

Cosmos DB vs Neo4j: How to Choose for Graph Workloads
As systems scale, relationships grow more complex while data models often stay the same. As entities multiply, the real complexity, and value, stems from how those entities connect.
Cosmos DB and Neo4j take different approaches to tackle this. While each has their merits, they also introduce genuine trade-offs.
The harder problem is supporting relationship-heavy queries on live data without fragmenting systems, pipelines, and governance. This article breaks down those trade-offs in concrete terms: data model, query behavior, scaling limits, and operational overhead, and demonstrates where a platform like PuppyGraph can offer a better solution.
What is Cosmos DB?

Azure Cosmos DB is Microsoft’s globally distributed, multi-model database service for applications that require low latency, elastic throughput, and multi-region availability. Cosmos DB exposes a unified storage and replication engine that supports different data models:
- Document (SQL API)
- Key-value (Table API)
- Column-family (Cassandra API)
- Graph workloads through the Gremlin API
For large-scale, geographically distributed systems, Cosmos DB can minimize operational friction by dint of all data models inheriting the same replication fabric, consistency guarantees, and throughput provisioning model.
Architecture Overview
Cosmos DB’s architecture concentrates on three aspects:
- Global distribution
- Horizontal partitioning
- SLA-backed performance
Data automatically replicates across Azure regions, allowing active–active writes or low-latency local reads. Partitioning is mandatory and determines distribution: each container is divided into logical partitions by a partition key, which maps to physical partitions internally. This matters for graph workloads since vertices and edges, which are stored as JSON documents, live inside these partitions and assume their locality properties.
Cosmos DB guarantees 99.999% availability for multi-region deployments. For single-region reads, p99 latency stays under 10 milliseconds in most consistency modes. Strong consistency is the exception because it requires cross-region synchrony, which raises latency.
Graph Model and Gremlin API
For graph workloads, Cosmos DB uses Apache TinkerPop’s property-graph model. It stores vertices and edges as documents, but adds internal metadata for adjacency fields (outE, inV, outV) to make traversals faster. These fields let local hops run without scanning every document, which a plain document store would struggle with, while still fitting into the larger multi-model design.
Cosmos DB doesn’t offer pointer-based, index-free adjacency like Neo4j. Traversals still run on a distributed document layer, so deep or cross-partition walks can trigger network hops and higher RU usage. The system thus intentionally favors global uptime and elastic scaling in lieu of a graph-only execution path.
The Gremlin API covers most of TinkerPop’s OLTP steps (V(), out(), has(), values(), and so on.). First vertex lookups use Cosmos DB’s automatic indexing. Later traversal steps depend on adjacency metadata and how well you have partitioned the data. Some advanced TinkerPop features, like lambdas, bytecode execution, and full match() support, are not available because of the distributed execution model.
Partitioning for Graph Workloads
Partitioning drives most of the performance behavior for graph workloads in Cosmos DB. Traversals that stay inside a single logical partition keep RU usage and latency low. When a query jumps across partitions, you pay extra RUs and take a network hit.
Here are some practical guidelines:
- Pick a high-cardinality partition key that matches how queries usually start (user ID, tenant ID, region).
- Avoid low-cardinality keys like “type” or “label”; they create hot partitions.
- Use hierarchical keys if your graph spans structured subdomains.
- Assess real traversal paths, not only data distribution, before choosing a key.
If the partition key doesn’t match your traversal patterns, you’ll see RU spikes and uneven latency, especially for multi-hop or neighborhood-style queries.
Consistency Guarantees
Cosmos DB provides five consistency levels:
- Strong
- Bounded staleness
- Session
- Consistent prefix
- Eventual
Session consistency is a good middle ground for most graph workloads. It gives read-your-own-writes without the latency penalty of strong consistency. If you prioritize ordering, you can choose a consistent prefix. For exploratory or large-scale graph queries, eventual consistency is usually fine.
These options let teams balance correctness and speed. This imports even more in multi-region setups because strong consistency forces cross-region round trips.
