

BigQuery vs Redshift: Key Differences & Performance
If you are evaluating cloud data warehouses, you might have narrowed the options down to Google BigQuery and Amazon Redshift. They dominate the space for good reason: both handle petabyte-scale analytics, both have matured considerably over the past decade, and both have deep ecosystem integrations that make them difficult to displace once embedded.
In this article, we will discuss how these solutions were built on fundamentally different premises, and how those premises have differed them across performance, expenses, and operations.
What is BigQuery?

Google BigQuery is a fully managed, serverless data warehouse built on Google Cloud Platform. It emerged from Google's internal Dremel query engine, the same infrastructure Google uses to query its own petabyte-scale datasets, and has been commercially available since 2011.
A characterizing property of BigQuery’s architecture is isolation of storage and compute; the two scale independently, and neither requires manual provisioning. BigQuery allocates processing capacity, measured in virtual CPU units called slots, on demand for queries, executes the query across Google's distributed infrastructure, and releases those resources upon completion. If you are an engineer, there are no clusters to size, no nodes to monitor, and no resize operations to schedule.
Data in BigQuery sits in Capacitor, Google's proprietary columnar storage format that is optimized for the read-heavy, aggregation-intensive patterns characteristic of analytical workloads. Query execution runs on Dremel's distributed tree architecture, which fans a query out across thousands of workers in parallel and reassembles the result; it is a design that makes it particularly well-suited to large, ad hoc scans over massive tables.
BigQuery natively integrates with the broader Google Cloud ecosystem, for example, Pub/Sub for streaming ingestion, Dataflow for pipeline orchestration, Looker for visualization, and BigQuery ML for in-warehouse model training through standard SQL.
What is Redshift?

Amazon Redshift is AWS's fully managed, petabyte-scale cloud data warehouse, first released in 2012. Where BigQuery abstracts all infrastructure away, Redshift is fundamentally a cluster-based system: you provision nodes, configure their type and count, and the cluster becomes your dedicated compute environment. This design gives engineers precise control over performance and cost, but it demands active management in return.
Redshift's architecture employs Massively Parallel Processing (MPP): queries decompose into parallel execution units distributed across nodes, each carrying its own CPU and memory, with results assembling at a leader node before returning to the client. Data persists in columnar format, which reduces I/O for analytical workloads, and Redshift applies compression encoding, like LZO, Zstandard, and byte-dictionary, automatically.
The current primary node family, RA3, decouples compute from storage by offloading data to Redshift Managed Storage, backed by S3. As a result, compute and storage scale independently, a meaningful architectural evolution from the earlier, SSD-bound DC2 nodes. If you prefer not to manage clusters at all, Redshift Serverless abstracts provisioning behind an RPU (Redshift Processing Unit) model, scaling between 8 and 512 RPUs on demand.
On the ecosystem side, Redshift integrates natively with S3 through Redshift Spectrum, AWS Glue Data Catalog, Lake Formation, and IAM. So it is a coherent fit if you are already running workloads on AWS. Its SQL dialect is PostgreSQL-compatible, though it diverges in places, so teams migrating complex query logic should expect some adaptation.
BigQuery vs Redshift: Key Differences
When to Choose BigQuery
Choose BigQuery if your team has substantially adopted Google Cloud. Data migration between cloud providers incurs egress costs and pipeline complexity. If your warehouse is on the same platform as your ingestion, orchestration, and visualization layer, you preclude those predicaments.
Also take a look at your query patterns: if they are irregular and your team lacks dedicated database administration resources, opt for BigQuery. Redshift's performance ceiling, although arguably higher, reaching that threshold requires deliberate tuning. BigQuery requires nothing of that sort. A data engineer can load a terabyte table and run a complex aggregation query within minutes, without having to use a single configuration parameter. That is a substantial appeal for when engineering resources are scarce, a meaningful productivity advantage over time.
BigQuery is also a sound option for bursty or seasonal workloads, like advertising analytics, event-driven pipelines, periodic batch jobs. Redshift's provisioned model bills hourly regardless of activity; a cluster sitting idle overnight still costs money. BigQuery's on-demand model charges only for what queries actually do, which makes it considerably more economical when utilization is uneven across the day or week.
If machine learning is a first-class concern alongside analytics, you can choose BigQuery. BigQuery ML allows engineers to train, evaluate, and run inference on models directly within the warehouse using standard SQL; so you do not need to export data to an external training environment.
