

What Is a Cyber Data Lake?
Modern security operations generate massive volumes of heterogeneous telemetry from endpoints, networks, cloud services, and applications. Traditional SIEM platforms struggle to keep up with this scale due to cost constraints, rigid schemas, and tightly coupled storage and compute architectures. As a result, organizations are often forced to trade visibility for affordability, creating blind spots in long-term detection and investigation.
The cyber data lake emerges as a foundational shift in security data architecture. By decoupling storage from compute and adopting open formats with schema-on-read flexibility, it enables scalable, cost-efficient, and long-term retention of raw security data. More importantly, it provides the basis for advanced analytics, threat hunting, and AI-driven security workflows, making it a central pillar of the modern SOC.
What Is a Cyber Data Lake?
A cyber data lake is a centralized, large-scale repository designed specifically to aggregate, store, and analyze vast quantities of security-related telemetry in its native format. Unlike traditional databases that require data to be structured before it is saved (schema-on-write), a cyber data lake adopts a schema-on-read approach. This allows security teams to ingest diverse data streams, such as packet captures, endpoint logs, cloud activity, and threat intelligence, without the immediate need for normalization or transformation.
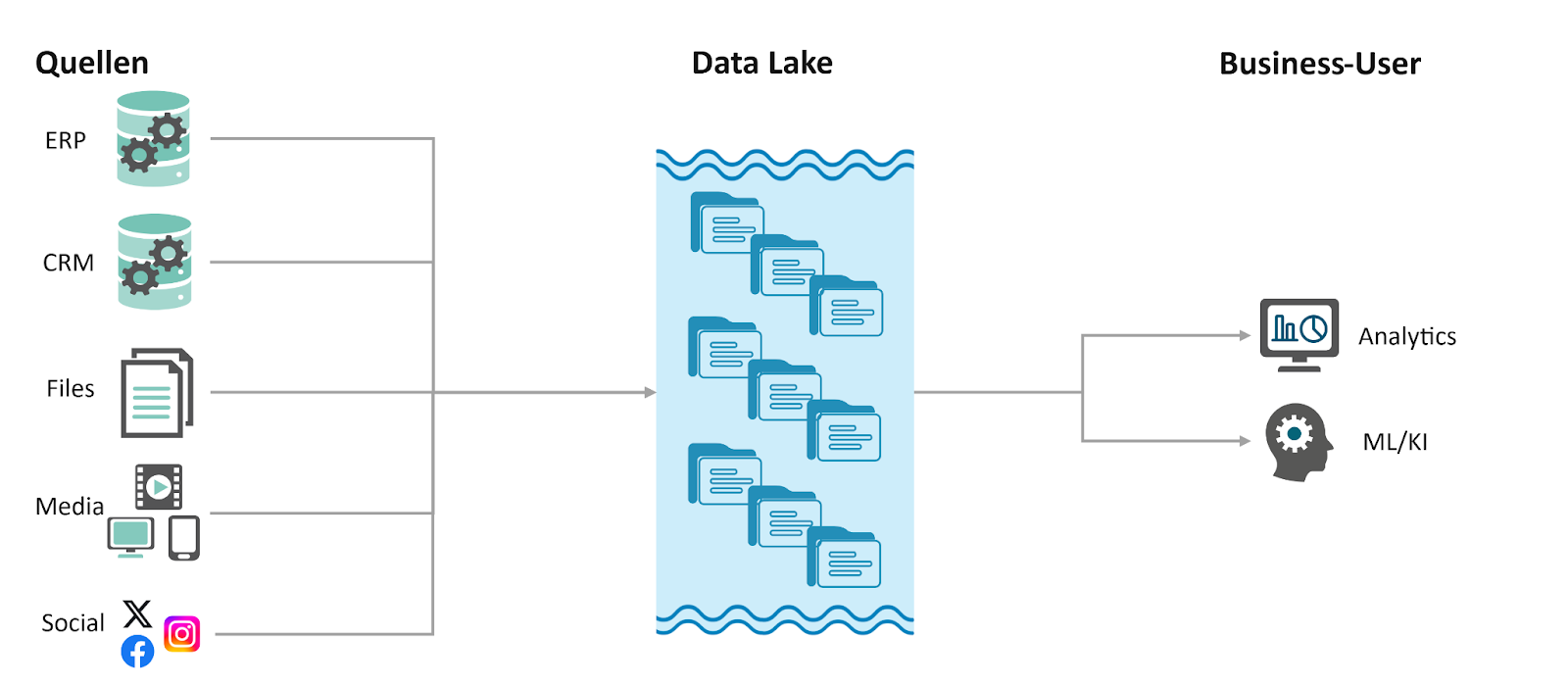
A cyber data lake can serve as a foundational data layer for modern security operations. It complements existing SIEM systems and the broader modern SOC by providing scalable, cost-efficient storage and long-term retention of raw telemetry. In this architecture, the data lake stores large-scale telemetry data for long-term retention, while enabling advanced analytics, threat hunting, and retrospective investigations that would otherwise be impractical within traditional SIEM constraints.
According to industry frameworks and architectural best practices (such as those outlined in The Security Data Lake by Raffael Marty), a cyber data lake has three core characteristics:
- Massive Scalability and Low Cost: Built typically on cloud object storage (like AWS S3 or Azure Blob) or distributed file systems (like Hadoop), it enables organizations to store petabytes of data for years. This is economically unfeasible in traditional SIEMs, which often force "data filtering" due to high licensing and storage costs.
