

Apache Parquet vs ORC: Key Differences & Performance
As modern data platforms continue to scale, efficient data storage formats have become a foundational component of analytics performance. Among the most widely adopted columnar formats in the big data ecosystem are Apache Parquet and ORC (Optimized Row Columnar). Both formats were designed to address the inefficiencies of traditional row-based storage, particularly for analytical workloads that scan large datasets but only a subset of columns. Despite sharing similar goals, Parquet and ORC differ significantly in architecture, compression techniques, ecosystem support, and performance trade-offs.
Choosing between Parquet and ORC is not merely a technical preference but a strategic decision that can influence query latency, storage costs, and long-term maintainability of data pipelines. Organizations using cloud data lakes, distributed SQL engines, and batch analytics frameworks often need to decide which format aligns best with their workloads. This article provides a comprehensive comparison of Apache Parquet and ORC, examining their internal design, performance characteristics, and practical use cases to help data engineers and architects make an informed decision.
What Is Apache Parquet?

Apache Parquet is an open-source, columnar storage format originally developed by Twitter and Cloudera, and later donated to the Apache Software Foundation. It is designed to efficiently store and process large-scale datasets in distributed systems such as Hadoop and cloud-based data lakes. Parquet organizes data by columns rather than rows, enabling analytical queries to read only the necessary columns instead of scanning entire records. This approach significantly reduces disk I/O and improves query performance in read-heavy workloads.
Parquet is built around a record shredding and assembly algorithm, which allows it to efficiently encode nested data structures such as arrays and structs. This makes it particularly well-suited for semi-structured data often encountered in modern analytics pipelines. Each Parquet file is divided into row groups, column chunks, and pages, enabling fine-grained data access and efficient compression. The format also supports schema evolution, allowing datasets to change over time without requiring complete rewrites.
One of Parquet’s major strengths is its broad ecosystem support. It is natively supported by Apache Spark, Apache Hive, Apache Impala, Presto, Trino, Amazon Athena, Google BigQuery, and many other analytics engines. As a result, Parquet has become the de facto standard storage format for cloud data lakes on platforms such as Amazon S3, Azure Data Lake Storage, and Google Cloud Storage.
How Apache Parquet Works
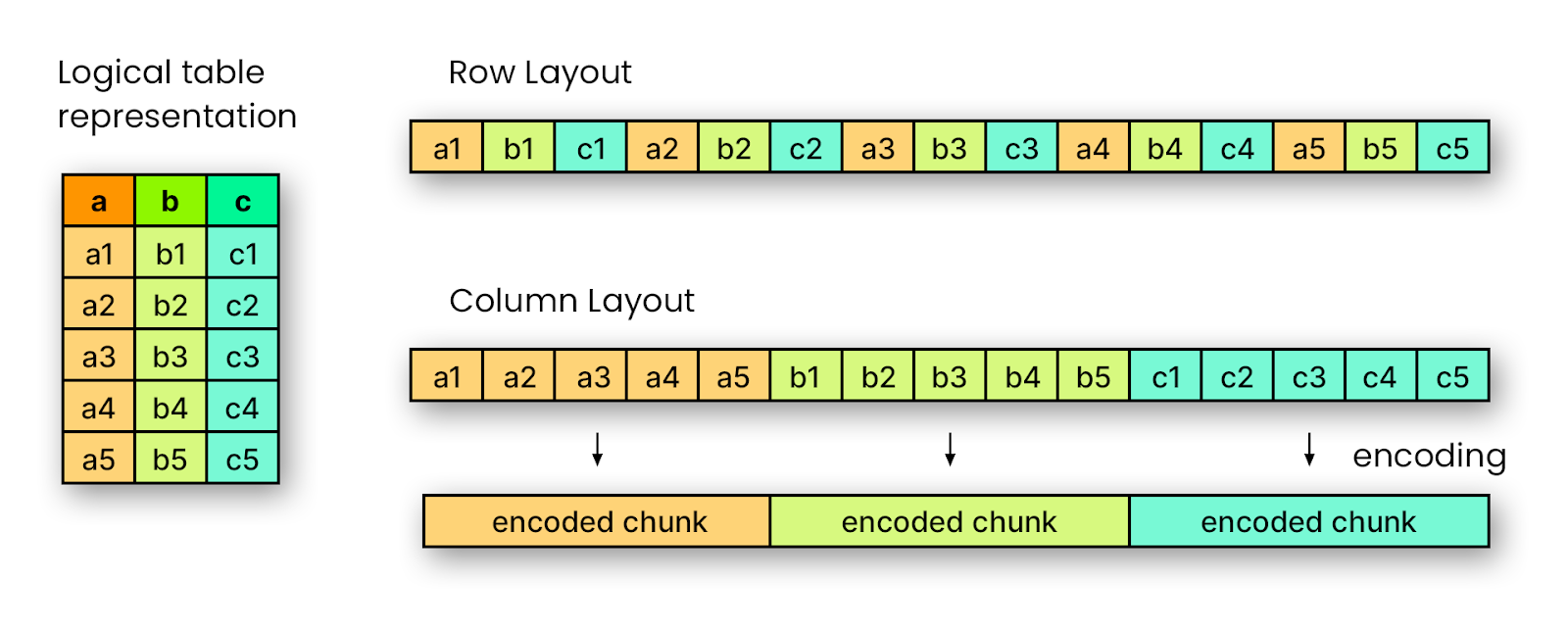
