

AI Ontology: How It Powers AI Systems
.png)
Artificial intelligence has always depended not just on data, but on the meaning behind data. As AI systems grow more sophisticated, reasoning across documents, answering complex queries, orchestrating multi-step workflows, a quiet infrastructure makes much of it possible: ontology. At its core, an AI ontology is a formal, machine-readable representation of concepts and the relationships between them. It is not a new idea. Philosophers have debated the nature of existence and classification for centuries. But applied to AI, ontology becomes something entirely practical: the semantic backbone that allows machines to understand what things are, how they relate, and what rules govern them. In 2025 and beyond, as enterprises deploy large language models, knowledge graphs, and autonomous agents at scale, ontology has moved from academic curiosity to critical infrastructure. This article explores what AI ontology is, why it matters, and how it functions at the heart of modern intelligent systems.
What is AI Ontology
The word "ontology" comes from the Greek ontos (being) and logos (study), referring to the philosophical study of what exists. In computer science and AI, an ontology is a structured model that formally defines a domain of knowledge: the entities that exist within it, the categories those entities belong to, the properties they possess, and the relationships that connect them. Think of it as a shared conceptual map that both humans and machines can read and reason over.
An AI ontology typically answers three fundamental questions: What kinds of things exist in this domain? How are those things related to each other? And what rules or constraints govern those relationships? A medical ontology, for instance, might define that "Metformin" is a type of "Drug," that drugs are used to treat "Conditions," and that "Type 2 Diabetes" is a condition affecting the "Endocrine System." That web of definitions, encoded in formal languages like OWL (Web Ontology Language) or RDF (Resource Description Framework), is precisely what makes an AI system capable of inferring that a patient with elevated blood sugar might be a candidate for a particular medication class.
Unlike a simple dictionary or taxonomy, ontologies encode logical relationships and support inference. A taxonomy tells you that a poodle is a dog. An ontology tells you that a poodle is a dog, that dogs are mammals, that mammals are warm-blooded, and that warm-blooded animals regulate their own body temperature, allowing an AI to derive conclusions about poodles that were never explicitly stated. This inferential power is what separates ontologies from flat data schemas or keyword lists.
Ontologies also differ from knowledge bases, though the two are closely related. A knowledge base stores facts; an ontology defines the schema and logic that gives those facts meaning. Together, they form the foundation of what researchers call the Semantic Web, a vision, first articulated by Tim Berners-Lee, of a web where data is not just linked but understood.
Why Ontology Has Become Essential for AI Systems
For decades, AI researchers built systems that were powerful but brittle, including expert systems that knew a great deal within a narrow domain but collapsed the moment a question fell outside their explicit programming. The fundamental problem was a lack of shared, structured meaning. Data existed in silos. Systems could process syntax but not semantics. And when two databases described the same concept using different words, integration required painstaking manual mapping. Ontology emerged as one of the core solutions to this problem.
The rise of large language models (LLMs) has not made ontology obsolete. It has made it more important. LLMs are remarkably fluent, but they hallucinate, they lack provenance, and they struggle with precise logical reasoning over complex domain knowledge. Grounding LLM outputs in ontologies dramatically improves reliability. When a language model answering a legal question can verify its reasoning against a formal legal ontology by checking that a cited statute actually applies to the described jurisdiction and case type, the output becomes trustworthy rather than merely plausible.
Several forces are converging to elevate ontology's role. Enterprise data complexity has exploded. Regulatory frameworks demand traceable, explainable AI decisions. Multi-system integration requires a common vocabulary that software can process unambiguously. And the deployment of autonomous AI agents, systems that plan, act, and coordinate across tools, requires that each agent share a consistent understanding of the world it is operating in. None of these requirements can be met with raw data alone. They require meaning, structure, and logic: the defining features of ontology.
How Ontologies Power AI and Data Intelligence
Ontologies do practical work across a surprisingly wide range of AI applications. To understand their power, it helps to trace how they flow through a modern AI pipeline.
