

What Is Context Engineering? Complete Guide

Large language models (LLMs) have rapidly evolved from research prototypes into core components of modern AI applications. As organizations increasingly deploy AI assistants, chatbots, and autonomous agents, attention is shifting from model capabilities alone to the information provided during inference. In many real-world systems, model performance depends not only on reasoning ability but also on access to relevant, accurate, and timely information. This growing need has led to the emergence of context engineering as a critical discipline in AI development.
Context engineering focuses on designing, organizing, and delivering the information that an AI system uses to generate responses. It encompasses prompts, retrieved knowledge, memory, conversation history, tool outputs, and external data sources. By ensuring that models receive the right information at the right time, context engineering improves accuracy, reduces hallucinations, and enables scalable AI systems. This article explores the principles, components, applications, and future directions of context engineering in modern AI environments.
What Is Context Engineering?
Context engineering is the practice of designing, collecting, organizing, and delivering information that helps an AI model perform a specific task effectively. In large language model applications, context refers to everything the model can access during a conversation or inference request. This includes prompts, retrieved documents, user preferences, conversation history, tool outputs, system instructions, and external knowledge sources.
Unlike traditional software systems that rely on fixed logic, LLMs generate responses based on the information available within their context window. The quality, relevance, and structure of that context directly influence the quality of the model’s output. As a result, context engineering focuses on maximizing the usefulness of information presented to the model while minimizing noise and irrelevant content.
A useful way to think about context engineering is to compare it with human problem-solving. A highly skilled employee cannot perform effectively if they lack access to relevant documents, customer history, project requirements, or organizational policies. Similarly, an AI model may possess strong reasoning capabilities but still produce poor results if it lacks sufficient context.
Modern AI systems increasingly depend on dynamic context rather than static training data. Instead of retraining models whenever information changes, organizations can retrieve and inject fresh information during inference. This approach enables AI applications to remain accurate and up to date while reducing operational costs and development complexity.
Why Context Engineering Matters for AI Systems
Many AI failures are not caused by model limitations but by context failures. When models hallucinate, misunderstand user intent, or provide outdated information, the underlying issue is often insufficient or poorly structured context rather than inadequate reasoning capabilities.
Context engineering helps address these challenges by ensuring models receive relevant information before generating responses. By carefully controlling what information enters the context window, developers can significantly improve factual accuracy, consistency, and task completion rates.
Consider an enterprise customer support assistant. Without access to internal documentation, product specifications, and customer account history, the assistant may provide generic or incorrect answers. However, when context engineering techniques retrieve relevant documents and customer data in real time, the same model can generate highly accurate and personalized responses.
Context engineering also plays a crucial role in reducing hallucinations. Large language models are designed to generate plausible text, even when they lack knowledge about a topic. Providing trustworthy supporting information allows the model to ground its responses in factual sources rather than relying solely on statistical patterns learned during training.
As context windows continue to expand, organizations may assume that simply providing more information will solve the problem. In reality, larger context windows often introduce new challenges. Excessive information can overwhelm the model, dilute important signals, and increase inference costs. Effective context engineering therefore focuses on relevance and precision rather than volume alone.
Context Engineering vs Prompt Engineering
Prompt engineering and context engineering are closely related but fundamentally different disciplines. Prompt engineering focuses on crafting instructions that guide model behavior. Context engineering encompasses the broader process of managing all information available to the model.
Prompt engineering emerged during the early stages of LLM adoption. Developers discovered that changing wording, formatting, or examples within prompts could significantly influence model outputs. Techniques such as chain-of-thought prompting, role assignment, and few-shot examples became common practices for improving performance.
Context engineering extends beyond prompt design. It includes retrieving external knowledge, managing memory, integrating tools, filtering documents, maintaining conversation state, and orchestrating information flows across complex systems. In many modern AI applications, prompt engineering represents only one component of a larger context engineering strategy.
The distinction becomes particularly important in enterprise environments. A prompt alone cannot provide access to proprietary databases, customer records, or operational systems. Context engineering enables these resources to be dynamically incorporated into model interactions.
