

SQL vs NoSQL: Which is Best Database?
In the rapidly evolving world of data management, choosing the right database remains one of the most critical architectural decisions for developers, architects, and businesses alike. SQL databases, with their structured, relational approach, have powered enterprises for decades, while NoSQL databases emerged to address the demands of massive scale, flexible schemas, and diverse data types in modern applications.
Neither is universally superior. The "best" database depends on specific requirements such as data structure, scalability needs, query complexity, consistency demands, and use cases. This comprehensive guide explores SQL and NoSQL in depth, including the major subtypes of NoSQL, key-value, document, wide-column, and especially graph databases, while comparing them across key dimensions. By the end, you will have a clear framework for making informed decisions tailored to your projects.
What is SQL?
SQL (Structured Query Language) is the standard language used to define, manipulate, and query structured data stored in relational systems. It allows users to create tables, insert and update records, filter and aggregate data, and retrieve information across related datasets through joins. Because SQL is declarative, users describe what data they want, while the database engine determines how to execute the query efficiently.
SQL became the foundation of relational data management because it provides a standardized and expressive way to work with structured data. Its consistency and portability have made it one of the most widely adopted technologies in modern software systems.
SQL databases, also known as relational database management systems (RDBMS), are the systems built around this model. They organize data into tables with predefined schemas consisting of rows and columns, where each table represents an entity and relationships between tables are established through foreign keys.
Popular SQL databases include PostgreSQL, MySQL, Oracle Database, Microsoft SQL Server, and SQLite. These systems excel in maintaining data integrity through ACID properties, ensuring that transactions are processed reliably even during failures or concurrent operations. For example, in a banking application, an SQL database guarantees that when transferring funds from one account to another, either both the debit and credit succeed or neither does.
SQL databases typically enforce schemas at the database level. Developers define tables, columns, data types, constraints, and indexes upfront. This rigidity provides strong data validation and consistency, though it often requires schema migrations as applications evolve. Their support for joins enables complex analytical and transactional queries, while modern systems such as PostgreSQL have also introduced features like JSON support to accommodate semi-structured data without abandoning relational principles.
SQL’s maturity brings robust tooling, extensive security features, and well-established support for backup, replication, and high availability. However, as data volumes grow and application requirements become more dynamic, these strengths can also introduce trade-offs in flexibility and horizontal scalability.
What is NoSQL?
NoSQL, often expanded as "Not Only SQL," refers to a broad category of non-relational databases designed to handle unstructured, semi-structured, or rapidly changing data at scale. Unlike SQL's uniform table-based model, NoSQL encompasses several distinct data models, each optimized for different problems.
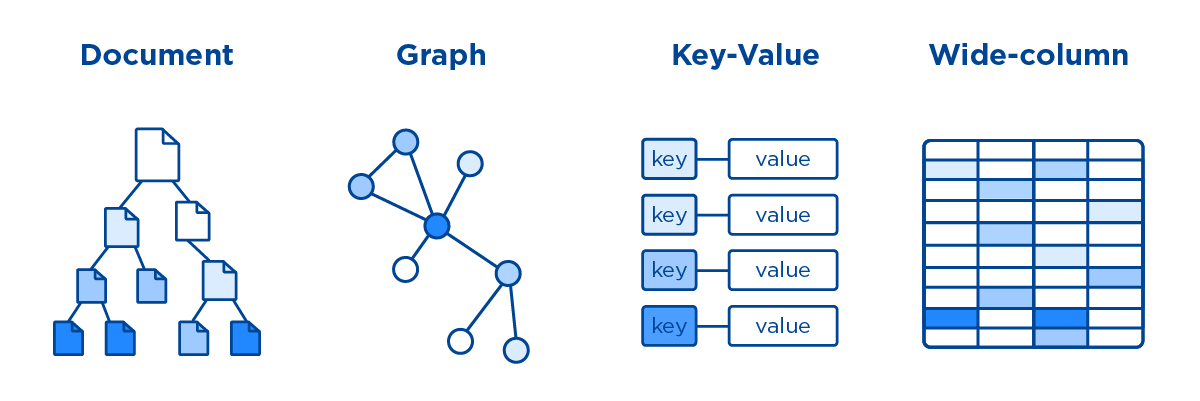
Key-Value Stores are the simplest, storing data as pairs of unique keys and associated values. Examples include Redis and Amazon DynamoDB. They offer extremely fast lookups and are ideal for caching, session management, and real-time counters.