Apache Parquet is a column-oriented storage format, which means that data from the same column is stored sequentially on disk rather than storing entire rows together. As shown in the figure, a logical table with multiple columns (a, b, c) can be represented in two ways: in a row-oriented layout, values are interleaved row by row (a1, b1, c1, a2, b2, c2…), whereas in a column-oriented layout, all values from a single column are stored consecutively (a1, a2, a3…, b1, b2, b3…). This columnar organization allows Parquet to apply compression and encoding individually on each column, leading to reduced file sizes and faster read performance for analytical queries that access only a subset of columns.
Parquet organizes data into row groups, with each row group containing column chunks corresponding to the table’s columns. Within these chunks, Parquet can independently apply various encoding techniques (such as dictionary encoding or run-length encoding) and compression for each column. This structure enables query engines to perform predicate pushdown and column pruning, reading only the necessary data while skipping irrelevant blocks. Moreover, Parquet files store metadata and statistics for each column chunk, like min/max values, null counts, and distinct counts, which further improves query efficiency and reduces I/O.
Since Parquet is designed for storage efficiency and fast reads, it does not manage multi-file transactions or table-level metadata; each file is self-contained, including its own schema and statistics. Table management, schema evolution, and consistency across multiple Parquet files are handled by higher-level systems such as Apache Iceberg or Spark.
What Is ORC?

ORC, short for Optimized Row Columnar, is a columnar storage format originally developed by the Apache Hive community to improve Hive query performance. Like Parquet, ORC stores data by columns rather than rows, but it places a stronger emphasis on aggressive compression, indexing, and query-time optimization. ORC files are designed to minimize storage footprint while enabling highly efficient predicate pushdown and data skipping during query execution.
An ORC file is composed of stripes, each containing index data, row data, and stripe-level statistics. These statistics include minimum and maximum values, counts, and sums for each column, allowing query engines to skip entire stripes that do not match query predicates. This makes ORC particularly efficient for large, structured datasets where filtering and aggregation are common. ORC also supports complex data types and nested structures, though its handling differs internally from Parquet’s shredding approach.
ORC has deep integration with Apache Hive and Apache Hadoop ecosystems, and it is also well-supported by Apache Spark, Presto, and Trino. In many Hadoop-centric deployments, ORC is often the default or recommended format for Hive-managed tables. Its advanced compression techniques and built-in indexing capabilities make it a strong choice for environments where storage efficiency and scan performance are critical.
