

What Is Data Lakehouse?

The rapid growth of enterprise data has created increasing demand for architectures that can support scalable storage, real-time analytics, and advanced artificial intelligence workloads simultaneously. Traditional data lakes provide flexible and low-cost storage for massive datasets, while data warehouses offer strong governance, transactional consistency, and high-performance analytics. However, maintaining these systems separately often introduces operational complexity, data duplication, and higher infrastructure costs.
To address these limitations, the data lakehouse architecture has emerged as a unified solution that combines the strengths of both data lakes and data warehouses. By integrating cloud object storage with metadata management, ACID transactions, and distributed query processing, lakehouses enable organizations to support business intelligence, machine learning, and real-time analytics within a single platform. This article explores the architecture, core technologies, advantages, and practical use cases of modern data lakehouse systems.
What Is a Data Lakehouse?
A data lakehouse is a unified data architecture that combines the scalability and flexibility of a data lake with the data management and transactional capabilities of a data warehouse. Instead of maintaining separate systems for raw storage and analytical processing, organizations can use a lakehouse to support both functions within a single environment.
Traditional data lakes were designed to store large amounts of raw data at low cost. However, they often lacked strong governance, schema enforcement, transactional consistency, and high-performance querying. Data warehouses solved these issues but typically required expensive infrastructure and rigid schema definitions.