Document Databases, such as MongoDB, CouchDB, and Firebase Firestore, store data in flexible, self-describing JSON-like documents. Schemas are dynamic, allowing documents in the same collection to have different fields. This accelerates development for content management systems and user profiles.
Wide-Column Stores, like Apache Cassandra and HBase, organize data in rows with dynamic columns grouped into column families. They excel at handling massive volumes of sparse data, such as time-series logs or sensor data in IoT applications.
Graph Databases deserve special attention. They model data as nodes (entities), edges (relationships), and properties. Neo4j, Amazon Neptune, and ArangoDB are leading examples. Graph databases shine where connections matter most, social networks, recommendation engines, fraud detection, and knowledge graphs. Querying deep relationships becomes natural and efficient through traversals rather than expensive joins.
SQL vs NoSQL: Key Differences
SQL and NoSQL databases represent fundamentally different philosophies in data management. SQL follows a rigid, relational model focused on structure, consistency, and complex querying through joins. In contrast, NoSQL solutions trade some of these features for flexibility, scalability, and specialized performance. Because NoSQL includes very different architectures, the comparison must examine each major type separately: key-value, document, wide-column, and graph databases.
The table below provides a detailed side-by-side comparison across critical dimensions.
This comparison highlights that no single database type wins in every scenario. SQL remains powerful for applications requiring strong consistency and complex data relationships expressed through joins. Key-value stores deliver raw speed for simple access patterns. Document databases prioritize developer agility. Wide-column stores handle extreme write volumes on sparse data. Graph databases uniquely excel when understanding connections between data points is central to the application. Many modern systems adopt polyglot persistence, combining SQL with one or more NoSQL types, to leverage the strengths of each.
Data Structure and Schema Comparison
Data structure and schema handling reveal sharp contrasts. SQL databases rely on rigid, predefined schemas with fixed tables, columns, data types, and constraints. Changes require migrations that can be costly in large systems, though modern tools have improved this process.
NoSQL types handle structure very differently. Key-value stores impose almost no schema whatsoever, treating values as opaque blobs. The application bears full responsibility for interpreting and validating data, enabling maximum flexibility but demanding robust client-side logic.
Document databases use schema-on-read flexibility. Documents in the same collection can contain entirely different fields, allowing rapid iteration. For example, a user profile document can later gain new attributes like preferences or location history without altering any collection structure. Validation occurs in application code or through optional schema validators in systems like MongoDB.
Wide-column stores provide row-level flexibility within column families. Rows can have vastly different columns, making them perfect for sparse datasets where most columns remain empty for any given row, such as user event histories with hundreds of possible attributes.
Graph databases structure data around nodes, edges, and properties. Nodes represent entities with attributes, while typed, directed edges capture relationships with their own properties. This model avoids join tables entirely. In a recommendation scenario, a graph might connect User nodes to Product nodes via PURCHASED and LIKED edges, with timestamps and weights as properties. Schema changes involve adding new node labels, relationship types, or properties without disrupting existing data.
Scalability: Vertical vs Horizontal Scaling
Scalability is a major consideration when selecting a database, but it is not a simple SQL-versus-NoSQL distinction. Most modern databases support both vertical scaling (adding more CPU, memory, or storage to a single server) and horizontal scaling (adding more servers), though their architectural emphasis differs.
