

What is Clustering Architecture?
Modern computing systems are under constant pressure to deliver higher availability, better performance, and stronger fault tolerance. As applications scale and user expectations grow, single-server architectures often become bottlenecks or single points of failure. This is where clustering architecture emerges as a powerful solution. By connecting multiple computers to work together as a unified system, clustering architecture enables organizations to build resilient, scalable, and high-performance infrastructures capable of handling demanding workloads.
Clustering architecture is widely used across industries, from enterprise IT systems and cloud platforms to scientific computing and artificial intelligence. It allows workloads to be distributed, failures to be absorbed gracefully, and resources to be utilized more efficiently. Unlike traditional standalone systems, clusters are designed to behave like a single logical machine, even though they are composed of multiple independent nodes.
This article provides a comprehensive exploration of clustering architecture. It explains its fundamental concepts, core components, operational mechanisms, and different architectural types. It also compares clustering with distributed architecture, examines its importance in AI and machine learning workloads, and discusses the challenges involved in implementation. By the end, you will have a deep understanding of why clustering architecture plays a critical role in modern computing systems.
What Is Clustering Architecture?
Clustering architecture is a system design approach in which multiple independent computers, known as nodes, are connected and coordinated to function as a single unified system. These nodes collaborate to perform tasks, share workloads, and provide redundancy. From the perspective of users or applications, the cluster appears as one logical machine, even though it is physically distributed across multiple servers.
At its core, clustering architecture focuses on improving availability, scalability, and performance. If one node fails, other nodes can continue operating, ensuring minimal disruption. This fault-tolerant behavior makes clustering architecture especially valuable for mission-critical systems such as databases, financial platforms, healthcare applications, and telecommunications networks.
Clustering architecture differs from simple parallel computing because it emphasizes coordination and failover in addition to performance. Nodes in a cluster often share storage, communicate through high-speed networks, and are managed by specialized cluster management software. These elements allow the system to balance loads dynamically, detect failures automatically, and recover services without human intervention.
In practical terms, clustering architecture enables organizations to grow their computing capacity incrementally. Instead of replacing a single powerful server, administrators can add more nodes to the cluster, making the architecture both cost-effective and flexible. This modular nature is one of the key reasons clusters are so widely adopted in modern IT environments.
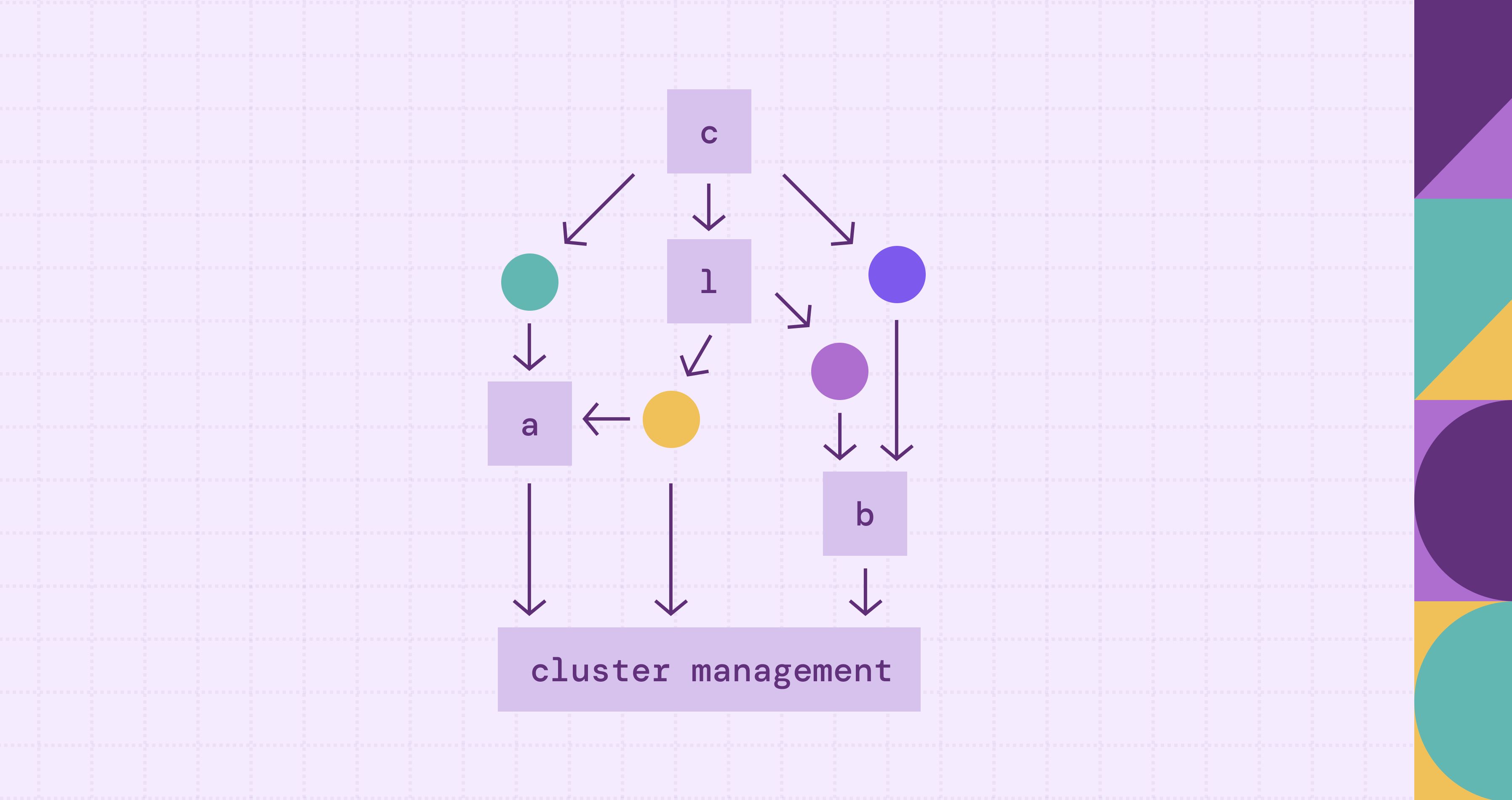
