

Agentic Text-to-SQL: A Detailed Guide
The rapid adoption of large language models has transformed how users interact with data, but traditional Text-to-SQL approaches remain fundamentally limited by their single-shot nature. These systems treat query generation as a direct translation problem, often failing in complex, real-world environments where ambiguity, schema scale, and business logic introduce significant challenges. As enterprise data ecosystems grow in size and complexity, a more adaptive and reliable paradigm is required.
Agentic Text-to-SQL emerges as this next evolution. By reframing query generation as a multi-step, goal-oriented reasoning process, it enables systems to plan, act, and refine iteratively. Rather than producing SQL in isolation, agentic systems interact with the data environment, leverage feedback, and collaborate across specialized agents. This shift moves data access from static translation toward intelligent analysis, laying the foundation for more autonomous and trustworthy data-driven decision-making.
What is Agentic Text-to-SQL
Agentic Text-to-SQL is an advanced framework that redefines semantic parsing, transitioning it from a "single-shot" translation task into a multi-step, autonomous problem-solving process. While traditional paradigms treat Text-to-SQL as a direct mapping problem, linguistically converting natural language into Structured Query Language (SQL), the agentic approach reframes this interaction as a sequence of goal-oriented actions. Unlike static models that attempt to generate code in one pass, an agentic system treats the database as a dynamic, interactive environment.
The core philosophy centers on a fundamental shift from prediction to reasoning. By leveraging Large Language Models (LLMs) as central reasoning engines, these systems employ a Chain-of-Thought (CoT) methodology to decompose complex requests, navigate "schema noise," and self-correct through environmental feedback. In essence, Agentic Text-to-SQL evolves the AI from a passive translator into an autonomous data analyst. This transition is vital for modern enterprise environments where ambiguous naming conventions and massive metadata volumes demand the iterative verification and nuanced planning that single-pass LLM calls cannot provide.
Architecture of Agentic Text-to-SQL Systems
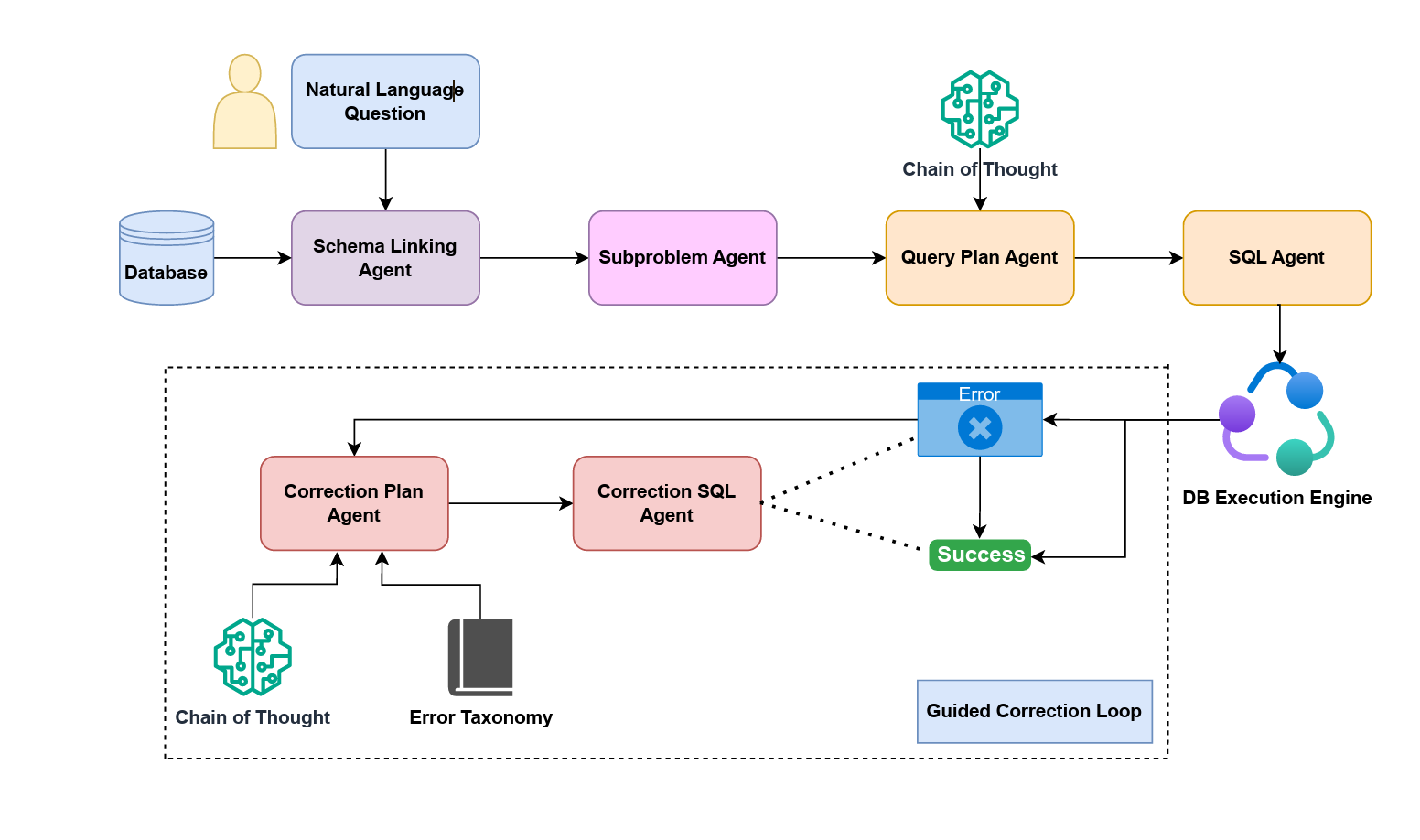
The architecture of an Agentic Text-to-SQL system is a multi-layered framework designed to replicate the sophisticated cognitive workflow of a human data scientist. Unlike traditional "Text-to-SQL" models that perform a direct translation from natural language to code, an agentic architecture is modular, resilient, and specialized. It consists of five primary layers that work in synchronization to bridge the semantic gap between human intent and structured database execution.