- Decoupling of Storage and Compute: This is a critical architectural shift. In a cyber data lake, the data resides in a cost-effective storage layer, while various "compute" engines (such as Snowflake, Databricks, or Amazon Athena) can be plugged in to run analytics, hunt for threats, or train Machine Learning (ML) models. This ensures that scaling your data volume does not exponentially increase your processing costs.
- Data Sovereignty and Interoperability: A true cyber data lake allows an organization to "own" its data in an open format (such as Parquet or JSON). This prevents vendor lock-in, enabling the SOC to swap or add different security tools (EDR, NDR, or AI analytics) that all point to the same central data source.
In essence, a cyber data lake serves as the "single source of truth" for the modern SOC. It moves beyond simple log management by providing a high-fidelity foundation for Security Data Science, allowing analysts to run complex, long-term forensic queries that would crash or timeout in a conventional security tool.
Why Cybersecurity Needs a Data Lake
The shift toward a cyber data lake is driven by the fundamental limitations of the traditional SIEMs that have dominated the industry for two decades. As organizations face an explosion of telemetry and more sophisticated adversaries, the traditional model is breaking under three primary pressures:
1. The "Data Gravity" and Cost Gap
Traditional SIEM platforms often tie the cost of the software to the volume of data ingested (e.g., GB per day or Events Per Second). This creates a "security paradox": as an organization grows and generates more logs to stay safe, their security budget becomes a bottleneck. To stay within budget, SOC teams are often forced to choose which data to discard. A cyber data lake solves this by using low-cost cloud object storage, allowing organizations to ingest 100% of their telemetry, including high-volume sources like NetFlow, DNS logs, and EDR data, at a fraction of the traditional cost.
2. Overcoming Data Silos and Proprietary Locks
In a conventional setup, data is often trapped in "proprietary black boxes." Your EDR data lives in one vendor's cloud, your firewall logs in another, and your SaaS logs in a third. This fragmentation prevents cross-stack correlation. A cyber data lake acts as a vendor-neutral repository. By adopting open standards like the Open Cybersecurity Schema Framework (OCSF) and open formats like Apache Parquet, the SOC regains "data sovereignty." This means you can point any analytics tool or AI model at a single, unified pool of data without having to move it.
