

How AMD Built IT Ops Agent System on Iceberg and PuppyGraph with Agent Harness
Executive Summary
- AMD needed a Data Intelligence Platform that connected tickets, code, logs, and telemetry into a graph-aware layer, enabling teams and AI agents to reason across systems, not just query rows of data
- Siloed data and multi-hop questions overwhelmed SQL joins and made traditional graph DBs costly due to ETL/data duplication
- AMD implemented GraphRAG with “query-in-place” over Iceberg - no data movement required -turning enterprise data into a connected, living knowledge graph based on their tech stack:
- MinIO AIStor for unified object storage
- Apache Iceberg with Nessie catalog for structured data
- Dremio for SQL querying
- PuppyGraph for Cypher query layer directly on Iceberg (zero-ETL)
- LangChain + Microsoft Autogen orchestrated agents using Claude Opus 4 and GPT-4o
- Query time reduced from minutes to sub-seconds while scaling to millions of relationships; eliminated ETL pipelines and duplicate stores; one Iceberg foundation now serves both SQL and graph analytics.
AMD, a global leader in high-performance computing, graphics, and semiconductor technologies, builds the hardware powering everything from consumer laptops to hyperscale data centers. Behind that innovation lies an increasingly complex web of internal engineering systems, from ServiceNow and Jira to GitHub repositories, telemetry pipelines, and infrastructure logs, each generating vast amounts of operational data.
Over time, these systems evolved independently, creating silos that made it difficult for teams to trace issues, reuse past knowledge, or uncover patterns across the engineering lifecycle. “We had all the data,” said Rajdeep Sengupta, Director of Systems Engineering at AMD, “but the context was missing.”
To address this, Sengupta’s team launched the Data Intelligence Platform, an enterprise initiative to make AMD’s internal data not just centralized, but connected. The goal wasn’t simply to collect events or tickets. It was to enable reasoning across them. A problem in ServiceNow should automatically relate to its corresponding GitHub commit, infrastructure component, and owner history.
Graph modeling emerged as the most natural way to represent these relationships:
- Tickets → Systems → Owners → Components → Code
This graph-based approach became the foundation for AMD’s larger AI-driven data transformation strategy, ultimately leading the team to adopt GraphRAG, a framework that enables contextual reasoning over connected enterprise data at scale.
“We have all the tickets. ServiceNow, Jira, everything. It’s nothing new, but now it’s connected. You can search that if there’s a black screen on a node, what were the probable problems before, and what fixed it.”
The Challenge: Connecting the Dots Across Disparate Engineering Systems
As AMD’s engineering environment expanded, so did the number of interconnected systems generating operational data; ServiceNow for incidents, Jira for tasks, GitHub for commits, telemetry for runtime behavior, and logs across infrastructure layers. Each system worked well in isolation but offered little visibility into how issues related to one another across domains.
The team initially tried to solve this using relational databases and semantic layers, but these approaches quickly reached their limits. Traditional SQL systems could handle joins between tables but struggled with multi-hop relationships such as issue → component → engineer → previous fix. Even small increases in depth caused query complexity and latency to explode.
AMD also experimented with graph databases like Neo4j to model dependencies more intuitively. However, these systems required heavy ETL processes to copy data out of the company’s existing data lake into specialized graph stores. Frequent schema changes, ingestion overhead, and the need to maintain separate infrastructure made production rollout impractical.
The engineering team needed a different approach. One that could:
- Query data in place without ETL or duplication.
- Deliver sub-second latency for traversal-heavy graph queries.
- Integrate directly with their AI reasoning layer built on LangChain for natural-language question answering and workflow automation.
As Rajdeep Sengupta put it during his talk:
“It’s not a human product anymore. These workflows, approvals, debug checks, they’re repetitive. The agent can learn them.”
The goal wasn’t just to build faster dashboards. It was to enable agents that could reason across AMD’s enterprise data and perform routine actions autonomously.