Performance Profile
Cosmos DB works best when graph operations sit alongside document or key-value access patterns, for example:
- User graphs tied to profile data
- Device and event graphs
- Metadata graphs affiliated to transactional systems
Traversals are fast when they stay shallow and within a single partition. Cost for deep or uneven graph shapes depends on partitioning and your RU budget.
Write performance remains predictable because RU/s hides the storage and replication work. But you need to carefully model densely connected graphs with scatter–gather queries. RU usage can grow faster than the dataset if traversals hit many partitions.
Indexing and Query Semantics
Cosmos DB indexes all properties automatically, including composite, range, and spatial indexes. For Gremlin queries, this speeds up the initial V() lookup and filtering. Once a traversal moves through edges, performance depends more on adjacency metadata and partition locality than on indexes.
Global secondary indexes (in preview as of writing this article) add flexibility for alternative lookup paths without forcing a data rewrite.
Operational and Ecosystem Characteristics
Cosmos DB focuses on operational ease:
- No cluster management; RU/s controls scaling.
- Autoscale handles spikes automatically.
- Monitoring is built in through Azure Monitor, Log Analytics, and Application Insights.
- Multi-region backups and disaster recovery happen without manual effort.
- Strong integration with Azure Functions, Event Hubs, Synapse, and Data Factory.
Recent features like Fleet Analytics and the MCP Toolkit improve observability across accounts, though they apply to all models, not only Gremlin.
Cosmos DB is best viewed as a globally distributed, multi-model platform that also supports graphs well, not a pure graph database. It has great utility when graph modeling consists part of a broader operational workload but not the entirety of it.
What is Neo4j?

Neo4j is a native property-graph database built for workloads where relationships constitute the main source of complexity. It stores nodes and relationships as linked records with direct pointers. This design gives constant-time hops across dense and deep graphs. Because the engine focuses on adjacency, performance stays predictable as graph depth grows; that is something multi-model and document-based systems often can’t guarantee.
Native Graph Storage and Index-Free Adjacency
Neo4j stores each relationship as its own record, including direct references to the start and end nodes. This design, called index-free adjacency, removes the requisite for join-style lookups during traversal:
- Each hop follows physical references in memory or on disk.
- Traversal cost depends on the number of relationships you touch, not on total dataset size.
- Dense graphs, long paths, and variable-length patterns remain efficient even when the graph exceeds memory size.
Neo4j’s page cache keeps active graph regions in memory while persisting everything on disk, supporting consistent latencies for both transactional and analytical graph work.
Cypher: Pattern-First Query Language
Neo4j created Cypher, a declarative query language that models graph logic through patterns:
MATCH (u:User)-[:FOLLOWS]->(v:User)
WHERE u.id = $id
RETURN vCypher aims for readable queries while giving the planner enough structure to optimize execution. Here are some notable features:
- Clear pattern syntax (()-[:REL]->())
- Support for schema indexes and full-text search
- Subqueries, list operations, and path functions
- Transactional semantics with parameter binding
Cypher’s influence on openCypher and ISO GQL has made it the most widely used graph language in production systems.
Causal Clustering and High Availability
In Enterprise Edition, Causal Clustering provides durable writes and scales read workloads horizontally.
- Primaries handle both reads and writes. It synchronously replicates transactions to a majority of primaries (N/2 + 1) acknowledging them.
- Secondaries replicate asynchronously from primaries. They don’t impact fault tolerance but allow the cluster to scale out read throughput to large numbers of queries.
- Bookmarks guarantee causal consistency, letting clients read their own writes from any node.
Leadership gets assigned per database: one primary becomes the leader to command writes, while others follow. Elections occur automatically if the leader fails, and Neo4j balances leadership roles across the cluster to avoid hotspots.
Thanks to this architecture, you get predictable correctness without complicating operational workflows.
Performance Posture
Neo4j performs well in these situations:
- Traversals span many hops.
- Node or relationship counts become dense.
- Graph algorithms repeatedly scan topology.
- You need transactional writes and real-time reads at the same time.
The native design befits deep and relationship-heavy graphs. General-purpose or multi-model systems often slow down here due to index lookups, document hydration, or cross-partition network trips.
