

What is a Customer 360 Graph Database?
According to the Qualtrics 2024 Consumer Trends Report, product and service quality along with strong customer support are the top drivers of purchases, ahead of even low prices. Understanding the customer experience is critical for customer acquisition and retention, but the ways we gather that understanding are changing. Since 2021, the share of consumers giving direct feedback through surveys has dropped by 7.2 percentage points. Companies now need new ways to follow each customer’s unique journey. Customer 360 is part of that shift, with the market projected to reach USD 10.5 billion in 2024.
The concept sounds simple enough: a unified view of each customer, for every customer. In practice it is full of design choices, trade-offs, and surprises that only appear once you start building. In this blog, we will explore what Customer 360 means, how graph technology can strengthen it, the architecture of a Customer 360 Graph System, the top graph solutions available, and the challenges you are likely to meet along the way.
What is Customer 360?
Customer 360 is a company’s single source of truth for understanding each customer, combining data from every available source into one unified profile. Without it, information remains fragmented even within the same organization. Imagine sales teams trying to qualify leads without knowing which marketing campaigns brought them in, while marketing teams keep targeting customers who have unresolved support tickets. The result is a disjointed and frustrating experience for the customer.
A Customer 360 view breaks down these silos, enabling teams to share data, align goals, and coordinate actions. It reflects the company’s current understanding of a customer and helps predict their needs in the moment, allowing for timely and relevant personalization.
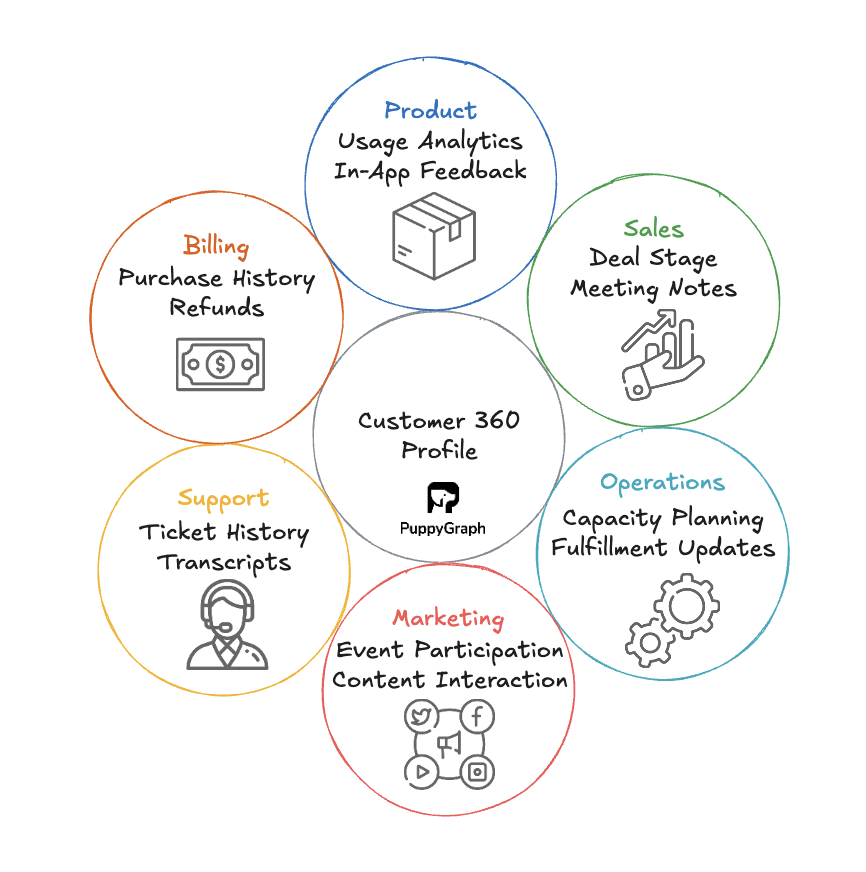
Building Customer 360 With Graph Databases
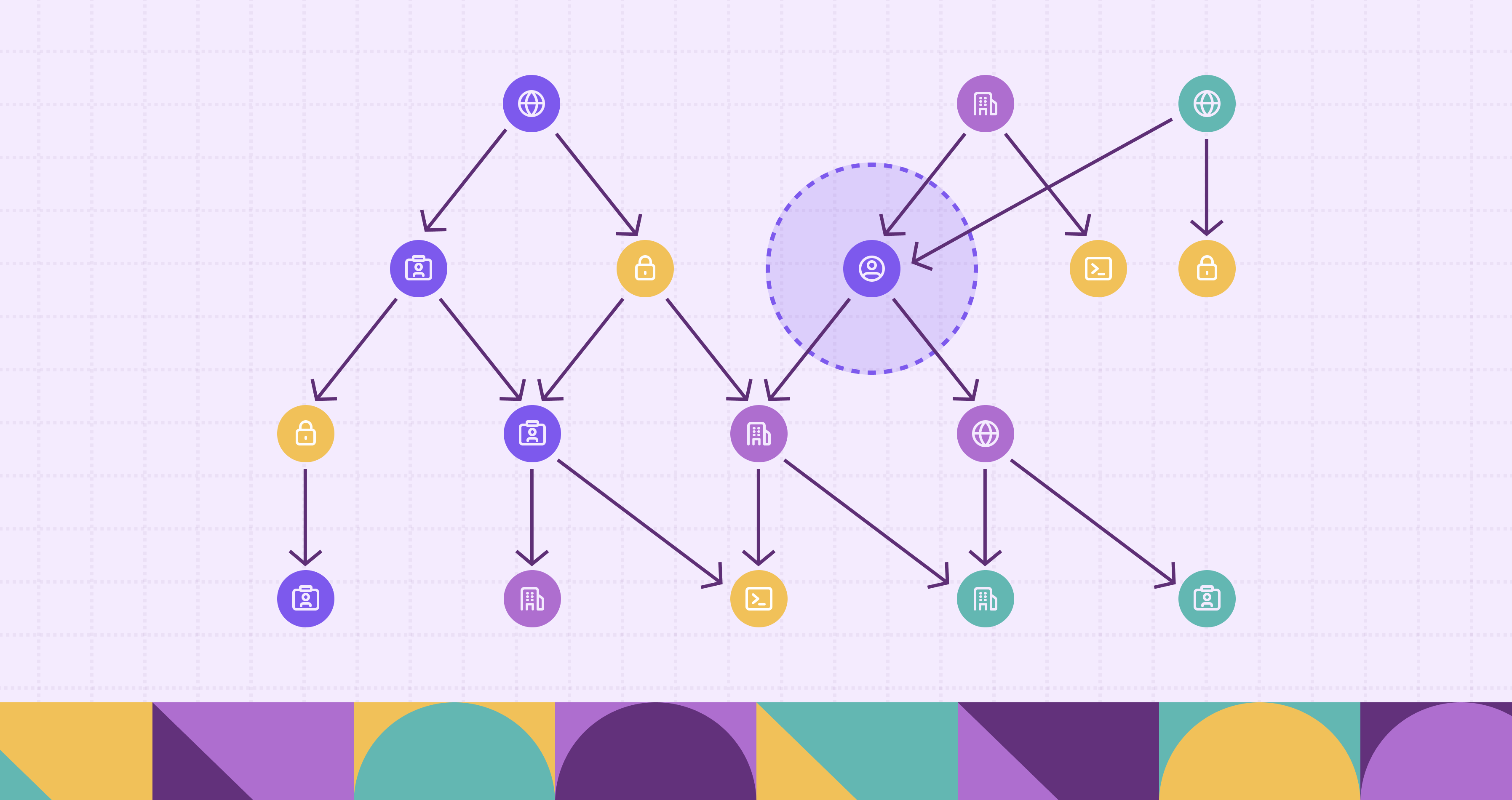
A Customer 360 knowledge graph organizes everything you know about a customer into a structure that reflects how those details relate to each other. Customers, accounts, devices, products, orders, and interactions become nodes, while purchases, logins, referrals, and support cases are the connections. This makes it easier to see how events and entities link together in context.

