

Apache Iceberg vs Parquet: Know The Differences
As organizations scale analytics, machine learning, and real-time reporting on top of data lakes, two technologies frequently appear in architectural discussions: Apache Iceberg and Apache Parquet. Although they are often mentioned together, they solve fundamentally different problems and operate at different layers of the data stack. Confusing them can lead to suboptimal system design and unexpected operational complexity.
Parquet is a columnar file format optimized for efficient storage and analytical query performance. Iceberg, on the other hand, is a table format that manages collections of data files, often Parquet files, while adding transactional guarantees, schema evolution, and consistent reads and writes. Understanding the distinction between “file format” and “table format” is essential for choosing the right technology.
This article provides a deep, practical comparison of Apache Iceberg and Parquet. We explore their architectures, key features, performance characteristics, and real-world use cases. By the end, you will clearly understand when to use Parquet alone, when Iceberg becomes essential, and how emerging alternatives like PuppyGraph fit into the broader analytics ecosystem.
What Is Apache Iceberg

Apache Iceberg is an open table format designed for large-scale analytic datasets stored in data lakes. It was originally developed at Netflix to address the limitations of earlier Hive-based table formats, particularly around reliability, schema evolution, and partition management. Iceberg defines how data files, metadata, and snapshots are organized so that multiple engines can safely read and write the same tables concurrently.
Unlike traditional table abstractions that rely heavily on external metastore conventions, Iceberg embeds rich metadata directly in the table structure. This design allows query engines such as Spark, Flink, Trino, Presto, and Hive to interpret tables consistently. Iceberg tables typically store data in Parquet, ORC, or Avro files, but the table format itself is independent of the underlying file format.
At its core, Iceberg introduces atomic commits, snapshot-based isolation, and declarative partitioning. These capabilities make data lakes behave more like modern data warehouses while preserving the flexibility and cost advantages of object storage systems like Amazon S3 or Azure Data Lake Storage.
How Apache Iceberg Works

Apache Iceberg organizes large analytic datasets by separating data storage from table metadata management, which enables reliable, consistent, and scalable operations in data lakes. The architecture consists of three main layers: the Iceberg catalog, the metadata layer, and the data layer.
At the top, the Iceberg catalog stores pointers to the current table state. For example, db1.table1 maintains a reference to the latest metadata file, which represents the table’s current snapshot. This design ensures that readers and writers can always access a consistent view of the table.
The metadata layer is the core of Iceberg’s transactional capabilities. Each table maintains metadata files that track the structure, schema, and snapshots of the table over time. A snapshot captures the table’s state at a particular moment and points to one or more manifest lists. Manifest lists aggregate references to manifest files, which in turn track individual data files (commonly Parquet, ORC, or Avro). This hierarchical organization enables Iceberg to provide atomic commits and snapshot-based isolation, ensuring that readers never encounter partial writes and writers can safely update the table concurrently.
Each manifest file contains metadata about a group of data files, including row counts, partition information, and column statistics. This metadata allows query engines to efficiently prune irrelevant files and partitions without scanning unnecessary data. The separation between metadata files, manifest lists, and data files also supports time travel, users can query historical snapshots of the table, and schema evolution, such as adding, renaming, or reordering columns without rewriting existing data.
Finally, the data layer stores the actual data files. Iceberg abstracts the physical layout of these files, enabling hidden and evolvable partitioning. Queries can efficiently access relevant subsets of data while the system automatically adapts to partition changes and schema updates.
By decoupling metadata management from raw storage, Iceberg allows multiple engines, such as Spark, Flink, Trino, and Hive, to safely read and write tables concurrently. The snapshot-based approach, combined with metadata-rich manifests, ensures reliable analytics at scale while maintaining the flexibility and cost advantages of object storage systems like Amazon S3 or Azure Data Lake Storage.
Key Features of Apache Iceberg
Apache Iceberg’s most significant feature is snapshot-based table management, which enables atomic reads and writes. Each change to a table produces a new snapshot, allowing readers to see a consistent view of the data while writers operate concurrently. This eliminates common issues such as partial writes or corrupt tables that plagued earlier data lake solutions.
Another critical feature is schema evolution without rewrites. Iceberg allows columns to be added, renamed, reordered, or dropped without rewriting existing data files. Because schemas are tracked using column IDs rather than names, queries remain stable even as the schema evolves over time.
Iceberg also provides hidden partitioning, freeing users from manually encoding partition logic into file paths. Partitions can evolve transparently, improving query optimization while reducing operational burden. Combined with time travel, rollback, and incremental processing, Iceberg delivers a robust foundation for reliable analytics at scale.
What Is Parquet

