
AI in Banking: How To Use in Banks?
Artificial intelligence in banking has moved out of the innovation lab. A few years ago, most bank AI lived in proofs of concept and slide decks; today it runs in production paths that touch real money: scoring a card transaction for fraud in the milliseconds before it clears, drafting the first pass of a credit memo, answering a customer at two in the morning, ranking which of last night's anti-money-laundering alerts an investigator should open first. The shift is less about any single breakthrough model and more about banks finally putting the data they already hold to work against problems where the manual approach has stopped scaling.
This post walks through what AI in banking actually means, why the investment is accelerating now, where it shows up across the business, and the benefits it delivers. It then goes deep on the use case where the stakes and the maturity are both highest, fraud detection and financial crime prevention, surveys seven concrete generative AI use cases, and closes on the risks that any serious adoption has to manage.
What is AI in banking
AI in banking is the application of machine learning, natural language processing, and, more recently, generative models to the core functions of a bank: detecting fraud, deciding who gets credit, serving customers, managing risk, meeting compliance obligations, and running back-office operations. It spans a stack of technologies, layered onto processes that banks have run for decades.
It helps to separate three waves, because banks today operate all three at once. The first is classical machine learning and rules: gradient-boosted models and hand-tuned rule engines that score transactions, predict default, or flag suspicious activity. This is the workhorse, and it is mature. The second is deep learning: neural networks for document understanding, voice, and pattern recognition over high-dimensional data such as transaction sequences. The third is generative AI: large language models that summarize, draft, converse, and increasingly act as agents that retrieve information and take steps on a user's behalf. Most of the recent excitement and most of the new risk sit in this third wave, but the first two still carry the bulk of the value in production today.
Why banks are investing in artificial intelligence
The investment is not driven by novelty. Four pressures are converging at once, and AI is the lever that addresses all of them with the asset a bank already has the most of: data. The upside is substantial: McKinsey estimates that generative AI alone could add the equivalent of $200 billion to $340 billion a year across global banking, roughly 9 to 15 percent of the sector's operating profits, mostly through productivity gains (McKinsey, Capturing the full value of generative AI in banking, 2023).
Cost and efficiency pressure. Margins in retail and commercial banking are thin, and a large share of operating cost is manual review: reading documents, clearing alerts, answering routine service requests, reconciling exceptions. Each of these is a task where a model can do the first pass and let a human handle the judgment calls, which is where most of the efficiency gain actually comes from.
Rising fraud and financial-crime losses. Fraud losses reached an estimated $485 billion globally in 2023 (Nasdaq Verafin 2024 Global Financial Crime Report), and the schemes behind them, real-time-payment abuse, account takeover, and synthetic-identity fraud, have grown faster than the rule-based systems built to catch them. As payments settle faster, the window to stop a fraudulent transfer shrinks, which pushes detection toward models that can score in real time rather than batch reviews after the fact.
Customer expectations set elsewhere. Digital-native fintechs and big-tech payment apps reset what customers consider normal: instant onboarding, in-app answers, personalized prompts. Incumbent banks invest in AI in part to close that experience gap without proportionally growing headcount.
Regulatory and risk-management load. Know-your-customer (KYC) refresh cycles, sanctions screening, suspicious-activity reporting, model validation, and fair-lending review are all labor-intensive and all growing. AI does not remove the obligation, but it can triage, summarize, and pre-fill the work that compliance staff then sign off on.
Underneath all four is a quieter point: banks sit on decades of transaction history, account relationships, and customer records, much of it underused because it lives in separate systems that are hard to query together. The driver for AI adoption is structural: the competitive pressure and the latent data are both already in the building, and AI is what connects them.
How AI is transforming the banking industry
AI does not show up in one place. It threads through nearly every function, in different forms and at different levels of maturity. The map below is the breadth; later sections go deep on the parts that matter most.