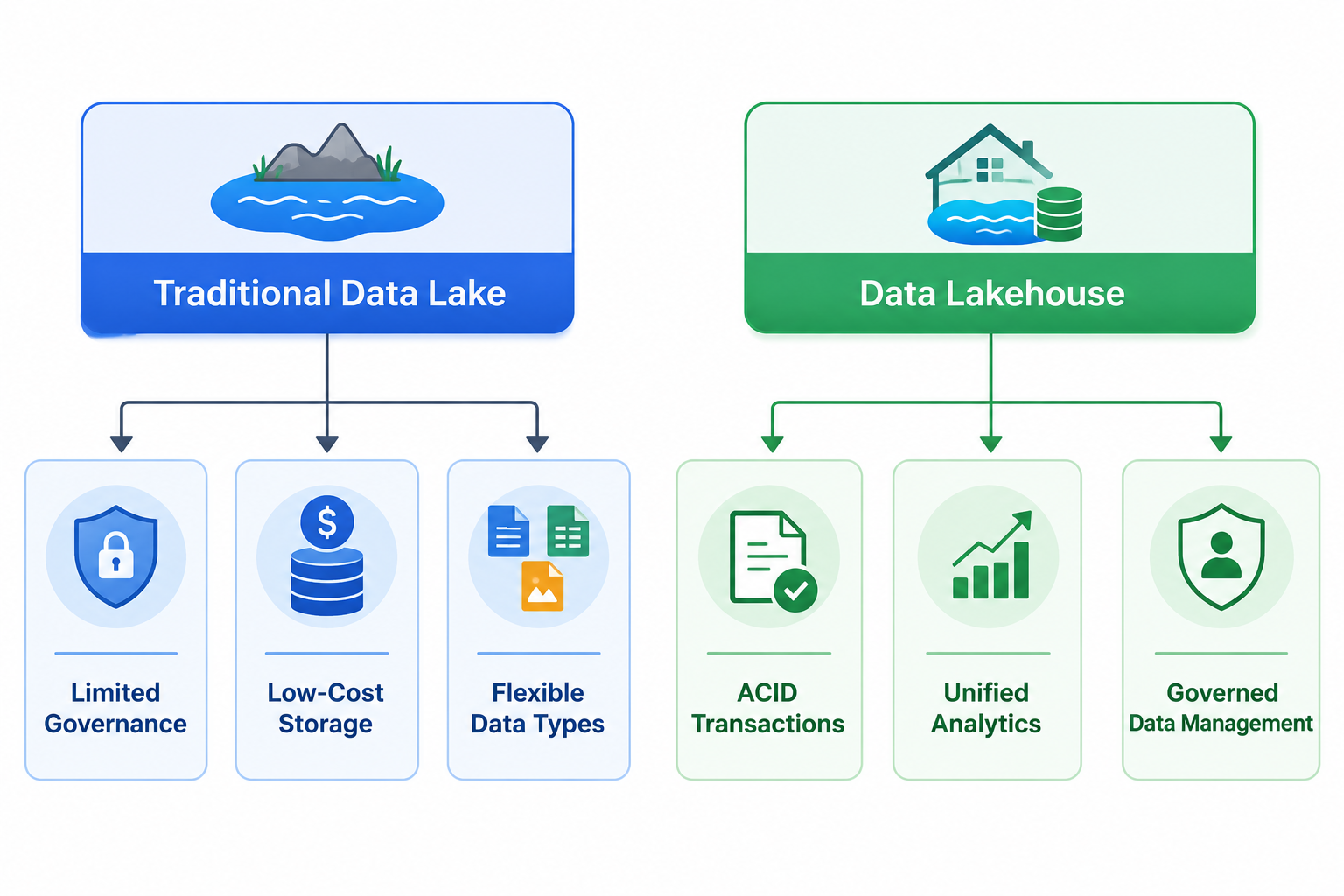
The lakehouse model bridges this gap by adding warehouse-like features directly on top of cloud object storage systems. These features commonly include ACID transactions, schema enforcement, metadata management, indexing, and performance optimization.
A modern lakehouse architecture enables organizations to ingest streaming and batch data, support SQL analytics, train machine learning models, and manage enterprise-grade governance policies from the same platform. As a result, data teams can simplify infrastructure while accelerating analytical workflows.
Core Characteristics of a Data Lakehouse
A typical data lakehouse includes several defining capabilities:
- Open storage formats such as Parquet or ORC
- Separation of compute and storage resources
- Support for structured and unstructured data
- Transactional consistency with ACID guarantees
- Unified analytics and machine learning support
These features allow businesses to scale efficiently while avoiding the duplication and operational complexity often associated with traditional data platforms.
How a Data Lakehouse Combines Data Lakes and Data Warehouses
The primary innovation of a data lakehouse lies in its ability to merge the strengths of two historically separate systems. To understand this hybrid approach, it is useful to examine how data lakes and data warehouses differ.
Data lakes prioritize flexibility and low-cost storage. They can store raw logs, images, video files, IoT data, documents, and relational datasets without predefined schemas. However, they often become difficult to govern and optimize as data volumes increase.