Ecosystem and Tooling
Neo4j’s ecosystem is broad and mature:
- APOC: Hundreds of procedures for ETL, transformations, and operations
- Graph Data Science (GDS): Algorithms, ML pipelines, embeddings, and production scoring
- Bloom and Neo4j Browser: Tools for visualization and exploration
- Official drivers: Java, Python, JavaScript, Go, .NET
- AuraDB: Managed cloud service with backups and elastic scaling
This ecosystem removes the need for extra compute platforms and makes it easier for engineering and analytics teams to adopt Neo4j.
Cosmos DB vs Neo4j: Feature Comparison
The following table compares Azure Cosmos DB (Gremlin API) and Neo4j, covering architecture, graph execution behavior, scaling models, and the operational trade-offs critical to production graph workloads.
When to Choose Cosmos DB vs Neo4j
Choosing Cosmos DB
Cosmos DB is a better fit when global availability, elastic scaling, and low operational effort take preference over deep traversal performance. If your system runs on Azure and needs multi-region reads or writes with strong uptime guarantees, Cosmos DB provides this by default. Neo4j can scale reads and stay highly available, but global distribution usually requires more careful cluster design or a managed Aura setup with regional limits. Carefully evaluate this aspect for user-facing apps, IoT metadata graphs, or multi-tenant SaaS systems; in those use cases, regional latency and automatic failover are more important than complex, multi-hop traversals.
Cosmos DB performs well when traversals are short, predictable, and aligned with a solid partition key. Queries that start from a known vertex and expand one or two hops, such as related records, session context, or ownership links, work reliably with the Gremlin API. Neo4j handles these cases too, but its advantages show up only as traversal depth and density increase.
Cosmos DB is optimized first for distributed document access, with graph traversal layered on top. Neo4j is built for traversal from the start. As long as queries stay close to their entry point, Cosmos DB is the better choice. When traversal depth becomes the primary concern, Neo4j becomes more befitting.
Choosing Neo4j
Choose Neo4j when relationships constitute the core of the query logic, besides supporting data. Fraud detection, identity resolution, dependency graphs, and recommendation paths: all depend on multi-hop traversals and dense connectivity. Neo4j’s index-free adjacency keeps traversal performance stable as the graph grows, something Cosmos DB can’t guarantee once queries cross partitions.
Cosmos DB can represent these graphs, but traversal cost increases with partition fan-out and network hops. Neo4j avoids this by design, thereby befitting it for highly connected graphs.
Pick Neo4j if your roadmap includes graph algorithms, embeddings, or iterative analysis. The Graph Data Science library runs algorithms like PageRank, community detection, similarity, and ML pipelines directly in the database. Cosmos DB has no comparable native analytics layer, so advanced analysis usually means exporting data elsewhere.
Practically, Cosmos DB fits operational graphs embedded in applications. Neo4j fits graph-first systems where traversal and analysis directly drive business value.
Which One Is Right for You?
Graphs Complement Your Primary Workload
Cosmos DB works best when graph relationships add context rather than define the system. Many applications store core entities, like users, devices, sessions, and resources, as operational records and use graphs for nearby lookups, ownership chains, or small expansions. In this shape, the Gremlin API suits because Cosmos DB already optimizes for low-latency reads, elastic throughput, and multi-region availability.
Neo4j can support these cases too, but it often nudges teams toward treating the graph as a primary system of record. When traversals stay shallow and predictable, that adjustment can introduce unnecessary duplication, extra governance, and more operational overhead than the workload really needs.
Global Availability and Managed Operations Have the Highest Priority
Cosmos DB is the better option when global distribution and operational simplicity outweigh deep traversal efficiency. Multi-region replication, configurable consistency, automated failover, and throughput scaling are built-in capabilities. If your system serves users across regions and you want predictable availability without managing clusters, Cosmos DB offers a straightforward path to production.
Neo4j supports high availability and read scaling, but global deployment usually requires more careful topology planning or a managed service with regional constraints. If reducing operational risk is the top priority, pick Cosmos DB.
Relationships Drive Query Complexity
Choose Neo4j if relationships are the workload. Fraud detection, identity resolution, dependency analysis, and recommendation paths all rely on deep, multi-hop traversals through dense subgraphs. Neo4j’s native storage and index-free adjacency keep traversal cost tied to the paths you walk, not the size of the dataset, which helps performance stay predictable as graphs grow.