Many companies already represent these relationships in SQL, linking customer profiles, transactions, and campaign touchpoints with foreign keys and joins. In a graph database, those same connections are stored directly, making them easier to navigate and query. Even this small change in how the data is organized can unlock new ways to explore and analyze customer relationships.
Why Use Graph Databases for Customer 360?
Unifying Disparate Data Sources
Customer data often lives in separate departmental systems: CRM for sales, marketing automation for campaigns, ticketing platforms for support, billing systems for finance, and product analytics for usage. For many Customer 360 projects, integrating these sources is one of the biggest upfront costs and in some cases it is a key reason initiatives stall. Graph databases help lower that barrier by linking entities from different systems without forcing them into a rigid, unified schema at the start. Relationships can be created as soon as a connection is identified, even if some attributes differ in format or completeness. This makes it easier to start analysis sooner and refine the model over time.
Built-in Relationship Analytics
Data quality and identity resolution are another common blocker. Matching the same customer across multiple systems often requires complex rules and iterative cleanup. Graph algorithms such as similarity scoring and community detection can help identify likely matches or related clusters, speeding up the resolution process. These algorithms can also reveal hidden relationships and behavioral patterns once the data is connected, adding analytical value beyond the initial integration.
Query Complexity
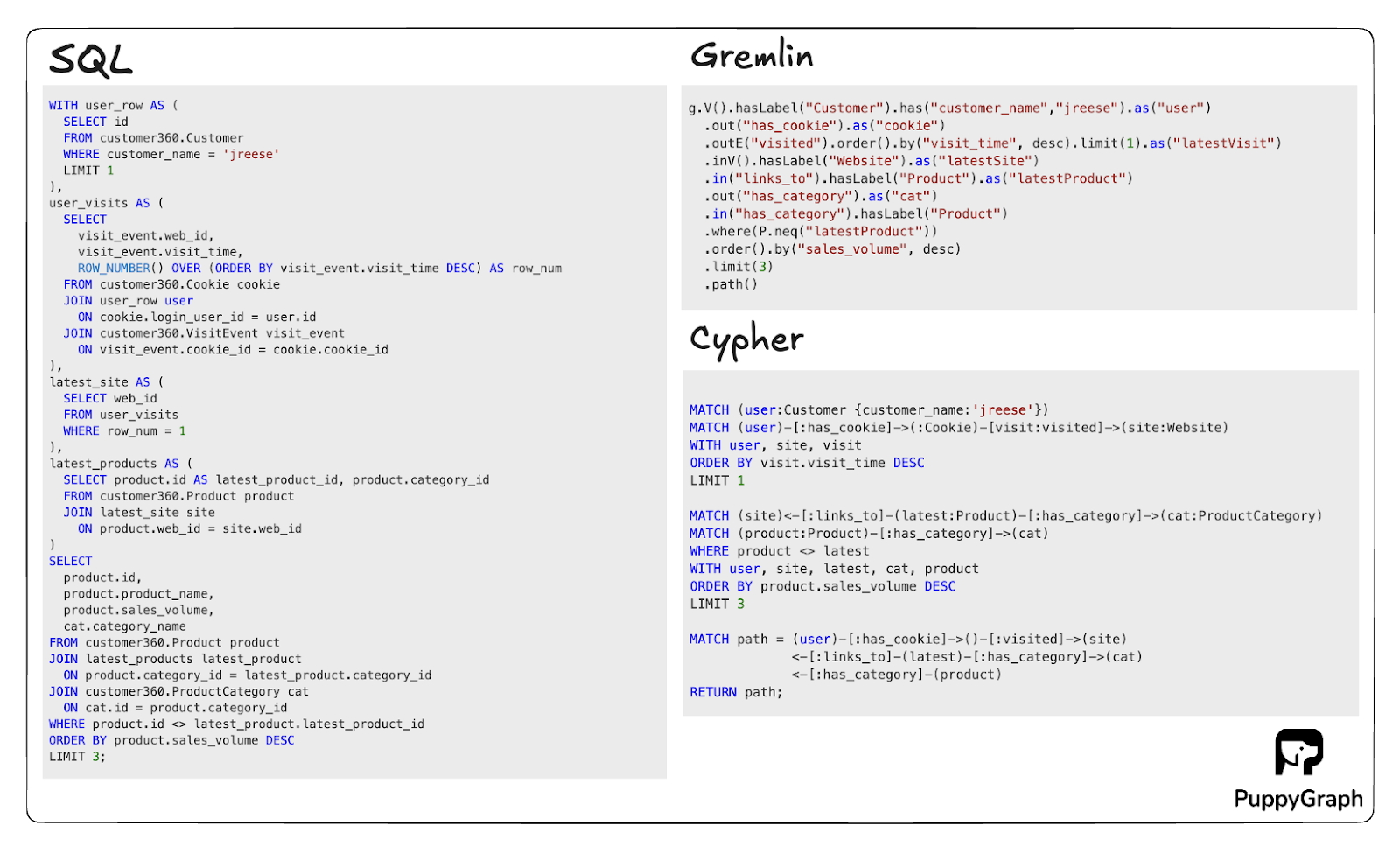