3. Support for Advanced Analytics and Long-Tail Investigations
Most SIEMs are optimized for "real-time" detection based on known rules. However, modern threats often involve "low and slow" attacks that take place over months.
- Historical Context: Cyber data lakes enable "look-back" investigations where analysts can query years of historical data in seconds to see if a newly discovered IOC (Indicator of Compromise) was present in the environment months ago.
- Security Data Science: Traditional tools aren't built for Python, R, or complex ML workflows. A data lake allows security data scientists to run large-scale behavioral modeling and anomaly detection directly on the raw data, which is essential for identifying zero-day threats that bypass rule-based signatures.
4. Future-Proofing for AI and Automation
The next generation of cybersecurity is built on AI. For Large Language Models (LLMs) and ML classifiers to be effective, they require vast amounts of high-fidelity, diverse training data. A cyber data lake provides the "fuel" for these AI engines. By centralizing all telemetry in a structured, accessible format, organizations can automate complex response workflows and train custom models that understand the unique "normal" of their specific network environment.
Key Components of Cyber Data Lake Architecture
The architecture of a modern cyber data lake is fundamentally "decoupled," representing a shift from monolithic "black box" systems to a modular, high-performance ecosystem. According to the framework described in The Security Data Lake, this architecture allows organizations to build a "best-of-breed" security stack where the layer that stores the data is independent of the layer that processes it.
The architecture follows a five-layer logical flow, integrating all critical functional components into a unified security data supply chain:
1. The Ingestion & Transformation Layer (The Pipeline)
This layer acts as the "intake" system, responsible for collecting fragmented telemetry from EDR, firewalls, SaaS, and cloud providers (e.g., AWS CloudTrail). It performs two critical functions before data hits the lake:
- Normalization & Schema Mapping: Converting disparate log formats into a standardized schema, such as the OCSF. This ensures a "process start" event from one vendor looks identical to another.
- Format Optimization: Converting raw text logs (JSON/CSV) into high-performance, open-source columnar formats like Apache Parquet. This significantly reduces storage footprints and speeds up downstream query times.
2. The Sovereign Storage Layer (The Foundation)
At the heart of the architecture is a low-cost, highly durable storage environment, typically built on cloud object storage (e.g., AWS S3, Azure Blob, or Google Cloud Storage).
- Data Sovereignty: Unlike traditional SIEMs, the data resides in an open format owned by the organization, not the vendor.
- Economic Scalability: By utilizing "cool" or "archive" storage tiers, organizations can retain petabytes of high-volume, "low-value" logs (like NetFlow or DNS) for years at a fraction of the cost of legacy databases.
3. The Metadata & Catalog Layer (The Map)
To manage a "schema-on-read" environment, the architecture includes a metadata catalog (such as AWS Glue or Hive Metastore).
- Discovery: This layer tells the compute engines exactly where specific data resides and how to interpret its structure.
- Schema Enforcement: It allows security analysts to discover relevant datasets for an investigation without needing to know the physical file paths, providing the flexibility to change analytical perspectives without re-indexing historical data.
4. The Disaggregated Compute Layer (The Analytics Plane)
This is the most transformative part of the architecture. Instead of a single proprietary search engine, multiple specialized "engines" can be "plugged in" to the same data source simultaneously:
- SQL Engines (e.g., Snowflake, Amazon Athena): For rapid forensic querying, complex joins, and compliance reporting.
- Stream Processing (e.g., Apache Flink): For real-time detection and alerting on critical "hot" threats.
- Data Science & AI Workspaces (e.g., Databricks, Jupyter): For security researchers to run Python-based ML, behavioral modeling, and RAG-based AI workflows.
5. The Integration & Egress Layer
The final architecture component connects the lake to the broader SOC ecosystem. Through API-driven connectors, the lake feeds high-fidelity context into SOAR (Security Orchestration, Automation, and Response) platforms for remediation and Visualization tools (like Grafana) for executive dashboards.
