

What is Text-to-SQL?
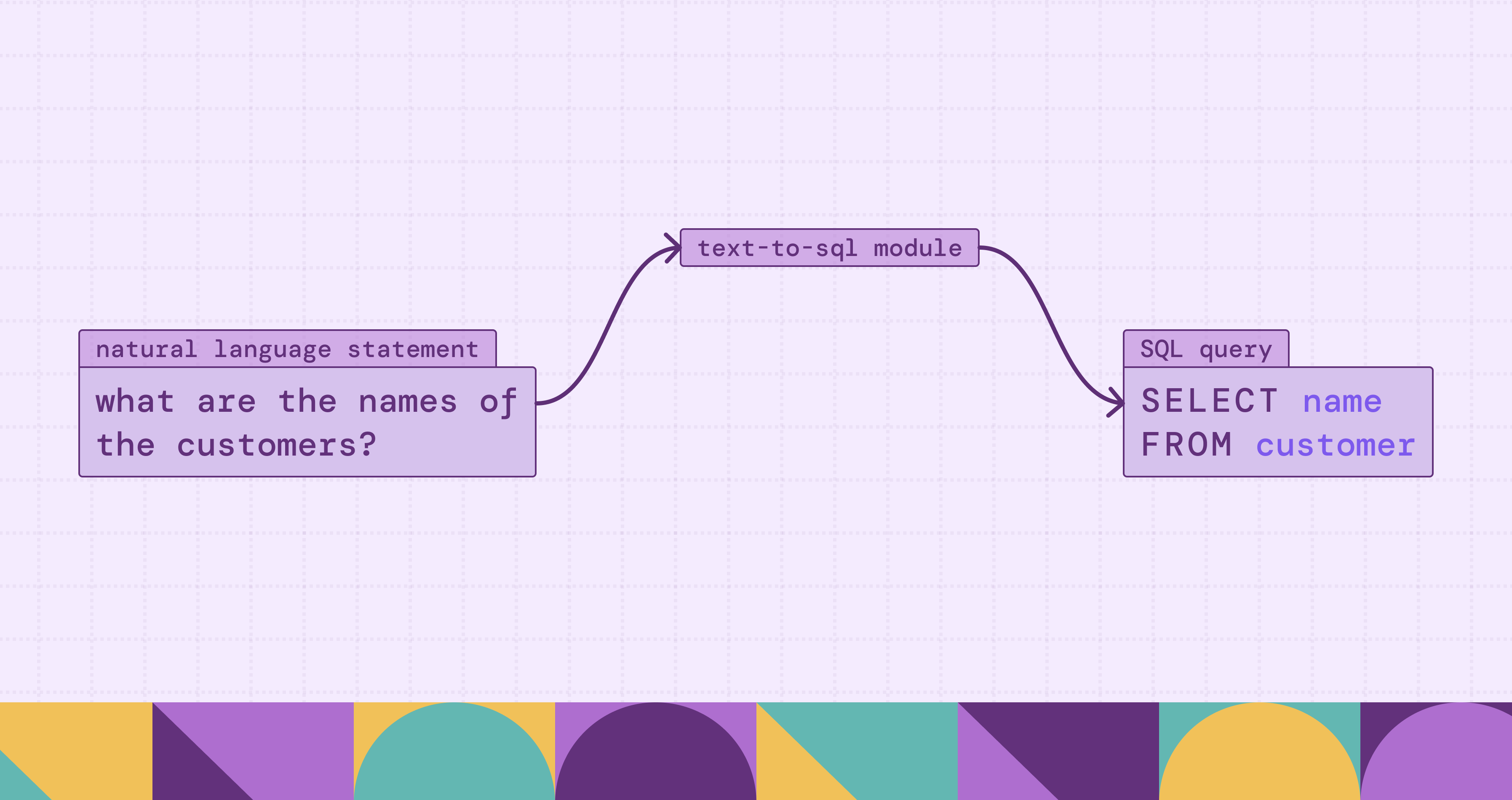
Text-to-SQL is a transformative branch of semantic parsing that bridges the gap between human intuition and structured data logic. In an era where data is an organization's most valuable asset, the ability to extract insights is often bottlenecked by the technical requirement of mastering SQL (Structured Query Language). Text-to-SQL technology aims to eliminate this barrier by automatically translating Natural Language Queries (NLQs) into executable database code.