Relationship-heavy questions in SQL can require deeply nested joins and Common Table Expressions (CTEs). For example, tracking a customer from a purchase to a support ticket to a marketing touchpoint often results in long, brittle queries that are sensitive to schema changes. In a graph database, these same paths are expressed as direct traversals, often in fewer lines of code and with less performance overhead.
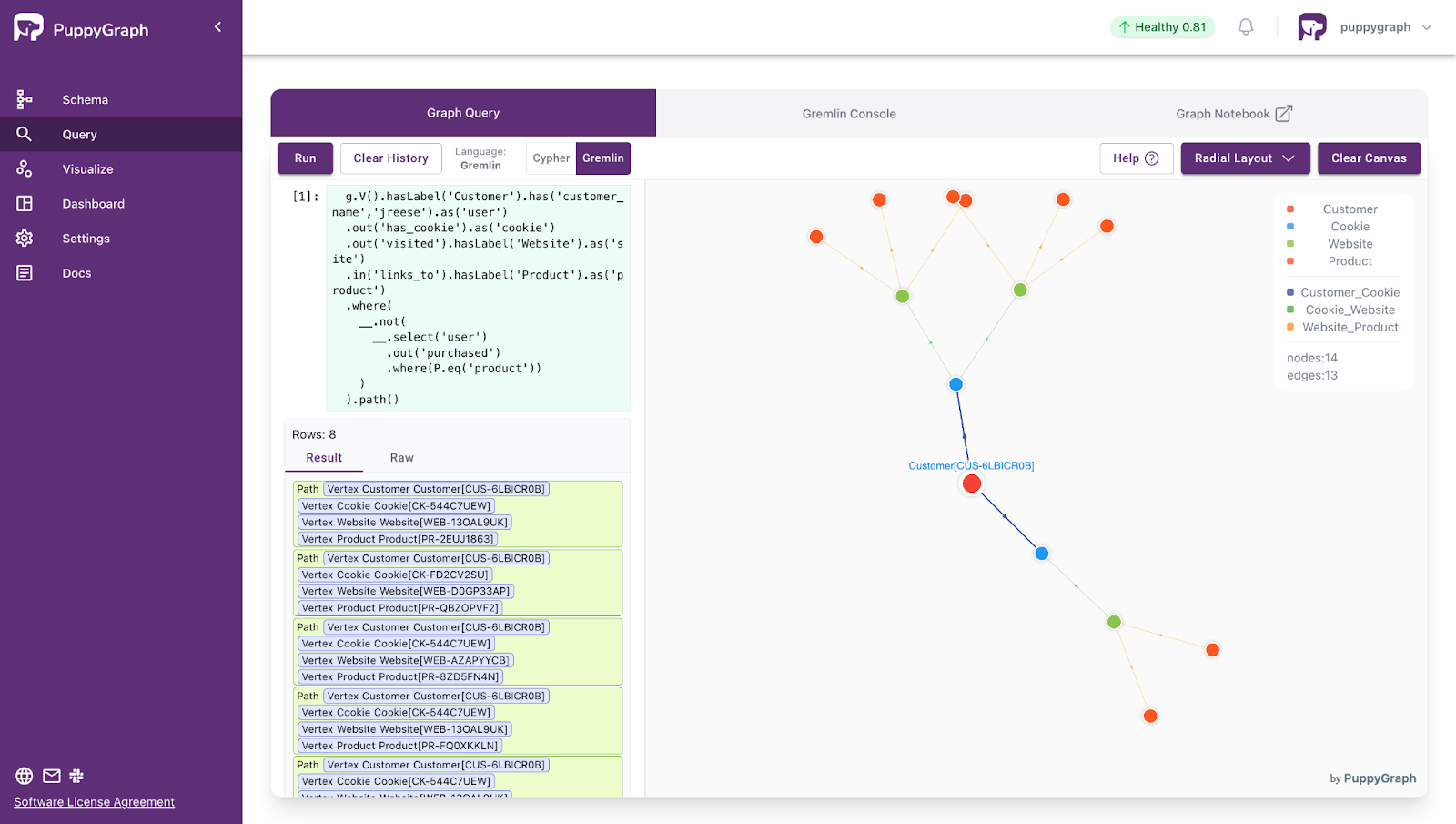
A practical example is recommending top-selling products from the same category as a user’s last viewed product. This powers on-site recommendations and follow-ups. In SQL, stitching together visits, pages, products, and categories can get long. In Gremlin or Cypher, the traversal follows the natural path from customer to cookie to visit to product to category, and it fits in a few lines, as shown below.
Schema Change
Customer data models evolve as new interaction types, products, or identity sources are introduced. In a relational system, accommodating these changes may involve altering multiple tables, updating ETL processes, and modifying existing queries. Graph databases allow new nodes and relationships to be added without disrupting current data or queries, enabling the model to grow naturally alongside the business.
Performance at Scale
In SQL, multi-table joins and large intermediate datasets grow quickly as data volumes increase. This can lead to slower queries, higher memory usage, and greater costs in cloud-based analytics environments. Graph databases are optimized for traversing relationships, which helps maintain more consistent performance as the number of nodes and connections grows. This efficiency is valuable whether your Customer 360 runs in real time, near real time, or batch mode, supporting everything from instant personalization and fraud detection to daily segmentation and scheduled reporting.
Core Architecture of a Customer 360 Graph System
A Customer 360 graph system brings together data from across the organization into a connected view that evolves alongside the business.
Data Integration and Identity Resolution
A Customer 360 graph depends on pulling data from across the business. This includes CRM for sales, marketing automation for campaigns, eCommerce for orders, support platforms for tickets, billing for invoices, and product analytics for usage events.
When evaluating a graph solution, it is important to consider the range of integrations it supports. Native connectors for CRMs, cloud data warehouses, and operational platforms can reduce implementation time and minimize the need for custom ingestion logic.
Some graph engines now support architectures that separate compute from storage. This allows the graph layer to query existing data sources directly, such as data lakes or lakehouse formats, without requiring data movement or preprocessing. This can further reduce integration overhead and enable teams to start querying as soon as the schema is mapped.
It is also at this stage that identity resolution is carried out. Related records across systems, such as logins, sessions, devices, and purchases, must be linked to a single node, maintaining a unified view of each customer. Graphs are well suited for this because they can represent and traverse multiple identifiers for the same entity.
Storage
The storage layer holds the graph’s nodes and relationships, optimized for fast traversals and multi-hop queries. Most graph databases use an integrated storage-and-compute model, though there is growing interest in separating the two for more flexible scaling.
