correction: it creates a data goldmine. This feedback can be captured to fine-tune the LLM or for reinforcement learning, allowing the agent to get smarter with every query it attempts.
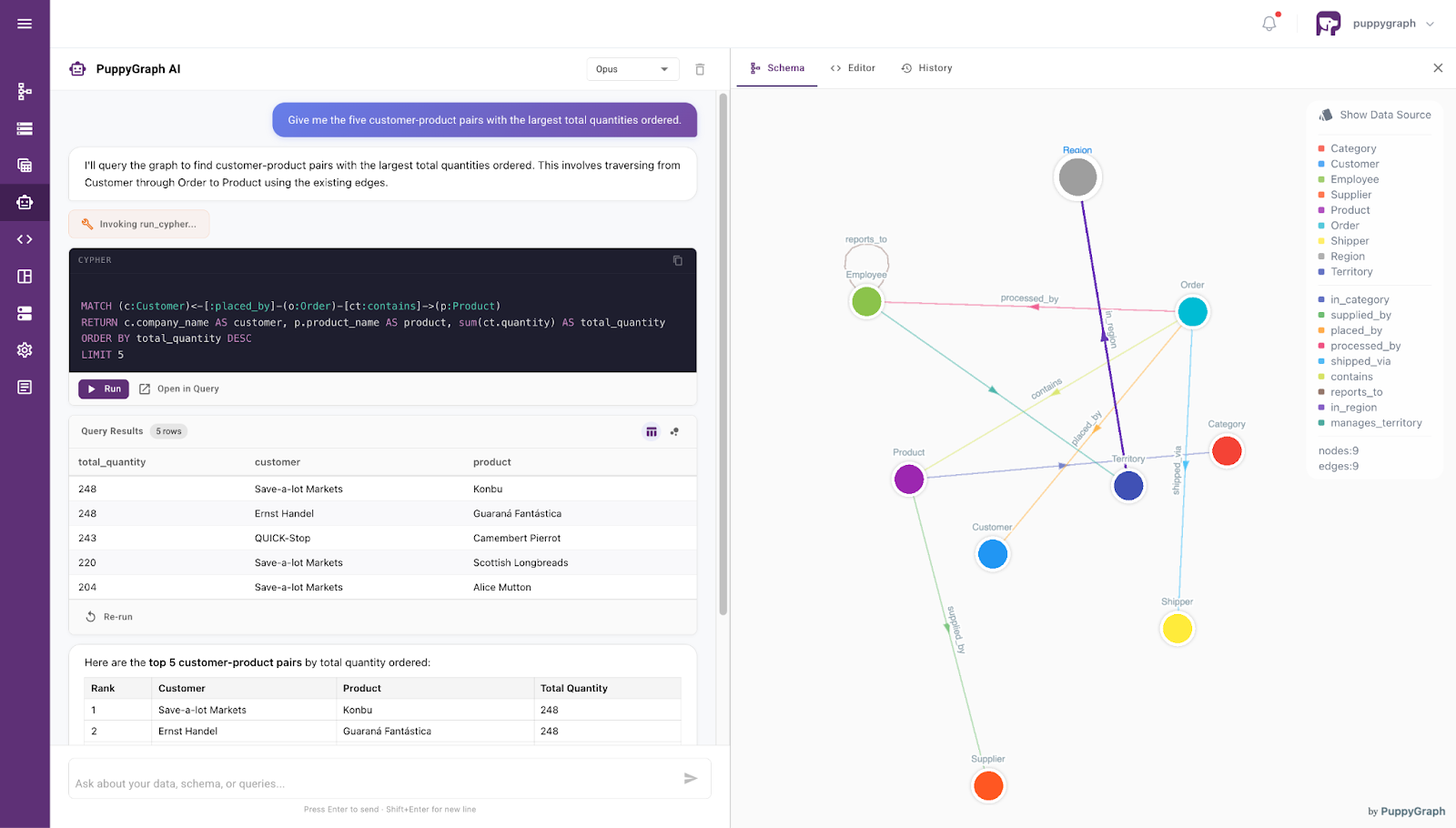
Beyond its architectural benefits, PuppyGraph offers a seamless, end-to-end interface for direct interaction: a built-in agent. This agent empowers users to query complex datasets using intuitive, conversational language, bypassing the need for manual SQL or Cypher drafting entirely. By leveraging the same ontology-enforced backbone described above, the chatbot translates natural language into precise, high-performance queries with pinpoint accuracy. It transforms the database from a static repository into a responsive collaborator, allowing both developers and business stakeholders to extract insights through simple dialogue while maintaining the rigorous semantic integrity of the enterprise schema.
Conclusion
The evolution of Recursive SQL represents a fundamental shift in database history: moving from rigid, flat-file retrievals to dynamic, self-referential computations. By mastering Recursive CTEs, developers unlock the ability to traverse complex hierarchies with the efficiency and safety of a unified, set-based execution model. However, as we move into the Agentic AI era, the challenge is no longer just about writing the recursion: it is about ensuring the semantic accuracy of the traversal.
While Recursive SQL provides the "engine" for navigating data, PuppyGraph provides the "map" through ontology enforcement. By bridging the gap between raw schema and business logic, PuppyGraph ensures that AI agents can leverage recursive power without falling into the traps of semantic hallucination. To experience the next step in this evolution, explore the forever-free PuppyGraph Developer Edition, or book a demo to see how we transform complex data relationships into actionable intelligence.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install