How Apache ORC Works
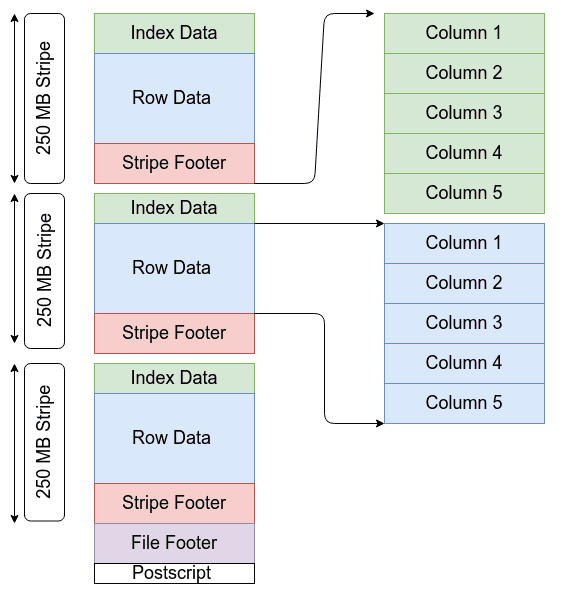
Apache ORC organizes data in a highly efficient, columnar layout designed to reduce I/O and speed up analytical queries. At the highest level, an ORC file consists of a sequence of stripes, each of which contains all the necessary information to read and filter a portion of the dataset independently.
Each stripe in an ORC file typically spans hundreds of megabytes (often ~250 MB), and is split into three main parts:
- Index Data: A set of lightweight indexes that store column statistics (like minimum, maximum, and null counts) and row positions. These indexes allow query engines to skip large blocks of data that do not satisfy a filter predicate without reading the actual row values. Within each stripe, the index data is organized by column so only the relevant parts need to be loaded for a given query.
- Row Data: The actual encoded and compressed values for each column in the stripe, stored in separate streams. Columns are broken into multiple streams (e.g., presence bits, actual values, length information for variable-length types) so that engines can read only the columns required by a query rather than the full row.
- Stripe Footer: A small directory describing where each stream lives within the stripe (offsets and lengths). This metadata enables the reader to locate the desired column data efficiently.
Together, these three sections allow an ORC reader to perform predicate pushdown and column pruning: by inspecting only the index data and stripe footer, the engine can decide whether to skip a stripe entirely or read just the necessary streams for matching columns.
After all the stripes in a file, the ORC format also includes a file footer and a postscript. The file footer aggregates global statistics, schema information, and the list of stripes, while the postscript includes compression parameters needed to interpret the rest of the file.
ORC supports a range of compression codecs (such as Zstd, Snappy, or Zlib) and uses efficient encoding schemes tailored to data types, for example, run-length or dictionary encoding. This combination of columnar layout, rich statistics, and compression makes ORC particularly effective at minimizing storage footprint and accelerating selective reads.
In summary, the way ORC breaks a file into self-describing stripes with per-column indexes and encoded data enables distributed query engines to read only what’s necessary, skip irrelevant data, and achieve high performance on analytical workloads.
Differences Between Apache Parquet vs ORC
The differences between Parquet and ORC become most apparent when examining their internal structures, compression strategies, and performance characteristics across different workloads. While both formats aim to optimize analytical queries, they take different design approaches that lead to distinct strengths and trade-offs. Parquet emphasizes flexibility and cross-platform compatibility, whereas ORC focuses on tight integration with query engines and aggressive optimization.
The table below summarizes the key differences between Apache Parquet and ORC across commonly evaluated dimensions.
From a performance perspective, Parquet tends to excel in environments where data is written once and read many times across diverse tools. ORC, on the other hand, often delivers superior performance for highly selective queries that benefit from its detailed indexing and statistics. Understanding these differences is essential when designing large-scale analytics systems.
When to Use Apache Parquet?
Apache Parquet is an excellent choice when interoperability and flexibility are primary concerns. In modern data lake architectures, datasets are often accessed by multiple query engines, machine learning pipelines, and external analytics tools. Parquet’s widespread adoption ensures that data stored in this format can be seamlessly read and written across a broad range of platforms without vendor lock-in. This makes it particularly suitable for organizations operating in heterogeneous analytics environments.