In a Customer 360 context, storage should handle large connected datasets without performance drops, support frequent updates so profiles stay current, and manage historical records efficiently for long-term analytics. Efficient formats and compression help control costs as data grows, while the ability to expand capacity without major rework ensures the system can grow with demand. Integration with data lakes or warehouses can also simplify ingestion and keep the Customer 360 aligned with other analytical systems. Here the focus is on performance, capacity management, and compatibility with the broader data ecosystem.
Graph Modeling
Graph modeling defines the logical blueprint of the Customer 360. It determines which entities become nodes, which relationships and interactions become edges, and which attributes are stored as properties. In practice, this could mean connecting a customer to products through purchases, to campaigns through clicks, and to support cases through tickets.
A strong model makes these connections easy to query while keeping the structure intuitive for analysts and developers. It should capture current needs while being easy to extend as business requirements change, without introducing unnecessary complexity. Clear naming conventions, consistent relationship directions, and well-documented entity definitions help maintain coherence as the graph grows and multiple teams contribute to it.
Query and Analytics
The query and analytics layer is where the Customer 360 delivers real value. This is where users can ask complex, relationship-heavy questions and get answers quickly, whether for operational dashboards, investigative analysis, or advanced modeling. Graph query languages such as Gremlin and Cypher allow you to follow paths across customers, products, and events without the deeply nested joins that SQL often requires.
This layer also supports built-in or pluggable graph algorithms, such as shortest path, centrality, and community detection, which can uncover influencers, hidden clusters, or potential churn risks. Integration with BI tools, data science platforms, or real-time APIs ensures that insights can be applied quickly, whether that means personalizing a webpage in milliseconds or generating weekly segmentation reports.
Governance and Security
Governance ensures that Customer 360 data stays accurate, consistent, and trustworthy. Security ensures that only authorized people and systems can access sensitive information. Together, they protect both the data and the trust customers place in the company.
In a graph system, governance includes clear data ownership, versioning changes to the model, and maintaining lineage so teams can trace each data point’s origin. Security covers role-based access control, fine-grained permissions at the node or property level, encryption in transit and at rest, and audit logging.
For Customer 360, these measures must work without slowing legitimate workflows. A marketer might need aggregate engagement metrics without personally identifiable information, while a support agent might require contact details but not financial notes. The architecture should make these distinctions easy to enforce and maintain as the system grows.
What are the Challenges and Considerations?
Data Integration and Quality Controls
A big challenge in Customer 360 is that the data you need lives in many different systems. Sales teams use CRMs, marketers use automation tools, support relies on ticketing platforms, and product teams track usage in separate analytics tools. These systems all store data differently, with their own formats, identifiers, and assumptions.
Even when the data is integrated, quality remains a concern. Skewed timestamps, inconsistent IDs, and relationships that don’t line up can make results misleading. Bad data spreads quickly, and even just spot-checking a few records can help to surface issues early.
Messy connectors and complex ETL pipelines can make this harder. When data is stitched together across systems, it’s easy for assumptions to break, especially when schemas change or source systems go out of sync. Keep your model as simple and observable as possible so you can trust the graph you’re building.
Identity Resolution
Accurate Customer 360 graphs begin with reliable identity resolution. To unify behavior and attributes across systems, you need to ensure that each person, account, or product is only represented once. That means resolving identities across different systems using user IDs, emails, phone numbers, device fingerprints, or other clues.