Apache Parquet is a columnar storage file format designed specifically for analytical workloads. Originally created by Twitter and Cloudera, Parquet has become a de facto standard for storing structured data in data lakes and big data platforms. Its column-oriented layout enables efficient compression, encoding, and selective data access, making it ideal for large-scale scans and aggregations.
Unlike Iceberg, Parquet does not define table semantics, transactions, or metadata management across multiple files. Each Parquet file is self-describing and contains its own schema and statistics. Query engines read Parquet files directly, applying predicate pushdown and column pruning to minimize I/O and improve performance.
Parquet is widely supported across the data ecosystem, including Spark, Hive, Presto, Trino, Impala, DuckDB, and many cloud-native analytics services. Because of its simplicity and efficiency, Parquet is often the default choice for raw and curated data storage in data lakes.
How Apache Parquet Works
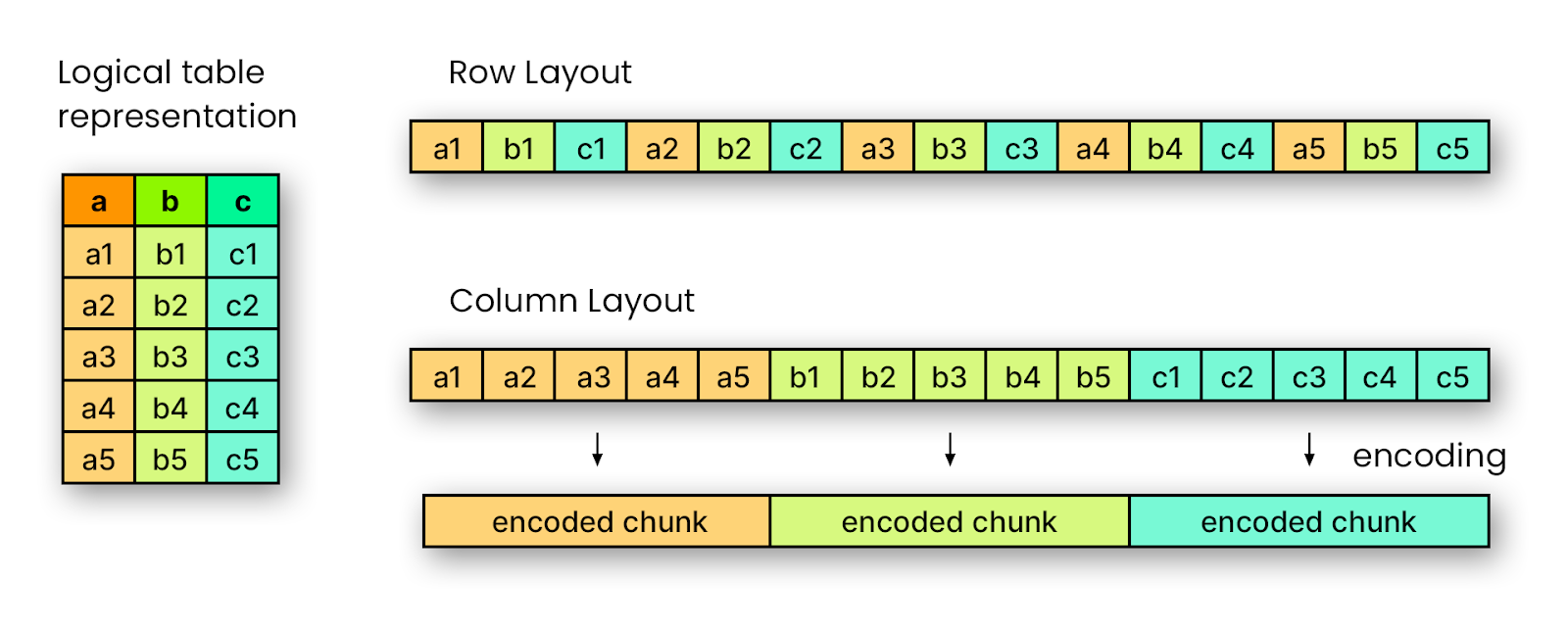
Apache Parquet is a columnar storage format, which means that values from the same column are stored contiguously on disk rather than storing entire rows together. This is illustrated in the figure: a logical table with multiple columns (a, b, c) can be stored either in row layout, where values are interleaved by row (a1, b1, c1, a2, b2, c2…), or in column layout, where all values from the same column are grouped together (a1, a2, a3…, b1, b2, b3…). By organizing data this way, Parquet enables efficient compression and encoding for each column independently, resulting in smaller file sizes and faster read performance for analytical queries that only need a subset of columns.
Parquet divides data into row groups, and each row group contains column chunks corresponding to the table columns. Within these chunks, Parquet can apply encoding schemes (such as dictionary encoding or run-length encoding) and compression independently for each column. This layout allows query engines to perform predicate pushdown and column pruning, reading only the relevant data blocks while skipping unnecessary ones. Additionally, Parquet files include metadata and statistics (like min/max values, null counts, and distinct counts) for each column chunk, which further helps optimize queries and minimize I/O.
Because Parquet focuses on efficient storage and fast reads, it does not handle multi-file transactions or table-level metadata, each file is self-describing and contains its own schema and statistics. Higher-level systems, like Apache Iceberg or Spark, are responsible for managing tables, schema evolution, and consistency across multiple Parquet files.
Key Features of Parquet
Parquet’s defining characteristic is its columnar layout, which stores values from the same column contiguously on disk. This design dramatically reduces the amount of data read during analytical queries, especially when only a subset of columns is required. Combined with advanced compression techniques, this results in smaller file sizes and faster scans.
Another important feature is rich metadata and statistics at the column and row-group level. Parquet files store min/max values, null counts, and other statistics that allow query engines to skip irrelevant data blocks efficiently. This capability is essential for predicate pushdown and query optimization.
Parquet also supports nested data structures, such as arrays and structs, making it suitable for semi-structured data. While Parquet excels at efficient storage and reads, it intentionally avoids managing multi-file consistency or transactions, leaving those responsibilities to higher-level systems.
Apache Iceberg vs Parquet: Feature Comparison
Apache Iceberg and Apache Parquet are often mentioned together, but they serve complementary purposes at different layers of the data stack.
Apache Iceberg
Iceberg is a table format designed to manage large analytic tables with reliability and flexibility. Its focus is on table-level operations, offering atomic commits, snapshot-based time travel, and safe concurrent reads and writes. Iceberg supports schema evolution and flexible, hidden partitioning, making it easy to handle incremental updates, rollbacks, and historical queries. It provides a consistent, versioned view of data for query engines, independent of the underlying file format.
Apache Parquet
