
Enterprise Data Security Solutions: Types and Best Practices
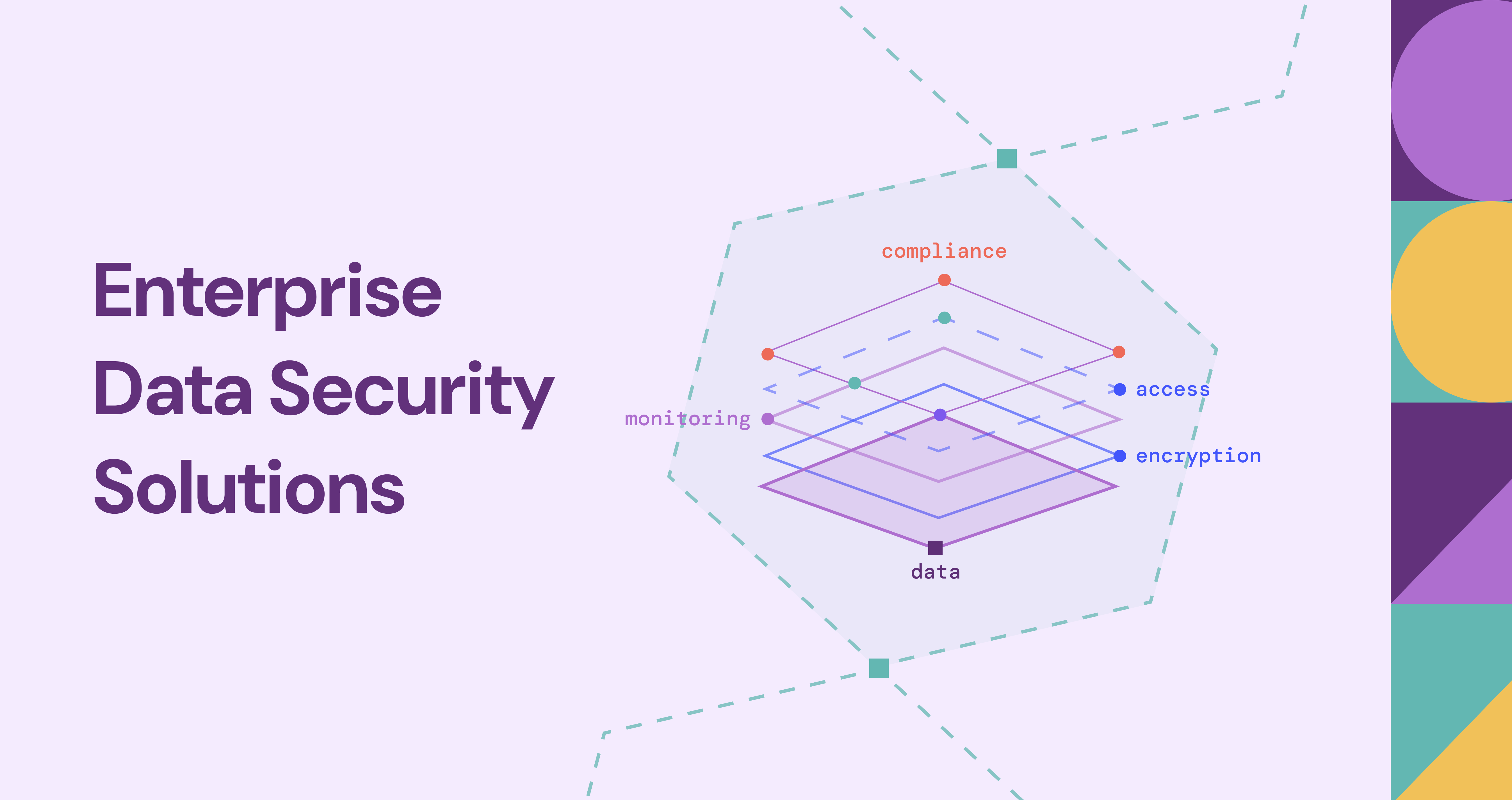
Enterprise data no longer sits in one place. It spreads across data warehouses and lakes, dozens of SaaS applications, multiple clouds, and the endpoints employees carry home, and copies of it propagate faster than any one team can track. Protecting it is therefore not a single control but a portfolio of overlapping categories, each of which covers a slice of the problem: finding sensitive data, stopping it from leaving, rendering it unreadable if stolen, governing who can reach it, and recovering it when something goes wrong. The difficulty is rarely that one category is missing. It is choosing the right combination and making the slices add up to coverage rather than gaps.
This post defines what enterprise data security covers and how it differs from adjacent disciplines, explains why it has become harder, maps the main categories of solutions and what each does and does not do, lays out how to choose among them, and ends with the practices that hold a program together.
What is enterprise data security?
