

Apache Avro vs Parquet: Key Differences & Performance
Choosing the right file format affects performance, storage costs, and data pipeline efficiency. Apache Avro and Apache Parquet are two popular formats in big data systems, but they serve different purposes and work best in different scenarios.
Both of these big data file formats are widely used. Sometimes it can be confusing to decide which is best for a particular use case or to understand the differences in performance and storage. Making the right choice about which format is most suitable is a critical decision for working with this data, and it becomes much easier when you understand the differences between the two formats. This post compares Apache Avro and Parquet in terms of architecture, performance characteristics, and use cases. You'll learn which format suits your data workloads and when to use each one. Let's begin by looking at both formats at a high-level.
What Is Apache Avro?

Apache Avro is a row-oriented data serialization framework developed within the Apache Hadoop project. Released in 2009, Avro provides a compact, fast, language-neutral data format that supports rich data structures and schema evolution.
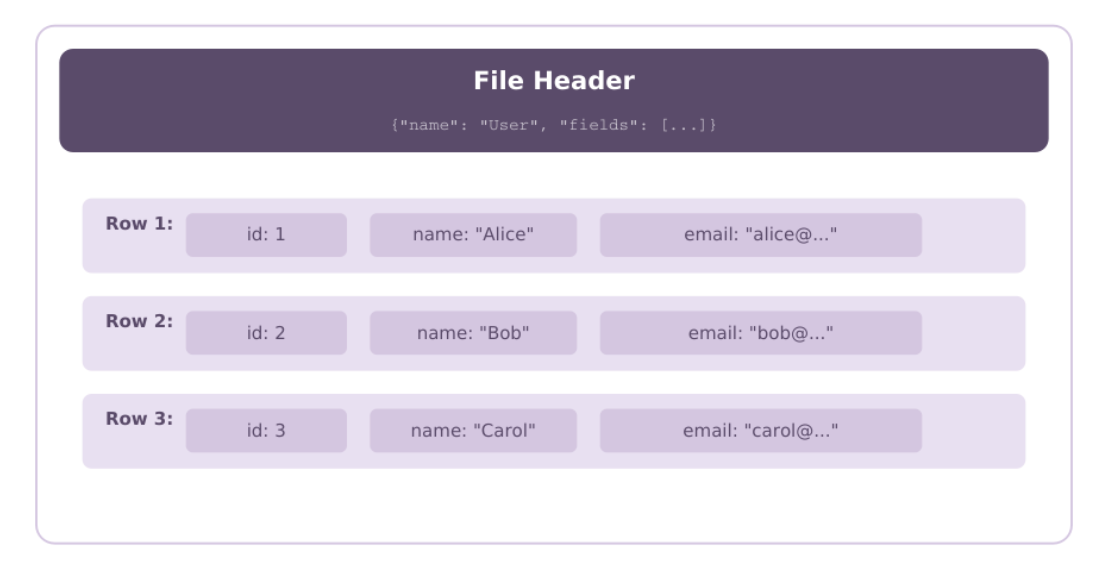
Avro stores data in a binary format with its schema defined using JSON. This schema-first approach works well for scenarios where data structures evolve over time. The schema is stored in the file header alongside the data, so readers can understand the structure even if it was written with a different schema version.
Key characteristics of Apache Avro:
- Row-oriented storage: Avro stores data row-by-row, meaning all fields for a single record are stored together. This makes it efficient for operations that need to access complete records.
- Schema evolution support: Avro provides great schema evolution capabilities, allowing you to add, remove, or modify fields without breaking existing data readers. This works through writer and reader schemas that can differ.
- Compact binary format: Data is stored in a space-efficient binary format, reducing storage requirements and network transfer costs.
- Language neutrality: Avro supports multiple programming languages, including Java, Python, C, C++, C#, and more.
- Splittable: Avro files can be split and processed in parallel, making them compatible with distributed processing frameworks like Apache Spark and Hadoop MapReduce.
