

What is Continuous Threat Exposure Management?

Continuous Threat Exposure Management (CTEM) is a proactive cybersecurity framework introduced by Gartner in 2022. It is not a one-time initiative. CTEM runs as an ongoing program that keeps focus on the exposures that matter, validates impact, and assigns clear owners. It asks teams to view their environment from two angles: how it is built and operated, and how an adversary might navigate it.
CTEM integrates data from threat intelligence, vulnerability management, cloud posture, identity entitlements, and security telemetry, then maps those signals to attack paths and business risk. Teams can stop chasing every critical finding, and instead focus on exposures that matter most to the organization, such as verified paths to sensitive systems and externally exploitable weaknesses. The result is a measurable, threat-informed practice that matches the pace of cloud change and stays well-aligned with business goals.
In this blog, we will define what CTEM is and walk through a step-by-step framework you can run for each critical service. We will cover benefits, trade-offs, and how CTEM compares to traditional methods.
What is Continuous Threat Exposure Management?
CTEM is a cybersecurity framework, not a product. It runs as an ongoing program with five stages: scoping, discovery, prioritization, validation, and mobilization. It continuously monitors your attack surface to identify exploitable paths with business context, focusing on what is important and reachable to an adversary. Just as important, CTEM creates a company playbook for response. It defines who does what, when, and how fixes are verified, tying security tools to a repeatable process with clear owners, SLAs, and evidence of closure. The result is a structured, proactive way to find threats and remediate the ones that matter most.
How Does Continuous Threat Exposure Management Work
CTEM runs as a repeatable loop. Each stage has a clear purpose so teams can find real risk, prove it matters, and get fixes into production.
- Scoping: Define the business service, the risks to tackle this cycle, and the in-scope boundaries so work aligns with priorities and owners.
- Discovery: Build a factual picture inside that scope by joining assets, identities, configs, controls, and findings into a single view of exposures.
- Prioritization: Cut the list to a small, actionable set of fixes by ranking items with context such as impact, exploitability, reachability, and control gaps.