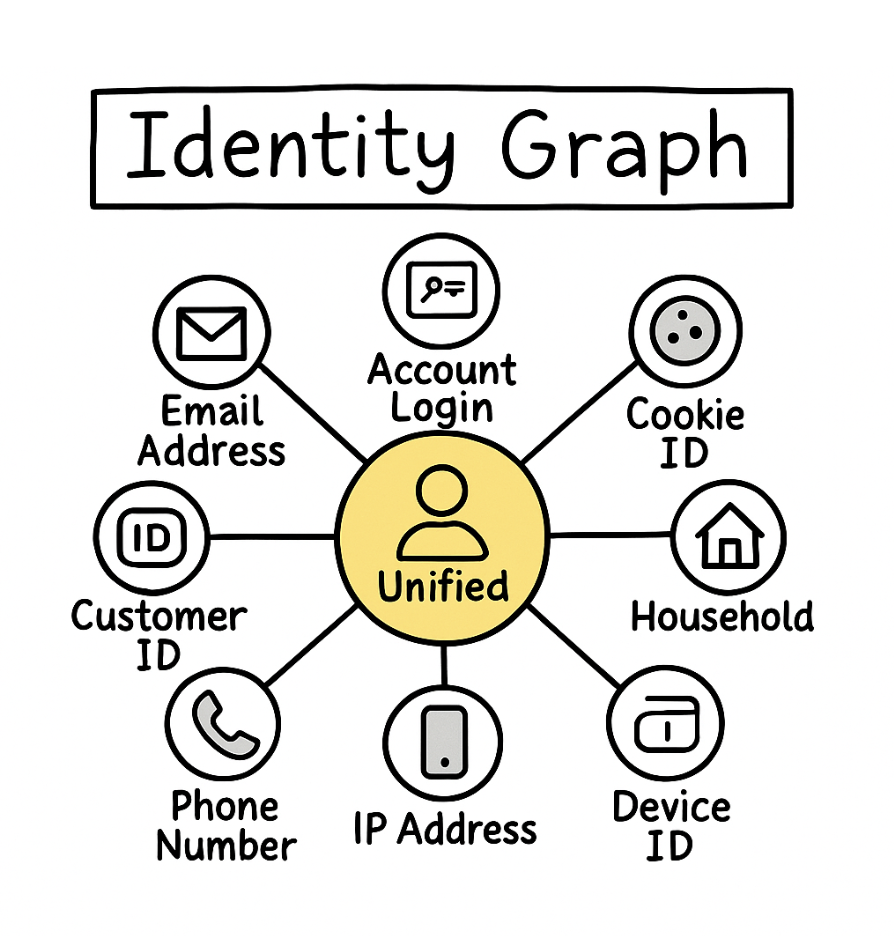
Graphs make this easier by allowing you to store and connect multiple identifiers to the same entity without flattening or duplicating the data. Because identity resolution involves analyzing high volumes of data and tracing connections across systems, it benefits from graph engines designed for analytical workloads. Identity graphs typically sit upstream of the Customer 360 graph, resolving duplicates and linking activity to the right customer before deeper analysis begins.
Privacy and Consent
Customer 360 graphs often include sensitive information such as names, emails, phone numbers and locations. As you connect more data points, you also increase the chance of exposing relationships or attributes that were never meant to be seen together.
If a piece of data was collected for support, it shouldn’t automatically be visible to marketing or sales. Avoid queries that infer sensitive details unless the use case is clear and approved. A well-designed graph makes it easy to create role-based views. Marketing might see engagement trends, support gets contact and ticket data, and fraud teams see device or IP histories. When the graph respects data boundaries by design, it's easier to stay compliant and build trust.
Governance and Auditability
As Customer 360 graphs shape decisions across teams, trust in the data matters. People need to know where data came from, how it was joined, and whether it’s up to date.
Good governance means assigning ownership, tracking changes, and keeping lineage visible so teams can follow how data moves and transforms. When something breaks or looks off, it should be easy to trace back and understand why.
Auditability is just as important. You should be able to explain why a relationship exists, when it was added, and by what process. That kind of transparency builds confidence, especially when the graph is used to make decisions that impact customers.
Top Graph Databases for Customer 360
Neo4J

Teams pick Neo4j for its mature ecosystem, polished tooling, readable Cypher queries, strong traversal performance, the Graph Data Science library, and flexible deployment options. Taken together, these strengths make it a comfortable fit for Customer 360 work where you need to follow relationships across many touchpoints and share results with non-engineers.