Key Components of Clustering Architecture
Clustering architecture is built on several foundational components that work together to deliver reliability and scalability. Each component plays a specific role, and the effectiveness of the cluster depends on how well these elements are integrated and configured. Understanding these components is essential for designing and managing a robust cluster.
Cluster Nodes
Cluster nodes are the individual computers or servers that form the cluster. Each node typically has its own CPU, memory, operating system, and local storage. Nodes can be physical machines, virtual machines, or containers, depending on the deployment model. In a well-designed clustering architecture, nodes are often homogeneous to simplify management and ensure predictable performance.
Nodes communicate continuously to coordinate tasks, share state information, and monitor health. If one node becomes unresponsive or fails, the remaining nodes can detect the issue and redistribute workloads. This cooperative behavior is fundamental to achieving high availability and fault tolerance within a cluster.
Network Infrastructure
The network is the backbone of clustering architecture, enabling fast and reliable communication between nodes. High-speed, low-latency networks are crucial, especially in performance-sensitive clusters such as those used for AI training or real-time data processing. Common technologies include Ethernet, InfiniBand, and software-defined networking solutions.
A robust network design ensures that heartbeat signals, data transfers, and synchronization messages are delivered efficiently. Network redundancy is often implemented to prevent single points of failure. Without a reliable network, even the most powerful nodes cannot function effectively as a cohesive cluster.
Shared Storage Systems
Many clustering architectures rely on shared storage to maintain data consistency across nodes. Shared storage allows multiple nodes to access the same datasets, configuration files, or application states. This is particularly important in high-availability clusters where workloads may move between nodes during failover events.
Shared storage can be implemented using network-attached storage (NAS), storage area networks (SAN), or distributed file systems. Modern clusters increasingly adopt software-defined storage solutions that scale alongside compute resources. Properly designed storage systems ensure data integrity, high throughput, and low latency.
Cluster Management Software
Cluster management software is responsible for orchestrating the entire system. It monitors node health, manages resource allocation, coordinates failover processes, and enforces cluster policies. Examples include Kubernetes, Apache Mesos, and traditional high-availability managers such as Pacemaker.
This software layer abstracts the complexity of the underlying infrastructure, allowing administrators to manage the cluster as a single entity. It also provides automation capabilities, which reduce manual intervention and improve operational efficiency. Without effective management software, clustering architecture would be difficult to scale or maintain.