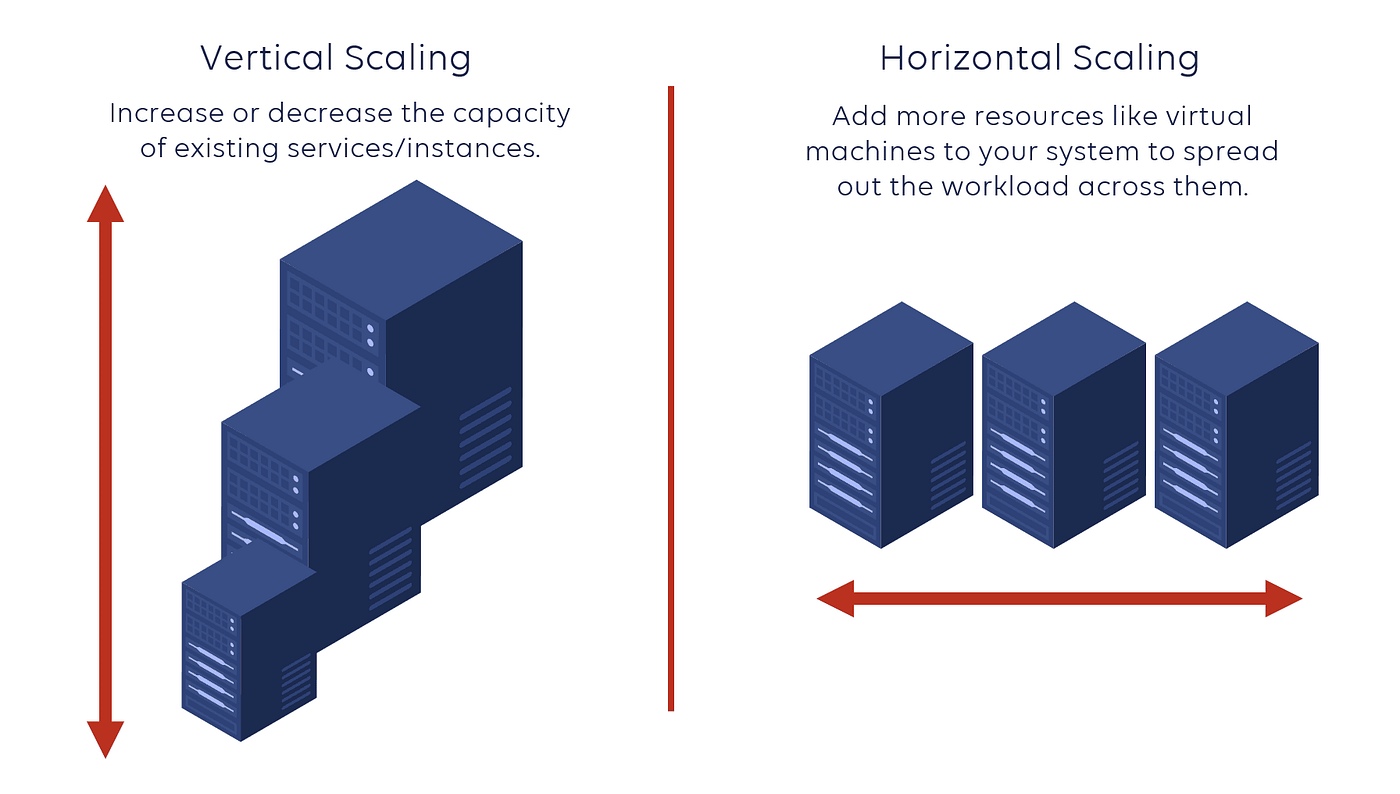
The table below compares how each major database model typically supports both scaling strategies.
Key Takeaways
Three practical patterns emerge:
- SQL systems favor vertical scaling first, then add horizontal techniques when workloads outgrow a single machine.
- Key-value, document, and wide-column systems are generally built for horizontal scaling, though vertical upgrades are often the easiest short-term optimization.
- Graph databases often scale vertically best, because relationship traversals are fastest when connected data stays local; horizontal scaling is possible but technically harder.
Ultimately, scalability is less about SQL versus NoSQL and more about whether a database’s architecture aligns with your workload, data distribution, and operational mode.
Performance and Query Capabilities
Different database models achieve performance through fundamentally different query designs, each optimized for specific access patterns rather than general-purpose querying.
SQL databases are designed for structured, relational workloads such as financial systems, reporting, and transactional applications. Their declarative query language allows users to specify what data is needed, while the optimizer determines execution strategies such as join ordering and indexing. This makes SQL powerful for complex queries involving multiple tables. Performance is generally strong for transactional workloads due to mature indexing and ACID guarantees. Analytical performance varies: traditional row-oriented SQL systems may struggle with large-scale scans and joins, while modern column-oriented or distributed SQL engines are optimized for such workloads. However, distributed joins can become expensive in large-scale systems due to network shuffling and data movement.
