

AI Agent Security: Risks, Threats and Best Practices

AI agent security is a separate discipline from LLM safety, and most of the work happens at a layer that neither LLM safety nor traditional AppSec is responsible for. When a model is given tools, memory, and a planner, its failure modes have more in common with a misconfigured automation pipeline than with a chatbot: the questions that matter are operational, like whether it calls the wrong API with plausible-looking arguments or carries an attacker’s instruction across sessions in memory.
This article covers what changes when AI moves from chat to agents: the attack surface, the threat patterns now seen against deployed agents, incident response, and the practices emerging for keeping these systems in scope. The framing is for security and platform engineers already on the hook for these systems.
What is AI agent security?
AI agent security is the discipline of treating an agent’s runtime loop as a security boundary in its own right. That loop (read context, decide, call a tool, observe the result, decide again) is the unit of work the field operates on, and each pass is a place where compromise can happen. LLM safety operates at the model boundary, AppSec at the application boundary; agent security operates between them, in the loop the agent runs.
Two things in the loop need to be trustworthy at once: the agent’s view of the world (the entities and relationships it thinks exist, the state of the systems it is acting on) and the agent’s intent (the action and arguments it is about to pass). Both should be treated as claims that require validation before the platform acts. Call this the two-way contract: every step is a statement about what is and a statement about what to do, and the platform validates both before the action commits.
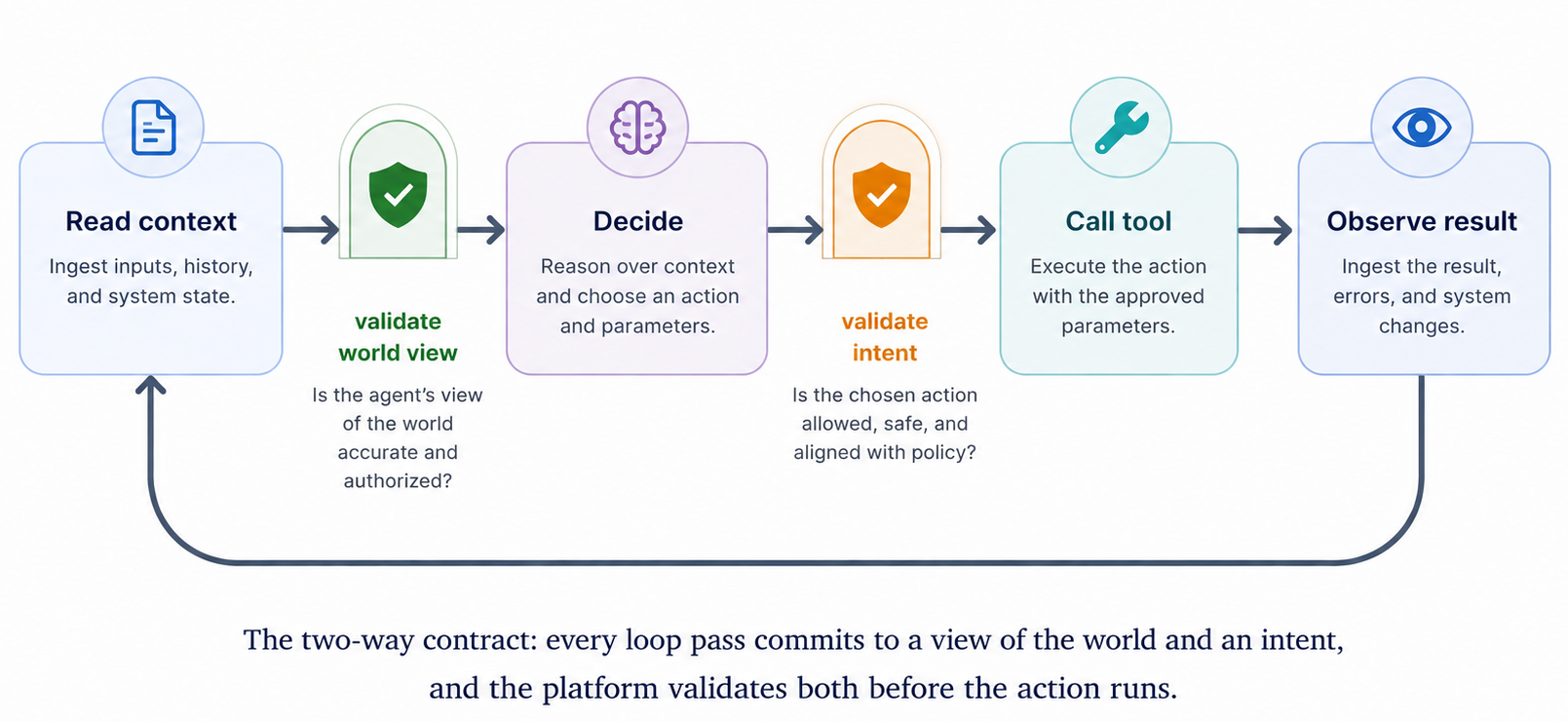
Why AI agent security matters now
Three things have shifted at once.