Finally, consider BigQuery if your data volumes are extreme and your queries are exploratory in nature. As we have already discussed, its distributed execution engine is optimized for such use cases. Redshift can match this at scale, but only with deliberate capacity planning and the engineering investment to back it.
When to Choose Redshift
Redshift is the evident choice if you are running your infrastructure on AWS; the native integrations are difficult to replicate from outside the ecosystem. BigQuery can ingest from AWS sources, but it does so across a cloud boundary, adding latency, egress cost, and pipeline complexity that Redshift simply doesn't incur.
Redshift is also recommended if your workloads are steady, high-volume, and query patterns are well understood. Redshift's provisioned model rewards consistency; a well-tuned cluster guarantees reliable, repeatable performance for the BI dashboards and scheduled reports that drive daily operations. While BigQuery's on-demand model is non-deterministic at the margins, organizations can achieve guaranteed, dedicated compute for SLA-bound workloads by utilizing slot reservations under BigQuery Editions.
Also consider the amount of investment in database administration and configuration efforts in Redshift. A carefully configured Redshift cluster outperforms BigQuery's managed defaults on structured, repetitive workloads. If your team treats the warehouse more as infrastructure to be engineered and less as a service to be consumed, you can draw out considerably more value from Redshift.
Redshift is a great option when data residency and network isolation are non-negotiable. Redshift deploys within your own VPC by default: your data never traverses a shared network boundary. Contrarily, BigQuery's multi-tenant architecture does offer logical isolation. However, regulated industries, as a compliance obligation, oftentimes require physical network separation. In those cases, Redshift's deployment model is the more defensible choice.
BigQuery vs Redshift for Real-Time Analytics
Both BigQuery and Redshift have made meaningful strides toward real-time analytics, but neither was conceived as a real-time system.
BigQuery ingests streaming data through its Streaming API and BigQuery Storage Write API, the latter making rows available for querying within seconds of ingestion. For event-driven pipelines, like IoT telemetry, this is a credible real-time path. The constraint is cost: streaming inserts bill separately from storage and query. At high ingestion volumes, those charges accumulate faster than batch loads would. BigQuery also introduced BI Engine, an in-memory analysis service that caches frequently accessed data to deliver sub-second query latency for dashboards. However, BI Engine operates on reserved capacity, reintroducing the provisioning decisions that BigQuery's serverless model otherwise eliminates.
Redshift approaches real-time analytics through zero-ETL integrations with Amazon Aurora and DynamoDB, which replicate operational data into the warehouse with minimal latency and no hand-rolled pipeline. If you are already running transactional workloads on those databases, this is an elegant path to near-real-time analytics without additional infrastructure. Redshift also supports streaming ingestion directly from Amazon Kinesis Data Streams, materializing a stream into a table incrementally. You can however face limitations from real-time query performance as it depends heavily on how well you have configured the underlying cluster.
Where both platforms converge on their limits is relationship-intensive queries: the kind that real-time fraud detection, network analysis, recommendation engines, and increasingly AI agents require. These workloads depend on traversing relationships across multiple entities at depth. In graph terms, they are multi-hop traversals; and both BigQuery and Redshift handle them through repeated joins or recursive CTEs that degrade progressively with each additional hop. At sufficient traversal depth, queries that take seconds in a graph-native execution model can stretch to 15–30 minutes in SQL, or fail outright with batch timeouts before returning a result. This limitation is one reason organizations increasingly augment warehouses with graph-based access patterns: not to replace systems like BigQuery or Redshift, but to make deeply connected data easier to traverse and reason about for analytics and AI workloads.
BigQuery vs Redshift for Data Warehousing
Data warehousing is the native domain of both platforms, but they differ across several dimensions.
For ingestion, BigQuery accepts batch loads from Google Cloud Storage natively, and its Transfer Service supports scheduled ingestion from a broad range of sources without additional pipeline infrastructure. Redshift's ingestion story centers on COPY commands from S3, and zero-ETL integrations with Aurora and DynamoDB for operational data. Both platforms support dbt for transformation, which has become the de facto standard for warehouse-layer modeling; neither has a meaningful advantage here.
In schema design, Redshift requires engineers to reason about distribution styles and sort keys at table creation; these decisions propagate forward and are expensive to reverse at scale. BigQuery's schema management is considerably more forgiving; it supports schema evolution natively, and engineers rarely need to think about physical data layout. However, without partitioning and clustering defined explicitly, query costs on large tables escalate quickly.