The Avro schema serves as a contract between data producers and consumers. When data is written, the writer schema is embedded in the Avro Object Container File. When data is read, the reader can use this schema to deserialize the data, or it can use its own schema, and Avro will handle the translation.
Avro was created to solve data exchange between systems and provide a format that could evolve over time without breaking existing workflows.
What Is Apache Parquet?

Apache Parquet is a columnar storage file format jointly developed by Twitter and Cloudera in 2013. Unlike Avro's row-oriented approach, Parquet organizes data by columns rather than rows, which changes how data is stored and retrieved.
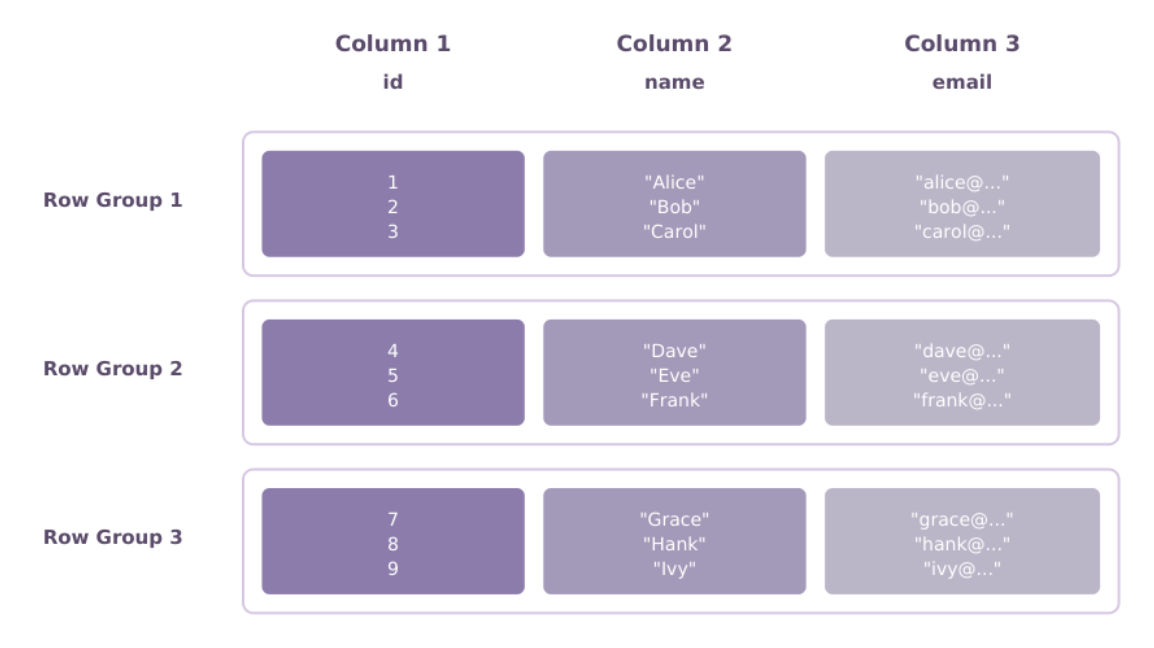
In Parquet, all values for a single column are stored together (since it uses a columnar storage format). This provides advantages for analytical queries that only need to access a subset of columns. The columnar layout also achieves better compression ratios by grouping similar data types, enabling compression algorithms to operate more effectively.
Key characteristics of Apache Parquet:
- Columnar storage: Data is organized by columns rather than rows, optimizing for queries that only need to read specific columns rather than entire records.
- Advanced compression: Parquet supports multiple compression codecs, including Snappy, GZIP, LZ4, and ZSTD. The columnar layout typically achieves better compression ratios than row-oriented formats.
- Predicate pushdown: Parquet files contain metadata that allows query engines to skip reading entire chunks of data that don't match filter conditions, improving query performance.
- Nested data support: Despite being columnar, Parquet efficiently handles complex nested data structures using the Dremel encoding scheme developed at Google.
- Optimized for analytics: The format is designed for OLAP (Online Analytical Processing) workloads, where queries scan large amounts of data while accessing only a few columns.