Retail and customer-facing banking. Virtual assistants and chatbots handle balance queries, card controls, and routine disputes; recommendation models surface the next-best product or a savings nudge; churn models flag accounts at risk of leaving. The outcome banks care about is deflecting routine contacts to self-service while routing genuinely complex cases to humans faster.
Lending and credit. Models extend underwriting beyond traditional bureau scores, incorporating cash-flow data and alternative signals to assess thin-file or credit-invisible applicants. The same models speed up decisioning, taking commercial-loan reviews from days to hours, though credit decisions carry explainability obligations that constrain how freely a black-box model can be used.
Risk management. AI sharpens credit-risk, market-risk, and liquidity models, and increasingly powers early-warning systems that watch portfolios for deterioration. The value is less in a single better forecast and more in continuously scanning more positions than a risk team could review by hand.
Compliance and financial crime. Transaction monitoring, sanctions screening, and KYC are heavy AI consumers, mostly aimed at the same problem: too many alerts, too few of them real. Models that cut false positives free investigators to spend time on the alerts that actually warrant a suspicious-activity report. On the wholesale side, the same surveillance approach watches trading activity for market-abuse patterns.
Operations and the back office. Document processing, reconciliation, exception handling, and intelligent process automation take repetitive work off staff. This is the least glamorous and often the highest-ROI category, because the baseline is fully manual.
Read together, the pattern is consistent: AI rarely replaces a banking function outright. It does the high-volume first pass and lets scarce human expertise concentrate where judgment, accountability, and regulatory sign-off actually require a person.
Key benefits of AI in banking
The benefits worth naming are outcomes, not model capabilities. Each one also carries a trade-off that determines whether it is real in practice.
Faster and more accurate fraud catch. Models score transactions in real time and learn patterns that static rules miss, catching more fraud while clearing legitimate transactions faster. The benefit is bounded by false positives: a model that blocks too many good transactions costs more in customer friction than it saves in fraud, so the real metric is precision at an acceptable recall, not raw detection rate.
Lower operating cost. Automating first-pass review across service, compliance, and back-office work reduces cost per transaction. The gain is realized only when the human-in-the-loop step is genuinely lighter, not when staff end up re-checking every model output anyway.
Around-the-clock, personalized service. Conversational AI gives customers immediate answers at any hour and tailors prompts to their actual behavior. The constraint is trust: a confidently wrong answer about someone's money erodes more goodwill than a slow correct one, which is why grounding and escalation paths matter more here than raw fluency.
Better credit access and decisions. Richer models can responsibly extend credit to applicants that thin bureau files would have rejected, expanding the addressable market while pricing risk more precisely. This benefit is the most regulated, because the same model that widens access can encode bias if its inputs proxy for protected characteristics.
Faster compliance review. Summarizing case files, pre-filling reports, and triaging alerts compresses the time investigators spend per case. The benefit holds only if the model's prioritization is trustworthy enough that analysts stop manually re-triaging behind it.
The through-line is that every benefit is a function of where the human stays in the loop. AI in banking pays off when it removes the volume from a task without removing the accountability, and it disappoints when teams adopt the model but keep the manual process running in parallel out of distrust.
AI for fraud detection and financial crime prevention
Fraud detection and anti-money-laundering (AML) are where AI in banking is both most mature and most consequential, so they deserve a closer look than the breadth tour above.
The starting point is transaction monitoring. Supervised models, trained on labeled fraud and confirmed suspicious activity, score transactions and behaviors against known patterns. Unsupervised methods, anomaly detection and clustering, catch novel patterns that no label exists for yet, which matters because fraud typologies shift constantly to evade whatever caught them last quarter. Both run alongside the rule engines banks already operate; the models do not replace the rules so much as reduce how many of the rules' alerts turn out to be noise.
That noise is the defining problem of financial-crime compliance. In a typical AML program, the large majority of alerts are false positives, and every one still has to be reviewed and dispositioned by a human investigator. The expensive constraint is investigator time. So the highest-value AI work in this space is often not finding more alerts but ranking and contextualizing the alerts already firing, so the ones that warrant a suspicious-activity report rise to the top.