Cosmos DB can model these graphs, but traversal cost rises as queries fan out across partitions. At scale, this stops being a tuning problem and becomes an architectural restraint.
Graph Analytics Are on the Critical Path
Neo4j is also the superior choice when graph algorithms and iterative analysis are core requirements. As discussed earlier, contrary to Neo4j’s Graph Data Science library, Cosmos DB has no equivalent in-database graph analytics layer. So advanced analysis typically means moving data into external systems.
Why Consider PuppyGraph as an Alternative
Cosmos DB prioritizes global distribution and managed operations, but traversal performance degrades once queries cross partitions or go beyond a few hops. Neo4j delivers strong traversal and analytics, but only by isolating graphs into a dedicated system, which introduces ETL pipelines, duplicated storage, separate governance, and memory-heavy infrastructure. In both cases, graph reasoning becomes detached from the rest of the data platform, either constrained by partitioning or weighed down by architectural sprawl. This tension is growing as enterprises try to run graph queries directly over existing relational and lakehouse data without copying or reshaping it first.

PuppyGraph is a real-time, zero-ETL graph query engine that lets teams query existing relational databases and data lakes as a unified graph. It runs directly on your data, can be deployed in minutes, and avoids the cost, latency, and operational overhead of traditional graph databases.
PuppyGraph connects directly to data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases such as MySQL, PostgreSQL, and DuckDB. You can query across multiple sources at the same time, without moving or reshaping data.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query layer on top of your existing data. There are no pipelines to build or maintain. You can start querying relationships in minutes.
- No Data Duplication: Data stays where it is. There’s no need to copy large datasets into a separate graph store, which helps preserve consistency and reuse existing access controls.
- Real-Time Analysis: Queries run on live data, so results reflect the current state of the system. Users report multi-hop queries, six hops across billions of edges, returning in under a few seconds.
- Scalable Performance: The distributed execution engine scales with your cluster. It supports deep traversals and large datasets through parallel execution and vectorized processing.
- SQL and Graph Together: Teams can keep using SQL engines for tabular analysis and PuppyGraph for relationship-heavy queries, all on the same source tables. You don’t need to force every workload into a graph database or retrain teams on a new system.
- Lower Total Cost of Ownership: Traditional graph stacks add cost through ETL pipelines, duplicated storage, separate governance, and memory-heavy infrastructure. PuppyGraph avoids these by querying data in place, with no second system to operate or secure.
- Flexible, Iterative Modeling: Metadata-driven schemas allow multiple graph views over the same data. Models can evolve quickly without rebuilding pipelines, supporting fast iteration.
- Standard Querying and Visualization: PuppyGraph supports common graph query languages like openCypher and Gremlin, in addition to built-in visualization tools for interactive exploration.
- Proven at Enterprise Scale: PuppyGraph is used by many large cybersecurity companies and engineering-focused organizations like AMD and Coinbase. These teams trust PuppyGraph for security analysis, asset intelligence, and deep relationship queries without the overhead of ETL-heavy graph architectures.


As data systems grow more complex, the definitive insight often comes from how entities connect. PuppyGraph makes those relationships easy to explore, whether you’re modeling organizational networks, social interactions, fraud and cybersecurity graphs, or building GraphRAG pipelines that track where knowledge comes from.