Data warehouses focus on structured analytics and reporting. They provide optimized SQL performance, schema governance, indexing, and data consistency. Yet warehouses usually require expensive ETL pipelines and struggle with unstructured or rapidly evolving data.
A lakehouse integrates both approaches into one architecture.
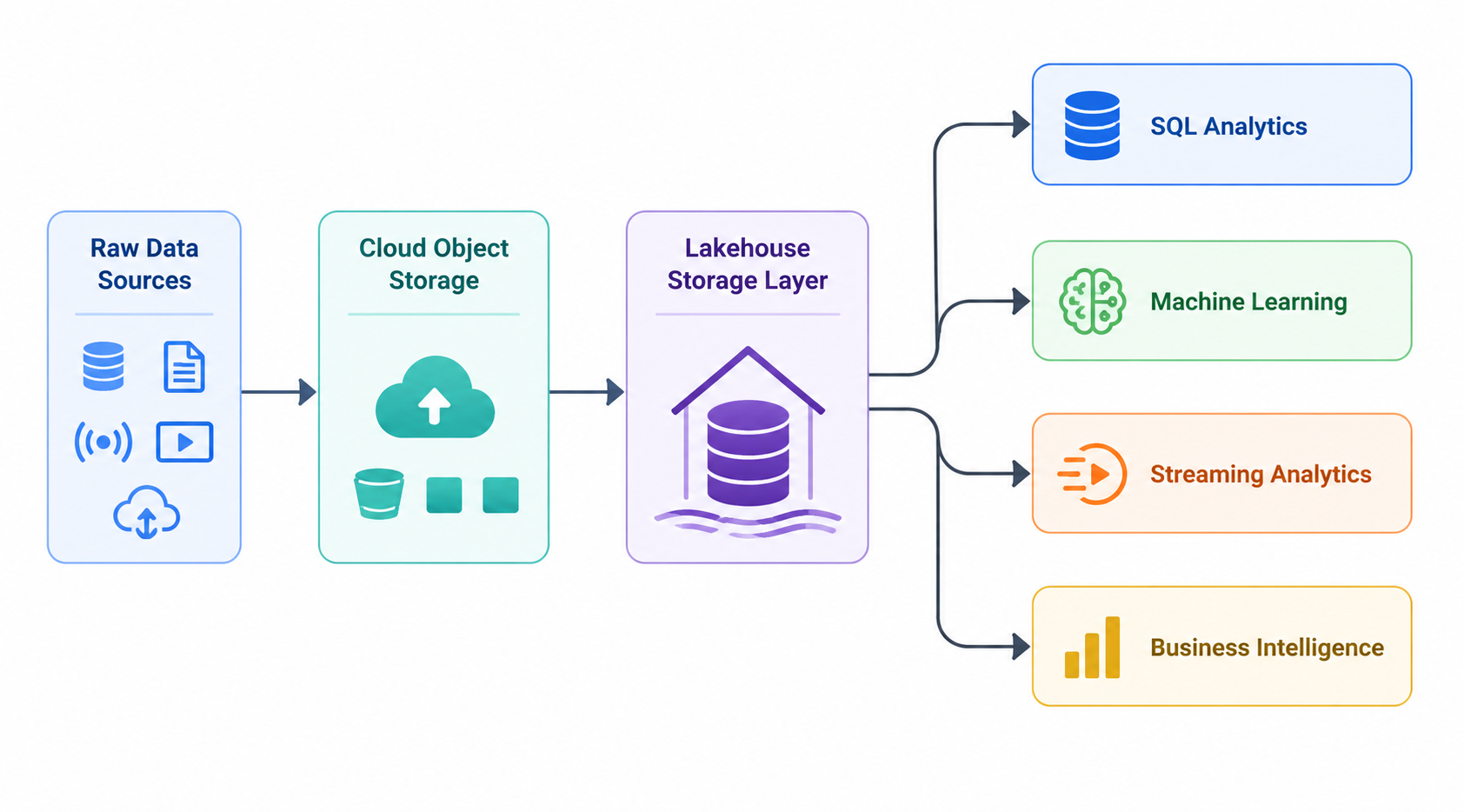
In a lakehouse environment, raw data is stored in scalable cloud object storage while metadata and transactional layers provide warehouse-like reliability and performance. Analysts, engineers, and data scientists can access the same datasets without copying them into separate systems.
Eliminating Data Silos
One major advantage of lakehouse architecture is the elimination of data silos. Traditional architectures frequently require moving data between ingestion platforms, lakes, warehouses, and machine learning environments. These repeated transfers increase operational overhead and introduce data inconsistency risks.
By centralizing data storage and analytics, lakehouses reduce duplication and allow different teams to work from a shared source of truth.
Supporting Multiple Workloads
Another critical benefit is workload consolidation. A single lakehouse can simultaneously support:
- Real-time analytics
- Interactive SQL queries
- AI and machine learning
- Data engineering pipelines
- Dashboard reporting
This flexibility significantly improves organizational agility while reducing infrastructure costs.
Key Components of Data Lakehouse Architecture
A data lakehouse consists of several interconnected architectural layers that work together to provide scalability, governance, and analytical performance.
Storage Layer
The storage layer forms the foundation of the lakehouse. Most modern lakehouses rely on cloud object storage services such as Amazon S3, Azure Data Lake Storage, or Google Cloud Storage.