How Clustering Architecture Works
Clustering architecture operates through continuous coordination among its nodes, networks, and management layers. The system is designed to maintain a consistent operational state, even in the presence of hardware failures or workload spikes. This is achieved through a combination of monitoring, communication, and automated decision-making.
At startup, each node joins the cluster and registers its resources with the cluster manager. The manager maintains a global view of available CPU, memory, storage, and network capacity. Applications or services deployed on the cluster are then scheduled based on predefined policies, such as load balancing or resource affinity. This ensures efficient utilization of all available nodes.
A key mechanism in clustering architecture is the heartbeat signal. Nodes periodically send heartbeat messages to indicate that they are alive and functioning correctly. If a node stops sending heartbeats, the cluster manager interprets this as a failure. In response, workloads running on the failed node are automatically restarted or migrated to healthy nodes.
This coordinated process allows clustering architecture to provide seamless failover and consistent performance. Users interacting with the system are often unaware that a failure has occurred, highlighting the transparency and resilience of well-designed clusters.
Types of Clustering Architecture
Clustering architecture can be classified into several types based on its primary purpose and operational characteristics. Each type addresses specific requirements, such as availability, performance, or load distribution. Choosing the right type depends on the nature of the workload and business objectives.
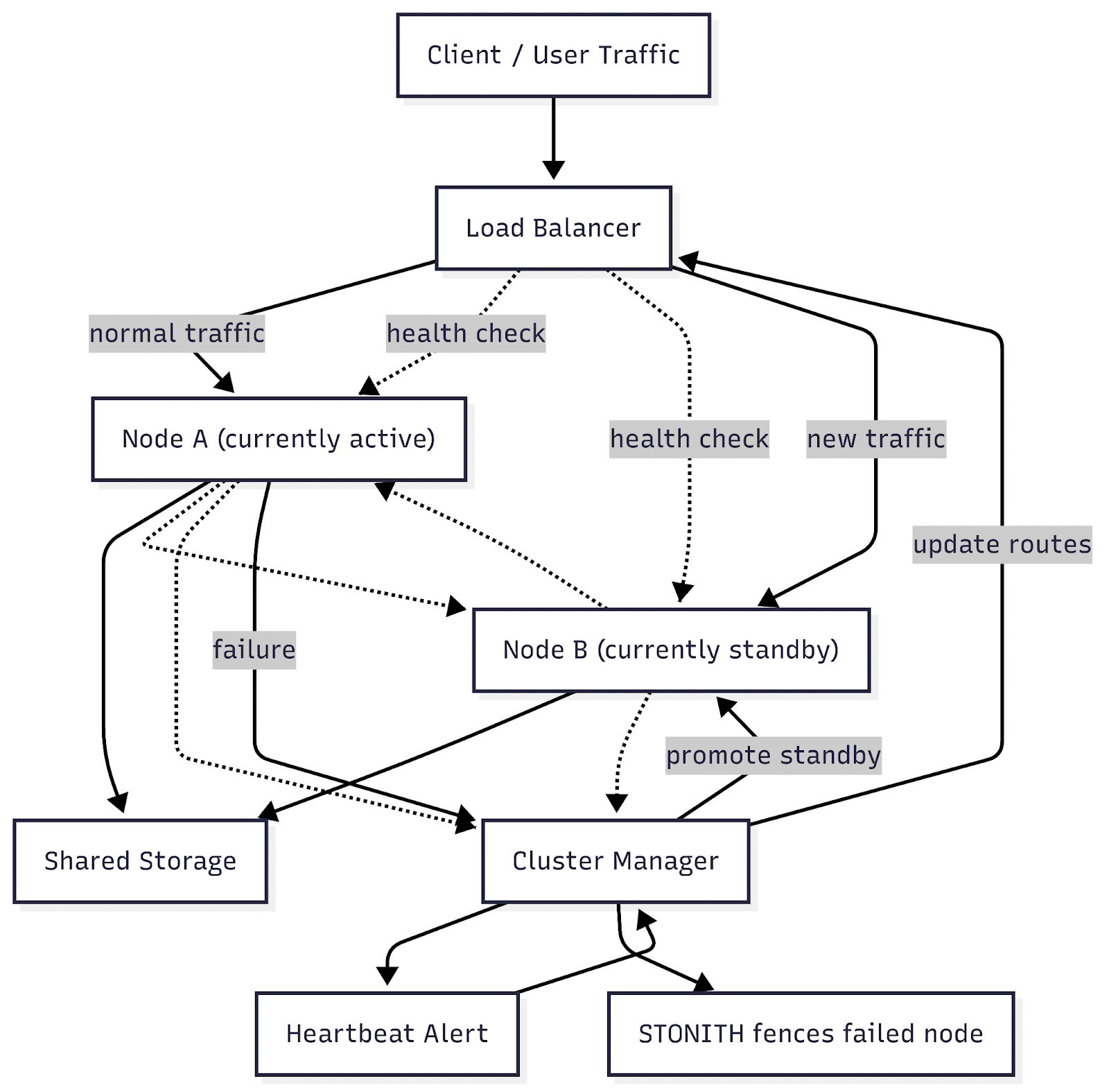
High-Availability Clusters
High-availability (HA) clusters are designed to minimize downtime by providing automatic failover capabilities. In an HA cluster, critical services run on one or more active nodes while standby nodes remain ready to take over if a failure occurs. This ensures continuous service availability even during hardware or software failures.
