

Top 7 ArangoDB Alternatives of 2026

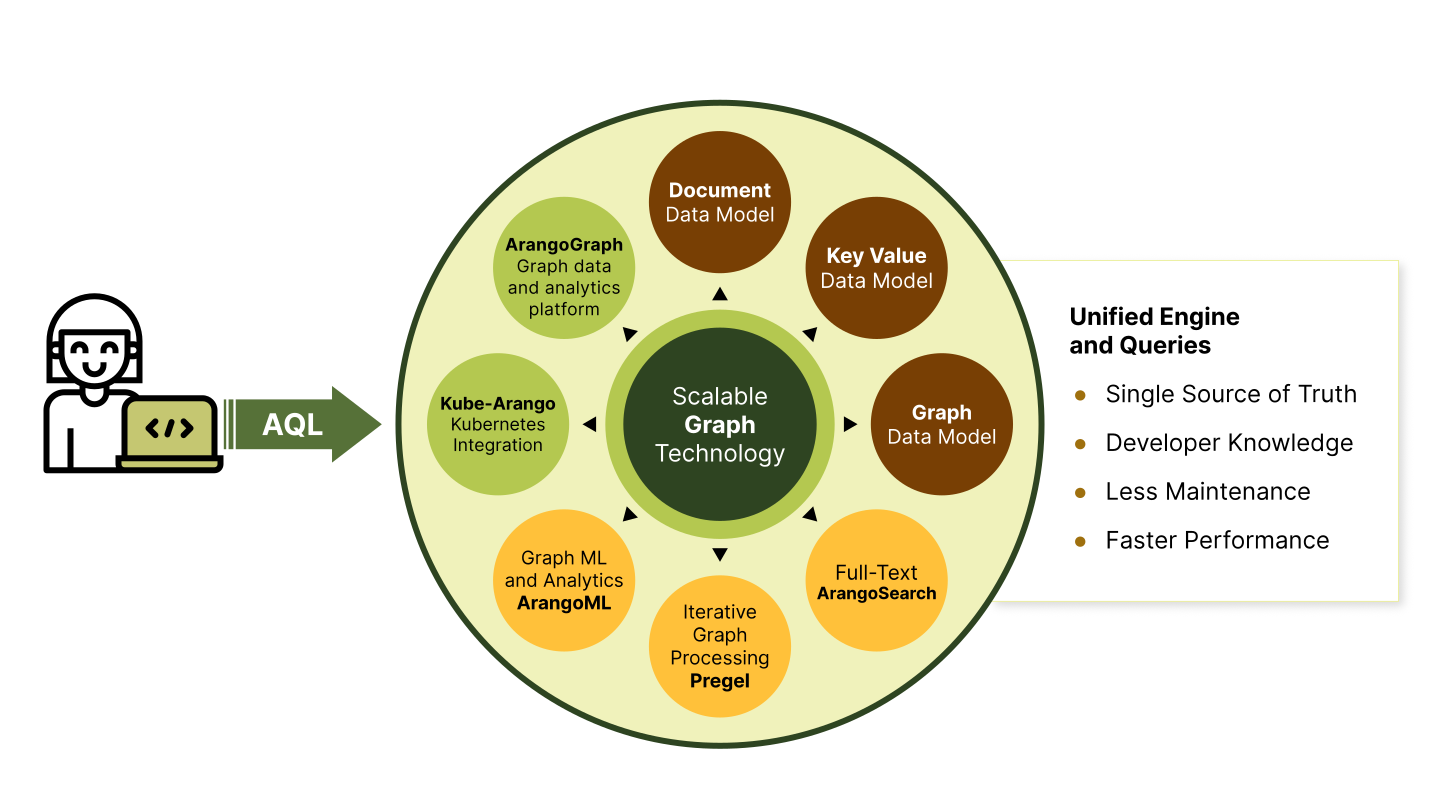
If you’re exploring graph databases, ArangoDB is hard to miss. It goes beyond just a graph store. ArangoDB is a multi-model database that combines graph, document, key-value, and search features in one engine. That flexibility matters when your data mixes relationships with rich attributes, or when you want to query connections and context together.