- Wide ecosystem support: Parquet is natively supported by most data processing engines, including Apache Spark, Presto, Hive, Impala, and Drill.
Parquet files consist of row groups, each containing column chunks for each column. Within these column chunks, data is divided into pages. This hierarchical structure enables efficient parallel processing and selective data scanning.
The format includes extensive metadata, including column statistics (min/max values, null counts), which let query engines make intelligent decisions about which parts of the file to read. This metadata-driven optimization is one of Parquet's most powerful features for analytical workloads.
Differences Between Apache Avro and Parquet
To help you understand the key distinctions between these two formats, here's a comprehensive comparison table:
The fundamental difference between Avro and Parquet lies in how they organize data. Avro's row-oriented structure works well for scenarios that require complete records, such as streaming applications or serializing data for transmission between systems. Parquet's columnar structure excels when you need to perform analytics on large datasets where queries access only a subset of columns.
Schema evolution is another critical distinction. Avro was designed from the ground up to handle evolving schemas. You can add new fields, remove old ones, or change field types, and Avro will handle the translation between different schema versions. Parquet supports schema evolution to some degree, but requires more careful planning because its columnar structure makes certain types of schema changes more complex.
Compression characteristics differ between the formats. Both support compression, but Parquet typically achieves better compression ratios because similar data types are stored together. This allows compression algorithms to find more patterns and achieve higher compression. Avro's compression is effective and the format is generally faster to write because it doesn't need to reorganize data into columns.
When to Use Apache Avro?
Apache Avro works best in specific scenarios where its row-oriented design and schema evolution capabilities provide clear advantages:
Data Serialization and Exchange
Avro excels at serializing data for exchange between different systems or services. Its compact binary format reduces network overhead, and the embedded schema means receivers can always understand the data structure. This makes it a good fit for microservices architectures where services need to communicate efficiently.
Streaming and Real-Time Processing
For streaming data pipelines, particularly those using Apache Kafka, Avro is often the format of choice. Its row-oriented structure means records can be written and read sequentially with minimal overhead. Many streaming platforms have native Avro support, and the format integrates with schema registries like Confluent Schema Registry that manage schema versions across distributed systems.
Write-Heavy Workloads
When your workload involves frequent writes and less frequent reads, Avro performs better than Parquet. Writing to Avro is faster because the format doesn't need to reorganize data into columns. If you're collecting logs, events, or sensor data that will be written continuously, Avro provides better write throughput.
Schema Evolution Requirements
If your data structures are likely to change over time, Avro's schema evolution support is valuable. You can add new fields, mark fields as optional, or remove fields that are no longer needed, all while maintaining compatibility with existing data and applications. This flexibility is useful for data pipelines that need to adapt to changing business requirements.
Data Migration and Backup
Avro works well for scenarios where you need to export data from one system and import it into another. The self-describing nature of Avro files means they carry all the information needed to understand and process the data, making migrations and backups more reliable.
Small to Medium Dataset Sizes
For datasets that don't require columnar storage optimization, Avro's simpler structure can be more practical. The overhead of maintaining column statistics and metadata in Parquet may not be justified for smaller datasets, as queries can quickly scan the entire file.
When to Use Apache Parquet?
Apache Parquet is the preferred file format when you need to optimize for analytical queries and read-heavy workloads:
Analytical and BI Workloads
Parquet was designed for analytical queries, and it performs best there. If you're running business intelligence tools, generating reports, or performing data analysis where queries aggregate data across many rows but only access a few columns, Parquet provides significant performance improvements. The ability to read only the columns needed for a query can reduce I/O by orders of magnitude.
Data Lake and Data Warehouse Storage
In data lake architectures, Parquet has become the standard for storing analytical data. Its combination of compression, columnar storage, and rich metadata makes it a good fit for storing large volumes of data that will be queried by various analytical tools. Services like AWS Athena, Google BigQuery, and Databricks all have optimized support for Parquet.
Large Dataset Analytics
When working with petabyte-scale datasets, Parquet's compression and selective scanning capabilities become critical. The format's ability to skip unnecessary data through predicate pushdown and column pruning enables even large datasets to be queried efficiently.