Key-value stores are optimized for ultra-fast lookups in use cases like caching, sessions, and counters. Their query model is minimal, typically limited to GET and PUT operations on keys. This simplicity eliminates query planning overhead, enabling constant-time access and very high throughput. However, they offer little support for filtering or relationships, pushing complexity to the application layer.
Document databases target flexible, evolving data such as user profiles and content systems. Queries operate over JSON-like structures using field-level filters and aggregation pipelines. They perform well for single-document access and moderately complex queries, but cross-document joins or large aggregations are less efficient compared to relational systems.
Wide-column stores are built for large-scale, write-heavy workloads like logs and IoT data. Their query languages resemble SQL but require queries to align with predefined partition keys. This design enables high throughput and predictable performance, but limits ad hoc querying and requires careful data modeling.
Graph databases specialize in relationship-centric workloads such as recommendations and fraud detection. Their query languages (e.g., Cypher) use pattern matching and traversals instead of joins. They excel at multi-hop relationship queries, offering significant performance advantages over relational joins, though distributed graph traversal can introduce overhead.
Overall, performance depends less on raw speed and more on how well the query model aligns with the underlying data access patterns.
SQL vs NoSQL for Modern Applications
Modern applications increasingly operate under diverse and evolving data requirements. A single system may need to support transactional workloads, flexible content structures, high-throughput logging, and relationship-heavy queries at the same time. These demands are difficult to satisfy efficiently with one database model, which has led to the rise of polyglot persistence, where multiple database technologies are used together within a single application architecture.
For example, an e-commerce platform may use an SQL database for orders and payments, where transactional consistency is critical, while storing product catalogs in a document database to support flexible and frequently changing attributes. A key-value store such as Redis may also be added for shopping carts and caching.
In social or recommendation-driven applications, different data models often coexist. User profiles and content may fit naturally in a document store, while a graph database such as Neo4j powers relationship-heavy features like recommendations, fraud detection, or “people you may know.”
For large-scale operational data, such as IoT telemetry or application logs, wide-column databases like Apache Cassandra are often chosen because they can efficiently ingest and distribute massive write volumes across clusters.
The key takeaway is that modern database architecture is increasingly shaped by workload characteristics rather than a single-system philosophy. The best design is often not choosing between SQL or NoSQL, but combining both in ways that align with data structure, query patterns, and scalability requirements.
Cost and Maintenance Considerations
Cost and maintenance are often overlooked but critical dimensions in database selection. Beyond raw pricing, the true cost of a database includes infrastructure usage, scaling efficiency, operational complexity, and the engineering effort required to maintain reliability over time.
From an infrastructure perspective, cost differences are driven largely by scaling strategies and resource utilization. Some systems rely on vertical scaling with high-performance machines, while others distribute workloads across clusters. However, lower infrastructure cost does not always translate into lower total cost, as data modeling constraints, system complexity, and ongoing engineering effort can significantly increase long-term spending.
Maintenance considerations vary primarily in terms of operational maturity and system complexity. SQL databases benefit from well-established tooling and predictable operations. Key-value stores are operationally lightweight but limited in flexibility. Document databases simplify schema evolution but introduce challenges in indexing and sharding. Wide-column stores scale efficiently but require careful cluster management. Graph databases provide expressive relationship modeling but often demand specialized expertise for tuning and optimization.
Overall, cost and maintenance should be evaluated as part of total system design, taking into account workload characteristics, lifecycle requirements, and team expertise rather than treating them as isolated selection criteria.
Common Mistakes When Choosing a Database
One of the most common mistakes is treating NoSQL as a single category rather than recognizing that it includes fundamentally different models, such as key-value, document, wide-column, and graph databases, each optimized for different workloads. Choosing the wrong NoSQL type, for example, using a document database for deeply connected data instead of a graph database, often leads to avoidable performance and modeling problems.
Another frequent mistake is selecting one database for every workload. Modern applications rarely have uniform requirements: transactional data, flexible content, analytical workloads, and relationship-driven queries often coexist. Trying to force all of them into a single database can create unnecessary compromises in performance, scalability, or developer productivity. In many cases, a polyglot approach, combining multiple databases for different use cases, delivers better long-term results.
Teams also often underestimate operational complexity. Distributed systems, especially wide-column and graph databases, can introduce challenges around partitioning, consistency, replication, and cluster maintenance that are easy to overlook during early design.