Semantic search and retrieval is perhaps the most immediate application. Traditional keyword search matches strings; semantic search matches meaning. When an ontology defines that "myocardial infarction," "heart attack," and "cardiac event" refer to the same underlying concept, a search for any one of these terms can retrieve documents indexed under any of the others. Enterprise search platforms, document intelligence tools, and retrieval-augmented generation (RAG) systems all rely on this kind of semantic equivalence to return relevant results even when vocabulary varies.
Knowledge graph construction is another major application. Knowledge graphs like those powering Google Search, LinkedIn's professional graph, or biomedical research platforms are built on ontological foundations. The ontology defines what types of nodes and edges are meaningful, what kinds of entities exist and what kinds of relationships can connect them, while the knowledge graph populates those structures with real data. The result is a navigable, queryable map of a domain that AI systems can traverse to answer complex, multi-hop questions.
Below is a simplified diagram illustrating how an ontology anchors a knowledge graph in an enterprise AI system:
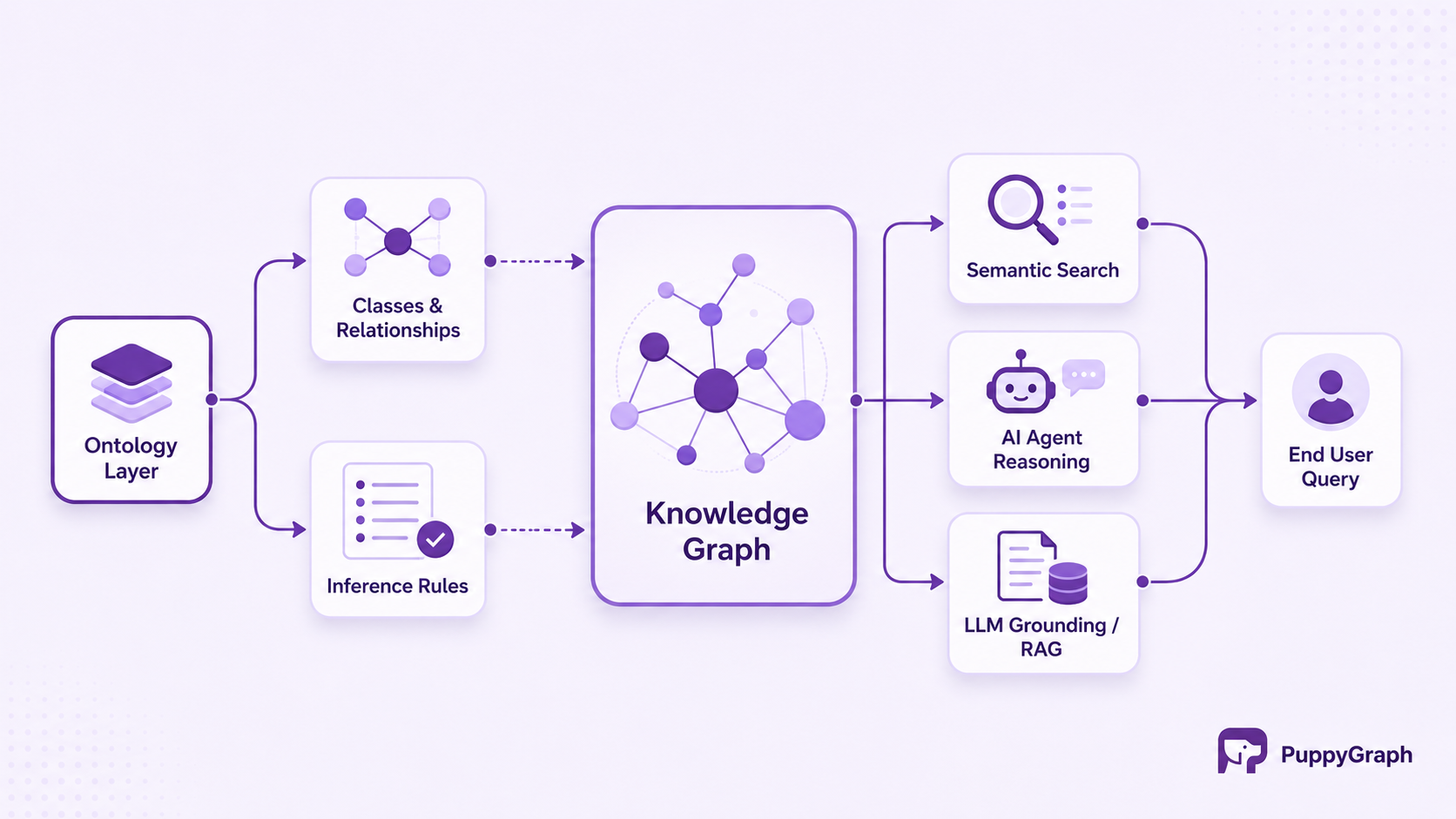
Natural language understanding (NLU) is a third domain where ontologies contribute critically. When an AI system processes a sentence like "The patient's creatinine is elevated," the words themselves carry little actionable meaning without domain context. An ontology that defines creatinine as a biomarker, elevated creatinine as a potential indicator of renal dysfunction, and renal dysfunction as a condition linked to specific treatment protocols gives the AI system the scaffolding it needs to move from text to actionable inference. This is the difference between language understanding and domain understanding.