HA clusters are commonly used in enterprise environments for databases, application servers, and transactional systems. They prioritize reliability over raw performance, making them ideal for workloads where downtime is unacceptable. Redundant components and rigorous monitoring are hallmarks of this clustering architecture type.
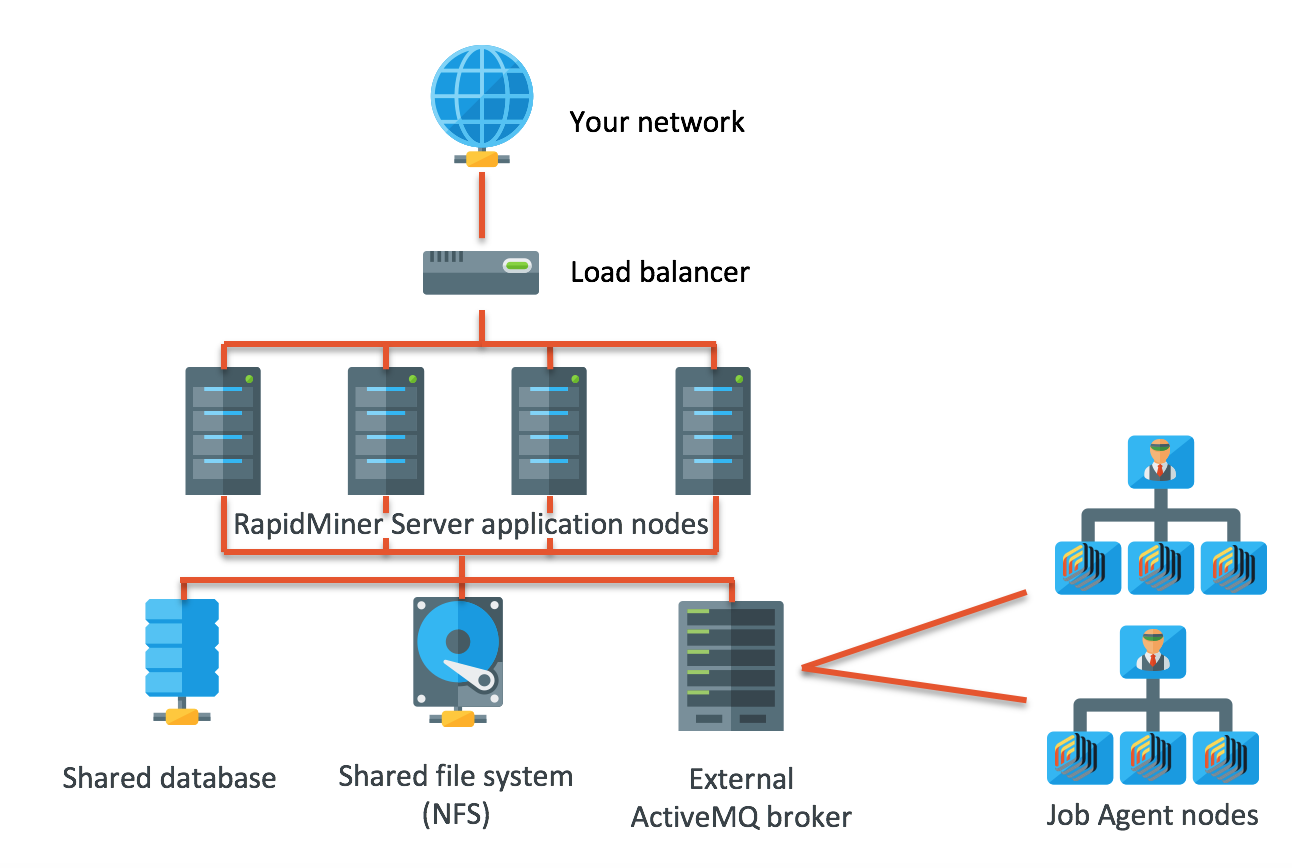