Cyber Data Lake vs SIEM
While traditional SIEMs have been the cornerstone of the SOC for decades, the emergence of the cyber data lake represents a shift from a "monolithic" to a "disaggregated" architecture. Rather than replacing SIEM systems, the cyber data lake complements them by introducing a scalable and flexible data layer that addresses longstanding limitations in storage, cost, and analytics. The following comparison focuses specifically on their approaches to storage, highlighting differences in scalability, cost efficiency, architecture, and data retention.
1. The "Security Paradox" and Cost Scalability
SIEM pricing is traditionally tied to data volume (GB/day or Events Per Second). As telemetry volumes explode due to cloud migration and EDR adoption, organizations face a "security paradox": they must discard potentially valuable logs to stay within budget.
Cyber data lakes break this cost curve by utilizing low-cost cloud object storage. This enables "100% logging", the ability to store high-volume, "low-value" logs (like DNS or NetFlow) for long-term retention at a fraction of the cost of a SIEM, ensuring that forensic data is available when a "low and slow" attack is finally detected.
2. Coupled vs. Decoupled Architecture
A SIEM is typically a "black box" where storage and compute are tightly coupled. You pay the vendor for both the database and the search engine as a single package. This creates vendor lock-in; if you want to use a different analytics tool, you often have to export the data out of the SIEM at a high cost.
A cyber data lake decouples storage from compute. The data sits in an open-format storage layer (like AWS S3) owned by the organization. This allows the SOC to "plug in" multiple specialized engines, such as SQL for reporting, Python for data science, or specialized search tools, simultaneously to the same data set.
3. Realtime Event Processing vs. Large-Scale Data Analysis
SIEMs are highly optimized for real-time detection and alerting based on known-bad patterns (IOCs). They excel at "finding the needle" in the stream of incoming data.
However, cyber data lakes are superior for deep investigation and threat hunting. Because they store raw, high-fidelity data over much longer horizons (years instead of weeks), they allow analysts to perform complex "look-back" queries and behavioral modeling that would typically time out or crash a traditional SIEM.
Role of Cyber Data Lake in Modern SOC
In traditional SOC environments, analysts are often constrained by data silos and high SIEM ingestion costs, which force teams to discard large portions of telemetry. As a result, visibility is limited and investigations are often incomplete. A cyber data lake addresses these challenges by shifting the SOC from a reactive, alert-driven model to a more proactive and data-driven approach. In this context, a cyber data lake plays several key roles in modern SOC operations:
1. The "Single Source of Truth" for Unified Visibility
A cyber data lake centralizes telemetry from endpoints, networks, and cloud platforms into a unified, vendor-neutral repository. With standardized schemas such as OCSF, analysts can correlate activities across the entire attack chain through a single query, improving both detection and response efficiency.
2. Powering Long-Tail Threat Hunting and Retrospective Analysis
Unlike traditional SIEMs that focus on short-term, real-time detection, a data lake enables analysts to query years of historical data. This makes it possible to conduct “look-back” investigations and uncover low-and-slow attacks or previously undetected indicators of compromise.
3. Enabling Security Data Science and Advanced Analytics
By exposing data in open formats, the data lake supports large-scale querying, complex joins, and machine learning workflows. This allows teams to build behavioral models and detect anomalies that go beyond rule-based detection.
4. Reducing Tool Lock-In with a Flexible Analytics Ecosystem
The decoupled architecture allows multiple compute engines to operate on the same dataset. This enables a best-of-breed approach, reduces vendor lock-in, and allows the SOC to evolve its analytical capabilities without restructuring its data foundation.
The Semantic Layer: Security Ontology and Ontology Enforcement
The cyber data lake helps solve the “data gravity” issue by centralizing petabytes of telemetry, but it also introduces a new challenge: semantic complexity. In a disaggregated architecture where storage is decoupled from compute, raw data often remains a collection of semantic silos, with opaque schemas and cryptic technical headers. For a SOC to transition into the agentic era, where AI agents assist in threat hunting, there must be a bridge between raw storage and intelligent reasoning.