Finally, ontologies are foundational to data integration and interoperability. When two enterprise systems use different schemas, such as one calling a field "customer_id" and another "client_number", an ontology can declare these as semantically equivalent, enabling automatic data mapping without brittle, hand-coded ETL pipelines. This is especially valuable in highly regulated sectors like healthcare, finance, and government, where data must be combined from dozens of sources while preserving precise semantic meaning.
The Building Blocks of an AI Ontology
Understanding what an ontology does requires understanding what it is made of. Despite variations in implementation, most AI ontologies share a common set of structural components.
Classes (also called concepts or types) are the categories that an ontology uses to organize entities. In a financial ontology, classes might include Asset, Liability, Transaction, and Party. Classes can be arranged in hierarchies, where child classes inherit the properties of parent classes. A BankAccount is a subclass of Asset; a SavingsAccount is a subclass of BankAccount. This inheritance structure allows AI systems to reason at multiple levels of abstraction.
Properties define the attributes that instances of a class can have, and the relationships that link instances of different classes. Object properties connect two classes. For example, a Transaction "involves" a Party. Datatype properties connect a class to a literal value. For example, a Transaction "hasAmount" expressed as a decimal number. Together, properties give an ontology its expressive depth, moving beyond simple categorization into rich relational description.
Individuals (also called instances) are specific real-world entities that belong to classes. The transaction "TX-20250401-0042" is an individual of the class Transaction. Individuals are what populate the knowledge graph that sits atop the ontology.
Axioms and constraints are the logical rules that govern valid configurations. An axiom might state that every Transaction must involve at least one Party, or that a Party cannot be both a Buyer and a Seller in the same Transaction. These constraints allow ontology reasoners to detect inconsistencies, infer implicit facts, and validate data quality, which are capabilities that are essential in enterprise environments where data errors have real consequences.
Most enterprise-grade ontologies are expressed using the W3C standard OWL 2, which provides a rich logical vocabulary and is supported by powerful reasoning engines like HermiT and Pellet. SPARQL, the standard query language for RDF data, allows AI systems to retrieve information from ontology-backed knowledge graphs with the same precision that SQL brings to relational databases.
Do AI Agents Need Ontology?
The question deserves a direct answer: yes, and increasingly so. AI agents are autonomous software systems that pursue goals by perceiving their environment, selecting actions, and executing those actions, often across multiple tools, APIs, and data sources. The more capable and autonomous an agent becomes, the more critical it is that the agent operates with a shared, structured understanding of the world.
Consider a simple agent tasked with processing a purchase order. It must understand what a "purchase order" is, that it contains "line items," that each line item references a "product SKU," that a SKU maps to inventory records, and that completing the order requires updating both financial and logistics systems. Without a shared ontological model, the agent must either hard-code these relationships, which makes the system brittle, or rely entirely on an LLM's implicit, potentially inconsistent world model. Neither approach scales reliably to complex enterprise environments.
The challenge becomes more acute in multi-agent systems, where different agents are built by different teams, trained on different data, and deployed in different contexts. For these agents to collaborate without misunderstanding each other, they need a shared vocabulary, which is precisely what a domain ontology provides. An agent reasoning about "shipment status" and an agent reasoning about "delivery state" cannot coordinate effectively unless an ontology declares these concepts equivalent or defines one in terms of the other.