- Validation: Prove the top items are real in your environment and confirm the planned changes break the path an attacker would use.
- Mobilization: Route validated items to the right teams, deliver changes through normal workflows, and verify outcomes with evidence.
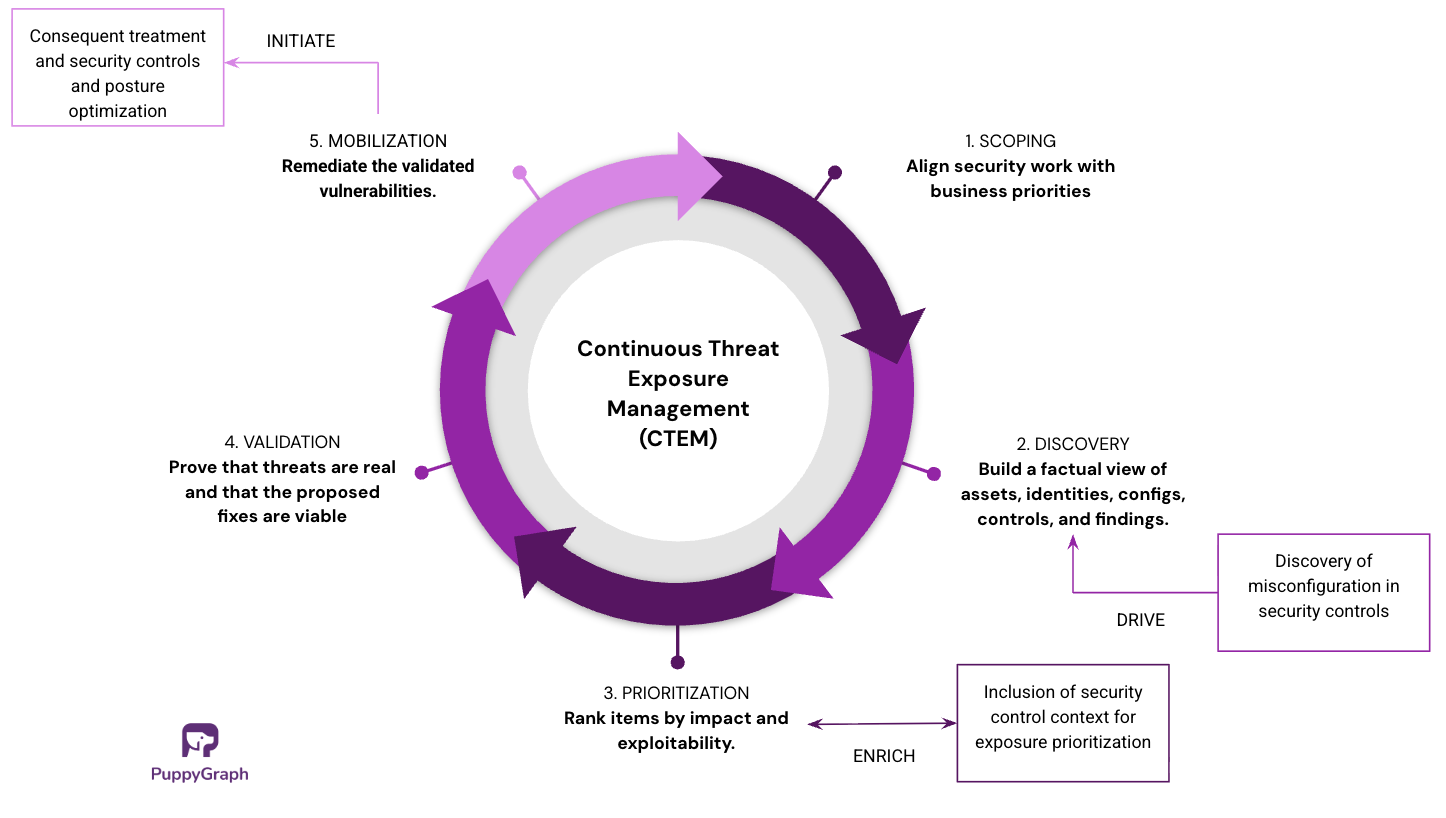
Continuous Threat Exposure Management Framework
In this section, we walk through each CTEM stage with the key considerations to keep in mind. Use tooling to speed data collection, enrich context, and automate routine steps, but keep people in the loop for scope decisions, risk trade-offs, and production changes. The goal is a smooth, repeatable program that combines human judgment with targeted automation.
Scoping
Scoping names the business service to protect and explains why it matters now. This step is pivotal for executive buy-in because it clearly states which systems you will protect first and why. A sharp scope aligns security work with revenue, uptime, and compliance priorities, which unlocks sponsorship and resources.
In this stage, you’ll gather the facts that anchor decisions on what to defend first. Look at business criticality, data sensitivity, and any revenue or uptime dependencies. Note change windows, SLAs, and compliance requirements that define what is feasible in this cycle. These inputs keep scope practical and aligned with the people who own the service.
You finish scoping with a short scope statement tied to one business service, a list of target risks with expected business impact, and the named approvers and change constraints for this cycle.
Discovery
Discovery builds a factual picture inside the agreed scope. At this point, confirm which accounts and environments are in play. Pull asset and identity lists, key configurations, control coverage, and scanner findings. Capture owners and basic business context for major components.
This should be treated as a cross-team effort. Involve security plus a few key partners such as IT, DevOps, and the service owners so findings have context and a clear home. The discovery process should yield a de-duplicated inventory, a joined view that links findings to assets and owners, a short list of obvious red flags, and a gap list to improve next cycle.
Prioritization
Prioritization ranks what you found in Discovery by impact and exploitability so security teams know exactly where to start. A comprehensive asset inventory is essential because it provides the context to make the right calls:
- Presence: Which devices, identities, and apps are in scope.