The relationship between the two concepts can be summarized as follows:
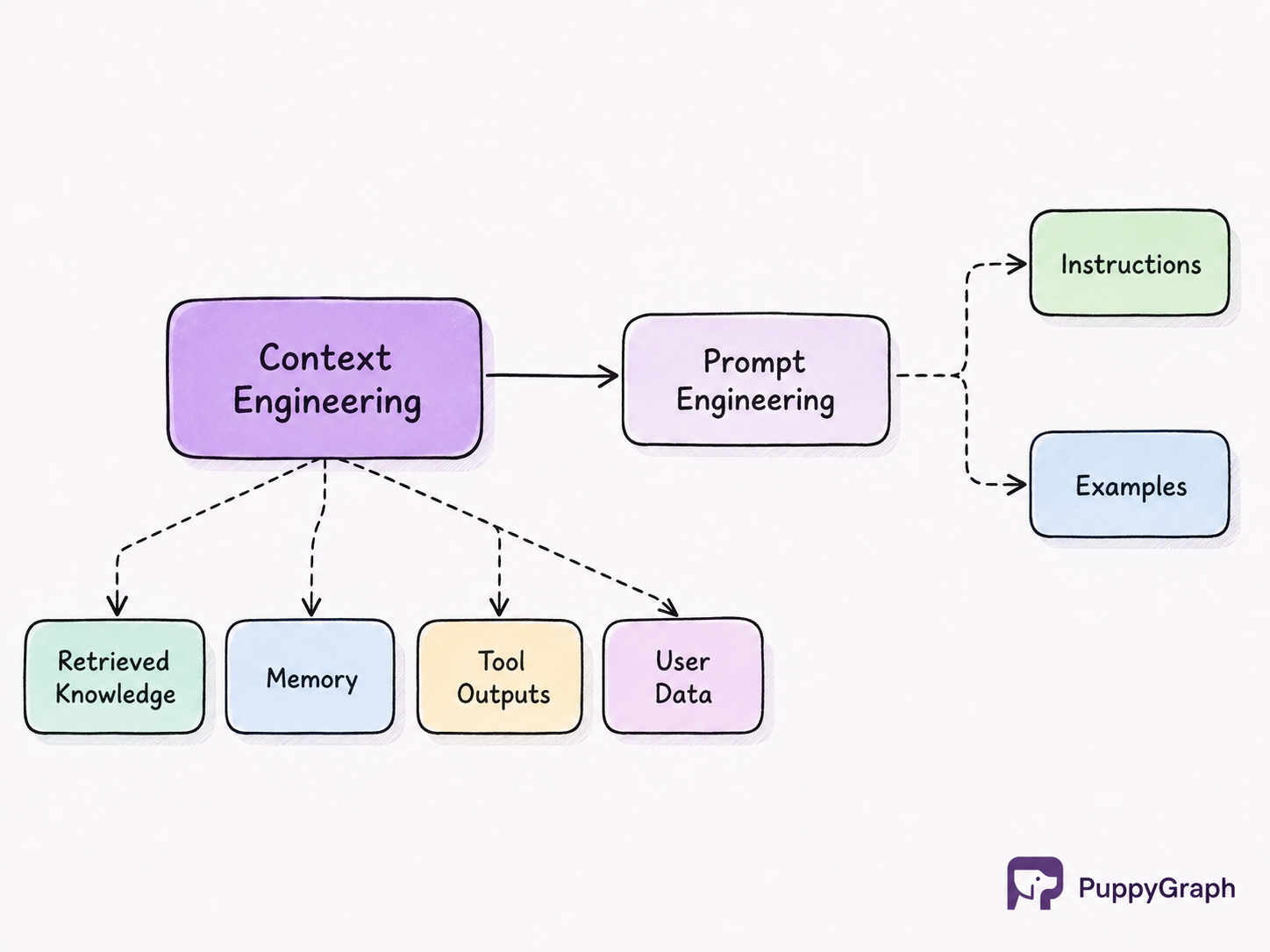
Prompt engineering influences how information is interpreted. Context engineering determines what information is available in the first place. As AI applications become more sophisticated, the importance of context engineering continues to grow.