Enterprise data security is the protection of data itself, across its lifecycle and wherever it resides, against unauthorized access, exfiltration, loss, and tampering, at organizational scale and under regulatory obligation. The phrase "data itself" is the important part. The goal is to protect the information regardless of which system holds it at a given moment, which means securing data at rest (in storage), in transit (moving between systems), and in use (being processed), rather than only hardening the perimeter around it.
It helps to place data security next to the disciplines it is often confused with. Network security defends the wire: the traffic between systems and the boundary around them. Endpoint security defends the device: the laptop, server, or container where work happens. Posture and threat monitoring provide continuous visibility into controls and attacker activity. Data security is the discipline concerned with the data and with who can reach it, which is why it cuts across all the others. A file can be protected at the network and endpoint layers and still be exposed because too many identities have standing access to it, and that exposure is what data security is meant to address.
Why enterprise data security matters
Three forces have made the problem harder at roughly the same time. The first is data sprawl. Sensitive records now live across multi-cloud storage, SaaS platforms, and analytical data lakes, often copied and transformed many times, so the simple question of where the sensitive data is has itself become difficult to answer. The second is regulatory pressure: regimes such as GDPR, HIPAA, PCI DSS, and CCPA impose specific obligations on how particular categories of data are handled, retained, and reported, with real penalties for getting it wrong. The third is the widening set of consumers that can reach data, including the AI systems enterprises are now wiring directly into their data stores, which expands both the value of the data and the number of paths to it.
The stakes are concrete: the cost of a breach, the share of incidents that involve sensitive or customer data, and the persistent role of insider risk all argue for treating data protection as its own program rather than a byproduct of network and endpoint defenses. These pressures are not independent: sprawl multiplies the surface that regulation governs and that an insider or attacker can reach, which is why the categories below are usually deployed together rather than singly.
Types of enterprise data security solutions
The market organizes into a handful of solution categories. They overlap at the edges, and several vendors bundle multiple categories into one platform, but the categories solve distinct problems and it pays to keep them distinct when reasoning about coverage. The order below is roughly the order in which they apply: you cannot protect what you have not found, so discovery comes first.
Data discovery and classification. These tools scan structured and unstructured stores to locate sensitive data and label it by type and sensitivity, increasingly with machine-learning assistance for accuracy. Classification is the prerequisite for everything else, because every other control needs to know what it is protecting. The boundary worth noting: discovery tells you what and where, not who can reach it or whether it is leaving, which is the job of the categories below.
Data loss prevention (DLP). DLP monitors and blocks inappropriate movement of sensitive data across channels such as email, endpoints, and cloud uploads, enforcing policies that stop, for example, a classified file from being sent to a personal account. It is the egress-control category. Its limitation is that it is only as good as the classification feeding it and the channels it covers, and it is oriented toward data in motion rather than the standing exposure of data at rest.
Encryption, tokenization, and key management. These render data unreadable to anyone without authorization, protecting it at rest, in transit, and increasingly in use. Encryption transforms data with a key that authorized parties hold; tokenization substitutes sensitive values with non-sensitive surrogates, which is common for fields like payment numbers. Both depend on enterprise key management, since the protection is only as strong as the control over the keys. The boundary: encryption protects against an attacker who obtains the data but does not, by itself, govern which authorized identities should have access in the first place.
Identity and access management and access governance. This category enforces who can reach which data, built on least privilege and role-based access, with periodic entitlement review to catch access that accumulated beyond what a role needs. It is where the question of standing access lives. Its challenge at enterprise scale is that entitlements sprawl across systems and groups, so knowing the effective access any one identity actually has often requires piecing together roles, group memberships, and grants from several sources.
Data security posture management (DSPM). DSPM continuously discovers where sensitive data lives across cloud environments and assesses its exposure and posture: misconfigurations, over-permissive access, unencrypted stores, and shadow copies. It is distinct from DLP. DLP watches data leaving; DSPM watches the standing state of data and its configuration, answering "where is sensitive data exposed right now" rather than "is something exfiltrating it." The boundary: DSPM surfaces exposure, but remediating it still depends on the access-governance and encryption controls above.
Backup, recovery, and resilience. These protect against loss, corruption, and ransomware by maintaining recoverable copies and tested restoration paths. The category is sometimes treated as an availability concern rather than a security one, but in the ransomware era it is squarely a data security control. The boundary worth stating: backups protect against loss, not against unauthorized access, and poorly secured backups are themselves a target, so this category has to be governed by the access controls above rather than sitting outside them.
Data governance and compliance. This is the policy and accountability layer: classification policy, audit logging, retention schedules, separation of duties, and the reporting that demonstrates compliance to an auditor. It ties the technical categories to obligations, defining what the other tools should enforce and producing the evidence that they did.
The pattern across all of these is that each category produces its own slice of the picture, in its own tool, with its own data. Discovery knows what is sensitive; IAM knows who has roles; DSPM knows what is exposed; governance knows the policy. The slices are rarely joined, which is what makes the next two sections, choosing among them and connecting them, the harder part of the work.