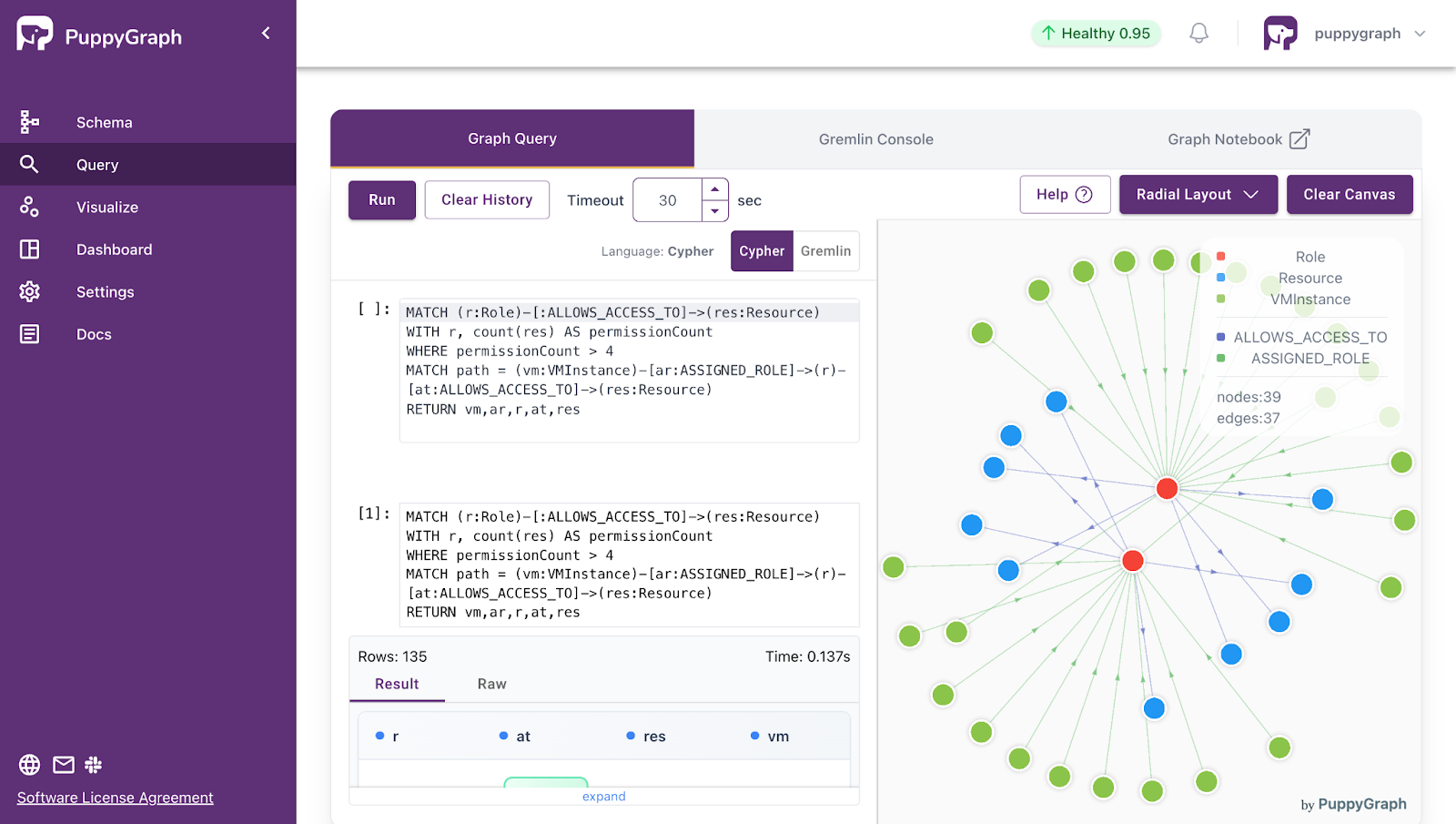

Getting started is straightforward. You can download the free Docker image, connect PuppyGraph to your existing data stores, define your graph schema, and start querying. PuppyGraph runs in Docker, an AWS AMI, through the GCP Marketplace, or inside your own VPC or data center if you need full control over data and networking.
Conclusion
Choosing between Cosmos DB and Neo4j depends on what you want the graph to optimize for. But as graph reasoning moves closer to the core of analytics and decision-making, these trade-offs are harder to overlook. That is why we have built PuppyGraph, so you can run graph queries directly on existing data without ETL or duplication, offering a more flexible long-term option.
To try the platform out, download PuppyGraph's forever free Developer edition or book a free demo.

Matt is a developer at heart with a passion for data, software architecture, and writing technical content. In the past, Matt worked at some of the largest finance and insurance companies in Canada before pivoting to working for fast-growing startups.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install