Entity resolution is the second hard problem. A single bad actor may operate under several lightly varied identities, across multiple accounts, sometimes across institutions. Tying those records to one underlying party is a prerequisite for seeing the real picture, and it is its own modeling challenge before any fraud scoring happens.
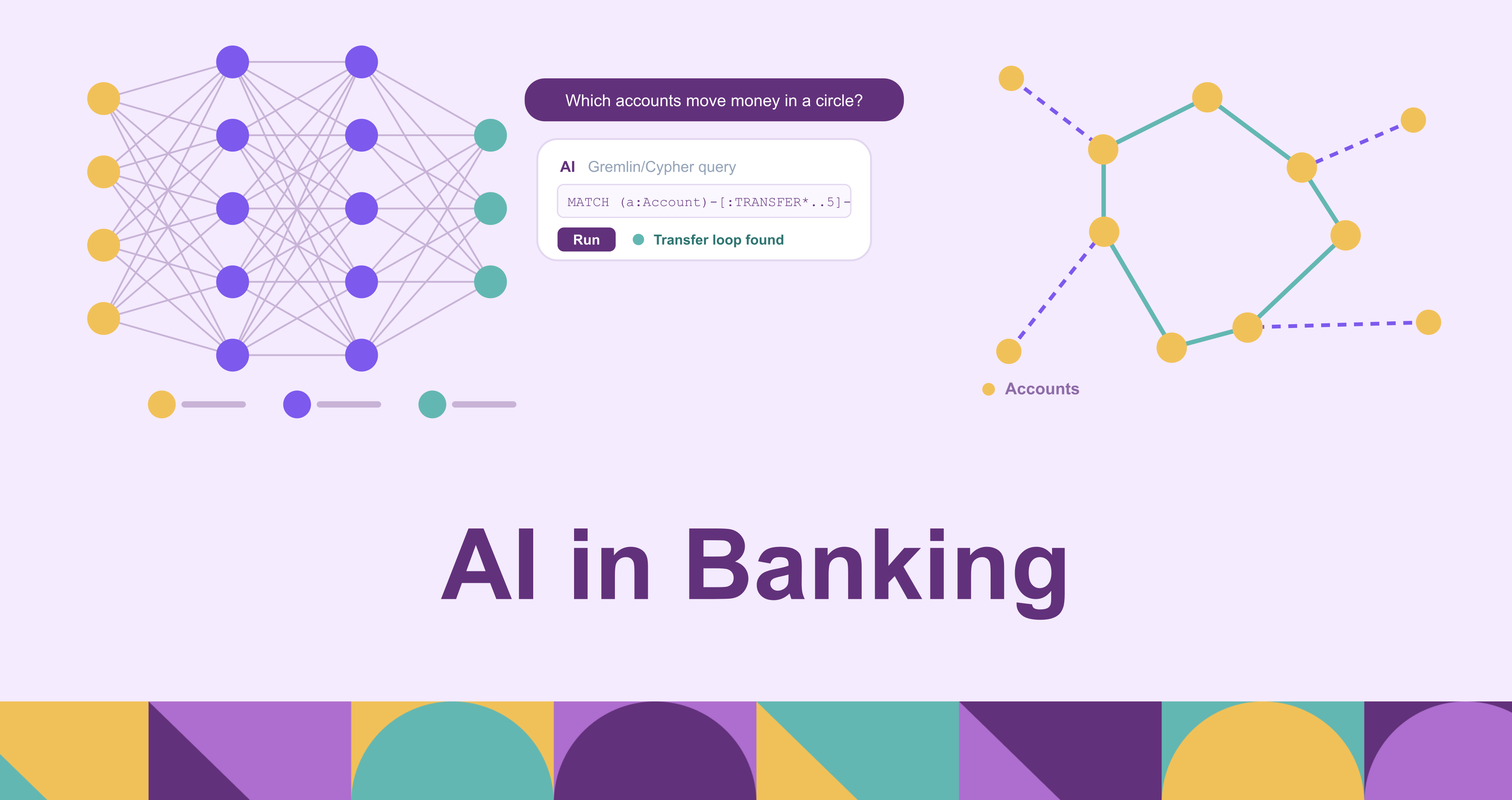
The third problem is the one that single-record scoring is structurally bad at. Sophisticated fraud and money laundering are relationships, not isolated transactions. A money-mule network, a circular-payment laundering scheme, a fraud ring opening accounts in coordination: none of these is visible in any one transaction scored on its own. They are visible only in how accounts, transactions, devices, and identities connect to one another. A model looking at one transaction at a time, however good, is looking at the wrong unit of analysis. The signal lives in the structure between records, and seeing it means traversing those connections, often many hops deep, across data that usually sits in separate systems.