ArangoDB began as an open-source project in 2011 under the name AvocadoDB, a playful nod to its early working title, Versatile Object Container (VOC). In 2012, the team rebranded to ArangoDB to avoid trademark issues, choosing “Arango” after an avocado variety.
As a breath of fresh air in the graph database scene, it delivers strong performance on graph workloads even though it is not a specialized graph database. That makes it worth a closer look. How is it architected? How does it store and query data? Where does it shine in practice?
Of course, no database fits every workload. In this blog, we’ll walk through how ArangoDB works, explore the trade-offs that come with its design, and compare seven alternatives you might consider instead: PuppyGraph, Neo4j, JanusGraph, Amazon DynamoDB, MongoDB, Couchbase, and CosmosDB.
What is ArangoDB?
Multi-Model Flexibility
ArangoDB is built as a multi-model database. You get graph, document, key-value, and even search capabilities in one system. You can model relationships with edges, keep JSON records nearby, and still perform simple lookups all in one place. That kind of flexibility is greatly appreciated when your data doesn’t fit neatly into one structure.
While ArangoDB exposes data as JSON, it internally stores documents in a highly optimized binary format called VelocyPack (VPack). Data lives in collections as JSON-like documents with _key, _id, and _rev. The primary index on _key gives you fast key-value access, and secondary indexes let you query by other attributes. This is the core that supports document workloads and simple lookups.
Graphs sit on top of the same storage. Entities are stored in regular (vertex) collections. Relationships are stored as documents in edge collections with _from and _to pointing to vertex _ids. Built-in edge indexes on those fields make traversals efficient. The data is still documents; the graph behavior comes from how edge documents link them.
It also offers optional schema validation. You can begin with a schema-less approach for rapid development, then introduce validation rules as your data structure matures. This flexibility makes ArangoDB a good fit for evolving datasets or mixed workloads where some collections need structure while others do not.
Unified Querying with AQL
ArangoDB uses AQL, a declarative language that works across documents, graphs, key-value access, and search, so you can combine relationships and attributes in a single query. It covers CRUD, joins, filtering, aggregation, graph traversal, and full-text search. Because it spans models, you can blend graph logic with document attributes in the same query.
For day-to-day development, AQL includes practical features that keep queries readable and reusable, such as bind parameters and subqueries. It also supports user-defined functions for custom logic when built-ins are not enough.
Graph and Search Capabilities
ArangoDB supports property graphs with vertex and edge collections. You can run multi-hop traversals, shortest path queries, and neighborhood lookups with fine-grained control over depth and direction in AQL.
For search-heavy workloads, ArangoSearch is a built-in engine based on inverted indexes. It offers relevance ranking, filtering, text analyzers, and nested search. Because ArangoSearch is fully accessible from AQL, you can combine text relevance with graph or document predicates in a single query. This works well for product catalogs, knowledge bases, and log or ticket exploration.
Scalability and Operational Features
ArangoDB’s Community Edition covers the core needs for production scale. You can shard data horizontally, replicate across nodes, and rely on automatic failover for high availability. ACID transactions are supported across documents and collections within the documented scopes. In clusters, full multi-document and multi-collection ACID semantics apply on a single server or with OneShard. Cross-shard transactions follow different guarantees.
The Enterprise Edition adds features aimed at large and distributed graphs. SmartGraphs, EnterpriseGraphs, SmartJoins, and SatelliteCollections improve data locality and reduce cross-shard hops. Traversals can run in parallel to speed up heavy graph reads. Enterprise also expands operations and security. It includes hot and encrypted backups, data center to data center replication for disaster recovery, encryption at rest, and audit logging for compliance.
How Does ArangoDB Work?
Persistent Storage
- Engine based on RocksDB with a write-ahead log and LSM compaction.
- Documents in collections with primary and secondary indexes, plus geo, TTL, and inverted indexes.
Sharding, Transactions, and High Availability
- Shard keys place documents across DB-Server. Edges are sharded too, so locality impacts traversal cost.
- Single-document writes are atomic. Full multi-collection ACID on a single server and in clusters with OneShard. Cross-shard transactions have different guarantees.
- Replication and automatic failover provide high availability.
Cluster Roles
- Coordinators: parse AQL, build plans, route work to data owners, merge results.
- DB-Servers: store shards of collections, run scans and traversals, apply writes, keep replicas.
- Agency: holds cluster metadata and consensus via the Raft Consensus Algorithm, coordinates shard moves and failover.
Query Layer (AQL)
- Model-agnostic planning that can mix a traversal, a document index scan, and an ArangoSearch view scan in one query.
- Built-in traversal operators support multi-hop navigation and shortest paths.
Search Layer (ArangoSearch)
- Inverted indexes exposed as Views with analyzers for tokenization and normalization.
- Relevance scoring such as BM25 and TF-IDF, with near-real-time visibility via background commitIntervalMsec and eventual consistency.
Analytics Layer (ArangoML and Pregel)
- ArangoML integrates ArangoDB with external ML stacks, supports feature engineering in AQL, and lets you export or serve features while tracking datasets, runs, and models in the same database.
- Pregel runs graph-wide algorithms as asynchronous jobs using a bulk synchronous model, writes results back to vertex fields for later AQL queries, and fits scheduled recomputes rather than request-time logic.
Service Layer (Foxx)
- JavaScript microservices that run inside ArangoDB. Define HTTP endpoints that execute AQL, enforce validation, and bundle small bits of business logic next to your data.
- Good for feature serving, simple APIs, and glue code where you want transactional reads or writes and minimal network hops. Keep heavy computation and long-running tasks in your application tier.
Why Explore ArangoDB Alternatives?
Licensing and Usage Limits
Since version 3.12, ArangoDB uses the Business Source License. Community Edition is free for non-commercial use and capped at 100 GiB of total data, which is fine for prototypes and small internal apps but limiting for production. Larger or commercial deployments require a paid edition or the managed service, which changes the cost model and procurement path.
Analytics Workflow
Global graph algorithms in ArangoDB run as Pregel jobs that execute asynchronously across the cluster and then write results back to vertices for later queries. This pattern fits scheduled analytics where a few minutes of freshness lag is acceptable. It also concentrates resource usage during the job window, which you need to plan around. If you require on-demand algorithms inside request-time queries, an external engine with a larger in-query algorithm catalog can fit better.
Vendor-specific Query Language
AQL is powerful and model-agnostic, but it is unique to ArangoDB. Teams standardizing on SQL, Cypher, or Gremlin will face query rewrites and retraining if they migrate. That shift also affects hiring, libraries, and existing tooling. If long-term portability across engines matters, a more widely adopted query language may be preferable.
Search Consistency Model
ArangoSearch is near real time, not strictly transactional. New writes become searchable after a background commit, so visibility depends on a configurable interval rather than an immediate read-after-write guarantee. You can tune the interval for faster freshness at the cost of more overhead. If your application needs strict read-your-writes semantics on search, this behavior can be a mismatch.
Top 7 ArangoDB Alternatives
PuppyGraphPuppyGraph