The Building Blocks of Context Engineering
Effective context engineering relies on several interconnected components. Together, these elements create the information environment that supports model decision-making and response generation.
System Instructions
System prompts establish high-level behavioral rules and operational boundaries. They define the assistant’s role, communication style, safety constraints, and objectives. These instructions serve as a foundation upon which other contextual information is layered.
User Inputs
User messages provide immediate task requirements and intent signals. Understanding user goals is essential because context selection should align with the specific problem being addressed. Context that is useful for one task may be irrelevant for another.
External Knowledge Sources
Most production AI systems connect to external data repositories such as knowledge bases, document collections, databases, APIs, and business systems. These sources provide fresh information that extends beyond the model’s training cutoff date.
Conversation History
Maintaining relevant conversation history enables continuity across interactions. The model can reference previous discussions, user preferences, and ongoing tasks without requiring repeated explanations.
Tool Outputs
Modern AI systems frequently interact with external tools. Search engines, calculators, code interpreters, workflow systems, and APIs generate outputs that become part of the model’s working context. Properly incorporating these outputs can dramatically improve task performance.
Each component contributes unique information. Context engineering involves determining which components should be included, how they should be structured, and when they should be updated during execution.
How Context Engineering Works in Practice
In production environments, context engineering typically follows a multi-stage workflow. Rather than sending raw user input directly to a model, AI systems often construct context dynamically before each inference request.
A common workflow begins with user input analysis. The system identifies user intent, extracts key entities, and determines what information may be needed. This step guides subsequent retrieval and context assembly processes.
Next, the system retrieves relevant information from available knowledge sources. These sources may include vector databases, enterprise documentation, CRM systems, internal APIs, or previous conversations. Retrieval algorithms rank information according to relevance and importance.
After retrieval, the system filters and compresses information to fit within token limitations. Redundant content is removed, important facts are prioritized, and formatting may be optimized for model consumption.
The final stage involves assembling context into a structured prompt. Instructions, retrieved knowledge, memory, tool outputs, and user messages are combined into a coherent context package that supports response generation.
The process can be visualized as follows:
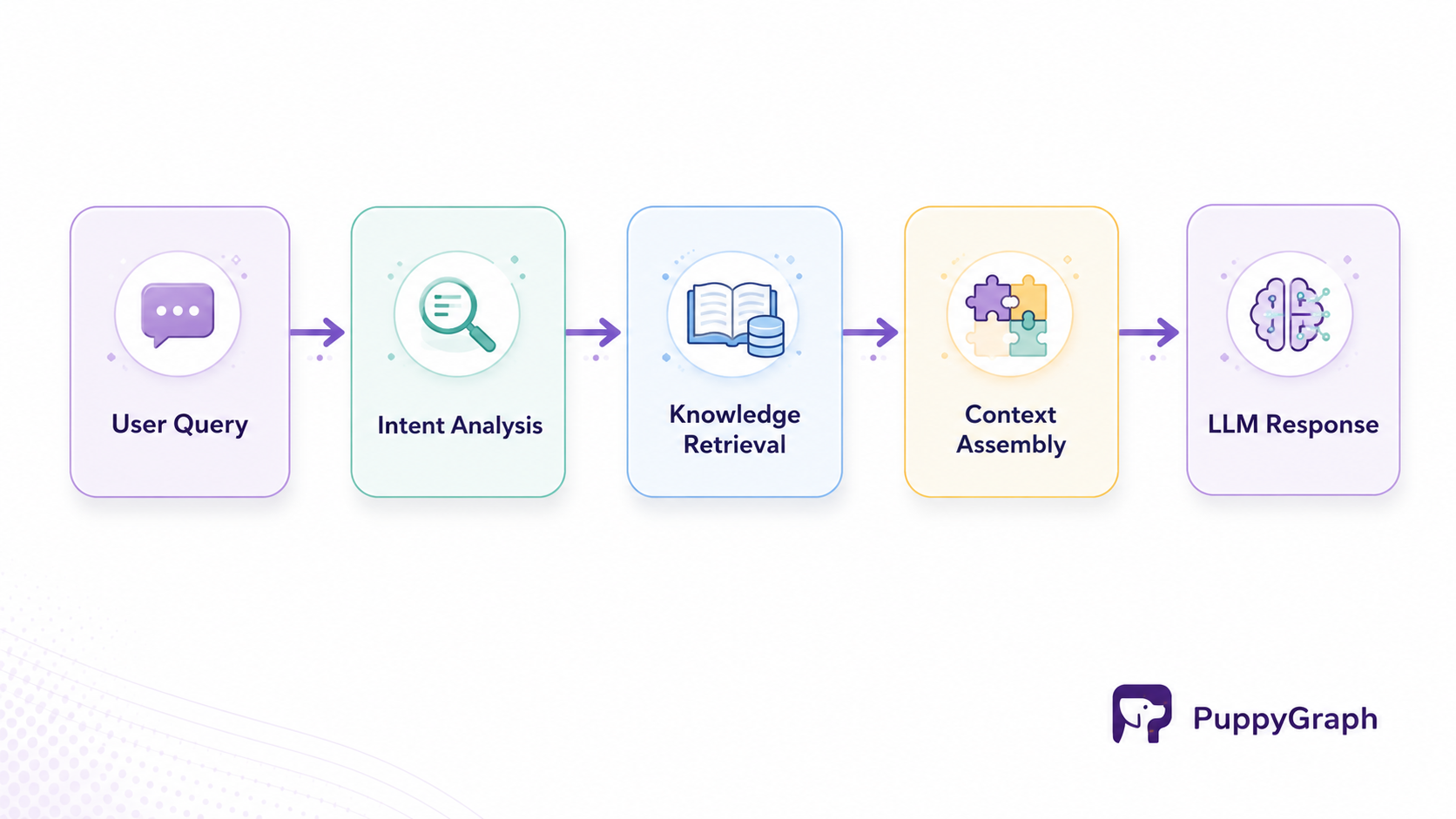