Why Intelligent Agents Depend on Ontologies
Intelligent agents capable of planning, learning, and adapting face a particularly acute need for ontological grounding. Three capabilities explain why.
Goal decomposition and task planning require that agents understand the structure of a domain well enough to break a high-level goal into achievable sub-tasks. An agent asked to "onboard a new supplier" needs to know that onboarding involves identity verification, contract creation, banking detail collection, and system provisioning, and that these steps must occur in a specific order. An ontology that models the supplier onboarding process provides exactly this structural knowledge, without requiring the agent to rediscover it through trial and error.
Tool selection and API routing depend on the agent knowing what each available tool does and what kinds of inputs it expects. Ontologies can describe tool capabilities in a machine-readable way, allowing an agent to reason about which tool is appropriate for a given sub-task. A growing number of AI frameworks, including those inspired by the emerging Model Context Protocol (MCP), use semantic descriptions of tools and services that are, at their core, lightweight ontological definitions.
Explainability and auditability are non-negotiable in regulated industries. When an AI agent makes a decision, regulators and auditors need to understand why. An agent whose reasoning is grounded in a formal ontology can trace each inference step back to explicit definitions and rules, producing explanations that are both human-readable and logically defensible. This is a qualitative advantage over agents that reason purely through opaque neural network activations.
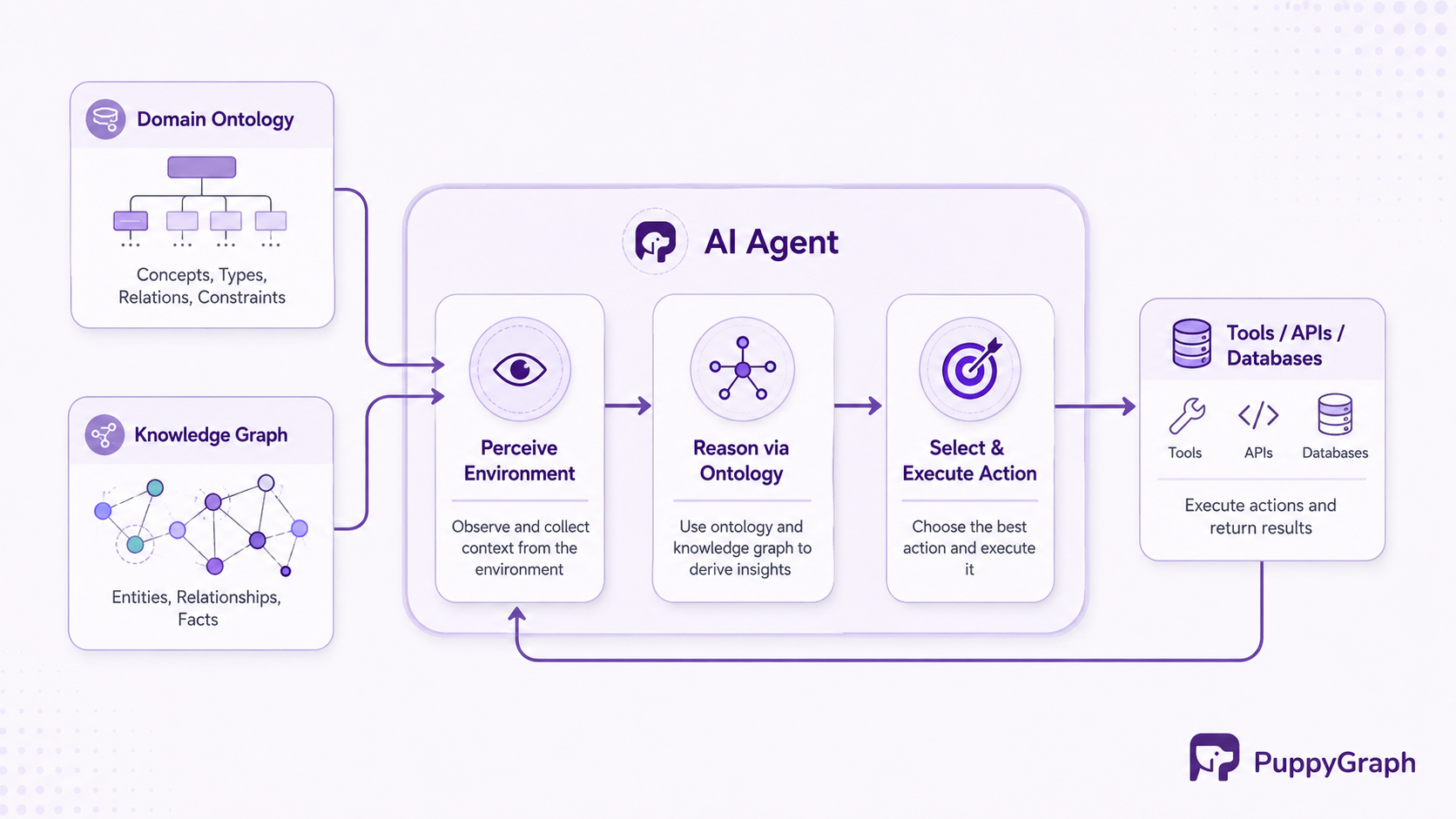
The diagram above illustrates how an ontology sits at the center of an intelligent agent's reasoning loop, connecting perception to action through structured knowledge rather than raw pattern matching.
Implementing Ontology in Enterprise AI Environments
Deploying ontology in a real enterprise environment is both a technical and an organizational challenge. The technical side involves selecting the right tools, building the right models, and integrating them into existing data pipelines. The organizational side involves aligning stakeholders, establishing governance processes, and sustaining the ontology over time.
Starting with scope is the most important early decision. Trying to build a universal enterprise ontology in a single effort is a recipe for failure. Successful implementations typically start with a specific, high-value domain, such as customer identity, product catalog, clinical terminology, and expand iteratively. Starting narrow allows teams to validate the ontology against real use cases, gather feedback from domain experts, and build internal confidence before scaling.