- State: Current versions, configurations, and control health.
- Business context: Criticality, data sensitivity, and ownership.
- Mitigating controls: EDR, WAF, IAM policies, backups, and logging already in place.
That context changes priority. A high-severity CVE on an internet-facing system with weak controls rises to the top. The same CVE on an isolated host with strong monitoring, strict IAM, and no path to sensitive data falls down the list.
Stay aligned to business priorities and the company’s risk profile by weighing more than CVSS:
- Severity: Likely effect on confidentiality, integrity, and availability.
- Threat level: Known exploits, public PoCs, active scanning, or abuse in your telemetry.
- Exploitability: Ease of use given your configs, identities, and network paths.
- Business impact: Financial, operational, regulatory, and data sensitivity.
You should end up with a clear, ranked set of high-impact fixes with owners, rationale, target dates, and a simple success check for each item.
Validation
You want to ask concrete questions to test plausibility. Then, after the “what-if” fixes land, re-test the path and keep monitoring to confirm the control continues to work over time, recording any residual risk and applying temporary mitigations if a full fix is not feasible.
At this stage, attack graphs and attack path analysis help visualize likely routes to sensitive systems and confirm that proposed changes remove them. Breach and attack simulation lets you run safe, scripted technique tests to prove exploitability. You can also use targeted penetration tests or red team exercises to provide focused proof on critical paths in realistic conditions.
For each item, you should have a pass or fail decision with evidence, the agreed change or mitigation and residual-risk notes.
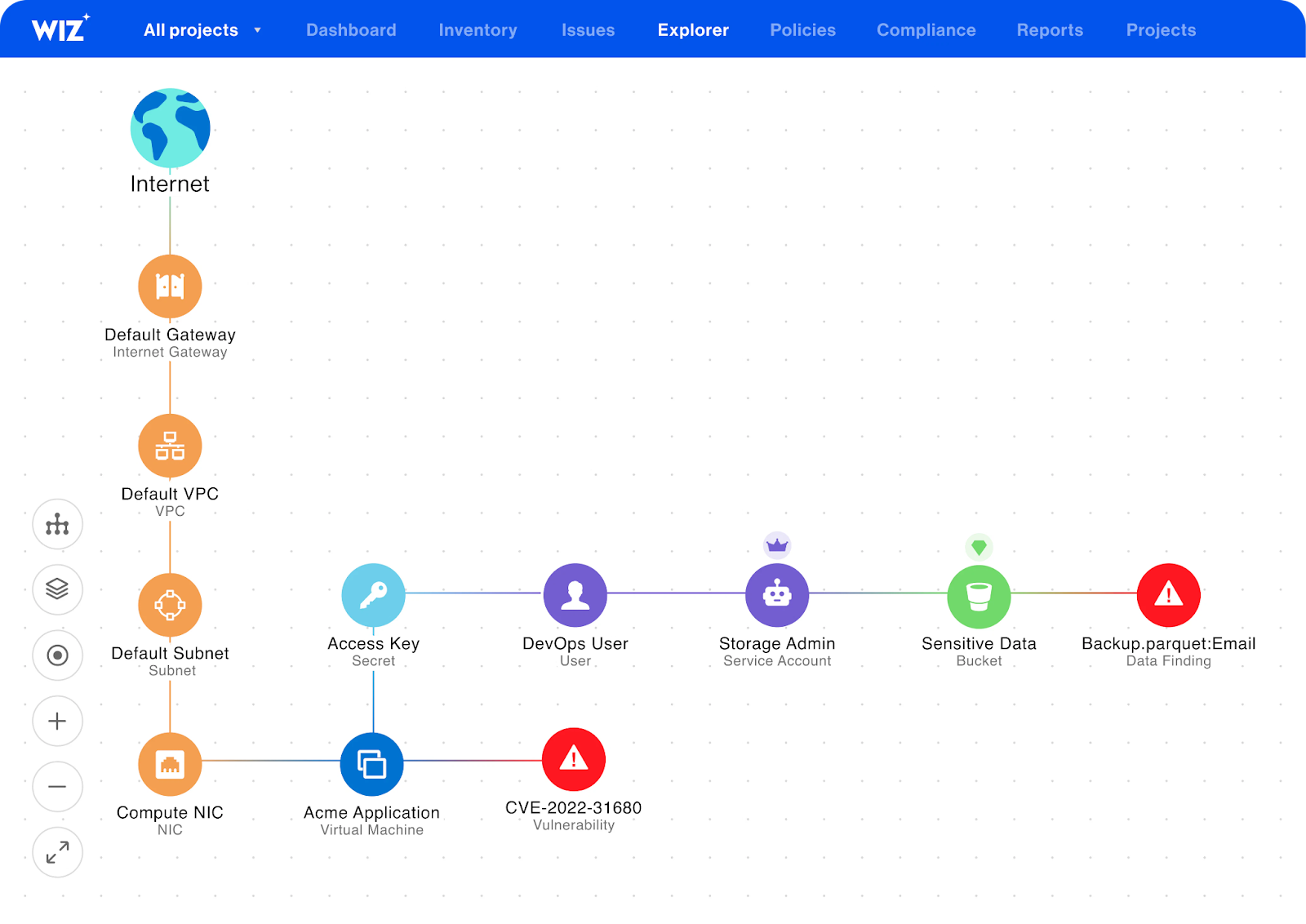
Mobilization
Mobilization turns validated findings into implemented changes, routing each item to the right team, getting the fix shipped through normal delivery paths, and verifying that risk went down.
Having a playbook for mobilization can be quite helpful. It prevents confusion, speeds handoffs, and makes results repeatable. This includes clear ownership, realistic SLAs, and shared context to keep work moving. When teams understand why a change matters, they commit the time and sequence it correctly.