I. The Reasoning & Planning Layer
At the entry point of the system sits the Reasoning and Planning Layer, often referred to as the "Brain" of the operation. This layer is centered around a Planner Agent (or Orchestrator) that utilizes high-order reasoning techniques such as CoT and Tree-of-Thoughts (ToT).
Instead of generating syntax immediately, the Planner decomposes a user’s request into a "Reasoning Path." For complex analytical queries, such as calculating year-over-year growth or cohort retention, the Planner identifies that it must first isolate distinct time periods, calculate intermediate aggregates, and then apply mathematical transformations. By creating this high-level execution plan, the system avoids the "logical leaps" that often lead to errors in non-agentic models.
II. The Knowledge Retrieval & Grounding Layer
The Knowledge Retrieval & Grounding Layer serves as the system's "Context Engine," addressing the pervasive issue of "schema noise." In enterprise environments where databases may contain thousands of tables, providing the entire schema to a LLM results in context window overflow and "lost-in-the-middle" phenomena.
- Schema Agent: This component performs dynamic Schema Linking via Retrieval-Augmented Generation (RAG). It identifies only the necessary tables, columns, and foreign key relationships required for the specific plan generated in Layer 1.
- Content Search Tool: This tool allows the agent to "peek" into the data distribution. By performing vector searches or distinct value lookups, it ensures that entities mentioned in the user's prompt (e.g., "The Big Apple") are correctly mapped to stored literals (e.g., 'New York City'), grounding the SQL in reality.
III. The Multi-Agent Generation Layer
This is the "Engine Room" where abstract plans are converted into executable code through role-based collaboration. The architecture employs a Multi-Agent System (MAS) to distribute cognitive load:
- Programmer Agent: Specializes in the nuances of specific SQL dialects (PostgreSQL, Snowflake, BigQuery). It is responsible for the technical synthesis of the query, ensuring that JOIN conditions and window functions are syntactically correct.
- Critic/Reviewer Agent: Acts as an automated peer-reviewer. It performs "static analysis," checking for common pitfalls such as Cartesian products, missing GROUP BY clauses, or inefficient subqueries that could lead to performance bottlenecks in production environments.