This bridge is built on Security Ontology and Ontology Enforcement.
1. Security Ontology and Ontology Enforcement
To understand how these concepts transform a data lake, we must distinguish between the raw schema and the logical meaning:
- Security Ontology: A formal, semantic representation of the security domain. It sits above the physical tables in the data lake, mapping technical logs (e.g., sys_log_82, flow_v5) into meaningful business entities like "Actor," "Asset," "Vulnerability," and "Lateral Movement." It defines not just what the data is, but how entities relate (e.g., "User X owns Device Y" or "IP A initiated Connection B").
- Ontology Enforcement: The active, real-time validation of queries against the defined ontology. It acts as a gatekeeper that ensures any query, whether written by a human or generated by an AI agent, adheres to the structural and logical rules of the security domain.
2. Ontology Enforcement in a Decoupled Architecture
In a modern cyber data lake, storage (e.g., S3 or Azure Blob) is decoupled from compute engines such as Athena, Snowflake, or Databricks. While this separation provides scalability and flexibility, it also introduces a critical challenge: semantic drift. Different teams, tools, or AI agents may interpret and query the same raw data in inconsistent ways, leading to fragmented and unreliable insights.
Ontology Enforcement addresses this by introducing a unified semantic control layer at the point of query. Instead of allowing each engine or user to directly interpret raw schemas, all queries are validated and executed against a shared ontology. This ensures that data is not only accessed consistently, but also understood and reasoned about in a uniform way across the entire ecosystem.
3. Benefits: From "Semantic Fog" to Agentic Clarity
The primary beneficiary of an enforced ontology is the AI Security Agent. Without it, agents struggle with "semantic fog": getting lost in complex join logic or hallucinating relationships between data points.
- Eliminating Semantic Hallucinations
In complex security environments, AI agents often produce queries that are "Syntactically Correct, but Logically Wrong." An agent might successfully join two tables but use a relationship that doesn't exist in the real world. Ontology enforcement acts as a "guardrail," forcing the agent to follow a validated roadmap of how security data interacts, eliminating silent failures. - The "Feedback Loop" for Self-Correction
Standard database errors lack sufficient semantic context. Ontology enforcement provides Structured, LLM-Readable Feedback. If an agent attempts an invalid join, the system explains why in semantic terms. This allows the agent to self-correct and further learn the environment's logic through fine tuning or reinforcement learning.
4. Data Access with AI assistant
Moving beyond architectural considerations, PuppyGraph provides a seamless, agent-driven interface for direct data interaction. Its built-in agent enables both developers and business users to explore complex datasets through intuitive, conversational queries.