Finally, many organizations optimize only for today’s requirements and fail to plan for future growth. Data volume, query complexity, and application demands evolve. Testing with realistic workloads and representative data before committing can prevent expensive migrations later.
The most effective database strategy is rarely about choosing a single “winner.” It is about selecting the right data model for each workload and enabling different systems to work together seamlessly. As modern architectures increasingly combine SQL and multiple NoSQL technologies, the ability to unify and query across heterogeneous databases becomes just as important as the databases themselves.
Beyond Database Choice: Adding Semantics to Existing SQL Systems
Choosing the right database is only the first step.
Even when organizations select the right storage systems, another challenge remains: making data easier to understand, govern, and access consistently, especially for AI applications.
This challenge is particularly visible in relational environments. Many enterprises already store their most critical business data in SQL databases such as PostgreSQL, MySQL, and Oracle Database, and modern data lakes or lakehouse systems. These systems provide strong consistency and mature operational tooling, but their schemas often reflect physical storage design rather than business meaning.
Tables, foreign keys, and joins describe how data is stored, but not always what it means.
A semantic layer addresses this gap.
The Role of a Semantic Layer
A semantic layer sits above existing SQL databases and exposes business concepts directly, such as Customer, Order, Product, or Transaction.
Instead of forcing applications or AI systems to reason through raw tables and joins, the semantic layer provides a higher-level logical model aligned with business meaning.
This allows developers and AI agents to work with data more naturally, without changing the underlying SQL databases.
Ontology and Ontology Enforcement
At the core of many semantic layers is an ontology, a formal definition of entities, relationships, and rules across the SQL data environment.
An ontology defines:
- what entities exist,
- how they relate to one another,
- and what relationships are valid.
For example, a Customer may place an Order, an Order may contain a Product, and a Supplier may provide that product.
Ontology enforcement ensures that queries and updates across SQL systems respect these rules. Whether data originates from an application, an analyst, or an AI agent, operations are validated against the semantic model to prevent inconsistent or logically invalid relationships.
Why It Matters: From Semantic Fog to Agentic Clarity
Without a semantic layer, working directly with SQL often shifts complexity into application code, making systems harder to maintain as they grow. For AI systems, this challenge is even greater. Large language models and autonomous agents can become trapped in semantic fog: navigating inconsistent schemas, ambiguous joins, and unclear relationships across tables.
This often leads to operations that are syntactically correct but logically wrong. An AI agent may successfully generate a query or connect two entities, yet create a relationship that does not exist in the real world.
Ontology enforcement acts as a semantic guardrail, ensuring that AI-generated reads and writes follow a validated model of how data entities interact. This reduces silent failures and improves trust in automated systems.
It also creates a valuable feedback loop for self-correction. Instead of returning only technical database errors, ontology-aware systems can provide structured semantic feedback, explaining why a query or update violates business logic. This allows AI systems to refine their behavior through iteration, learning the rules of the data environment over time. Over the longer term, this feedback can also serve as a reward signal for fine-tuning or reinforcement learning.
Data Access with AI Assistants
Moving beyond architectural considerations, PuppyGraph provides a graph-based way to access and query existing SQL data as connected knowledge, without requiring organizations to migrate everything into a native graph database. This enables developers and AI systems to explore existing SQL data through graph-style reasoning and relationship-aware retrieval.