By leveraging Large Language Models (LLMs) and advanced Agentic Workflows, modern Text-to-SQL systems have evolved beyond simple translation. They now serve as intelligent intermediaries capable of understanding complex schema relationships, reasoning through multi-step analytical requests, and even self-correcting execution errors. This shift from "procedural logic" (telling the machine how to get data) to "declarative intent" (telling the machine what data is needed) is redefining the landscape of Business Intelligence and data democratization.
What Is Text-to-SQL?
Text-to-SQL, conceptually known as a specialized form of Semantic Parsing, is the task of automatically translating a user’s natural language query (NLQ) into a structured executable SQL statement. Its primary objective is to map human intent, expressed in messy and often ambiguous language, to the rigid, formal logic of a relational database.
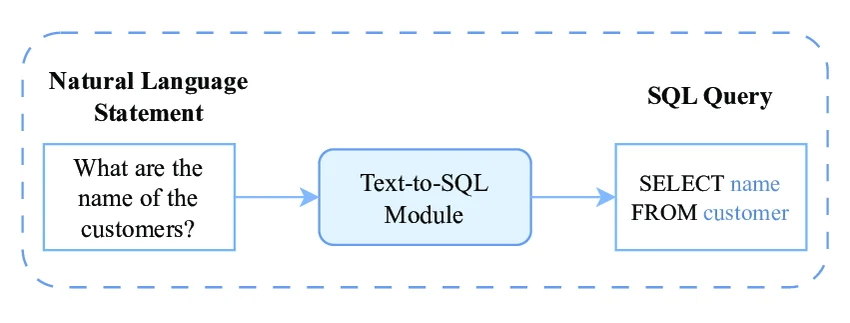
According to recent research, the essence of Text-to-SQL lies in the interaction between three core elements:
- The Natural Language Input: The user’s question, which may range from simple lookups to complex analytical requests involving multiple conditions.
- The Database Schema: The structural metadata of the target database, including tables, columns, and the relationships (foreign keys) that link them.
- The Formal Output: A syntactically correct SQL query that, when executed, returns the precise data requested by the user.
How Text-to-SQL Works
Modern Text-to-SQL systems have evolved from rigid rule-based parsers to dynamic systems powered by Large Language Models (LLMs). The process is no longer just a simple translation; it is a multi-step orchestration that connects human intent with database logic.
The workflow typically follows these stages:
- Natural Language Understanding (NLU): The system receives a user's question (e.g., "Who were the top 5 customers by revenue last year?"). The LLM parses this to identify the user's intent, the metrics involved (revenue), and the constraints (top 5, last year).
- Schema Context Injection: Since the LLM doesn't inherently know your private database structure, the system must provide "context." This involves feeding the model relevant metadata, such as table names, column names, data types, and primary/foreign key relationships.
- SQL Generation (Inference): Combining the user's question with the schema context, the LLM generates a syntactically correct SQL statement. Modern approaches often use "Few-shot Prompting," where the model is shown a few examples of question-SQL pairs to improve accuracy.
- Validation and Refinement: The generated SQL is often put through a "Self-Correction" loop. The system may check the query for syntax errors or run it in a sandbox environment. If the execution fails, the error message is fed back to the LLM to regenerate a corrected version.
- Execution and Formatting: Finally, the validated SQL is executed against the database, and the raw result sets are often converted back into natural language or visual charts for the end user.
Key Components of a Text-to-SQL System
To build a production-grade Text-to-SQL pipeline, several specialized components must work in harmony. Based on industry best practices, these include:
1. The Prompt Engine (Context Provider)
This is the most critical component. It manages the information sent to the LLM. A robust prompt includes:
- The Database Schema: A DDL (Data Definition Language) representation of relevant tables.
- Sample Data: A few rows of "Golden Records" to help the model understand the actual data format (e.g., whether a "Status" column uses "1/0" or "Active/Inactive").
- Instructions: Specific rules, such as "Always use JOINs instead of subqueries" or "Return dates in YYYY-MM-DD format."
2. The Retrieval-Augmented Generation (RAG) Layer
In large enterprise databases with hundreds of tables, you cannot fit the entire schema into a single prompt. The RAG component uses vector embeddings to search and retrieve only the most relevant table definitions and documentation based on the user's specific question, keeping the prompt concise and cost-effective.