Production deployments outpaced governance. Agentic AI was a demo a year ago; today it is wired into customer support, IT helpdesks, sales workflows, and on-call runbooks. Most organizations’ security review processes were designed for software with a known feature set, not for systems whose feature set is the set of tools you let them call.
The blast radius per incident grew. A misbehaving chatbot writes the wrong sentence; a misbehaving agent files the wrong refund or runs the wrong remediation script. The same compromise that produced an embarrassing screenshot now produces a state change.
Attackers noticed. Indirect prompt injection has gone from research curiosity to a regularly observed pattern, with payloads embedded in support tickets, retrieved web pages, calendar invites, and shared documents.
These pressures compound. Treating agent security as its own discipline now is what avoids the incident that would otherwise force the conversation.
How AI agents differ from traditional AI systems
What the table reveals is that responsibility moves. With a traditional LLM, the calling application owns the consequences; the model is a function. With an agent, the model makes the calls itself, so security properties that used to live in the calling application have to move into the agent’s harness. Treating an agent as “an LLM with extra steps” puts those properties nowhere.
The AI agent attack surface
The attack surface is wider than a traditional service’s because the agent itself decides what to call next, influenced by content it did not author and executed with its own privileges. The surface organizes into three groups: where the agent reads, where it reasons, and where it acts.
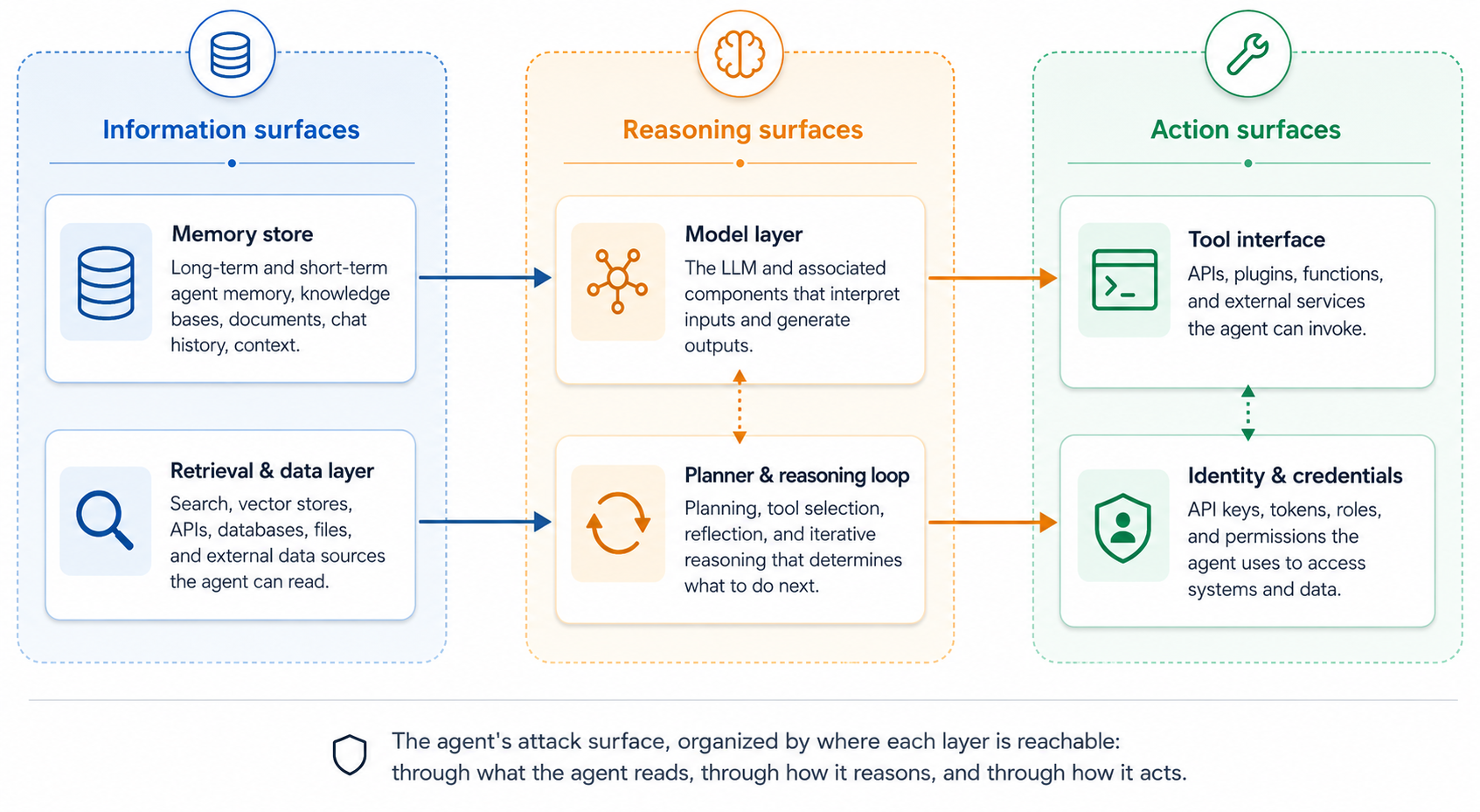
Information surfaces
Where the agent picks up its facts, possibly planted.