You will also see differences in concurrency and workload management at enterprise scale. BigQuery absorbs concurrent query spikes without configuration, which makes it tractable for large, heterogeneous analyst populations running ad hoc queries simultaneously. Redshift's WLM (Workload Management) system allows engineers to define query queues, allocate memory per queue, and prioritize workloads, a powerful but operationally demanding mechanism. You can opt for automatic WLM, but organizations with complex, mixed workloads frequently find manual WLM configuration necessary to preclude resource contention between long-running ETL jobs and latency-sensitive dashboard queries.
Data sharing has become a first-class feature on both platforms. BigQuery's Analytics Hub allows datasets to be published and subscribed to across organizational boundaries without data movement: a clean model for multi-team or multi-tenant architectures. Redshift Data Sharing provides analogous functionality within and across AWS accounts, enabling live query access to another cluster's data without copying it. Both implementations reflect the broader industry shift toward zero-copy data architectures.
Beyond the Warehouse: Adding Semantics to SQL Systems
Choosing between BigQuery and Redshift solves the infrastructure question, but it does not fully solve the data access problem. Even in well-designed warehouse environments, organizations still face a separate challenge: making data understandable, consistent, and usable across applications, analytics systems, and increasingly, AI agents.
This issue becomes more visible as data ecosystems grow. Warehouses such as BigQuery and Redshift are optimized for storage efficiency and analytical performance, but their schemas primarily describe physical organization rather than business meaning. Tables, foreign keys, and JOIN paths explain how data is stored, yet they do not always express how entities actually relate in the real world.
A semantic layer helps address this gap.
The Role of a Semantic Layer
A semantic layer sits above existing SQL systems and exposes business concepts directly, such as Customer, Order, Product, or Transaction. Instead of forcing applications or AI systems to reason through raw tables and joins, the semantic layer provides a higher-level logical model aligned with business meaning.
This allows developers and AI agents to work with data more naturally, without changing the underlying warehouse or database infrastructure.
Ontology and Ontology Enforcement
At the core of many semantic layers is an ontology: a formal definition of entities, relationships, and rules across the data environment.
An ontology defines:
- what entities exist,
- how they relate to one another,
- and what relationships are valid.
For example, a Customer may place an Order, an Order may contain a Product, and a Supplier may provide that product.
Ontology enforcement ensures that queries and updates across SQL systems respect these rules. Whether data originates from an application, an analyst, or an AI agent, operations can be validated against the semantic model to prevent inconsistent or logically invalid relationships.
Why It Matters: From Semantic Fog to Agentic Clarity
Without a semantic layer, complexity often shifts into application code, transformation pipelines, and orchestration logic, making systems progressively harder to maintain as they grow.
For AI systems, this challenge becomes even more significant. Large language models and autonomous agents can become trapped in semantic fog: navigating inconsistent schemas, ambiguous joins, and unclear relationships across tables. This can produce operations that are syntactically correct but logically wrong.
An AI agent may successfully generate a SQL query or connect two entities, yet create a relationship that does not exist in the real world.
Ontology enforcement acts as a semantic guardrail, ensuring that AI-generated reads and writes follow a validated model of how data entities interact. This reduces silent failures and improves trust in automated systems.
It also creates a feedback loop for self-correction. Instead of returning only technical database errors, ontology-aware systems can provide structured semantic feedback explaining why a query or update violates business logic. Over time, this helps AI systems refine how they interact with enterprise data environments.
Data Access with AI Assistants
Moving beyond storage architecture, graph-based semantic layers provide a way to access and query existing SQL data as connected knowledge, without requiring organizations to migrate everything into a native graph database.
This allows developers and AI systems to explore relational data through graph-style reasoning and relationship-aware retrieval while preserving the existing warehouse foundation.