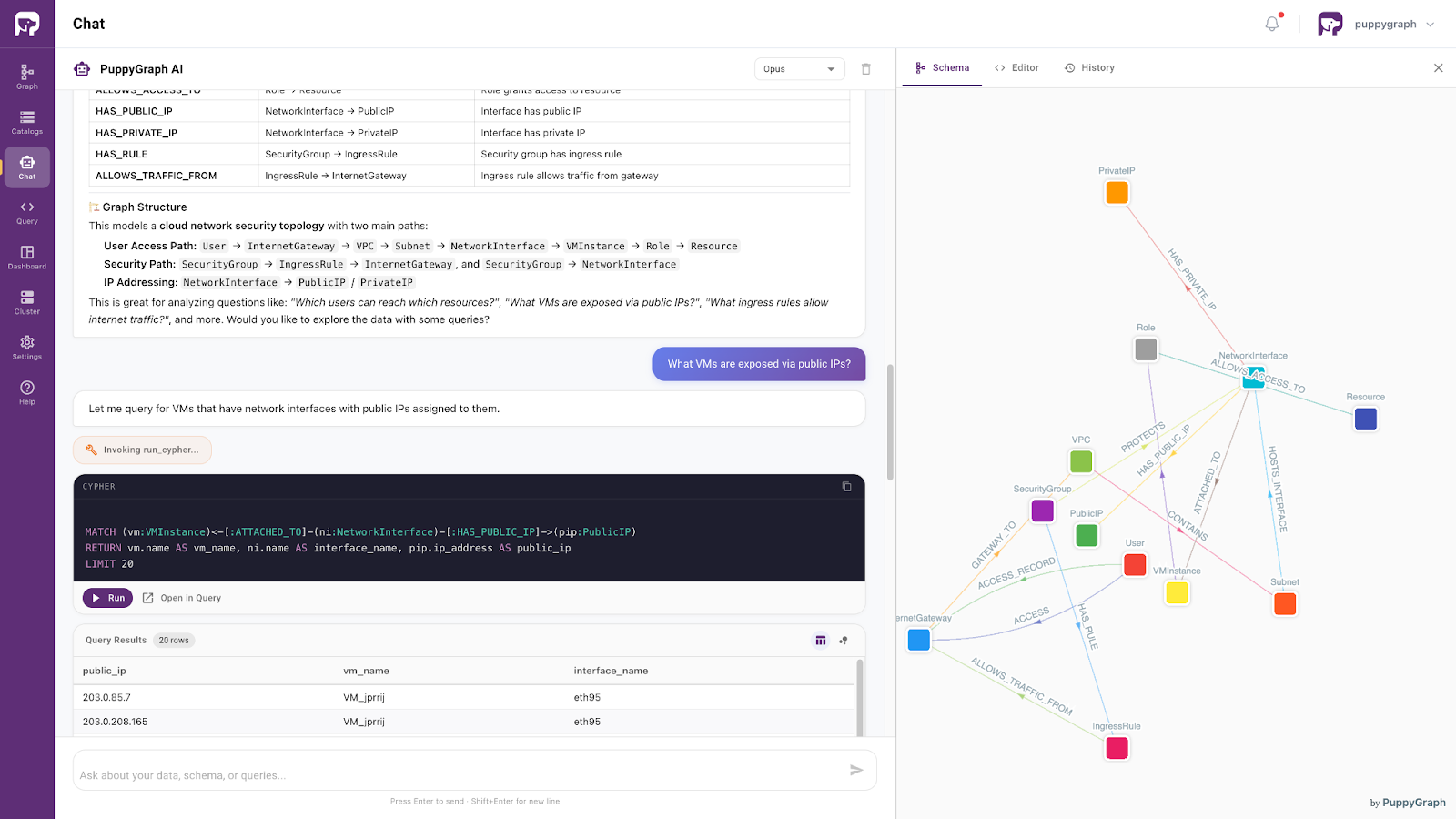
Powered by the same ontology-enforced foundation, this approach supports precise, context-aware access to enterprise SQL data. It allows AI systems to interpret user intent within a well-defined semantic framework and retrieve relevant information accordingly.
As a result, enterprise data evolves from a passive storage layer into an active semantic layer: one that preserves consistency while enabling more reliable search, analytics, and next-generation AI agents.
Conclusion
In summary, SQL and NoSQL databases are not competing replacements but complementary approaches optimized for different data and workload requirements. SQL systems provide strong consistency, structured schemas, and powerful relational querying, while NoSQL databases introduce flexibility and scalability across diverse models such as key-value, document, wide-column, and graph stores. Modern architectures increasingly rely on polyglot persistence, combining multiple database types to address diverse data management needs within a single ecosystem.
Beyond storage choices, the next challenge is semantic understanding. As data systems grow in complexity, an ontology-enforced semantic layer helps bridge the gap between physical schemas and business meaning, enabling more consistent and intelligent data access. PuppyGraph further extends this idea by turning relational data into connected, queryable knowledge without ETL. Together, these approaches shift databases from passive storage systems into active foundations for analytics, applications, and AI-native systems.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see how PuppyGraph turns existing SQL data into a connected, ontology-aware knowledge layer for AI and applications.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install