This is the point where a graph approach earns its place. Representing accounts, customers, devices, and transactions as nodes and edges turns finding the laundering ring from a hard correlation problem into a path-traversal query. The obstacle has historically been that building a graph meant standing up a separate graph database and copying data into it through an ETL pipeline, which adds a synchronization lag a bank can rarely afford when the data it needs to traverse is its transaction history.
PuppyGraph addresses that obstacle by querying the bank's existing tables as a graph directly, with no ETL and no second copy of the data. It runs as a graph compute layer over data that stays in the warehouse, lake, or an open table format such as Iceberg, so the same transaction and account tables that feed the rest of the bank's analytics become traversable as a graph. Analysts query them in openCypher (Gremlin is also supported), and because compute and storage are separate, the graph layer scales independently of where the data lives. It complements transaction-monitoring and case-management systems by adding the relationship view they lack, over the data the bank already has.
A circular-payment query that would be awkward to express in SQL becomes direct as a traversal:
// Find circular fund flows: money that leaves an account and returns
// through a chain of 2 to 5 transfers within a 14-day window, each
// just under the $10,000 reporting threshold (a structuring signal).
MATCH cycle = (origin:Account)-[hops:TRANSFER*2..5]->(origin)
WHERE all(t IN hops WHERE t.amount >= 8000 AND t.amount < 10000)
AND all(t IN hops WHERE t.ts >= datetime() - duration('P14D'))
RETURN origin.id,
length(cycle) AS ring_length,
[t IN hops | t.amount] AS amounts
ORDER BY ring_length DESCThe same model extends to money-mule detection (accounts one or two hops from a confirmed-fraud account that suddenly start moving funds), shared-device rings (distinct identities that transact from the same device fingerprint), and built-in graph algorithms such as community detection to surface clusters that no single rule was written to find. PuppyGraph's users include Coinbase; the pattern generalizes to any institution whose fraud signal lives in how accounts and transactions connect rather than in any one of them alone.
The takeaway for this section is that AI for financial crime is a layered system: models to score, entity resolution to know who is who, and a relationship view to catch the coordinated schemes that per-transaction scoring cannot see. The graph layer is the part most banks are missing, largely because the data integration was historically too costly even though the technique itself is well understood.
7 generative AI use cases in banking
Generative AI is the newest wave and the one with the most active pilots. Seven use cases have moved beyond demos into real deployments, each with a caveat that keeps it honest.
- Customer-service assistants. LLM-powered assistants answer account questions, walk customers through disputes, and explain products in natural language, escalating to a human when confidence is low. The caveat is grounding: the assistant must answer from the customer's actual data and the bank's real policies, not from the model's general training, or it will be confidently wrong about someone's money.
- Document processing and summarization. Loan files, KYC packets, contracts, and correspondence get parsed and summarized, turning hours of reading into a reviewable digest. The human still signs off, but starts from a draft rather than a blank page.
- Code generation and legacy modernization. Engineering teams use code assistants for everyday development and, more pointedly, to document and translate the COBOL and other legacy code that core banking systems still run on. Generated code is reviewed and tested like any other; the value is in accelerating comprehension of systems whose original authors have long since left.