This workflow enables AI systems to adapt dynamically to changing information needs while maintaining efficiency and accuracy.
Retrieval-Augmented Generation (RAG) and Context Engineering
Retrieval-Augmented Generation (RAG) has become one of the most influential approaches in modern AI development. At its core, RAG is a context engineering technique that supplements model reasoning with external knowledge retrieval.
Traditional language models rely solely on information learned during training. As knowledge evolves, these models may become outdated. RAG addresses this limitation by retrieving relevant documents during inference and incorporating them into the context window.
The effectiveness of a RAG system depends heavily on context engineering decisions. Choosing which documents to retrieve, determining how many passages to include, ranking sources, and formatting retrieved information all influence response quality.
Poor retrieval can lead to irrelevant context that confuses the model. Excessive retrieval may consume valuable token space. Insufficient retrieval can leave critical knowledge unavailable. Successful RAG implementations therefore require careful optimization of retrieval pipelines and context construction mechanisms.
Organizations increasingly use RAG to connect AI systems with proprietary information sources. Examples include customer support documentation, financial reports, medical literature, legal databases, and software development repositories. Because information remains external, updates can occur without retraining the underlying model.
Memory Management in AI Applications
Memory management represents another critical aspect of context engineering. As AI systems engage in longer interactions, maintaining relevant information becomes increasingly important.
Human conversations rely heavily on memory. Participants remember previous discussions, preferences, and shared experiences. AI systems require similar capabilities to deliver coherent and personalized interactions.
Short-term memory typically consists of recent conversation history stored within the context window. This information helps maintain continuity during ongoing interactions. However, context windows remain limited resources, making efficient memory management essential.
Long-term memory involves storing important information outside the context window and retrieving it when needed. Examples include user preferences, historical interactions, project details, and recurring behavioral patterns. Rather than preserving every message, systems selectively retain information with lasting relevance.
Effective memory systems must balance retention and relevance. Storing excessive information increases retrieval complexity and introduces noise. Storing too little information reduces personalization and continuity. Context engineering techniques help determine what information should be remembered, forgotten, summarized, or retrieved.
As AI assistants become integrated into daily workflows, robust memory management will increasingly differentiate effective systems from generic conversational interfaces.