IV. The Self-Correction & Execution Layer
The Self-Correction & Execution Layer represents the "Quality Control Lab" and is the hallmark of agentic design. It features a Sandbox Execution Engine where queries are tested against a live or mirrored database environment. This layer is not merely a pass-through; it is an iterative loop. If the database returns a runtime error or a timeout, the Refiner Agent captures the specific traceback. It uses this feedback to "reflect" on the failure, identifying whether the error was a structural misunderstanding of the schema or a simple syntax typo, before triggering a regeneration cycle.
V. The Verification & Formatting Layer
The final layer, the Verification & Formatting Layer, ensures that the output is both accurate and consumable. A Validator Agent performs a post-execution check: it compares the returned dataset against the original user intent to ensure semantic alignment. Once verified, a Response Generator transforms the raw rows and columns into natural language insights, interactive tables, or data visualizations, completing the bridge from "Data" back to "Decision."
How Agentic Text-to-SQL Works
While the architecture provides the structural blueprint, the Agentic Workflow describes the dynamic, iterative lifecycle of a query. Drawing from recent advancements in autonomous database agents, such as the MAC-SQL (Multi-Agent Collaboration) framework, the workflow replaces linear translation with a "Reasoning-Acting-Correcting" cycle.
Step 1: Task Decomposition and Strategic Planning
The lifecycle begins when the Orchestrator receives a natural language question. The primary goal here is Decomposition. For instance, a request for "the top 3 products by profit margin in 2023" is broken down into a series of sub-tasks:
- Defining the business logic for "profit margin" (e.g., (Revenue - Cost) / Revenue).
- Identifying the temporal filters required for the WHERE clause.
- Determining the necessary ORDER BY and LIMIT constraints. This step ensures that the agent understands the "Why" and "How" before it ever attempts the "What."
Step 2: Semantic Schema Linking and RAG Integration
To prevent "hallucinations," the workflow moves into the Schema Linking phase. In massive data warehouses, the agent must act as a librarian. Using semantic similarity, the Schema Agent retrieves the "minimal viable schema": the smallest set of metadata needed to answer the question. By grounding the LLM in the actual database catalog and primary-foreign key relationships, the workflow ensures that the generated SQL refers to real entities rather than invented table names.
Step 3: Collaborative Synthesis and Multi-Agent Dialogue
In an agentic framework, SQL generation is a collaborative dialogue rather than a single-shot attempt. The Programmer Agent drafts the initial SQL code based on the strategic plan. Simultaneously, the Reviewer Agent scrutinizes the draft. This is particularly vital for handling complex JOIN structures. If a query requires connecting five disparate tables, the Reviewer ensures that the join keys are correctly aligned according to the metadata retrieved in Step 2, preventing the execution of logically flawed queries.
Step 4: The Execution-Reflection Loop (Self-Correction)
This is the most critical stage of the agentic lifecycle, where the system "acts" and "learns." The SQL is submitted to the Sandbox, leading to three possible outcomes:
- Outcome A: Syntax/Runtime Error. The engine returns a traceback (e.g., "Column not found"). The agent analyzes the error, realizes it misinterpreted a column alias, and generates a corrected version.
- Outcome B: Empty Results. If a query runs but returns no data, the agent invokes a Content Search tool to verify if the user's filter (e.g., a misspelled city name) exists. It then adjusts the query and tries again.
- Outcome C: Success. The data is retrieved, and the loop terminates. This iterative "Reflection" mechanism allows agentic systems to solve complex benchmarks that traditional models fail to address.
Step 5: Final Semantic Verification and Insight Generation
Before the result is presented to the user, a Validator Agent performs a final audit. It asks: "Does this specific table of numbers actually answer the user's original question about product margins?" This prevents the "right answer to the wrong question" scenario. If the validation passes, the system uses a response generator to synthesize the data into a human-readable narrative, providing context, identifying trends, and ensuring the user receives a comprehensive answer rather than a raw data dump.
Role of AI Agents in Text-to-SQL
In an agentic Text-to-SQL framework, AI agents are not merely passive translators; they are autonomous entities that operate within a specialized "division of labor" to navigate the complexities of relational databases. The role of these agents is defined by their ability to act as intermediaries between unstructured human intent and the rigid constraints of SQL.