3. The SQL Executor & Validator
This component acts as the gatekeeper. It performs two roles:
- Syntax Check: Ensuring the SQL matches the specific dialect (PostgreSQL, Snowflake, MySQL, etc.).
- Security Guardrails: Stripping away destructive commands like DROP or DELETE and enforcing Read-Only permissions to prevent SQL injection or accidental data loss.
4. The Self-Correction (Agentic) Loop
Often called an "Agentic workflow," this component automatically captures execution errors. If the database returns a "Column not found" error, this component sends the error log back to the LLM, allowing the model to realize its mistake and produce a "fix" without human intervention.
5. Evaluation Framework
To ensure reliability, systems use evaluation datasets (like Spider or BIRD benchmarks) or custom "Gold Queries." This component measures the Execution Accuracy (does the result match the ground truth?) and Valid SQL Rate to track the system's performance over time.
Text-to-SQL vs Traditional SQL Querying
The shift from traditional SQL querying to AI-driven Text-to-SQL represents a transition from procedural logic to declarative intent. While traditional SQL remains the gold standard for precision, Text-to-SQL addresses the scalability and accessibility bottlenecks that have long plagued data-driven organizations.
The following table summarizes the key differences based on technical implementation and operational impact:
Types of Text-to-SQL Approaches
Modern Text-to-SQL methodologies, as categorized in recent research, have transitioned from traditional deep learning models to diverse strategies centered around Large Language Models (LLMs). These approaches are generally classified into three main categories based on their technical implementation:
1. Prompt Engineering-based Approaches
This category focuses on designing and optimizing the input given to a frozen LLM. It is the most widely adopted approach due to its efficiency and lack of training requirements.
- Prompt Construction: Research in this area focuses on how to represent the database schema (e.g., using DDL statements or JSON) and how to select the most effective "Few-shot" examples (Demonstration Selection) to guide the model.
- Reasoning Enhancement: Strategies like Chain-of-Thought (CoT) are employed to guide the model through intermediate logical steps, such as identifying relevant tables and columns before writing the final SQL, which significantly improves accuracy for complex queries.
2. Fine-tuning-based Approaches
While prompt engineering uses general-purpose LLMs, fine-tuning involves adapting the model's parameters to the specific task of SQL generation.
- Supervised Fine-Tuning (SFT): Models are trained on specialized Text-to-SQL datasets like Spider or BIRD. This allows smaller models (e.g., Llama, Mistral) to achieve performance comparable to much larger proprietary models like GPT-4.
- Domain Adaptation: For industries with highly specific terminology (e.g., medical or financial databases), fine-tuning helps the model understand proprietary schemas and complex domain-specific logic that general models might miss.
3. Agentic and Refinement Frameworks
This approach treats Text-to-SQL as an iterative workflow rather than a single-turn translation. It introduces "agents" or "loops" to ensure the validity of the output.
- Self-Correction (Feedback Loops): The system executes the generated SQL in a sandbox environment. If an error occurs (e.g., a syntax error or a missing column), the error message is fed back to the LLM as feedback, allowing it to "debug" and refine its own query.
- Multi-Agent Orchestration: Complex tasks are split among specialized agents, for instance, one agent selects the schema, another drafts the SQL, and a third performs a "self-consistency" check to verify that different reasoning paths lead to the same result.
Why Text-to-SQL Fails and Ontology Enforcement Fixes It
In complex enterprise environments, databases often contain a large number of tables with intricate relationships and business logic. In such settings, LLMs may misinterpret the underlying business context. On one hand, they may generate queries that are syntactically correct and executable but produce incorrect results. On the other hand, some generated queries may fail to execute altogether. For the latter case, the feedback returned by the system often lacks sufficient semantic information and business context, making it difficult to effectively pass this feedback to an agent for a self-correction loop.
To address these challenges, we adopt an ontology and an accompanying ontology enforcement mechanism. When datasets contain numerous tables, they inherently encode rich entities and relationships. Therefore, it is necessary to abstract these semantic elements from the underlying schema and represent them explicitly in the form of an ontology. This explicit semantic layer helps reduce semantic hallucinations during query generation by LLMs.