Context Engineering for AI Agents
AI agents represent one of the most demanding applications of context engineering. Unlike traditional chatbots, agents must reason, plan, take actions, monitor outcomes, and adapt to changing environments.
Agent workflows often involve multiple steps spanning extended periods. During execution, agents accumulate observations, tool results, intermediate reasoning outputs, and task progress information. Managing this growing information landscape requires sophisticated context engineering strategies.
An agent tasked with conducting market research may search websites, analyze documents, summarize findings, generate reports, and revise conclusions based on new evidence. Throughout this process, the agent must maintain awareness of objectives, constraints, previous actions, and relevant discoveries.
Context engineering enables agents to operate effectively by selectively maintaining information relevant to current decision-making. Rather than continuously processing all accumulated data, agents retrieve and prioritize context according to task requirements.
Multi-agent systems introduce additional complexity. Different agents may possess specialized roles and unique knowledge domains. Context must be shared appropriately across agents while avoiding unnecessary duplication and communication overhead.
As autonomous AI systems become more common, context engineering will play an increasingly central role in enabling reliable agent behavior.
Techniques for Optimizing Context Quality
High-quality context does not emerge automatically. Organizations must actively design and optimize context pipelines to maximize performance and efficiency.
One important technique is relevance filtering. Retrieved information should directly support the task being performed. Removing unrelated content reduces distraction and helps models focus on essential information.
Context compression is another valuable approach. Summarization techniques can preserve key facts while reducing token usage. This allows systems to incorporate larger knowledge bases without exceeding context limitations.
Semantic ranking improves retrieval quality by prioritizing documents that are conceptually related to user intent. Advanced ranking systems often combine keyword matching, embedding similarity, metadata filtering, and reranking models.
Chunking strategies significantly influence retrieval performance. Large documents are typically divided into smaller segments before indexing. Well-designed chunks preserve semantic meaning while enabling precise retrieval.
Evaluation frameworks are equally important. Teams should measure retrieval accuracy, context relevance, hallucination rates, and task success metrics. Continuous evaluation enables iterative improvements and helps identify weaknesses in context pipelines.
The most successful AI applications treat context engineering as an ongoing optimization process rather than a one-time implementation task.
Future Trends in Context Engineering
As language models continue to advance, context engineering will evolve alongside them. Larger context windows, multimodal inputs, and agentic workflows are already reshaping how information is managed.
Future systems will likely combine text, images, audio, video, and structured data within unified contextual environments. Context engineering will therefore extend beyond textual retrieval into multimodal knowledge orchestration.
Adaptive context systems may dynamically determine which information should be retrieved based on changing objectives and environmental conditions. Rather than relying on fixed pipelines, these systems will continuously optimize context composition during execution.
Research is also exploring model architectures with enhanced memory capabilities. While such advances may reduce certain limitations, they are unlikely to eliminate the need for context engineering. Information selection, prioritization, and orchestration will remain essential challenges regardless of context window size.
Ultimately, context engineering is becoming a foundational layer of AI infrastructure, comparable to databases in traditional software systems. Organizations that master this discipline will be better positioned to build scalable, trustworthy, and intelligent applications.
From Information Retrieval to Semantic Context
As organizations scale AI applications, improving retrieval quality alone is often not enough. Even when relevant information can be found, another challenge remains: ensuring that AI systems consistently understand what that information means and how different pieces of knowledge relate to one another.
This challenge becomes increasingly important in enterprise environments, where information is distributed across databases, documents, APIs, knowledge bases, and operational systems. While retrieval pipelines can surface relevant content, the underlying data often lacks a unified representation of business meaning. Different systems may describe the same concepts using different schemas, identifiers, or terminology, making it difficult for AI systems to reason reliably across sources.
As context engineering matures, many organizations are discovering that effective context is not only about retrieving information, but also about organizing knowledge into a coherent semantic structure that AI systems can understand and use consistently. This is where semantic layers and ontology-driven approaches become increasingly valuable.