The primary roles performed by AI agents in this ecosystem include:
1. The Planner (Reasoning and Strategic Decomposition)
The Planner agent is responsible for high-level cognitive processing. Instead of attempting to generate a query immediately, it decomposes a natural language prompt into a logical sequence of sub-steps. This involves identifying the specific intent (e.g., trend analysis vs. point retrieval) and determining the order of operations. By creating a roadmap, the Planner ensures that the system handles nested subqueries and complex aggregations without losing track of the user's original goal.
2. The Schema Linker (Metadata Management and Retrieval)
A critical challenge in Text-to-SQL is "schema noise": the presence of hundreds of irrelevant tables. The Schema Agent acts as a precision filter. It uses semantic search and RAG to identify the exact tables, columns, and foreign key relationships necessary for the query. This agent "grounds" the system in the database catalog, ensuring the generated SQL refers to real, existing entities rather than "hallucinated" identifiers.
3. The Programmer (Code Generation and Tool Use)
The Programmer agent focuses on the technical translation of the plan into executable SQL. Unlike traditional models, this agent is equipped with "tools", such as content search functions to look up specific cell values (e.g., checking if a user means "California" or "CA") and syntax checkers. This role is defined by its ability to utilize environmental feedback to refine the code before it is finalized.
4. The Critic/Reflector (Self-Correction and Validation)
Perhaps the most distinctive role in an agentic system is that of the Critic. This agent performs "self-reflection" by analyzing the output of the Programmer. If a query fails during sandbox execution, the Critic examines the database traceback or error message (e.g., a JOIN error or a type mismatch) and provides corrective feedback. This iterative loop allows the system to autonomously debug its own mistakes.
5. The Orchestrator (Coordination and State Management)
The Orchestrator maintains the "memory" of the interaction. It manages the flow of information between the Planner, Programmer, and Critic, ensuring that the context of the user’s request is preserved throughout the iterative process. This role is essential for handling multi-turn conversations where a user might ask a follow-up question based on the previous result.
By moving away from a monolithic architecture to this role-based collaboration, Agentic Text-to-SQL systems can solve complex reasoning tasks that exceed the "context window" and logic capabilities of standard, single-pass LLMs.
Features of Agentic Text-to-SQL
Unlike traditional static models, Agentic Text-to-SQL systems are defined by their ability to "think," "act," and "refine." The following features distinguish this agentic approach as the next evolution in data interaction:
Multi-Step Reasoning and Problem Decomposition
The hallmark of an agentic system is its ability to break down a high-level natural language prompt into a series of logical sub-tasks. Rather than attempting to map a complex sentence to a SQL statement in one "leap," the agent utilizes a CoT process. It identifies discrete stages, such as identifying relevant entities, determining join conditions, and applying aggregations, before any code is written. This reduces the error rate for multi-table joins and nested queries that typically baffle non-agentic models.
Autonomous Self-Correction and Debugging
One of the most powerful features is the execution-feedback loop. When a generated query results in a database error (e.g., a syntax error or a type mismatch), the agent does not simply fail. Instead, it captures the engine's traceback, analyzes the error, and performs "self-reflection" to debug and regenerate the code. This iterative refinement allows the system to overcome initial misunderstandings of the schema or syntax without human intervention.
Dynamic Schema Linking and Tool Use
Traditional systems often struggle with "schema noise", the presence of hundreds of irrelevant tables. Agentic systems feature Active Schema Selection. They use specialized tools to browse the database catalog, sample data, and verify foreign key relationships dynamically. By acting as an explorer, the agent ensures that it only considers the metadata pertinent to the specific query, which significantly improves precision and avoids "hallucinated" column names.
Environmental Grounding (In-Context Verification)
Agentic Text-to-SQL is "grounded" in the actual data environment. If a query returns an empty result set, the agent can use a Content Search tool to check if the user’s requested value (e.g., a specific city name or product ID) actually exists in the database or if it is spelled differently. This ability to query the data to help write the query ensures that the final output is not just syntactically valid but contextually accurate.
Role-Based Collaboration (Multi-Agent Architecture)
Modern agentic frameworks often employ a multi-agent design where different "experts" collaborate. For example, a "Planner Agent" handles the logic, a "Programmer Agent" writes the SQL, and a "Critic Agent" reviews the code for security risks or optimization issues (like missing indexes). This division of labor mimics a professional data engineering team, ensuring higher quality and more robust governance than a single-model approach.