At the end, the fixes should be implemented with evidence attached, as well as trend reporting that shows fewer validated paths and improving posture over time.
Benefits of CTEM
The true value of CTEM comes from the program working as a whole, not any single tool. Here’s what organizations gain when CTEM is run well.
Higher Impact Fixes
An effective CTEM implementation allows security teams to focus on exposures that can actually hurt the business. With clear ownership, SLA targets and simple playbooks, the process of remediation is greatly streamlined. As fixes land faster, attacker opportunity shrinks and repeat findings drop. The result is visible risk reduction within each cycle.
Actionable Insights
CTEM involves unifying assets, identities, configs, and findings into one view so signals have context. Teams can see ownership, likely attack paths, and the specific change that removes the risk. This replaces alert-chasing with informed decisions and makes handoffs to remediation straightforward. Less guesswork, more targeted action.
Increased Adaptability
Security posture changes daily as cloud resources, identities, and configs shift. A CTEM cadence that re-scopes, re-ranks, and re-validates keeps priorities current. Continuous monitoring highlights new activity, while each cycle updates plans before drift becomes exposure. You stay aligned to reality, not last month’s inventory.
Security with Business Objectives
Work is scoped by business service, with outcomes measured against revenue, uptime, compliance, or data protection goals. Evidence shows how each fix shortens attack paths to crown jewel assets or eases audit burden. When the business impact is clear, sponsorship and resources follow, and teams stay aligned.
Audit-Ready Evidence
Every cycle generates artifacts that are easy to show and hard to dispute: the scope brief, the prioritization rationale, validation evidence, and post-fix verification. Dashboards and ticket trails tell the story end to end. This shortens audits, supports attestations, and proves progress to leadership.
CTEM vs Traditional Security Approaches
Traditional security programs grew around periodic activities like quarterly scans, annual pen tests, perimeter controls, and audit checklists. CTEM takes a different path: a continuous, service-scoped framework that uses context such as reachability, business impact, and control gaps to drive decisions.