How AMD Built a Unified Graph Intelligence Layer
To unify its fragmented engineering and IT systems, Sengupta’s team designed an architecture that connects every layer of its data stack. From raw object storage to AI reasoning, without traditional ETL pipelines. The goal was to make engineering and operational data queryable, connected, and explainable through graph reasoning.
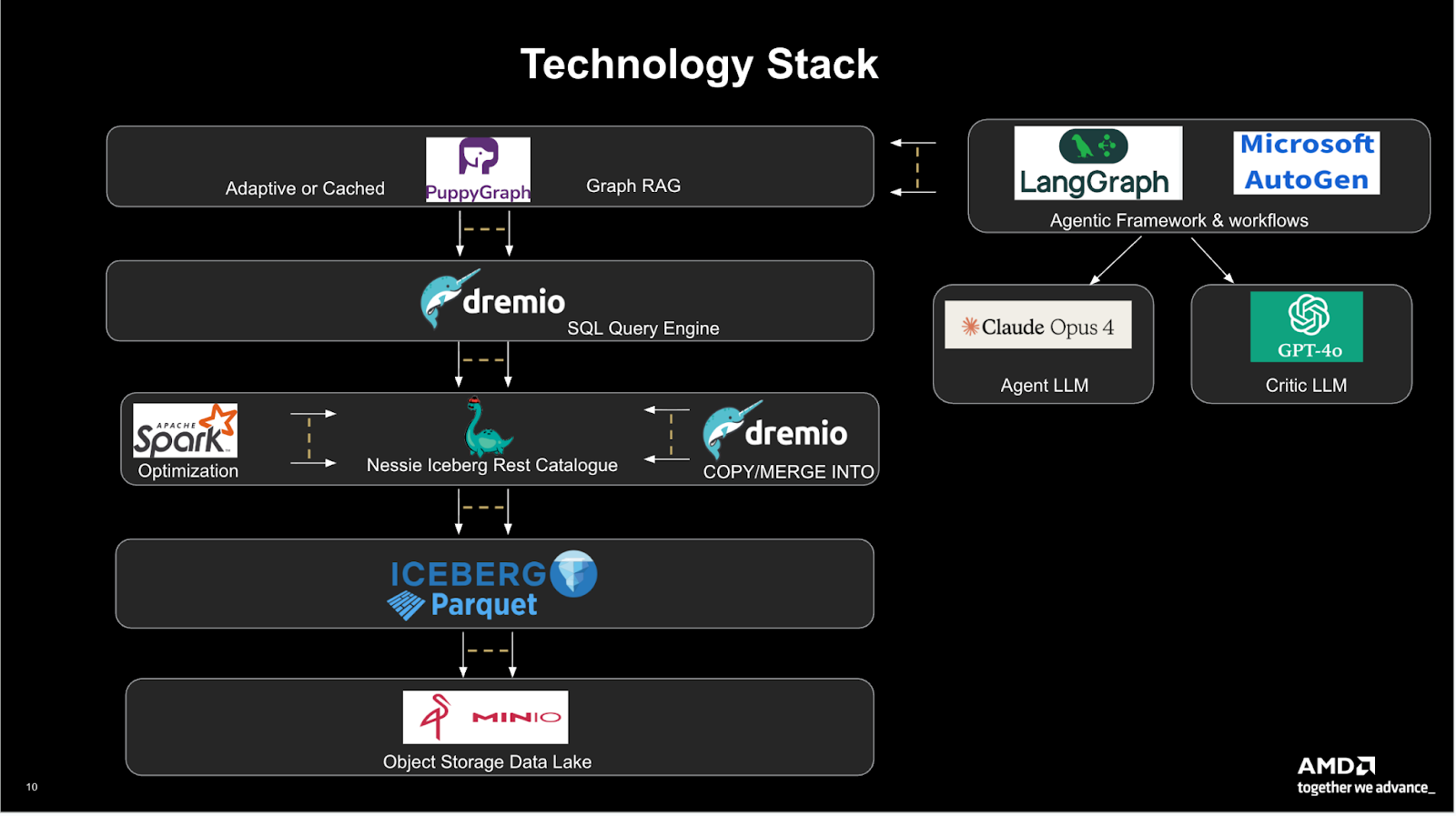
At the base of the stack, MinIO AIStor serves as the unified object store, housing raw data, logs, and telemetry across the enterprise. On top of AIStor, Apache Iceberg provides the open table format that standardizes schema evolution, enables time travel, and keeps datasets versioned and consistent across workloads.