Cost Optimization
Parquet's compression ratios translate to storage cost savings. In cloud environments where storage costs can be high, using Parquet instead of less efficient formats can reduce your cloud bill. Reduced I/O also means lower compute costs for query processing.
Machine Learning Feature Storage
For machine learning applications, training datasets are often read many times but written once. Parquet works well for this access pattern. The columnar format aligns with how machine learning frameworks access data, where features (columns) are loaded into memory for training algorithms.
Long-Term Archival
When data needs to be retained for years for compliance or historical analysis, Parquet's compression and self-contained nature (with metadata embedded) make it a good choice for long-term storage. The format is stable, well-documented, and widely supported.
Ad-Hoc Query Workloads
In environments where users frequently run exploratory queries with unpredictable access patterns, Parquet's columnar structure provides consistent performance. Users can efficiently query any combination of columns without pre-optimizing the data layout for specific query patterns.
Which Is Best? (Avro vs Parquet)
The question of which format is "best" doesn't have a simple answer because Avro and Parquet are optimized for different use cases. Rather than competing directly, they complement each other in data architecture.
Choose Avro when:
- Your primary need is data serialization and exchange between systems
- You're building streaming data pipelines
- Schema evolution is a critical requirement
- You have write-heavy workloads
- You need to read entire records most of the time
- You're working in a transactional or operational context
Choose Parquet when:
- Your workload is dominated by analytical queries
- You need to optimize storage costs through compression
- Queries access only a subset of columns
- You're building a data lake or data warehouse
- Read performance is more critical than write performance
- You need to support ad-hoc analytical queries
In many architectures, both formats coexist and serve different purposes. A common pattern is to use Avro for the streaming/speed layer (for real-time data ingestion) and Parquet for the batch/serving layer (optimized for analytical queries).
For example, you might use Avro in your Kafka streams to capture events in real time, then periodically convert and store the data in Parquet format in your data lake for analytical queries. This approach leverages the strengths of both formats.
The decision depends on your requirements:
- If you're building operational systems with real-time data processing, lean toward Avro
- If you're building analytical systems with large-scale reporting needs, lean toward Parquet
- If you need both capabilities, consider using both formats at different stages of your data pipeline
Modern data processing frameworks like Apache Spark support both formats efficiently, so you're not locked into a single choice. You can experiment with both formats and measure the performance characteristics for your specific workload before committing to one over the other.
Working with PuppyGraph
PuppyGraph fits naturally into modern lakehouse architectures as a graph query engine that runs directly on your existing tables. It connects to Apache Iceberg, Delta Lake, Apache Hudi, and Hive-managed tables, then queries the underlying data in place, without introducing a new storage layer or duplicating data.
Because lakehouse tables are commonly backed by Parquet or Avro, PuppyGraph works with the strengths of each format. With Parquet, it can take advantage of columnar layouts for selective reads and filter pushdown. With Avro, it fits well with record-oriented datasets and evolving schemas, which are common in event and streaming pipelines. Either way, teams can keep using SQL engines for tabular analysis and rely on PuppyGraph for relationship-heavy exploration, all on top of a single lakehouse foundation.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.




Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Apache Avro and Apache Parquet represent two different approaches to data storage, each optimized for distinct workloads. Avro’s row-oriented design and schema evolution make it a strong fit for streaming and operational pipelines. Parquet’s columnar layout and compression make it a better choice for analytical queries and data warehousing.
In many architectures, the best approach is using both: Avro where flexibility and write throughput matter most, and Parquet where scan performance and storage efficiency matter most. Regardless of which format you choose, PuppyGraph can query lakehouse tables backed by Parquet or Avro in place, so you can run graph analytics without moving data.
Want to try it? Download PuppyGraph’s forever-free Developer Edition, or book a demo with the team to walk through your use case.

Matt is a developer at heart with a passion for data, software architecture, and writing technical content. In the past, Matt worked at some of the largest finance and insurance companies in Canada before pivoting to working for fast-growing startups.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install