Because Vulnerability Management (VM) is the baseline most teams already run, the shift from VM to CTEM is the most common starting point. Below is a quick look at how the two approaches differ.
Challenges & Considerations
While many organizations are considering the switch to the CTEM approach, implementing this framework comes with its own set of difficulties. It’s important to be aware of the common pitfalls that teams fall into.
Executive Buy-In & Scope Creep
CTEM usually starts with the CISO’s approval and sponsorship, since it reorders work across security and engineering teams. Without that backing, scope drifts and cycles devolve into open-ended inventory. Competing priorities such as uptime, release deadlines, audit dates, can also create tension over what to include now versus later, which is where scope creep commonly appears.
Data Privacy & Residency
Centralizing signals can move sensitive data across legal or contractual boundaries, especially in multi-region and SaaS-heavy environments. Ownership and access often fragment across teams and tools, creating shadow copies and unclear custodianship. Moving data introduces lag. ETL jobs, exports, and reviews delay detection and can leave prioritization working with stale context. Third-party integrations and evidence retention add risk, so decide up front what you collect, where it lives, who can see it, and how long you keep it.
Relationship-Aware Analysis
The core questions in CTEM are relational: who can reach what, through which paths, under current configurations. Most security signals already form a graph, but they live in relational tables that require costly joins, or in separate graph stores that need ETL and create duplicate data. Both patterns slow analysis and introduce inconsistencies across tools.
How PuppyGraph Can Help

PuppyGraph is the first real-time, zero-ETL graph query engine. It lets data teams query existing relational stores as a single graph and get up and running in under 10 minutes, avoiding the cost, latency, and maintenance of a separate graph database. PuppyGraph is not a traditional graph database but a graph query engine designed to run directly on top of your existing data infrastructure without costly and complex ETL (Extract, Transform, Load) processes. This "zero-ETL" approach is its core differentiator, allowing you to query relational data in data warehouses, data lakes, and databases as a unified graph model in minutes.
Here’s how PuppyGraph’s unified graph query engine can help with CTEM:
- Scoping: Quickly see which assets and identities sit closest to important systems, making the in-scope vs out-of-scope line clear.
- Discovery: Stitch findings, configurations, identities, and controls into one relationship view without heavy joins.
- Prioritization: Run graph queries that help to compute risk in context. Identify paths to sensitive data, internet exposure, blast radius, and missing controls.
- Validation: Run safe “what if” checks by virtually removing a role or tightening a policy, then confirm that attack paths disappear.
- Continuous monitoring: Replay key path queries on a cadence to catch regressions and produce audit-ready proof that risk went down.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.


Getting started is quick. Most teams go from deploy to query in minutes. You can run PuppyGraph with Docker, AWS AMI, GCP Marketplace, or deploy it inside your VPC for full control. Interested in building a Wiz-like security graph? Read our step by step tutorial guide or watch the tutorial video.
Conclusion
CTEM gives security teams a practical way to reduce real risk, letting organizations tackle security threats with a steady loop: scope a business service, discover what exists, prioritize with context, validate what is real, and mobilize fixes with clear owners and proof. The payoff is fewer noisy tickets, faster remediation, and evidence that attack paths to crown-jewel systems are shrinking over time.
A unified graph query engine is one tool that helps this loop run smoothly. Most security signals already describe relationships like who can reach what, through which paths, under current configs, but that context is hard to extract from scattered tables and one-off exports. With PuppyGraph, you can get to querying those relationships directly, without heavy joins or duplicate data stores.
Ready to try CTEM supported by a unified graph? Get started with PuppyGraph Developer Edition to run graph queries against your own data, or book a demo to see how PuppyGraph can help improve your organization’s security posture.

Jaz Ku is a Solution Architect with a background in Computer Science and an interest in technical writing. She earned her Bachelor's degree from the University of San Francisco, where she did research involving Rust’s compiler infrastructure. Jaz enjoys the challenge of explaining complex ideas in a clear and straightforward way.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install