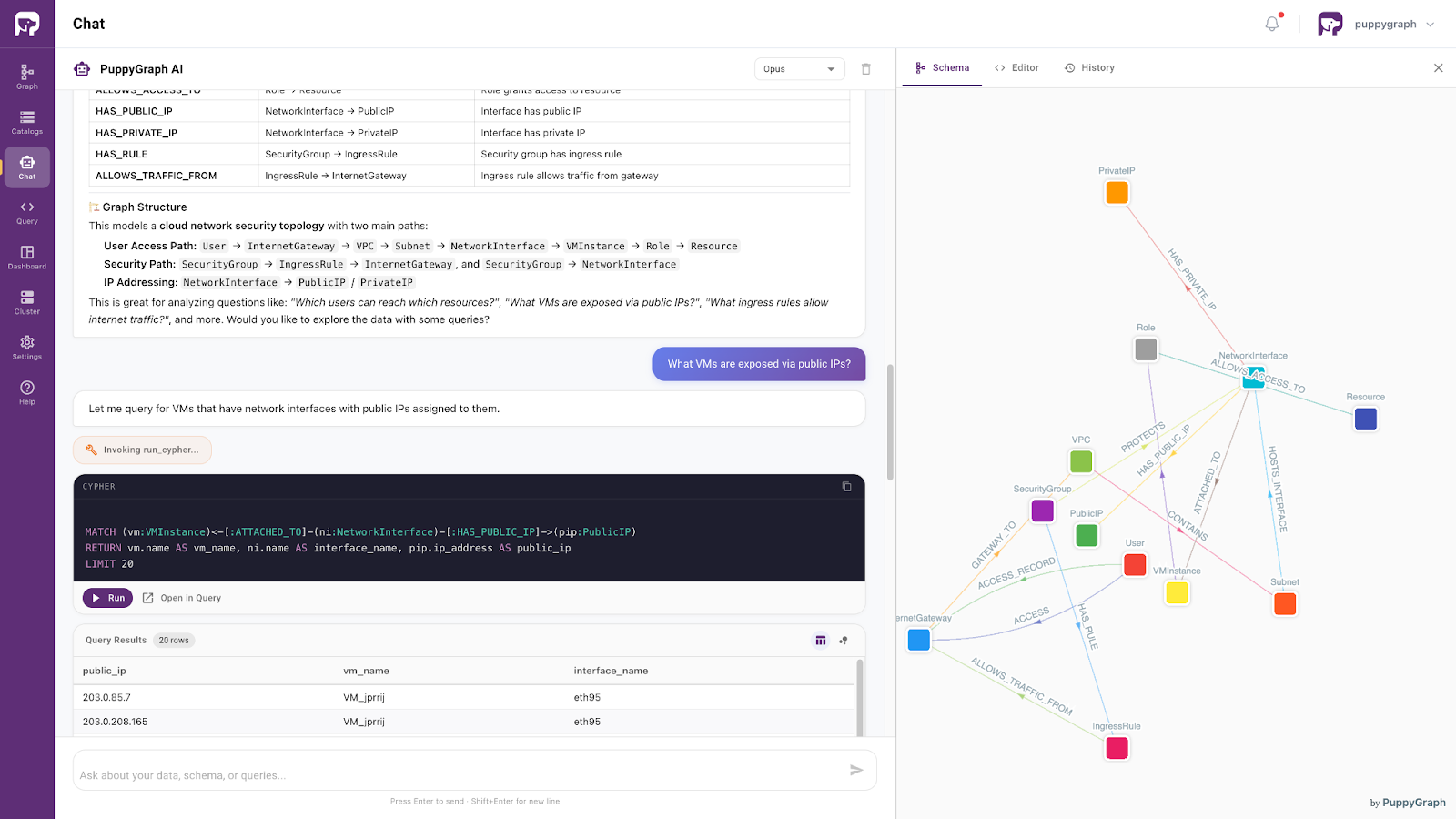
Powered by the same ontology-enforced model, this approach supports more precise and context-aware access to enterprise data. Rather than forcing AI systems to infer relationships from fragmented schemas and repeated joins, the semantic layer exposes validated relationships directly.
As a result, enterprise data evolves from a passive storage layer into an active semantic layer: one that preserves consistency while enabling more reliable search, analytics, and next-generation AI agents.
Conclusion
BigQuery and Redshift are both mature, highly capable cloud data warehouses, but they reflect different architectural philosophies. BigQuery prioritizes simplicity, elasticity, and minimal operational overhead through a serverless design, making it well suited for exploratory analytics, bursty workloads, and teams with limited infrastructure resources. Redshift, by contrast, emphasizes control, predictable performance, and deep AWS integration, rewarding organizations willing to invest in tuning and workload management for stable, high-volume operations.
Yet infrastructure alone does not solve the broader challenge of understanding and accessing enterprise data. As organizations increasingly rely on AI-driven analytics and automation, semantic layers and ontology enforcement become critical for providing consistent, relationship-aware access to data. Together, these technologies help transform warehouses from passive storage systems into intelligent, semantically governed foundations for modern analytics and AI applications.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see how ontology-enforced graph semantics can bring faster, more intelligent, and relationship-aware access to your existing BigQuery or Redshift data.

Matt is a developer at heart with a passion for data, software architecture, and writing technical content. In the past, Matt worked at some of the largest finance and insurance companies in Canada before pivoting to working for fast-growing startups.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install