Tooling choices shape the implementation significantly. Graph databases such as Amazon Neptune, Neo4j, and Stardog provide the storage and query infrastructure. Ontology editors like Protégé offer visual environments for building and maintaining OWL ontologies. Reasoners like HermiT or ELK perform automated inference. And increasingly, purpose-built knowledge graph platforms combine these layers into integrated stacks that are easier to deploy and maintain.
Domain expert involvement is non-negotiable. An ontology built by engineers alone will inevitably get the domain wrong in ways that undermine its value. The concepts, relationships, and constraints that matter in a domain are held by the people who work in it, including clinicians, lawyers, financial analysts, logistics specialists. Effective ontology development treats these experts as co-authors, using structured elicitation workshops and iterative review cycles to capture their knowledge accurately.
Governance and versioning determine whether an ontology remains useful over time. Ontologies reflect the world, and the world changes: regulations evolve, product lines expand, organizational structures shift. A governance process that assigns ownership of ontology modules, defines change management procedures, and tracks version history ensures that the ontology stays accurate without becoming a bureaucratic burden. Some organizations establish dedicated knowledge engineering teams; others embed ontology maintenance into domain teams' regular workflows.
Finally, integration with LLM pipelines is a rapidly evolving frontier. Retrieval-augmented generation systems that ground LLM responses in knowledge graph facts while following ontological rules are showing significant improvements in factual accuracy and auditability compared to ungrounded LLMs. Frameworks that allow agents to query SPARQL endpoints, traverse knowledge graphs, or validate outputs against ontological constraints are maturing quickly. For enterprises serious about deploying trustworthy AI, this integration layer is becoming a standard architectural component rather than an experimental feature.
Beyond Database Choice: Adding Semantics to Existing SQL Systems
Much of the discussion around ontology and knowledge graphs assumes that organizations are building greenfield systems, including selecting graph databases, designing RDF schemas, and constructing semantic layers from scratch. The reality in most enterprises is quite different. The most business-critical data already lives in relational databases: PostgreSQL instances running transactional systems, Oracle databases supporting financial records, MySQL clusters powering e-commerce platforms. Migrating this data wholesale into a new storage paradigm is rarely practical, nor is it necessary. The more pressing challenge is making existing SQL environments semantically accessible to analysts, applications, and increasingly AI systems without disrupting the infrastructure that runs the business.