Above Iceberg, Nessie acts as the Iceberg REST catalog, providing version control and atomic branching for table metadata. Spark is used for data optimization and preprocessing within the same environment, ensuring that the Iceberg tables remain performant and up to date.
Dremio powers the SQL query layer for federated access, and also handles copy/merge operations, providing a fast analytic interface across Iceberg-managed data.
On top of this, PuppyGraph connects directly to Iceberg and Dremio, exposing a zero-ETL graph query engine that enables multi-hop graph traversals and contextual reasoning. Instead of replicating or transforming data into a graph database, PuppyGraph virtualizes the graph model directly from Iceberg tables and executes Cypher queries in place.
At the orchestration layer, LangChain translates natural-language prompts, such as “Which systems are most affected by repeated outages?”, into executable Cypher queries. LangChain then coordinates with Microsoft AutoGen, which manages multi-agent workflows between specialized models.
For reasoning, AMD uses Claude Opus 4 as the agent LLM and GPT-4o as the critic LLM, creating a feedback loop that validates, refines, and explains each result before surfacing it in dashboards or chat interfaces.
Together, these components form a real-time reasoning pipeline that Rajdeep described as “connecting intelligence across systems, not just collecting data.”
Data Flow Summary
- Engineering, IT, and operations data are stored in AIStor and organized in Apache Iceberg tables.
- Nessie catalogs and versions those tables, with Spark handling optimization and updates.
- Dremio enables fast SQL queries and merge operations across Iceberg datasets.
- PuppyGraph connects directly to these Iceberg tables — no ETL, no duplication — and executes Cypher queries as graph traversals.
- LangChain converts natural-language prompts into structured graph queries and routes them through Microsoft Autogen workflows.
- Claude Opus 4 and GPT-4o serve as the reasoning and validation agents, returning contextual answers to internal dashboards and chatbots.
Implementing GraphRAG at Enterprise Scale
AMD’s implementation centers on a deceptively simple idea: query data where it already lives. Instead of copying information into specialized databases or knowledge systems, the team built an intelligent graph layer directly on top of their Iceberg tables, all served from the same AIStor object store.
PuppyGraph acts as the zero-ETL graph layer. It reads data directly from Iceberg using vectorized access, eliminating duplication and preserving Iceberg’s time-travel and schema-evolution capabilities. Every ticket, system log, code commit, or configuration change becomes a node; relationships such as “ticket references commit” or “commit affects component” form the edges.
On top of this graph layer, LangChain orchestrates a set of agents that handle retrieval, prompt routing, and reasoning. When a user enters a natural language query, such as “Which commits introduced the most recurring incidents?”, LangChain translates it into a Cypher query that PuppyGraph executes directly against Iceberg data.
“In the Data Intelligence Platform, we have all the tickets, and we know what was done 10 or 20 times before,” said Rajdeep Sengupta during his talk. “It’s nothing new. The system gets that knowledge, does all the checks, and fixes it automatically.”
This structure transforms historical data into a live knowledge base. One that improves over time as more incidents, fixes, and workflows are recorded. The system can reason about probable root causes, detect patterns in failures, and even automate responses for known scenarios.
Example Queries (Translated from Natural Language)
- “Find all issues related to this component that were resolved in the past 3 months.”