The Role of a Semantic Layer
A semantic layer sits above existing data and knowledge systems and exposes business concepts directly, such as Customer, Order, Product, Employee, Project, or Transaction. Instead of forcing applications or AI systems to reason through fragmented schemas, disconnected documents, or system-specific representations, the semantic layer provides a higher-level logical model aligned with business meaning.
This allows developers and AI agents to work with organizational knowledge more naturally, without requiring fundamental changes to the underlying data infrastructure. More importantly, it provides a consistent semantic foundation for context construction across different AI workflows.
Ontology and Ontology Enforcement
At the core of many semantic layers is an ontology, a formal definition of entities, relationships, and rules across the enterprise knowledge environment.
An ontology defines:
- what entities exist,
- how they relate to one another,
- and what relationships are valid.
For example, a Customer may place an Order, an Order may contain a Product, and a Supplier may provide that product. These relationships represent business reality rather than implementation details hidden inside individual systems.
Ontology enforcement ensures that queries, retrieval operations, and AI-generated actions respect these rules. Whether information originates from databases, documents, APIs, analysts, or AI agents, interactions can be validated against the semantic model to prevent inconsistent or logically invalid relationships from entering the context pipeline.
Why It Matters: From Context Overload to Semantic Clarity
Without a semantic layer, context engineering often becomes an exercise in assembling increasingly large amounts of information and hoping the model can infer the correct relationships.
For AI systems, this can create a form of semantic overload. Large language models may receive relevant documents, database records, and tool outputs, yet still struggle to determine how entities relate to one another or which interpretations are correct. The result is often reasoning that appears plausible but fails to align with business reality.
An AI agent may successfully retrieve the necessary information and generate a syntactically correct response while still drawing incorrect conclusions from ambiguous or inconsistent context.
Ontology enforcement acts as a semantic guardrail. It provides an explicit representation of how entities interact, helping AI systems reason within a validated model of the organization’s knowledge domain. This improves consistency across retrieval, reasoning, and action execution while reducing subtle semantic errors that are difficult to detect through retrieval quality alone.