Because Neo4j is a native property graph database, its storage and query engine are built for graphs, which keeps multi-hop traversals fast and predictable. In addition, the developer experience is strong: documentation is extensive, the community is active, and Neo4j Desktop makes local development straightforward. If you prefer a managed option, AuraDB runs Neo4j in the cloud and takes care of operations.
The core capabilities include index-free adjacency for efficient traversals and Cypher’s clear pattern-matching syntax for complex queries. From a licensing perspective, Neo4j follows an open-core model. The Community Edition is open source, while the Enterprise Edition adds clustering, advanced security, and commercial support.
ArangoDB

ArangoDB is a multi-model database that combines graph, document, and key-value in one engine. For Customer 360, that means you can keep rich customer profiles as documents, represent interactions and relationships as edges, and use key-value patterns for fast lookups without stitching together multiple systems. You get a single place to model people, products, and events while choosing the most suitable data model for each part.
ArangoDB provides native support for property graphs and uses AQL, a query language that lets you mix traversals, joins, and filters in a single statement. ACID transactions help keep profiles consistent during merges and identity updates, and cluster deployments provide horizontal scale as the graph grows. If you prefer a managed option, ArangoGraph runs the platform for you, and the ecosystem integrates with graph visualization tools so analysts can explore journeys and relationships.
This multi-model design suits hybrid Customer 360 workloads and consolidated data platforms. It keeps varied data close together, supports both single-node and distributed setups, and gives teams the flexibility to evolve models as new touchpoints appear.
TigerGraph

TigerGraph is a popular choice when raw speed on large, multi-hop analytics matters. It is a native parallel graph built on an MPP architecture that partitions data across a cluster and executes queries in parallel. GSQL, its SQL-like language, compiles to C++, so complex traversals run quickly and predictably at scale.
That profile fits Customer 360 work that spans many touchpoints. You can trace journeys from views to purchases to support interactions, map influence across accounts, and spot patterns such as household relationships or coordinated fraud. Real-time loading keeps profiles current as new events land, so recommendations and alerts can react quickly.
TigerGraph also supports in-database analytics and feature creation, which helps when you want to compute similarity scores or churn signals without moving data elsewhere. If you would rather not run clusters, a managed cloud option is available so teams can focus on modeling customers and relationships instead of operating the platform.
Amazon Neptune

Teams pick Amazon Neptune when they want a fully managed graph service that fits cleanly into an AWS stack. AWS handles patching, backups, and high availability, which cuts operational work. Neptune Serverless scales compute up and down with traffic, so costs follow demand. It supports both Property Graph and RDF models and works with Gremlin and openCypher, giving teams flexibility in how they model and query.
Under the hood, Neptune separates storage and compute. The storage layer grows automatically to large datasets, and you can add low-latency read replicas to increase throughput for applications and dashboards. This design lets you scale data size and query load independently without re-architecting.
For Customer 360, Neptune plugs into common AWS data flows so you can bulk load from S3, manage access with IAM, and bring graph features into models with SageMaker. That makes it straightforward to keep profiles current, scale reads during campaigns, and run relationship-heavy queries without standing up and operating your own graph infrastructure.
Bonus: PuppyGraph

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.

Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Customer 360 graphs offer a practical way to connect fragmented data into something usable, reflecting how customers actually interact with your business. Graph databases simplify the process of unifying systems, tracking relationships over time, and running queries that follow real customer journeys. But getting there takes more than just adopting a graph database. It requires the right architecture, data integration, and a model designed to make those questions easier to ask and faster to answer.
If you want to get started without the cost and complexity of ETL, try a zero-ETL engine like PuppyGraph. Download the forever free PuppyGraph Developer Edition, or book a demo with our engineering team.

Jaz Ku is a Solution Architect with a background in Computer Science and an interest in technical writing. She earned her Bachelor's degree from the University of San Francisco, where she did research involving Rust’s compiler infrastructure. Jaz enjoys the challenge of explaining complex ideas in a clear and straightforward way.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install