Load-Balancing Clusters
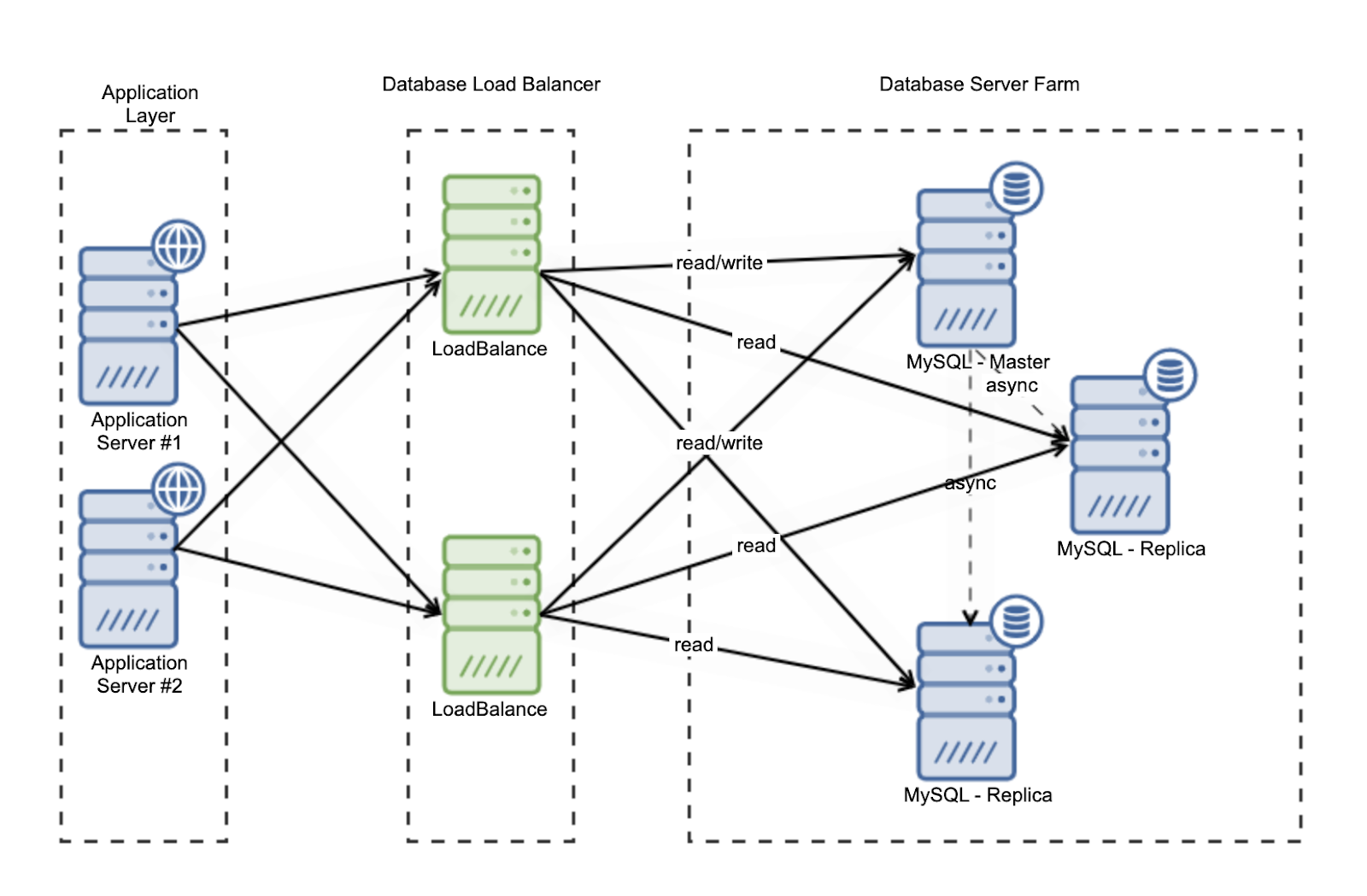
Load-balancing clusters distribute incoming requests or workloads evenly across multiple nodes. This approach improves performance, responsiveness, and scalability by preventing any single node from becoming overloaded. Load balancers can operate at various layers, including the network and application levels.