- “Which commits introduced the most recurring incidents?”
- “If this service fails, what dependent systems will be affected?”
Query Flow in the Graph Intelligence System
Natural Language Prompt → LangChain (translation & orchestration) → PuppyGraph (Cypher execution) → Iceberg via AIStor (data retrieval) → Result Graph + Context → AI Summary / Agent Action.
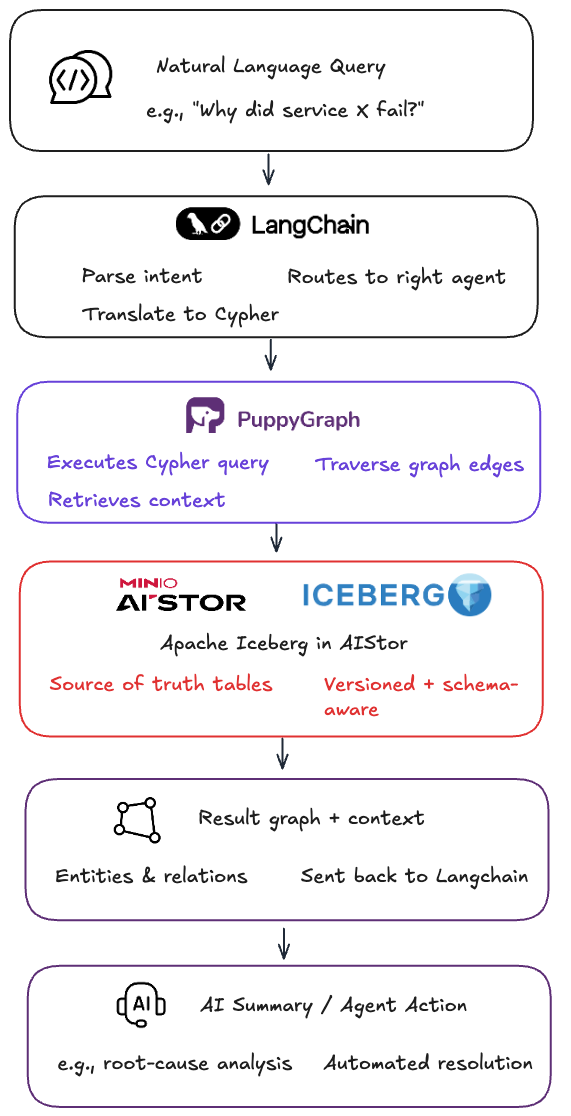
This workflow allows engineers and AI agents to ask questions in plain English while the backend performs complex graph traversals in milliseconds, all without data movement or preprocessing.
Real-World Applications from AMD’s Data Intelligence Platform
Rajdeep’s talk highlighted how AMD’s Data Intelligence Platform uses its connected data foundation to automate workflows, diagnose infrastructure issues, and enable self-learning systems, all built on Apache Iceberg, PuppyGraph, AIStor, and LangChain.
A. Automating IT Workflows
One of the first use cases Rajdeep shared was automating routine IT processes such as NDA approvals: repetitive five-step workflows that traditionally required manual input and multi-level approvals.
By modeling each task, actor, and dependency as nodes and relationships in a graph, AMD’s system enables agents to reason through these flows automatically. The system can identify redundant approvals, bottlenecks, and errors and route tasks intelligently, reducing time-to-completion dramatically.
“It’s a very standard process,” Rajdeep said. “But it still takes two days to complete. You can do it with an agent. It doesn’t need a human.”
This use case demonstrated how graph-based representations can simplify automation far beyond what rule-based systems or isolated process tools could manage.
B. Auto-Diagnosis of Infrastructure Issues
Another example Rajdeep discussed was AMD’s ability to detect and auto-diagnose system failures, such as “black screen” issues on ETX nodes.