Traceability and Explainability
Because agentic systems follow a structured plan, they provide a clear "audit trail" of their reasoning. Users can see how the agent interpreted the request, which tables it selected, and why it chose certain filters. This transparency builds trust, especially in enterprise environments where users need to verify the logic behind a generated report or data insight.
Traditional vs Agentic Text-to-SQL: Difference
The fundamental difference between traditional and agentic systems lies in the transition from Translation to Analysis. While traditional models treat Text-to-SQL as a linguistic mapping problem, agentic systems treat it as a goal-oriented problem-solving task.
Bridging the Semantic Gap: Ontology & Ontology Enforcement
Despite the advanced reasoning of agentic workflows, a fundamental challenge remains: the Semantic Gap. In complex enterprise environments, LLMs often struggle to map human business logic to fragmented physical schemas. This leads to syntactically wrong queries or even "Silent Failures": queries that are syntactically perfect and executable but produce logically incorrect results because the agent misinterpreted the business context.
To solve this, we need to introduce the concepts of ontology and ontology enforcement.
1. The Semantic Foundation: Ontology and Enforcement
At the heart of a reliable agentic system lies the Ontology, a formal representation of domain-specific concepts and their interrelationships. It acts as a semantic abstraction layer that sits above physical tables, transforming cryptic column names and fragmented joins into meaningful business entities like "Customer," "Transaction," or "Lifetime Value."
Ontology Enforcement is the active validation mechanism that serves as a real-time gatekeeper. It ensures that every action taken by the agent strictly adheres to the structural and logical rules defined in the semantic layer. For AI agents, this matters for three critical reasons:
- Contextual Clarity: It provides the "Why" behind the "What," allowing agents to understand business rules rather than just syntax.
- Reduced Hallucination: By providing an explicit roadmap of valid relationships, the agent is less likely to "invent" non-existent paths between data points.
- Structured Feedback for Self-Correction: When a query violates business logic, the system doesn't just return a cryptic SQL error; it provides structured, LLM-readable feedback that explains the semantic violation, enabling a much more effective self-correction loop.
2. Empowering Reliable AI Agents
PuppyGraph addresses the limitations of agent-based data access by leveraging an ontology-enforced architecture. It acts as a critical bridge between raw, complex data and intelligent agents through several key capabilities:
- Abstracting Massive Schema Complexity: Instead of overwhelming an LLM with hundreds of fragmented tables, PuppyGraph abstracts them into rich, manageable entities and relationships. This significantly reduces the agent's cognitive load, preventing it from getting lost in intricate join logic.
- Eliminating Semantic Hallucinations: In multi-table environments, PuppyGraph’s explicit semantic layer acts as the single source of truth. It ensures the agent doesn't just write valid code, but follows the "Right" business logic, preventing logically flawed but executable queries.
- Bridging the "Feedback Gap": Without ontology enforcement, database errors (e.g., "Column not found") lack sufficient semantic context. PuppyGraph converts these into structured, LLM-readable feedback. When an agent violates a business rule, PuppyGraph explains why in semantic terms, enabling the agent to autonomously debug and refine its strategy. This structured feedback also creates a continuous improvement loop, where violation signals can be captured to fine-tune the LLM or drive reinforcement learning, making the agent progressively smarter over time.
3. Beyond Infrastructure: The Built-in Analytical Partner
Moving beyond mere architecture, PuppyGraph offers a seamless interface for direct interaction through its built-in agent. This agent allows both developers and business stakeholders to query complex datasets using intuitive, conversational language.