These clusters are widely used for web services, APIs, and cloud-based applications. As demand increases, additional nodes can be added to handle the load. Load-balancing clusters are particularly effective in environments with fluctuating traffic patterns and high concurrency requirements.
High-Performance Computing Clusters
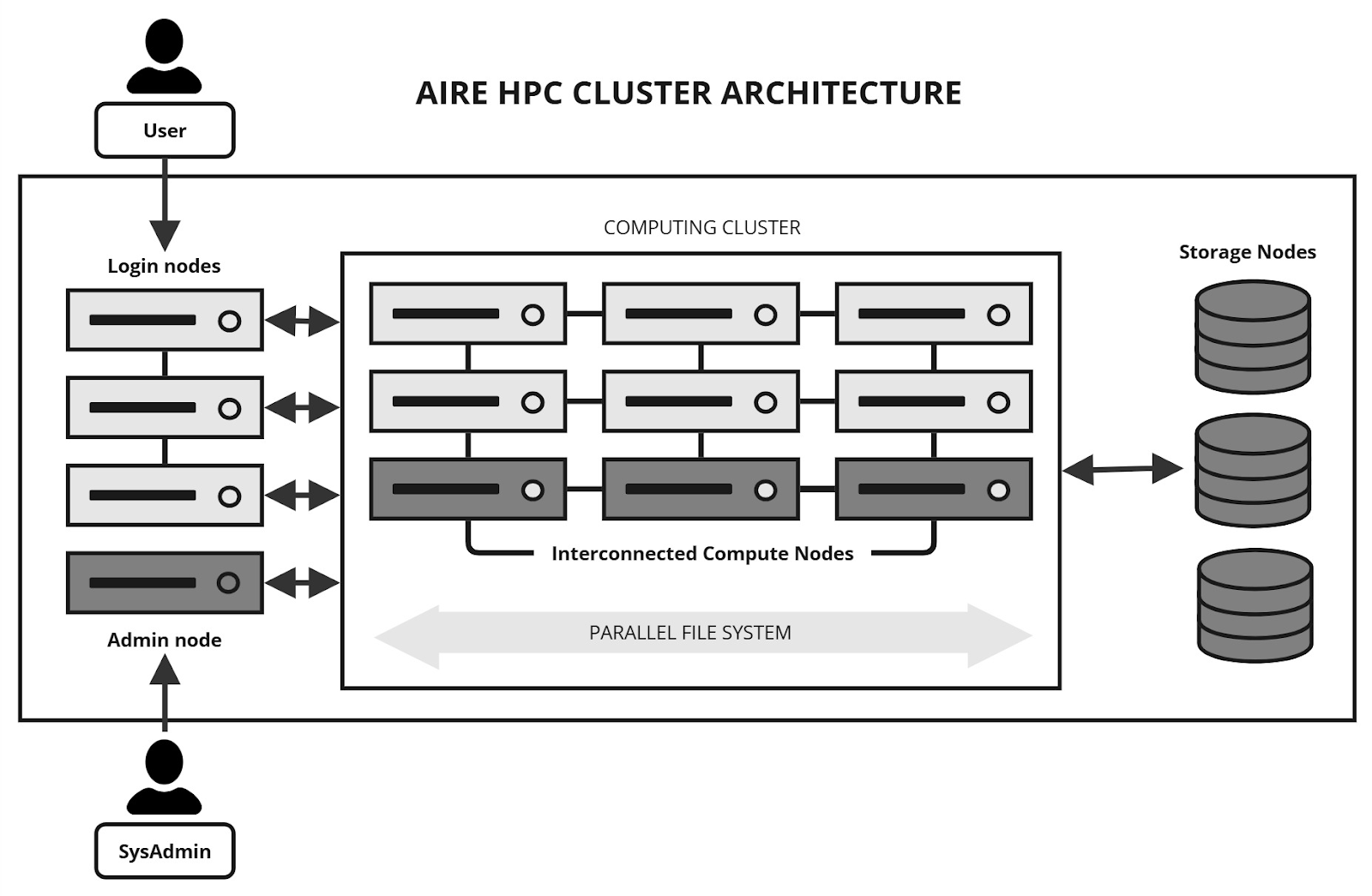
High-performance computing (HPC) clusters focus on maximizing computational power for complex calculations and simulations. They are commonly used in scientific research, engineering, weather modeling, and financial analysis. HPC clusters emphasize parallel processing and low-latency communication.