This is where a semantic layer becomes essential, not as an alternative to ontology, but as the practical bridge that extends its benefits into the SQL world.
The Role of a Semantic Layer
A semantic layer sits above existing SQL databases and exposes business concepts directly, such as Customer, Order, Product, Transaction, rather than the tables, foreign keys, and join paths through which those concepts happen to be stored. Instead of forcing applications or AI systems to navigate raw schemas, the semantic layer provides a higher-level logical model aligned with business meaning. Developers and AI agents can work with data naturally, querying "orders placed by high-value customers in the last quarter" without needing to know which tables hold that information or how they relate. The underlying SQL databases remain unchanged; the semantic layer simply gives them a more meaningful face.
Ontology and Ontology Enforcement
At the core of many semantic layers is an ontology: a formal definition of entities, their relationships, and the rules that govern valid interactions across the data environment. This ontology defines what exists: a Customer may place an Order, an Order may contain a Product, and a Supplier may provide that Product. Crucially, it also defines what cannot exist: an Order without a valid Customer reference, or a Product linked to a Supplier that is not registered in the system.
Ontology enforcement ensures that every operation, whether issued by a human analyst, an application, or an AI agent, is validated against this semantic model before it touches the underlying data. Operations that are syntactically correct but logically invalid are caught at the semantic layer rather than silently propagating errors into storage. For AI systems in particular, this guardrail is significant. Large language models and autonomous agents can generate queries that are structurally well-formed yet semantically wrong by connecting entities in ways that make no business sense. Ontology enforcement transforms these silent failures into structured, interpretable feedback, explaining not just that an operation failed, but why it violated the rules of the domain. Over time, this feedback loop supports agent self-correction and can even serve as a reward signal for reinforcement learning.
Why It Matters: From Semantic Fog to Agentic Clarity
Without a semantic layer, working directly with SQL shifts complexity into application code. Joins accumulate, naming conventions diverge across teams, and the gap between what the schema says and what the business means widens with every new table added. For human developers, this creates maintenance debt. For AI systems, it creates something worse: semantic fog. An agent navigating an undifferentiated schema of hundreds of tables has no reliable way to distinguish which relationships are meaningful from which are merely artifacts of storage design. It may successfully execute a query while constructing a relationship that has no counterpart in the real world.
A semantic layer enforced by a domain ontology resolves this fog. The agent no longer needs to reason about storage topology; it reasons about business concepts. The ontology defines which relationships are valid, the semantic layer enforces those definitions at query time, and the AI system operates in a structured environment where its actions are constrained to what is logically meaningful. This shifts the agent's operating context from an ambiguous data maze to a well-governed semantic environment where mistakes are caught, explained, and correctable.
Data Access with AI Assistants
Moving beyond architectural considerations, tools like PuppyGraph provide a graph-based way to access and query existing SQL data as connected knowledge, without requiring organizations to migrate everything into a native graph database. This enables developers and AI systems to explore existing SQL data through graph-style reasoning and relationship-aware retrieval.