These storage systems provide virtually unlimited scalability at relatively low cost. Data is usually stored in open file formats like Apache Parquet, Avro, or ORC to ensure interoperability across tools and platforms.
Metadata Layer
The metadata layer is one of the most important differentiators between a lakehouse and a traditional data lake. This layer tracks schemas, file versions, partitions, access permissions, and transactional information.
Technologies such as Delta Lake, Apache Iceberg, and Apache Hudi commonly provide these capabilities.
The metadata layer enables:
- ACID transactions
- Time travel queries
- Schema evolution
- Concurrent data operations
- Data version control
Without strong metadata management, maintaining reliability and governance at scale becomes difficult.
Compute Layer
The compute layer handles data processing and analytics workloads. Modern lakehouses often separate compute from storage, allowing organizations to scale processing resources independently.
This layer typically includes engines such as:
- Apache Spark
- Trino
- Presto
- Flink
- Snowflake
- Databricks SQL
Because compute resources are elastic, organizations can optimize performance and cost efficiency based on workload requirements.
Governance and Security Layer
Governance capabilities ensure data quality, compliance, and secure access management. Lakehouses often integrate identity management, encryption, auditing, lineage tracking, and role-based access controls.
These features are essential for enterprises operating under regulations such as GDPR, HIPAA, or CCPA.
Data Consumption Layer
The final layer supports downstream consumption through dashboards, BI tools, APIs, notebooks, and machine learning environments.
Popular integrations include Tableau, Power BI, Looker, Jupyter notebooks, and AI frameworks such as TensorFlow or PyTorch.
How Data Lakehouse Technology Works
A data lakehouse operates by combining cloud-native storage with intelligent metadata management and distributed query processing. The architecture enables organizations to process large-scale datasets efficiently while maintaining governance and consistency.
Data Ingestion
Data ingestion typically begins with collecting information from operational databases, IoT devices, APIs, applications, and streaming platforms.
Lakehouses support both batch and streaming ingestion pipelines. Streaming technologies such as Apache Kafka or Apache Pulsar continuously feed data into the platform in near real time.
Data Storage and Formatting
Once ingested, data is stored in open columnar formats optimized for analytics. Columnar storage improves compression and query efficiency by reading only the relevant columns instead of scanning entire datasets.
Common storage formats include:
- Apache Parquet
- ORC
- Avro
These formats are highly efficient for analytical workloads involving large datasets.
Transaction Management
A defining feature of the lakehouse is transactional consistency. Technologies like Delta Lake and Apache Iceberg maintain transaction logs that record all changes to datasets.
This capability enables:
- Atomic writes
- Rollbacks
- Concurrent updates
- Reliable streaming ingestion
As a result, organizations can trust the integrity of analytical data even in complex distributed environments.
Query Optimization
Lakehouse systems improve performance through metadata indexing, caching, partition pruning, and query optimization techniques.
For example, if a query only needs sales data from a specific month, the engine can scan only relevant partitions rather than the entire dataset.
This dramatically reduces latency and infrastructure costs.
Unified Analytics
Perhaps the most valuable aspect of lakehouse technology is unified analytics. Analysts, engineers, and data scientists can all work on the same datasets without creating redundant copies.
This shared architecture accelerates collaboration and simplifies data operations across the organization.
Data Lakehouse vs Data Warehouse: Key Differences
Although lakehouses and data warehouses share some capabilities, they differ significantly in architecture, scalability, flexibility, and cost structure.
Flexibility
Data warehouses are optimized for predefined reporting and analytics use cases. However, changing schemas or integrating new data types can require significant engineering effort.
Lakehouses provide greater flexibility because they support both structured and unstructured data within open storage systems.
Cost Efficiency
Warehouses often rely on proprietary storage and compute infrastructure, which can become expensive at large scale. Lakehouses leverage lower-cost object storage while allowing compute resources to scale independently.
This separation improves cost control for data-intensive organizations.