By unifying tickets, logs, and telemetry data, the graph can correlate new issues with historical incidents and previous fixes. When a recurring issue occurs, the agent searches the graph for probable causes and known resolutions, effectively shortening debug cycles from hours to seconds.
“You can search if there is a black screen on a node. What are the probable problems?” Rajdeep explained. “It will go search and say: most likely this is the problem. If not, this is the next.”
This capability turns tribal debugging knowledge into a living, queryable knowledge graph that learns with every new ticket.
C. Graph as Memory for Agents
In AMD’s architecture, the graph serves as the persistent memory for all reasoning agents. Each node, representing systems, tickets, or commits, is connected through contextual relationships that allow agents to recall, compare, and act based on past behavior.
When a new issue or workflow request enters the system, the agent traverses the graph to find similar historical cases, enabling auto-healing and predictive response patterns.
As Rajdeep summarized, the system no longer depends on individuals recalling prior incidents. The context itself is encoded in the graph. This makes the platform both faster and more resilient as organizational knowledge compounds over time.
Impact and Measurable Outcomes
AMD’s new data intelligence layer has cut query time from minutes to sub-seconds, even as it scales to millions of relationships. By running graph queries directly on Iceberg data in MinIO AIStor via PuppyGraph, the team eliminated both ETL pipelines and data duplication.
The unified Iceberg layer also powers Dremio SQL and Cypher queries, giving engineers one foundation for analytics, graph reasoning, and AI.
“You as a human also do that: check, validate, debug,” Rajdeep said. “That knowledge is stored here so that agents can do it.”
With LangChain agents accessing real enterprise data instead of static embeddings, AMD can now experiment, diagnose, and automate faster, proving that open-format graph architectures can be both production-ready and lightweight.
From POC to Production Graph Intelligence
AMD’s implementation proves that GraphRAG isn’t limited to LLM demos or prototypes. It’s a production-ready pattern for turning enterprise data into active knowledge. By combining open formats like Apache Iceberg and AIStor object storage with graph compute from PuppyGraph, AMD avoided the data silos, duplication, and lock-in that slow most AI initiatives.
Instead of building a static knowledge base or retraining models endlessly, the system lets AI reason directly over live enterprise data, tickets, logs, commits, telemetry, all connected in context. This shift moves AI from retrieval to true reasoning.
For other engineering and IT organizations, AMD’s experience highlights a repeatable blueprint:
- Use open data formats on a high-performance S3-compatible object store to unify data and schema evolution.
- Layer a zero-ETL graph engine for relationship awareness and sub-second traversal.
- Integrate agentic frameworks like LangChain to translate human questions into graph logic.
The result is a living, queryable memory for the enterprise. One that evolves as fast as the systems it represents.
What’s Next for AMD’s Graph Intelligence Platform
Rajdeep’s team is now extending the graph foundation beyond IT and infrastructure into software engineering and DevOps domains, applying the same reasoning framework to code analysis, dependency tracking, and change management.
The architecture remains consistent:
- PuppyGraph, Iceberg, and LangChain as the core reasoning stack.
- AIStor provides globally consistent object storage, while Nessie manages the Iceberg tables built on top of it.
- Dremio supports mixed SQL and graph access.
AMD is also experimenting with fine-tuned retrieval and hybrid search, combining vector, graph, and semantic queries for deeper context understanding.
As the system matures, it’s becoming more than a data platform; it’s the foundation for agentic operations across AMD, where AI systems learn from history, act in context, and improve continuously.
In Rajdeep’s words:
“The data is all there: tickets, commits, telemetry. Now it’s connected, and it can act.”
That connection between data, reasoning, and action is what turns GraphRAG from an experiment into an enterprise capability.
Editor’s note:
This case study is based on the talk “GraphRAG on Iceberg” presented by Rajdeep Sengupta, Director of Systems Engineering at AMD, during the Bay Area Apache Iceberg Meetup on October 1, 2025 in San Francisco.
You can watch the full recording here:

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install