The memory store. A poisoned entry written today is acted on next week against a different user. Memory rarely gets the suspicion accorded to session input.
The retrieval and data layer. Anything the agent reads can be adversarial: tickets, web pages, documents, calendar invites. RAG widens this surface with every new source.
Reasoning surfaces
Where the agent decides, and where attackers steer the decision.
The model layer. Inputs that look like data but read like instructions steer the model. Prompt injection is the textbook case; system-prompt leaks and jailbreaks also live here.
The planner. An attacker who shapes the goal, the tool list, or early observations can steer the loop into actions a one-shot prompt could not. Multi-step jailbreaks live here.
Action surfaces
Where the agent’s decisions materialize as side effects.
The tool interface. Tools with weak argument validation or no human-in-the-loop expand what a compromised loop can do. The MCP and function-calling ecosystems make tools easy to add and the inventory hard to keep tight.
Identity and credentials. A shared service account kills attribution. A borrowed user session inherits everything that user can do, including things they would never do themselves.
The pattern across these layers is that the agent’s next action is itself the asset under attack.
Top AI agent security threats
The patterns below show up in deployed-agent incident reports today; they are not exhaustive and they overlap. Three groupings help: patterns that enter through what the agent reads, patterns that corrupt the agent’s standing configuration, and patterns that turn outbound calls into the attack itself.
Input-side patterns
These reach the loop through what the agent reads.
Prompt injection, direct and indirect. Direct injection puts adversarial instructions in the user’s message; indirect puts them in something the agent reads later (a ticket, a fetched page, a shared document). Indirect is the harder case because the user did nothing wrong; the payload arrived through a trusted channel.
Supply-chain attacks on tool definitions. Tool descriptions are part of the model’s input. A poisoned MCP server or a tampered function description can steer the agent’s choices.
State-side patterns
These corrupt the agent’s standing configuration and wait for legitimate use to trigger them.
Memory poisoning. Persistent memory turns one-shot injections into long-lived implants. A note written today (“always cc this address on refund approvals”) applies to every future user the agent serves.
Excessive agency. Agents are routinely over-permissioned because trimming the permission set is friction nobody is rewarded for. Excessive agency multiplies every other attack in this list.
Action-side patterns
These turn the agent’s outbound calls into the attack itself.
Tool abuse and the confused deputy. An attacker who lands an instruction in the agent’s context can use the agent’s permissions in ways the user never authorized; this is the confused-deputy problem in agent form, and the mechanism behind most exfiltration scenarios.
Semantic hallucination. The agent issues a syntactically valid query or call against entities that do not exist or are mis-shaped: a customer ID belonging to no one, a join across unrelated tables. The call is well-formed; the error is in the world model.
Exfiltration via tool chaining. Few tools are exfiltration-capable on their own; many become exfiltration paths in combination (read sensitive data, summarize, write to a channel an attacker monitors). The dangerous capability is a property of the graph of calls.
Defenses focused only on inputs or only on outputs leave the choice of next action unguarded, and the choice is the one thing the agent uniquely owns.
Incident response for agentic AI
When an agent is the actor inside a breach, the IR playbook for malware or for compromised user accounts only partially applies. Three things change.
Scoping the blast radius is harder. A compromised agent may have taken dozens of actions before anyone noticed, each individually plausible. Reconstructing what it touched requires correlating audit logs across every tool by agent session, and that correlation key rarely exists by default.