- Personalized financial guidance. Models generate tailored next-best-action prompts, spending insights, and savings nudges grounded in a customer's own transaction history. The line to stay behind is regulated financial advice; guidance is framed as information, not a recommendation that triggers suitability obligations.
- Report and disclosure drafting. Risk reports, regulatory filings, and internal memos get a first draft from a model working off structured inputs. Given the regulatory weight of these documents, human review is not optional, and the model's job is to compress drafting time, not to file anything itself.
- KYC, onboarding, and adverse-media screening. Generative models summarize adverse-media hits, draft customer-due-diligence narratives, and speed onboarding review. Because false negatives here carry regulatory consequences, these systems run as investigator aids with the decision staying human.
- Synthetic data generation. Banks generate synthetic transaction and customer data to train and test models without exposing real customer information, which also helps balance datasets where genuine fraud examples are rare. The caveat is fidelity: synthetic data has to preserve the statistical patterns that make a model useful without leaking the real records it was derived from.
Across all seven, the same discipline recurs: generative AI in banking is deployed as a drafting and triage layer with a human accountable for the output, not as an autonomous decision-maker. The institutions getting value are the ones that scoped it that way from the start.
Challenges and risks of AI adoption in banking
These risks are manageable, and managing them is the work that separates a serious program from a demo. Most of them are governance problems before they are technical ones.
Model risk and explainability. Banks operate under model-risk-management expectations (in the US, the SR 11-7 supervisory guidance is the common reference point), which require models to be validated, monitored, and explainable. A credit model that cannot produce a reason for a denial cannot issue the adverse-action notice that fair-lending rules require, which alone rules out unexplainable black boxes for many lending decisions.
Bias and fair lending. A model trained on historical data can learn historical discrimination, and inputs that correlate with protected characteristics can encode bias even when those characteristics are excluded. Fair-lending testing is not a one-time check but an ongoing obligation, and it constrains which features a model may use at all.
Data governance and privacy. AI is only as good as the data feeding it, and banking data is sensitive, regulated, and spread across systems. Using it for AI raises questions of consent, residency, retention, and access control that have to be answered before a model goes near production.
Hallucination in generative systems. A language model that fabricates a fact about a customer's account or a regulation is a direct liability. This is why every generative use case above is scoped with a human accountable for the output, and why grounding the model in the bank's real data matters more than raw fluency.
Third-party and concentration risk. Heavy reliance on a small number of foundation-model providers and cloud platforms concentrates operational and vendor risk, which regulators have begun to scrutinize as a systemic concern.
The grounding problem deserves one concrete note, because it connects back to the data architecture. When a bank deploys an AI agent over its financial data, the agent's reliability depends on it querying what actually exists rather than inventing entities or relationships; grounding it on an enforced ontology over the bank's data keeps its generated queries semantically aligned with the real schema and bounds what it can reach to what the ontology exposes. That is a risk-management property, not a security control on its own, but it is the kind of structural guardrail that makes agentic AI defensible in a regulated environment.
The common thread is that the hard part of AI in banking is governance: validation, monitoring, explainability, fairness, and data control. Banks that treat those as the actual project, rather than as compliance overhead bolted on at the end, are the ones whose AI survives contact with a regulator.
Conclusion
AI in banking has crossed from experiment to infrastructure. The value is no longer a single clever model but a layered system: classical ML and rules carrying the production load, deep learning reading documents and sequences, generative AI drafting and triaging with a human in the loop, and governance wrapped around all of it. The institutions pulling ahead are the ones that connected the data they already had to the problems that data could finally solve, fraud and financial crime chief among them, and that built the validation and oversight to run it safely.
If you are working on the financial-crime side of that picture, where the signal lives in how accounts and transactions connect, you can try the graph approach on your own data with PuppyGraph's forever-free Developer Edition (https://www.puppygraph.com/download-confirmation), which queries your existing tables as a graph with no ETL. For a walkthrough of how the graph layer fits alongside your current fraud and AML stack, book a demo with the team (https://www.puppygraph.com/book-demo).

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.