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


PuppyGraph also supports Gremlin and openCypher, two expressive graph query languages ideal for modeling user behavior. Pattern matching, path finding, and grouping sequences become straightforward. These types of questions are difficult to express in SQL, but natural to ask in a graph.

PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the teams that win ask deeper questions faster. PuppyGraph fits that need. It powers cybersecurity use cases like attack path tracing and lateral movement, observability work like service dependency and blast-radius analysis, fraud scenarios like ring detection and shared-device checks, and GraphRAG pipelines that fetch neighborhoods, citations, and provenance. If you run interactive dashboards or APIs with complex multi-hop queries, PuppyGraph serves results in real time.
Getting started is quick. Most teams go from deploy to query in minutes. You can run PuppyGraph with Docker, AWS AMI, GCP Marketplace, or deploy it inside your VPC for full control.
Neo4j

Neo4j is a native property-graph database built around nodes and relationships. It created the Cypher query language, a declarative pattern-matching syntax used widely for expressing complex graph queries. The platform also includes the Graph Data Science library for algorithms such as PageRank, community detection, and link prediction, and provides official drivers for common languages over Bolt and HTTP.
Under the hood, Neo4j uses index-free adjacency, where each node stores direct references to its neighbors. This makes multi-hop traversals efficient. Neo4j provides full ACID transactions, ships in Community and Enterprise editions, and is available self-hosted or as the managed AuraDB service.
Choose Neo4j when you want a graph-first stack with Cypher, you plan to use an in-database algorithms library, or you prefer a fully managed service for production.
JanusGraph