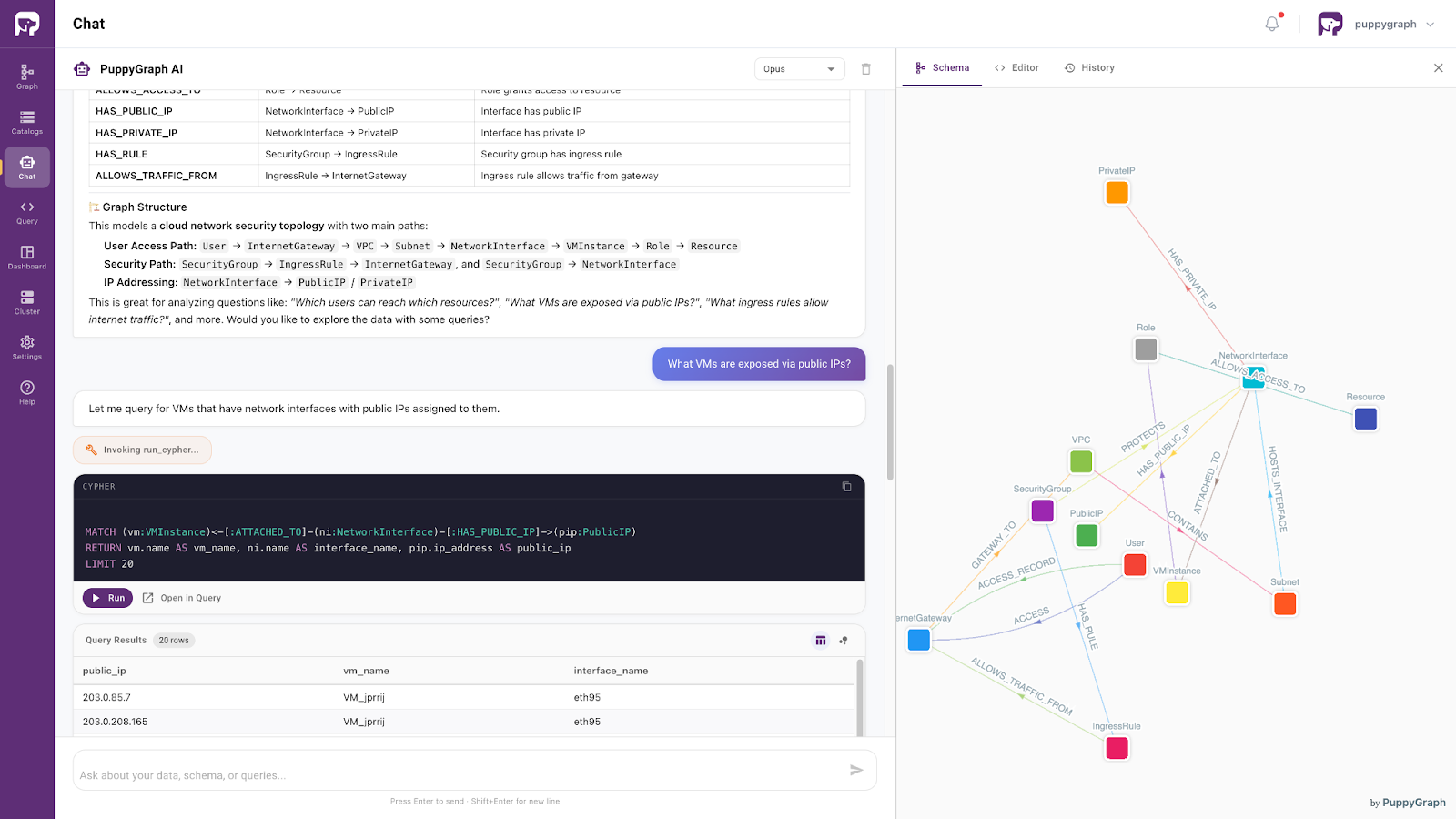
Powered by the same ontology-enforced foundation, this approach supports precise, context-aware access to enterprise SQL data. It allows AI systems to interpret user intent within a well-defined semantic framework and retrieve relevant information accordingly. As a result, enterprise data evolves from a passive storage layer into an active semantic layer that preserves consistency while enabling more reliable search, analytics, and next-generation AI agents.
Conclusion
Ontology gives AI systems something raw data and language models alone cannot provide: structured meaning. By defining entities, relationships, rules, and constraints, ontologies help AI systems reason more precisely, integrate data more reliably, and explain their decisions more transparently. As enterprises adopt LLMs, knowledge graphs, and autonomous agents, ontology is becoming essential infrastructure for trustworthy and scalable AI.
The next step is making this semantic foundation practical for the data systems enterprises already use. A graph-based semantic layer can expose existing SQL data as connected, ontology-enforced knowledge without requiring migration to a native graph database. Explore the forever-free PuppyGraph Developer Edition, or book a demo to see how PuppyGraph helps bring semantic clarity, graph reasoning, and AI-ready data access to your existing SQL systems.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install