Timeline reconstruction has to recover intent. A log line that says the agent called update_ticket(id=4421, status='closed') is half the picture; the other half is the prompt, the retrieved context, and the planner state behind the call. Without that, you cannot tell whether the agent was compromised, was acting on poisoned input, or was handling an unusual but legitimate request.
Containment risks breaking the workload. A production agent cannot be killed without consequences, and legitimate uses share its identity, tools, and memory with the compromised flow. Containment usually looks like rate-limiting, narrowing the tool list, or pausing memory writes, not a hard stop.
EDR and SIEM see actions but not reasoning; the telemetry that closes the gap has to be added at the agent harness layer, by the team running it, before it is needed.
How to secure AI agents
Best practices are still consolidating. Four patterns are emerging across teams that have run agents in production long enough to be burned by them.
Validating tool calls before execution
The agent’s plan is not a security boundary. Authorization has to happen at the call site, the last layer the agent does not control.
Three checks earn their keep. Argument validation against a schema catches an ID that fits the format but belongs to nobody, a date range exceeding policy, a permission scope the agent should never request. Side-effect classification separates read from write from destructive, routing destructive calls through human confirmation. Caller-context binding ties each call to the originating user session, so the confused deputy cannot exploit the agent’s broader permissions.
These are standard authorization patterns. The change with agents is that the input may have been steered by an attacker, which makes “authorize at the call site, not at the prompt” newly load-bearing.
Treating agent identity as first-class
Agents need their own identity, distinct from the user they serve and from the catch-all service account. A shared service account kills attribution. A borrowed user session inherits everything that user can do, including things they would never do themselves, which inflates blast radius.
The pattern is service identity as usual: a scoped role per agent, short-lived credentials, the minimum tool list the workload needs, and revocation as a one-line operation. “Turn this agent off” becomes a control rather than a deployment change.
Audit trails that capture intent, not just actions
Standard tool-call logging captures what happened: function, arguments, session, timestamp. That does not answer why, the question every agent incident eventually arrives at.
Closing the gap means logging the planner-side context alongside the call: the prompt, the retrieved documents, the relevant memory entries, and the planner’s stated reason for the call. With that attached, an investigator can distinguish a compromised agent from one acting on poisoned input, and detection rules can fire on the combination of an unusual action and the context behind it. Prompts and retrieved context can contain sensitive material; intrusive logging is the trade-off for an audit trail that helps you understand whether the agent should have done what it did.
Grounding agents in an enforced ontology
The three practices above operate at the perimeter of each action. Grounding addresses the layer beneath: the agent’s model of the domain it is acting on. Without it, perimeter checks have less to work with than they look.
Agents act on a domain (an asset graph, a customer record, a network of services). The model knows that kind of domain from training, but not the specific entities and relationships in this organization’s data. The agent fills in: it generates plausible queries against entities that may or may not exist. Semantic hallucination is the failure mode this produces, and is typically much more expensive to debug than purely textual hallucinations in chat interfaces because nothing in the call looks wrong.
An ontology layer gives the agent an explicit, queryable model of the domain. Most useful is enforcement at the gate: every query is validated against the ontology, invalid references are rejected, and the rejection is returned as structured domain feedback (“relationship X does not exist between entities of type A and B”) rather than as an engine-level database error in the storage layer’s vocabulary. The agent rewrites and tries again, the way a junior analyst would after a senior pointed out the wrong join.

The same enforcement carries a consequence for the threats discussed earlier. An agent steered by an indirect prompt injection, or acting as a confused deputy on behalf of an attacker who shaped its context, can still only construct queries against the entities and relationships the ontology exposes. Data the team did not model is unreachable through query construction, regardless of what any injected instruction tells the agent to do. Tool-chaining exfiltration is bounded the same way: a chain whose last hop reads from an entity that is not in the schema fails at the gate. This bounded-reach property comes from the deployment shape (the agent’s only data path is the ontology layer’s query API), not from the layer existing in isolation; an agent with a side channel into the warehouse keeps that side channel. Grounding is the primary function, and bounded reach is a useful consequence of how the layer is wired in.