Parquet is a columnar file format optimized for efficient storage and analytical query performance. Its main goal is to reduce I/O and storage costs through column-wise compression and encoding, enabling fast scanning of large datasets. Parquet does not manage table metadata or concurrency; it focuses solely on efficient storage and access. Combined with table formats like Iceberg, Parquet ensures both high storage efficiency and robust table management.
Together, Iceberg and Parquet enable scalable, reliable, and high-performance analytics: Iceberg handles table-level operations, versioning, and metadata, while Parquet provides the underlying columnar storage that makes large-scale queries fast and efficient.
Which One Is Right for You?
At its core, the difference between Iceberg and Parquet is one of scope and responsibility. Parquet is a columnar file format: it defines how data is stored on disk for efficient compression and query performance. Iceberg, in contrast, is a table format: it organizes collections of files into managed tables with explicit metadata, schemas, partitions, snapshots, and transactional guarantees.
Because Parquet focuses only on file layout, it excels in read-heavy analytical workloads where data is mostly append-only and schema evolution is rare. It does not track versions, enforce atomic writes, or manage partitions beyond what the file system provides. Iceberg builds on top of formats like Parquet (or Avro/ORC), adding a layer of table management that makes large datasets easier to govern. With Iceberg, users can safely perform concurrent reads and writes, roll back changes, time-travel queries to previous snapshots, and evolve schemas without rewriting entire datasets.
In practice, the choice boils down to whether you need just efficient storage and query performance (Parquet) or a full-fledged, manageable table abstraction with transactional guarantees and metadata-driven operations (Iceberg). For pipelines that require incremental updates, complex partitioning, or long-term table governance, Iceberg is the natural fit; for simple analytical workloads over static or append-only datasets, Parquet alone may suffice.
Real-Time Graph Queries on Iceberg with PuppyGraph
Apache Iceberg serves as a foundational component in modern lakehouse architectures, providing reliable, high-performance storage for large-scale analytical datasets. By combining the flexibility of data lakes with the reliability and transactional guarantees of data warehouses, Iceberg enables organizations to manage evolving data efficiently while supporting ACID transactions, schema evolution, and time travel. This makes it an ideal backbone for analytics, machine learning, and data engineering workflows, allowing teams to maintain a single source of truth across vast, heterogeneous datasets without sacrificing query performance or governance.
PuppyGraph extends the Iceberg ecosystem by enabling real-time graph queries directly on Iceberg tables, without requiring data movement or duplication. Users can model complex relationships and explore multi-hop dependencies, such as organizational hierarchies, supply chains, or knowledge graphs, directly on their existing datasets. By supporting standard graph query languages like Gremlin and openCypher, PuppyGraph integrates seamlessly with existing access controls and analytics pipelines, providing live insights across billions of edges with sub-second response times. This approach combines the scalability and reliability of Iceberg with the flexibility of graph analytics, allowing teams to analyze relationships iteratively and at enterprise scale, all within their existing lakehouse environment.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.




Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Apache Iceberg and Apache Parquet address different layers of the data stack but work best together. Parquet provides efficient columnar storage for fast analytical queries, while Iceberg adds table-level management, transactional guarantees, schema evolution, and time-travel capabilities. Understanding their distinction ensures better system design, allowing organizations to handle large-scale, evolving datasets with reliability and performance.
PuppyGraph builds on this foundation by enabling real-time, zero-ETL graph queries directly on Iceberg tables and other data lakes. It allows teams to explore complex relationships without duplicating data or building separate pipelines, combining the power of SQL and graph analytics. Together, Iceberg, Parquet, and PuppyGraph empower organizations to extract timely, actionable insights from massive datasets while reducing operational complexity and total cost of ownership.
Try the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install