AI and Machine Learning
Modern AI workloads frequently require access to raw images, logs, audio, and streaming datasets. Traditional warehouses struggle with these workloads due to rigid schema requirements.
Lakehouses are better suited for AI and machine learning because they can directly store and process diverse data formats.
Data Lakehouse vs Data Lake: Understanding the Comparison
Although lakehouses evolved from data lakes, the two architectures differ substantially in governance, reliability, and performance optimization.
Governance and Reliability
Traditional data lakes often suffer from poor governance practices, resulting in what many organizations call “data swamps.” Inconsistent schemas, duplicate files, and missing metadata can make analytics unreliable.
Lakehouses address these issues by introducing:
- Schema enforcement
- Transactional consistency
- Metadata indexing
- Data quality controls
These capabilities significantly improve trust in analytical results.
Performance Optimization
Data lakes generally require external query engines and extensive tuning to deliver acceptable performance. Lakehouses integrate performance optimization directly into the architecture through indexing, caching, and metadata acceleration.
This improves query speed for BI and analytical workloads.
Unified Workflows
A pure data lake often requires separate systems for BI analytics, machine learning, and streaming applications. Lakehouses consolidate these workloads into a unified platform.
As organizations seek to simplify infrastructure, this consolidation becomes increasingly valuable.
Benefits of Implementing a Data Lakehouse
Organizations adopt lakehouse architectures because they provide operational, analytical, and financial advantages across modern data ecosystems.
Reduced Infrastructure Complexity
Traditional architectures often require multiple disconnected systems for ingestion, transformation, analytics, and machine learning. Maintaining these systems increases operational complexity and engineering overhead.
A lakehouse consolidates many of these capabilities into a single architecture, simplifying management and reducing maintenance costs.
Lower Storage Costs
Because lakehouses typically rely on cloud object storage, organizations can store massive volumes of data more economically than in proprietary warehouse systems.
This becomes especially important for AI and IoT workloads generating petabytes of information.
Faster Innovation
Lakehouses enable teams to access raw and processed data from a shared environment. Analysts and data scientists can experiment more quickly without waiting for extensive ETL pipelines.
This agility accelerates product development, customer analytics, and AI innovation.
Improved Data Accessibility
A unified architecture improves collaboration across departments. Engineers, analysts, and business users can access consistent datasets through standardized interfaces and governance policies.
This reduces data fragmentation and improves decision-making quality.
Support for Advanced Analytics
Lakehouses are designed to support advanced analytical workloads such as:
- Machine learning
- Predictive analytics
- Real-time processing
- Generative AI applications
As AI adoption grows, this flexibility becomes increasingly valuable for enterprises.
Common Data Lakehouse Use Cases
Data lakehouses support a wide range of analytical and operational use cases across industries.
Business Intelligence and Reporting
Organizations use lakehouses to power dashboards, executive reporting, and operational analytics. High-performance SQL engines enable interactive analysis while centralized storage ensures consistent reporting data.
Machine Learning and AI
Data scientists can train machine learning models directly on raw datasets stored in the lakehouse. This eliminates the need to copy data into specialized ML environments.
Common applications include recommendation systems, fraud detection, and predictive maintenance.
Real-Time Analytics
Streaming ingestion technologies allow organizations to analyze events in near real time. Industries such as finance, retail, and logistics rely on this capability for operational monitoring and customer engagement.
Customer 360 Platforms
Lakehouses help organizations unify customer information from CRM systems, websites, applications, and support channels.
This centralized view enables more personalized marketing, improved customer service, and stronger retention strategies.
IoT and Sensor Data Processing
Industrial IoT systems generate enormous volumes of sensor data continuously. Lakehouses provide scalable storage and real-time analytics capabilities necessary for predictive maintenance and operational optimization.
Data Governance and Security in Data Lakehouse Environments
As organizations centralize large volumes of sensitive information, governance and security become critical components of lakehouse architecture.
Data Governance
Governance ensures that data remains accurate, consistent, discoverable, and compliant with regulatory requirements.