Building on this foundation, we further use ontology enforcement to validate generated queries against the ontology. When a query violates the ontology constraints, the system returns structured, LLM-readable error feedback. This feedback guides the agent in performing effective self-correction. Moreover, such feedback can be leveraged for further fine-tuning or reinforcement learning, enabling continuous improvement of the model’s performance.
Text-to-SQL Tools and Platforms
The rapid evolution of Text-to-SQL has fostered a diverse ecosystem of tools ranging from academic evaluation frameworks to enterprise-grade production platforms. According to recent research, these tools leverage a combination of prompt engineering, RAG, and agentic workflows. Their ecosystem can be viewed through the following categories:
1. Academic Benchmarks and Evaluation Frameworks
Evaluation is the cornerstone of progress in Text-to-SQL. Research-oriented platforms provide the standardized data and metrics needed to measure model performance:
- Spider: Long considered the gold standard, this cross-domain dataset focuses on complex SQL structures and multi-table joins across diverse schemas.
- BIRD (Big Bench for Large-scale Database Grounding): A more recent and challenging benchmark that bridges the gap between academic research and real-world application. It features massive databases (up to 100GB) and requires "external knowledge" to answer queries: tasks where simple schema mapping is insufficient.
- Evaluation Metrics: Platforms now prioritize Execution Accuracy (EX) and Valid SQL Rate (VSR) over simple string matching, ensuring that the generated queries actually return the correct data from the database.
2. Open-Source Development Frameworks
To lower the barrier for developers, several frameworks have emerged that implement the Prompting-based and Agentic methodologies discussed in current literature:
- DB-GPT: An open-source framework that emphasizes private, secure environment deployment. It aligns with the "Knowledge Injection" concept by allowing developers to link local documents and schemas to LLMs without exposing sensitive data to public APIs.
- LangChain & LlamaIndex: While general-purpose LLM orchestrators, these libraries offer specialized SQL-Chain and SQL-Agent modules. They implement the Self-Correction (Feedback) Loop, where execution errors are automatically fed back to the model for iterative debugging.
3. AI-Driven Business Intelligence (BI) Platforms
In the commercial sector, Text-to-SQL has moved beyond simple APIs to become comprehensive data assistants:
- Vanna.ai: This platform utilizes a RAG-based approach specifically for SQL. It trains a metadata layer on your specific schema and historical "Golden Queries," allowing the system to provide high-accuracy results by retrieving relevant context for the LLM.
- Chat2DB & SQLChat: These tools focus on the user interface, blending traditional Database Management Systems (DBMS) with AI chat. They facilitate the transition from procedural logic to declarative intent, allowing users to explore data without writing code.
4. Enterprise Cloud Integrations
Major cloud providers are increasingly embedding Text-to-SQL capabilities directly into their data ecosystems:
- AWS (Amazon Q in QuickSight) & Google Cloud (BigQuery Data Canvas): These services leverage fine-tuned proprietary models and massive metadata indexing. They are designed to handle enterprise-level complexity where a single database may contain thousands of tables, requiring the advanced Schema Linking techniques described in the BIRD study.
Examples of Text-to-SQL
To better understand how Text-to-SQL translates ambiguous human intent into precise machine instructions, we can examine three categories of examples derived from leading research benchmarks (such as Spider and BIRD). These range from simple data retrieval to complex, knowledge-intensive reasoning.
1. Basic Single-Table Query
This is the foundational level of Text-to-SQL, focusing on mapping natural language entities to database columns and applying simple filters.
- User Question: "Show the names of all movies with a rating higher than 8.5."
- Model Reasoning: The system identifies "names" as the title column and "rating" as the score column. It recognizes the "higher than" intent as a > comparison operator.
Generated SQL:
SELECT title FROM movies WHERE score > 8.5;2. Complex Multi-Table Join
In real-world scenarios (often featured in the Spider benchmark), data is normalized across multiple tables. The model must infer the correct join paths using schema metadata.
- User Question: "Find the name of the author who has published the most papers in conferences held in New York."
- Model Reasoning: The system must link three tables: authors, papers, and conferences. It identifies foreign key relationships, applies a location filter, and determines that "most papers" requires a COUNT aggregation combined with ORDER BY and LIMIT 1.