In this type of clustering architecture, workloads are divided into smaller tasks that run simultaneously across multiple nodes. Specialized interconnects and optimized software libraries are often employed to achieve maximum performance. Fault tolerance may be less emphasized compared to performance efficiency.
Storage Clusters
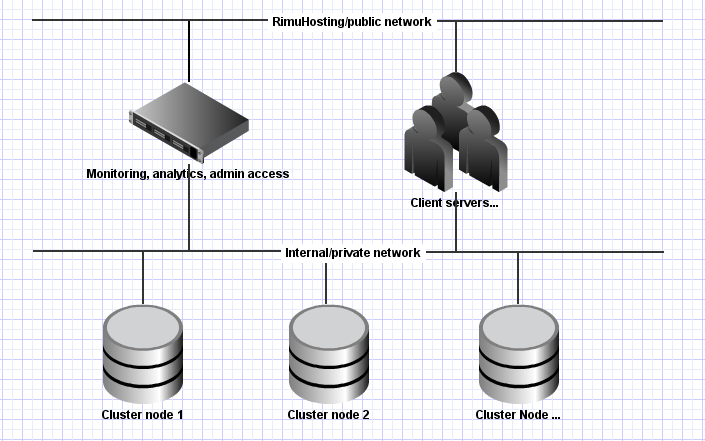
Storage clusters aggregate the storage capacity of multiple nodes to create a scalable and resilient data storage system. Data is typically replicated or distributed across nodes to ensure durability and availability. Examples include distributed file systems and object storage platforms.
Storage clusters are essential for big data analytics, backup solutions, and cloud storage services. They allow organizations to scale storage independently of compute resources while maintaining high levels of data protection and accessibility.
Clustering Architecture vs Distributed Architecture
Clustering and distributed architectures are related but distinct concepts. Both involve multiple computing nodes collaborating to perform tasks, yet they differ significantly in design philosophy, node autonomy, and operational goals. Understanding these differences is crucial for selecting the appropriate architecture based on requirements such as scalability, availability, and fault tolerance.
Comparison Table
Key Notes
- Subset Relationship: Clustering architecture can be considered a subset of distributed architecture. All clusters are distributed to some degree, but not all distributed systems form a cluster.
- Node Autonomy: Distributed systems emphasize independent operation and modularity, whereas clustering focuses on coordinated operation and high availability.
- Hybrid Architectures: Modern cloud platforms often combine both principles, clusters operate within a single data center for low-latency high-availability, while distributed principles coordinate across multiple regions or zones.
Clustering Architecture for AI and ML Workloads
Clustering architecture plays a crucial role in supporting artificial intelligence and machine learning workloads. These workloads are computationally intensive, data-heavy, and often require parallel processing across multiple nodes. Clusters provide the scalability and performance needed to train complex models efficiently.
In AI and ML environments, clusters are commonly equipped with specialized hardware such as GPUs or TPUs. These accelerators are distributed across nodes and coordinated to perform parallel training tasks. Clustering architecture enables frameworks like TensorFlow and PyTorch to scale training jobs across multiple devices seamlessly.