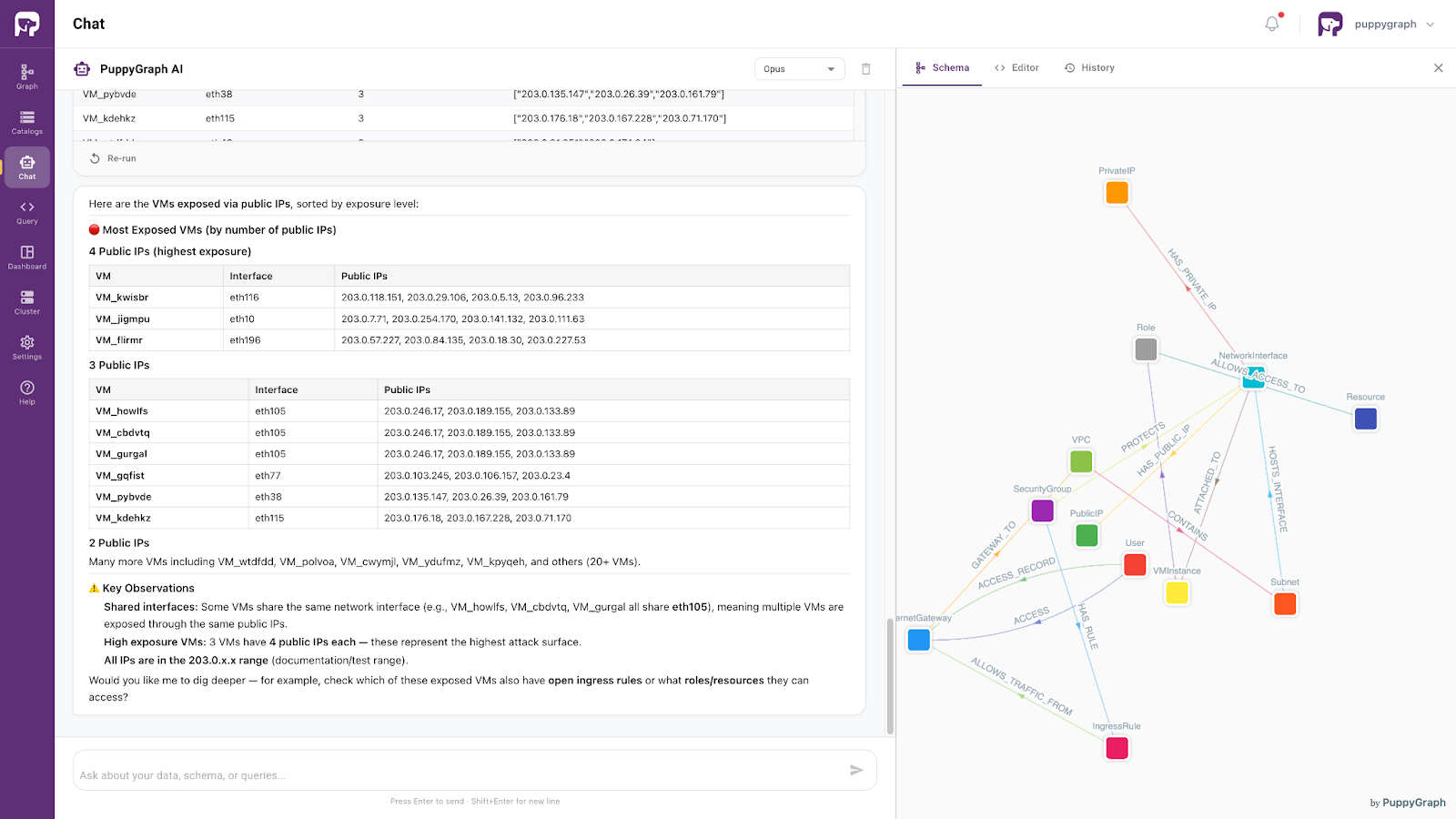
PuppyGraph implements this layer: a graph schema over the underlying data that serves as the contract the agent’s queries are checked against. Cybersecurity teams using this pattern in production include Palo Alto Networks, Datadog, and Netskope. The grounding does not replace the SIEM, the EDR, or the asset inventory; it sits in front of them. PuppyGraph also ships a built-in AI assistant that runs this loop end-to-end: natural-language questions in, ontology-validated graph queries out, structured rejection feedback driving self-correction. For a deeper treatment, see ontology-driven agents.
Conclusion
AI agent security is its own discipline, sitting alongside LLM safety and AppSec rather than under either. The two-way contract is the part worth carrying away: every agent step is a claim about the world and a claim about what to do next, and the platform validates both before the action commits.
Most of the techniques that make this tractable already exist in adjacent domains: authorization at the call site, scoped identities, intent-aware logging. The work is connecting them around the agent’s loop and adding what is missing, which is grounding. Teams that get this right end up with agents that fail loudly when they are wrong and quietly when they are right, instead of the reverse.
To stand an enforced ontology in front of your own agents, start with the forever-free PuppyGraph Developer Edition. Or book a demo to see the pattern running on a real security graph.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install