How to choose enterprise data security solutions
Choosing is less about ranking vendors than about sequencing controls to your data and your obligations.
Start from discovery. You cannot protect, classify policy for, or report on data you have not located. A program that begins anywhere other than discovery and classification tends to protect the data it already knew about and miss the sprawl, so treat discovery as the foundation the rest builds on.
Match controls to data states and locations. Decide which protections you need for data at rest, in transit, and in use, and where that data actually lives: warehouse, lake, SaaS, or endpoint. The right mix for a regulated data warehouse differs from the right mix for unstructured data scattered across collaboration tools, so map controls to states and locations rather than buying one tool and hoping it reaches everything.
Scope to your regulatory obligations. Let the regimes you operate under define the non-negotiable controls: what must be encrypted, retained for how long, access-logged, and producible on demand. Compliance scope often settles debates about which categories are mandatory versus nice to have.
Check integration with your stack and identity provider. Data security tools are only effective if they reach where your data lives and align with how identity is already managed. Native integration with your cloud platforms, data stores, and identity provider is worth more than a longer feature list that requires custom plumbing.
Weigh operational overhead and consolidation. Every category added is a tool to run and tune. The industry trend toward consolidated data security platforms (DSPs) that bundle discovery, DLP, DSPM, and governance reflects the real cost of operating point tools separately. Consolidation reduces overhead but increases dependence on one vendor; weigh both honestly against your team's capacity.
There is a question that cuts across every category above, and no single one of them answers it cleanly: which identities can reach which sensitive datasets, through which roles, entitlements, and group memberships, and what is the blast radius if one of those identities is compromised. Discovery knows the data is sensitive, IAM knows the roles exist, and DSPM knows something is exposed, but joining them into "this person, through this chain of grants, can reach this regulated dataset" means relating data that lives in separate tables across the warehouse, lake, or an open table format such as Iceberg. That is a multi-hop relationship problem, and it is the kind of problem a graph layer is built for. PuppyGraph is a graph query engine that maps those existing identity, entitlement, dataset, and classification tables to a graph and lets a team traverse the access paths directly, without copying the data out (zero-ETL, querying the tables in place) and with compute separated from storage. The cross-cutting access question becomes a path query:
MATCH (u:Identity)-[:HAS_ROLE]->(:Role)-[:GRANTS]->(d:Dataset)
WHERE d.classification = 'restricted'
RETURN u.name, collect(d.name) AS reachable_restricted_data
PuppyGraph speaks openCypher (its default; Gremlin is also supported), so the query runs against the tables a data team already maintains. The boundary matters: PuppyGraph is not a data security tool in the sense the categories above are. It is not DLP, not an encryption or key-management system, and not a DSPM scanner. It is a relationship and correlation layer that complements those tools, letting you reason about who can reach what and what the exposure of any one identity actually is, over data your other controls already produce. Security teams including Palo Alto Networks, Datadog, Netskope, and Trend Micro use PuppyGraph for this kind of relationship analysis.
Best practices for enterprise data security
Classify first, and keep classifying. Treat discovery and classification as ongoing rather than a one-time project, since data sprawl is continuous and stale classification quietly erodes every control that depends on it.
Enforce least privilege and review entitlements. Grant the minimum access a role needs, and review entitlements on a schedule to catch the access that accumulates over time. Standing over-access is one of the most common and most reachable exposures.
Encrypt by default and manage keys properly. Encrypt data at rest and in transit as a baseline, and treat key management as a first-class concern, because the protection is only as strong as the control over the keys.
Apply defense in depth across data states. No single category covers data at rest, in transit, and in use; combine them so a gap in one is backstopped by another rather than left open.
Monitor access continuously and map who can reach what. Beyond logging access, periodically map the effective access paths to sensitive data, so over-permissioned identities and unexpected reachability surface before an incident does rather than after.
Test recovery, not just backup. A backup that has never been restored is an assumption, not a control. Exercise recovery so it works when it is needed, and secure the backups themselves under the same access governance as production data.
Align controls to compliance and prove it. Map each control to the obligation it satisfies and keep the audit evidence current, so demonstrating compliance is a query rather than a fire drill.
Conclusion
Enterprise data security is a portfolio, not a product. Discovery tells you what you have, DLP and encryption protect it as it moves and rests, access governance and DSPM manage who can reach it and how it is exposed, and backup and governance keep it recoverable and accountable. The leverage is in knowing where sensitive data lives and who can reach it, then combining controls so the slices add up to coverage. The recurring hard question, what the access paths and blast radius actually are across all that data, is a relationship problem, which is where a graph layer over your existing tables complements the rest of the stack.
To reason about data access and exposure as a graph over your existing tables, the PuppyGraph Developer Edition is forever-free and connects directly to where your data already lives: download it here. If you would rather see access-path and blast-radius analysis walked through against a realistic data model, book a demo with the team.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.