It also creates a valuable feedback mechanism for AI systems. Instead of receiving only retrieval failures or application errors, agents can receive structured semantic feedback explaining why a proposed action, inference, or relationship violates domain rules. This enables more effective self-correction and supports the development of increasingly reliable autonomous systems. Over the longer term, such semantic feedback may also serve as a reward signal for fine-tuning or reinforcement learning, helping AI systems align more closely with organizational rules and domain knowledge.
Context Engineering with Knowledge Graphs
Moving beyond traditional retrieval architectures, knowledge graphs provide a natural way to represent semantic context as connected knowledge rather than isolated pieces of information.
PuppyGraph enables organizations to build graph-based semantic layers directly on top of existing data sources, allowing AI applications to explore relationships across enterprise knowledge without requiring data migration into a dedicated graph database.
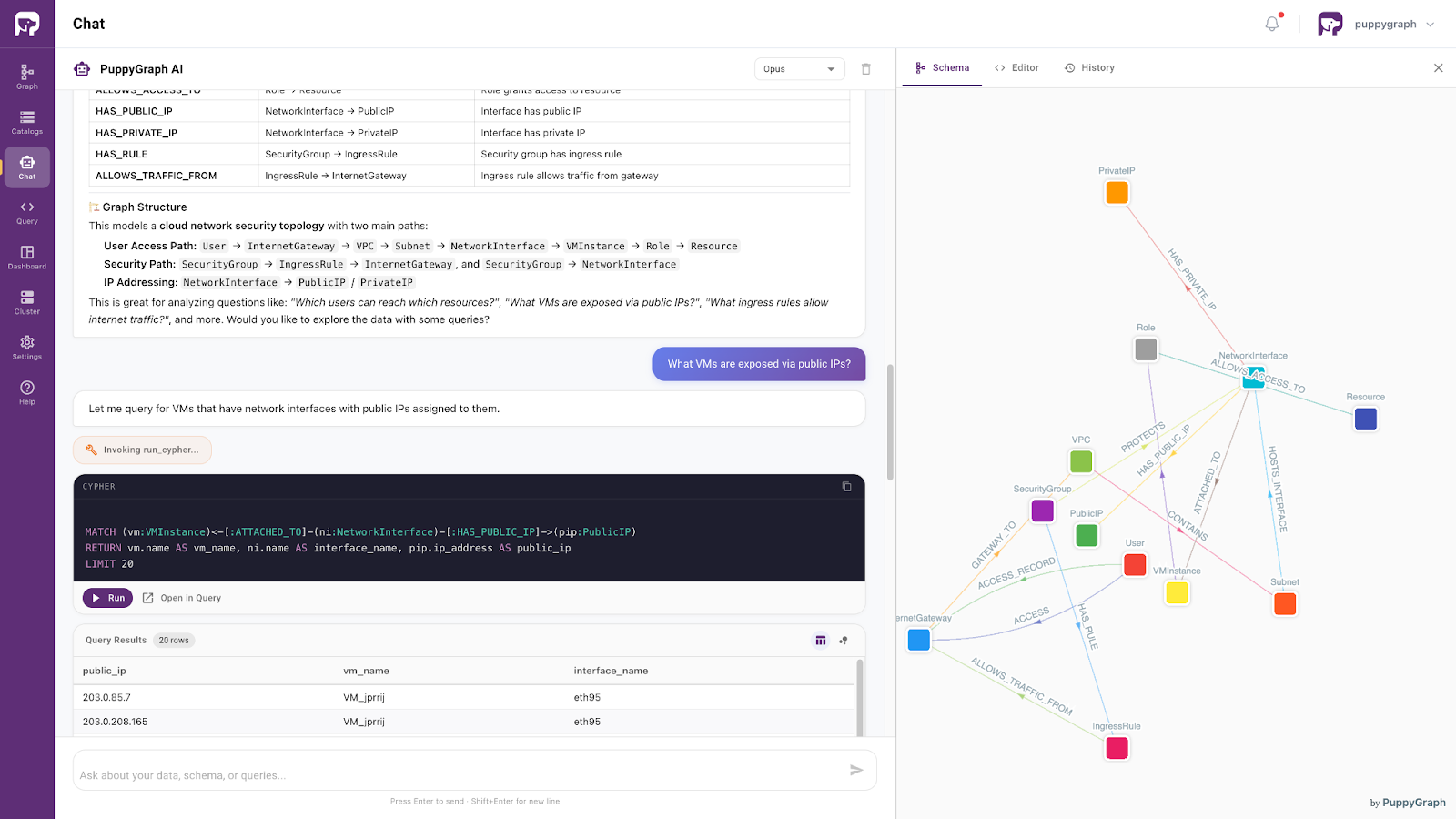
Powered by ontology-aware graph representations, this approach enables context engineering systems to retrieve not only relevant information, but also the relationships that connect it. AI agents can reason over entities, dependencies, and business structures in ways that are difficult to achieve through document retrieval alone.
As AI systems become increasingly agentic, semantic context will play a growing role in ensuring reliability and trustworthiness. Rather than treating context as a collection of isolated inputs, organizations can transform enterprise knowledge into a connected semantic foundation that supports retrieval, reasoning, decision-making, and autonomous action.
Conclusion
Context engineering has emerged as a foundational discipline for building reliable AI systems. Rather than focusing solely on model capabilities, it emphasizes delivering the right information at the right time through retrieval, memory management, tool integration, and context optimization. As AI applications become increasingly complex, effective context engineering plays a critical role in improving accuracy, reducing hallucinations, and enabling scalable, production-ready systems. The evolution of techniques such as RAG and agent memory further highlights the growing importance of context as a core component of AI infrastructure.
Looking ahead, the future of context engineering will extend beyond information retrieval toward semantic understanding. Semantic layers, ontologies, and knowledge graphs provide AI systems with structured representations of business knowledge, enabling more consistent reasoning and trustworthy decision-making. By combining context engineering with graph-based semantic technologies such as PuppyGraph, organizations can transform fragmented enterprise data into connected, actionable knowledge, creating a stronger foundation for the next generation of intelligent and autonomous AI systems. Explore the forever-free PuppyGraph Developer Edition, or book a demo to see semantic context engineering in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install