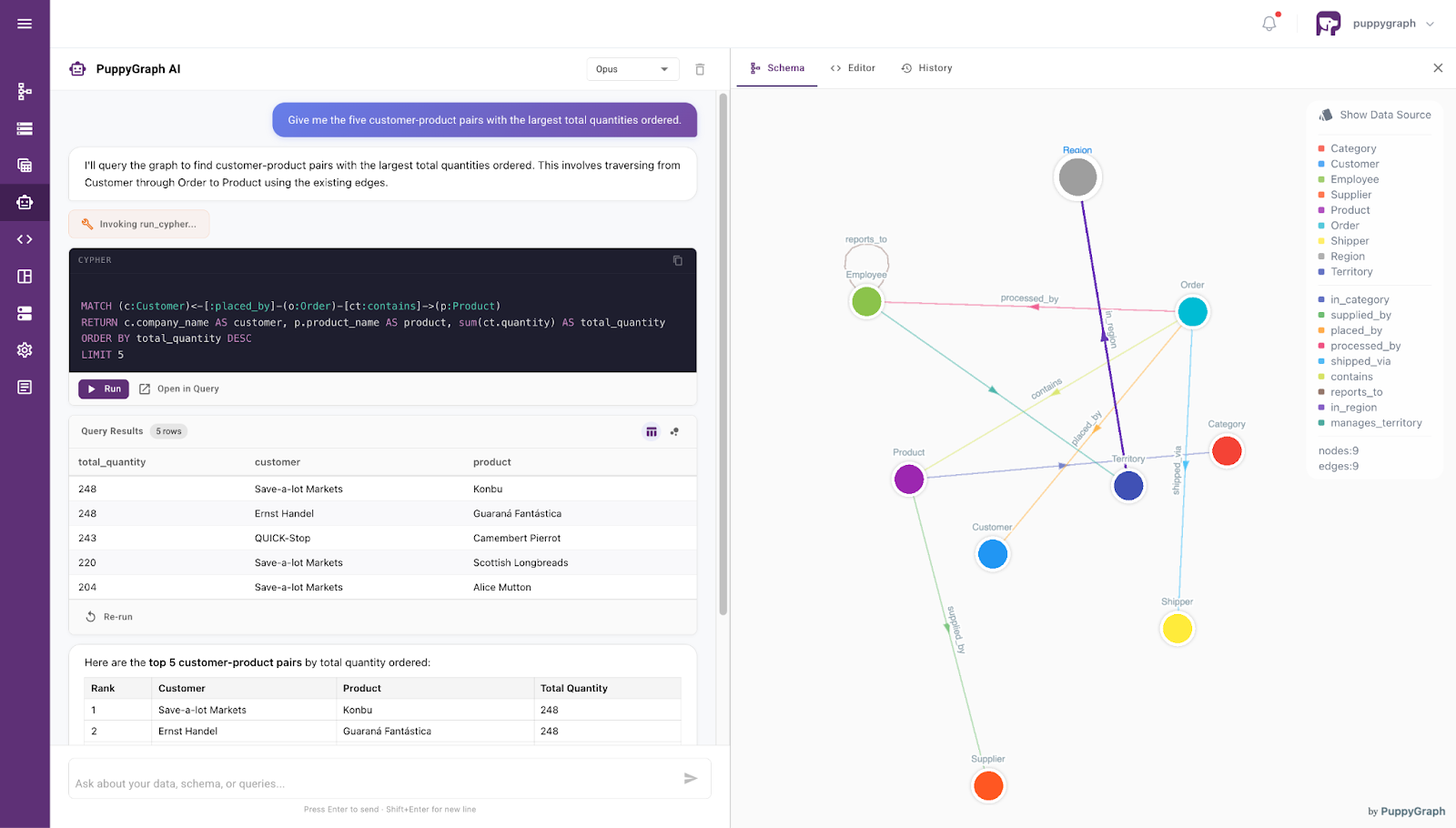
By leveraging the same ontology-enforced backbone, the PuppyGraph agent enables natural language-driven data access with high precision: it interprets user intent within a semantically structured context and retrieves relevant information accordingly. This transforms the database from a static, technical repository into a responsive, autonomous collaborator, one that maintains rigorous semantic integrity while delivering human-readable insights.
Conclusion
Agentic Text-to-SQL represents a fundamental shift from passive query generation to active problem-solving. Through multi-step reasoning, dynamic schema grounding, and iterative self-correction, it addresses many of the limitations inherent in traditional approaches. The introduction of role-based agents and execution feedback loops enables these systems to operate with greater robustness, transparency, and adaptability in complex data environments.
However, reasoning alone is not sufficient to fully bridge the semantic gap between human intent and physical data schemas. This is where ontology and ontology enforcement become critical. By embedding domain knowledge and enforcing semantic constraints, systems like PuppyGraph ensure that generated queries are not only executable but also logically correct. Together, agentic workflows and ontology-enforced architectures point toward a future where interacting with data becomes more intuitive, reliable, and aligned with real-world business understanding. Explore more with the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install