Parquet is also well-suited for workloads involving semi-structured or nested data. Its record shredding mechanism efficiently represents complex schemas, enabling performant analytics on datasets derived from JSON, Avro, or event-based sources. Data engineers working with streaming ingestion pipelines often prefer Parquet because it integrates naturally with Apache Spark and Apache Flink, supporting both batch and micro-batch processing patterns.
In cloud-native architectures, Parquet is frequently the default format for data lakes due to its strong support in managed services such as Amazon Athena, AWS Glue, Google BigQuery external tables, and Azure Synapse. These services leverage Parquet’s column pruning and predicate pushdown capabilities to reduce query costs and latency. Consequently, Parquet is also the most widely used file format for Apache Iceberg tables, ensuring compatibility and performance across modern analytics engines.
When to Use ORC?
ORC is particularly advantageous in environments where query performance and storage efficiency are tightly coupled with the Hadoop ecosystem. Organizations that rely heavily on Apache Hive or Hadoop-based SQL engines often benefit from ORC’s deep integration and optimization features. The format’s stripe-level indexes and rich column statistics allow query planners to aggressively skip irrelevant data, resulting in faster execution times for selective queries.
ORC is also well-suited for large, structured datasets with relatively stable schemas. Its compression efficiency can lead to significantly smaller file sizes compared to other formats, reducing storage costs and improving scan speed. This makes ORC attractive for data warehouses and reporting systems where data is frequently aggregated and filtered but infrequently updated.
Another scenario where ORC excels is in environments with strict performance requirements and controlled tooling. When the data access patterns are well understood and the analytics stack is standardized around ORC-compatible engines, the format’s advanced optimizations can deliver consistent and predictable performance. In such cases, ORC’s tighter coupling with the execution engine becomes a strength rather than a limitation.
Working with PuppyGraph
PuppyGraph fits naturally into modern lakehouse architectures as a graph query engine that operates directly on existing relational tables. Rather than introducing a new storage layer, PuppyGraph connects to lakehouse table formats such as Apache Iceberg, Delta Lake, and Apache Hudi, as well as Hive-managed tables, and queries their underlying columnar data in place.
These table formats internally store data in columnar file formats such as Apache Parquet or ORC. Iceberg and Hudi are format-agnostic and commonly use Parquet (with optional ORC support), while Delta Lake standardizes exclusively on Parquet. Hive, acting as a metastore and SQL layer, can manage tables backed by Parquet or ORC files. PuppyGraph transparently leverages these existing storage layouts, preserving column pruning, predicate pushdown, and compression benefits without duplicating data.
By operating directly on lakehouse tables, PuppyGraph enables teams to model and query relational data as a unified graph without ETL pipelines or data replication. Graph traversals, multi-hop joins, and relationship-heavy analytics are executed in real time on top of the same Parquet or ORC files already used for SQL, machine learning, and other analytic workloads, ensuring consistency across workloads.
This approach allows organizations to combine the strengths of columnar storage formats, efficient scans and cost-effective storage, with native graph querying capabilities. Teams can continue using SQL engines for tabular analysis while relying on PuppyGraph for deep relationship exploration, all on top of a single, shared lakehouse foundation.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.




Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
As data ecosystems scale, choosing the right columnar storage format, Parquet or ORC, directly impacts performance, storage efficiency, and analytics flexibility. Parquet excels in interoperability, semi-structured data handling, and cloud-native environments, making it ideal for diverse, read-heavy workloads across multiple engines. ORC offers superior compression, indexing, and selective query performance, particularly in Hadoop-centric, structured datasets. Understanding these differences allows teams to align storage choices with workload patterns, ensuring optimized query speed and cost efficiency.
PuppyGraph leverages these columnar formats without introducing new storage layers, enabling real-time graph analytics directly on existing lakehouse or database tables. By combining zero-ETL access, in-place querying, and scalable distributed computation, PuppyGraph allows organizations to extract relationship insights efficiently while maintaining data consistency and lowering operational overhead. This integration bridges the best of SQL and graph analysis, making complex, multi-hop queries on massive datasets both practical and performant.
Try the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install