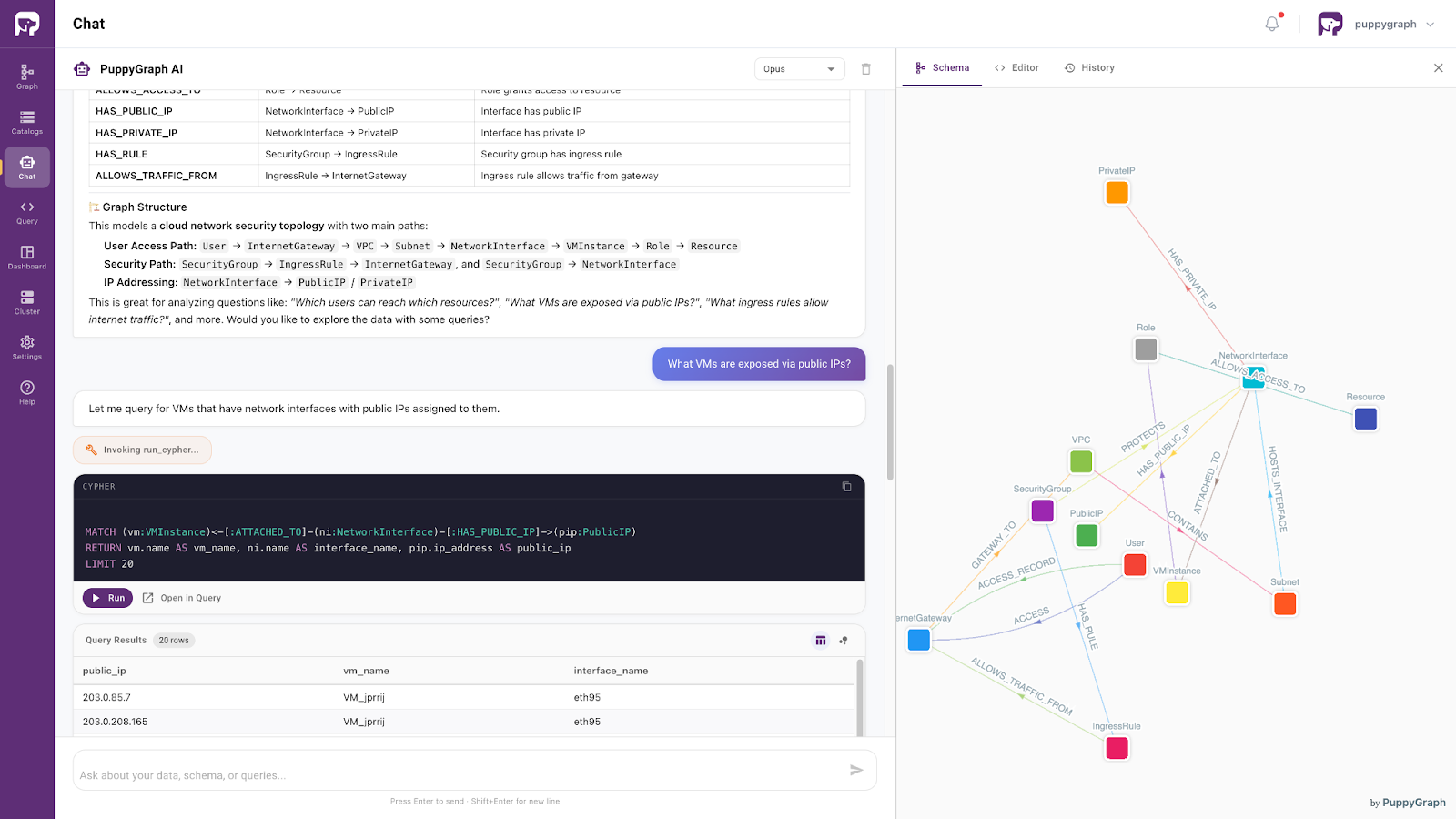
Powered by the same ontology-enforced foundation, the agent supports precise, natural language-based data access. It understands user intent within a well-defined semantic context and retrieves relevant information accordingly. As a result, the cyber data lake evolves from a static, technical system into an interactive and responsive layer: one that preserves semantic consistency while delivering clear, human-readable insights.
Conclusion
The cyber data lake represents a structural evolution in how security data is stored, accessed, and analyzed. By breaking the constraints of traditional SIEM systems, it enables organizations to retain full-fidelity telemetry, support diverse analytical engines, and perform deep retrospective investigations across years of data. This shift transforms security operations from reactive monitoring into proactive intelligence gathering.
However, unlocking its full potential requires more than scalable storage. As complexity grows, semantic consistency becomes critical. With the introduction of security ontologies and ontology enforcement, cyber data lakes can provide a unified meaning layer that ensures consistent interpretation across tools and AI agents. Together, these capabilities establish a foundation for a more automated, intelligent, and resilient SOC. Explore more with the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install