Generated SQL:
SELECT T1.name
FROM authors AS T1
JOIN papers AS T2 ON T1.id = T2.author_id
JOIN conferences AS T3 ON T2.conf_id = T3.id
WHERE T3.location = 'New York'
GROUP BY T1.id
ORDER BY COUNT(*) DESC LIMIT 1;3. Knowledge-Intensive & Reasoning Query
According to the BIRD (Big Bench for Large-scale Database Grounding) study, advanced queries often require "External Knowledge" or multi-step logic that isn't explicitly stated in the schema.
- User Question: "Calculate the annualized return for the fourth quarter of 2023."
- The Challenge: The database may not have a "Q4" column or an "Annualized Return" field.
- Reasoning Process (Chain-of-Thought):
- Temporal Mapping: The model interprets "Q4" as a date range from 2023-10-01 to 2023-12-31.
- Formula Derivation: It applies domain knowledge to calculate the annualized return (e.g., quarterly_revenue * 4).
Generated SQL:
SELECT SUM(revenue) * 4 AS annualized_return
FROM sales
WHERE sale_date BETWEEN '2023-10-01' AND '2023-12-31';Agentic Self-Correction Example
Modern systems use an "Agentic Loop" to handle execution errors. If a generated query fails, the system learns from the error log and retries.
- Initial Attempt: User asks for "average pay," and the model incorrectly guesses a column named salary.
- Feedback: The database returns: ERROR: column "salary" does not exist.
- Correction: The Agent scans the schema again, realizes the correct field is monthly_income, and regenerates the query.
-- Corrected Query --
SELECT AVG(monthly_income) FROM employees;Benefits of Using Text-to-SQL
Integrating natural language capabilities into database querying is more than just a change in interface; it represents a fundamental shift in organizational efficiency. Based on industry research and technical evolution, the core benefits of Text-to-SQL can be categorized into four key dimensions:
1. Democratizing Data Access
Traditionally, database analysis has been guarded by a "technical barrier." Non-technical users, such as those in operations, sales, or executive leadership, usually follow a rigid cycle: submit a request, wait for data team triage, and receive results days later. Text-to-SQL empowers business users to interact directly with databases using natural language. By removing the dependency on SQL expertise, it transforms data into a real-time resource available to everyone, achieving true "data democratization."
2. Accelerating Time-to-Insight
Text-to-SQL drastically increases the iteration speed of data analysis:
- Immediacy: Users can perform ad-hoc exploratory analysis in real-time. For example, during a meeting, a user can test a hypothesis and get results instantly without interrupting the decision-making flow.
- Operational Efficiency: For data analysts, Text-to-SQL serves as a "Copilot." It can automate complex JOIN logic and basic query scaffolding, freeing experts to focus on high-value data interpretation and strategic planning rather than syntax debugging.
3. Ensuring Consistency and Accuracy
Manual SQL writing is prone to human error, such as typos, logical flaws, or misunderstandings of the underlying schema.
- Standardized Logic: By injecting "Golden Records" and standard business definitions (e.g., the specific formula for "Net Profit") into the prompt, the system ensures every generated query adheres to unified corporate standards.
- Reduced Oversight: Large Language Models (LLMs) are highly stable when navigating vast table relationships. They effectively prevent common human errors, such as missing join conditions in complex multi-table queries.
4. Scalability in Complex Environments
In enterprise environments with hundreds of tables, finding the correct fields and relationships manually is a massive bottleneck.
- Context-Aware Retrieval: Modern systems use Retrieval-Augmented Generation (RAG) to automatically search through massive metadata and inject only the most relevant table structures into the prompt. This automation allows the system to remain efficient even as the database grows in complexity, eliminating the need for users to manually consult extensive documentation.
Conclusion
The evolution of Text-to-SQL marks a paradigm shift in data interaction. What began as a rigid academic pursuit has matured into a sophisticated ecosystem of RAG-enhanced pipelines and self-healing agents. By automating the transition from human language to database logic, Text-to-SQL empowers non-technical stakeholders to become autonomous data explorers.
When facing a large quantity of business data and logic, we need to introduce an ontology and ontology enforcement. By explicitly modeling the rich entities and relationships inherently embedded across large numbers of tables in complex schemas, it eliminates "semantic hallucinations" and provides the rich feedback necessary for a self-correction loop, as well as for further fine-tuning and reinforcement learning.
Try PuppyGraph to see how ontology enforcement works in practice. Explore more with the forever-free PuppyGraph Developer Edition, or book a demo.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install