Data management is another critical aspect. Large datasets must be accessible to all nodes in the cluster with minimal latency. Distributed storage systems integrated into the cluster ensure that training data and model checkpoints are readily available. This reduces bottlenecks and improves overall training throughput.
Clustering architecture also supports fault tolerance during long-running training jobs. If a node fails, the system can recover from checkpoints and continue training without restarting from scratch. This reliability is essential for production-grade AI pipelines, where training runs may take days or weeks to complete.
Challenges of Implementing Clustering Architecture
Despite its many advantages, clustering architecture introduces several challenges that organizations must address. These challenges span technical, operational, and organizational domains, and they can impact the success of a cluster deployment if not properly managed.
One major challenge is complexity. Designing, configuring, and maintaining a cluster requires specialized knowledge and careful planning. Issues such as network latency, data consistency, and synchronization can be difficult to troubleshoot. As clusters grow in size, this complexity increases, demanding more sophisticated management tools and processes.
Cost is another important consideration. While clustering architecture can be cost-effective in the long term, initial investments in hardware, networking, and software can be significant. High-performance clusters, in particular, may require expensive interconnects and accelerators. Organizations must balance performance requirements against budget constraints.
Security also becomes more complex in clustered environments. Multiple nodes, shared resources, and dynamic workloads increase the attack surface. Proper authentication, encryption, and access controls are essential to protect sensitive data and services. Without strong security practices, clusters can become vulnerable to breaches and misconfigurations.
Finally, operational challenges such as monitoring, upgrades, and capacity planning require ongoing attention. Effective automation and observability tools are critical to managing these challenges and ensuring that the cluster continues to meet business needs.
Leveraging Infrastructure Graphs
To help manage the complexity of clustered systems, many organizations turn to infrastructure graphs. These are specialized graph-based models that represent nodes, services, workloads, and their interconnections within a cluster as a unified network of entities and relationships. By capturing dependencies explicitly, these graphs provide a clear, real-time view of how components interact, communicate, and rely on each other.
For observability, such knowledge graphs are particularly valuable: they enable multi-hop analysis of service dependencies, highlight bottlenecks, and facilitate root-cause detection across complex infrastructures. They also allow engineers to correlate logs, metrics, and traces in a meaningful way, turning scattered telemetry into actionable insights. In cybersecurity, these graphs can help identify vulnerable pathways, detect unusual interactions, and map potential attack surfaces, providing a structured foundation for threat analysis and response.
In short, infrastructure graphs make clustered systems more transparent and manageable, giving teams the ability to reason about performance, reliability, and security in a coherent, relationship-centric way.
Building Infrastructure Graphs with PuppyGraph
In practice, the effectiveness of infrastructure graphs depends largely on how easily they can be created, continuously updated, and integrated with existing data systems. Traditional approaches often require heavy data duplication, custom ETL pipelines, or offline graph construction, which can limit freshness and increase operational complexity. As clustered environments evolve rapidly, teams need a way to reason over infrastructure relationships without introducing yet another isolated data store.
PuppyGraph builds on this graph-based approach by constructing a live, logical representation of clustered systems directly from existing data sources. It maps cluster components and their relationships into a queryable graph model, enabling real-time, multi-hop analysis across relational databases or data lakes, without duplicating data or building ETL pipelines. By querying the logical cluster network in place, PuppyGraph helps teams uncover bottlenecks, analyze dependencies, and optimize distributed workloads, while maintaining data consistency and reducing operational overhead.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.




Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Clustering architecture is a cornerstone of modern computing, enabling organizations to build scalable, resilient, and high-performance systems. By coordinating multiple nodes as a single logical entity, clusters provide high availability, fault tolerance, and efficient resource utilization, making them essential for enterprise IT, cloud platforms, scientific computing, and AI workloads. Whether through high-availability, load-balancing, HPC, or storage clusters, this architecture supports complex, data-intensive applications while minimizing downtime and performance bottlenecks.
PuppyGraph enhances clustering management by providing real-time, zero-ETL graph insights across existing databases and data lakes. By mapping nodes, services, and workloads into a unified queryable model, PuppyGraph simplifies dependency analysis, performance optimization, and security monitoring. Together, clustering architecture and infrastructure graph platforms empower organizations to handle modern workloads efficiently, gain deeper operational visibility, and extract actionable insights from complex systems without costly overhead.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install