JanusGraph is an open-source, distributed graph database that runs on top of backends like Apache Cassandra, Apache HBase, or Google Cloud Bigtable, with indexing through Elasticsearch, Solr, or Lucene. Queries use the Apache TinkerPop stack with the Gremlin traversal language, and large-scale analytics can run through GraphComputer with engines such as Spark.
Compared with ArangoDB, JanusGraph decouples storage, indexing, and query rather than bundling them into one multi-model engine. You work in Gremlin instead of AQL, and you rely on your chosen index backend for search features rather than a built-in search layer.
It follows the property graph model and uses Gremlin from the Apache TinkerPop stack. That gives you a traversal-first way to express paths and patterns, which fits teams that already build around TinkerPop’s tooling and drivers.
Choose JanusGraph when you want Gremlin and TinkerPop, plan to reuse infrastructure, or prefer an open-source graph that scales by pairing with the storage and search systems you already operate.
Amazon DynamoDB

Amazon DynamoDB is a fully managed, serverless database for key-value and document data. You do not manage servers or capacity planning. DynamoDB scales with your traffic, allowing reads and writes to stay fast at high load. You can pay on demand or set a target and let the service autoscale, which cuts operational work and helps you move from prototype to production quickly.
Global Tables replicate your data across AWS regions so users see low latency, and traffic can fail over automatically if a region has issues. DynamoDB also supports transactions for critical updates and secondary indexes so you can add a few extra access patterns without redesigning your data.
Choose DynamoDB over ArangoDB when your workload is mostly document or key-value, you want the convenience of not having to manage servers on AWS, and your queries are straightforward lookups or simple aggregations.
MongoDB

MongoDB is a document database built around BSON documents and MQL, which includes both CRUD-style queries and the Aggregation Framework. You index the fields you query and compose pipelines with stages like $match, $project, $group, $sort, and $lookup for joins. It supports multi-document ACID transactions, automatic replication, and horizontal sharding. Many teams run it on MongoDB Atlas for backups, security controls, global distribution, and mature operational tooling.
Compared with ArangoDB, MongoDB is document-first rather than multi-model. If you need full-text features, Atlas Search brings Lucene-based relevance directly into the platform, keeping everything within the same operational envelope.
Choose MongoDB when your workload is primarily document-centric and you want fast iteration and flexible schemas with a large ecosystem. If you don’t need one engine to handle graphs and search alongside documents, MongoDB often provides the simpler path with strong managed options and broad driver support.
Couchbase

Couchbase is a distributed JSON document store with a built-in key-value layer and separately scalable Data, Query, Index, Search, Analytics, and Eventing services. Its Multi-Dimensional Scaling (MDS) architecture lets you scale each one independently instead of growing the whole cluster at once.
You work with SQL++ (formerly N1QL) for querying JSON. Couchbase’s full-text search service is distributed and powered by the Bleve search library, so you can scale search separately while still calling it from SQL++.
Operationally, Couchbase provides distributed ACID transactions with tunable durability. Writes are memory-first, then persisted and replicated per your durability level. Ephemeral buckets are available when you want in-memory datasets without disk.
Consider Couchbase Choose Couchbase when your workload is document-heavy, you need fast key-value access and SQL-style queries, and you want the freedom to scale search, query, and indexing on their own.
CosmosDB

Azure Cosmos DB is Microsoft’s fully managed cloud database. It runs in data centers worldwide and handles the heavy lifting for you, including servers, upgrades, backups, and failover. It offers multi-API support, so most apps and drivers keep working without big rewrites. You can also choose a consistency level (from strong to eventual) per account, and override it per request when needed.
Getting global coverage is simple. You add regions with a click, and Cosmos DB keeps your data in sync and routes traffic automatically if a region has trouble. You do not size machines or build your own replication. For capacity, you can set a target and let Cosmos scale for you, or pay per request with a serverless option.
Choose Cosmos DB when your priority is a managed, globally available database with minimal operational work.
Conclusion
The right database depends on how your data behaves and what you expect from it. ArangoDB delivers when you need a multi-model engine that supports documents, graphs, key-value pairs, and search in one place. But if your use case stretches beyond those boundaries, whether it’s real-time search consistency, a different analytics model, or tighter alignment with Cypher or Gremlin, other tools may be a better fit.
What if you already have the data but don’t want to rework your pipelines? That’s where PuppyGraph stands apart. It gives you the power of graph queries without the traditional cost and overhead of managing a separate graph database.
Try the forever-free PuppyGraph Developer Edition, or book a demo with our team to see how quickly you can start querying your data as a graph.

Jaz Ku is a Solution Architect with a background in Computer Science and an interest in technical writing. She earned her Bachelor's degree from the University of San Francisco, where she did research involving Rust’s compiler infrastructure. Jaz enjoys the challenge of explaining complex ideas in a clear and straightforward way.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install