Effective governance practices include:
- Metadata management
- Data lineage tracking
- Schema validation
- Cataloging and discovery
- Quality monitoring
These processes improve trust in analytical outputs and reduce compliance risks.
Access Control
Lakehouses typically implement role-based access control (RBAC) and attribute-based access control (ABAC) to manage permissions across users and departments.
Granular access policies help organizations protect sensitive information while enabling secure collaboration.
Encryption and Compliance
Modern lakehouse platforms support encryption both at rest and in transit. Compliance frameworks such as GDPR, HIPAA, and SOC 2 often require strict security controls and audit capabilities.
Organizations handling regulated data must implement comprehensive governance strategies to maintain compliance.
Data Lineage and Auditing
Lineage tracking enables organizations to understand how data flows through pipelines and transformations. Auditing features record user activity, schema changes, and access events.
These capabilities are essential for troubleshooting, governance, and regulatory reporting.
Zero Trust Architectures
Many enterprises are integrating zero trust security principles into lakehouse environments. This approach assumes no user or system is trusted by default and continuously verifies identity and access permissions.
As cyber threats evolve, zero trust models are becoming increasingly important for cloud-native data platforms.
Beyond Infrastructure: Adding Semantics to Lakehouse Architectures
Choosing the right data architecture is only the first step. Even when organizations adopt modern data lakehouse platforms, another challenge remains: making enterprise data easier to understand, govern, and access consistently, especially for AI applications.
Although lakehouses unify structured, semi-structured, and unstructured data into a single environment, their schemas and storage structures often still reflect physical data organization rather than business meaning. Tables, partitions, metadata layers, and object storage formats describe how data is stored, but not always what the data actually represents.
A semantic layer helps address this gap.
The Role of a Semantic Layer
A semantic layer sits above the lakehouse architecture and exposes business concepts directly, such as Customer, Order, Product, or Transaction.
Instead of forcing applications or AI systems to reason through raw schemas, files, and joins, the semantic layer provides a higher-level logical model aligned with business meaning.
This allows developers and AI agents to work with enterprise data more naturally without changing the underlying lakehouse infrastructure.
Ontology and Ontology Enforcement
At the core of many semantic layers is an ontology: a formal definition of entities, relationships, and rules across the enterprise data environment.
An ontology defines:
- what entities exist
- how they relate to one another
- what relationships are valid
For example, a Customer may place an Order, an Order may contain a Product, and a Supplier may provide that product.
Ontology enforcement ensures that queries and updates across the lakehouse environment respect these rules. Whether data originates from an application, an analyst, or an AI agent, operations are validated against the semantic model to prevent inconsistent or logically invalid relationships.
Why It Matters: From Semantic Fog to Agentic Clarity
Without a semantic layer, working directly with large-scale lakehouse environments often shifts complexity into application code, making systems harder to maintain as they grow.
For AI systems, this challenge is even greater. Large language models and autonomous agents can become trapped in semantic fog: navigating inconsistent schemas, fragmented metadata, ambiguous relationships, and unclear business logic across enterprise datasets.
This often leads to operations that are syntactically correct but logically wrong.
An AI agent may successfully generate a query or connect two entities, yet create a relationship that does not exist in the real world.
Ontology enforcement acts as a semantic guardrail, ensuring that AI-generated reads and writes follow a validated model of how data entities interact. This reduces silent failures and improves trust in automated systems.
It also creates a valuable feedback loop for self-correction. Instead of returning only technical system errors, ontology-aware platforms can provide structured semantic feedback explaining why a query or operation violates business logic.
This allows AI systems to refine their behavior through iteration and better understand the rules of the enterprise data environment over time.
Data Access with AI Assistants
Moving beyond infrastructure alone, PuppyGraph provides a graph-based way to access and query lakehouse data as connected knowledge without requiring organizations to migrate everything into a native graph database.
This enables developers and AI systems to explore enterprise data through graph-style reasoning and relationship-aware retrieval while preserving existing lakehouse infrastructure investments.
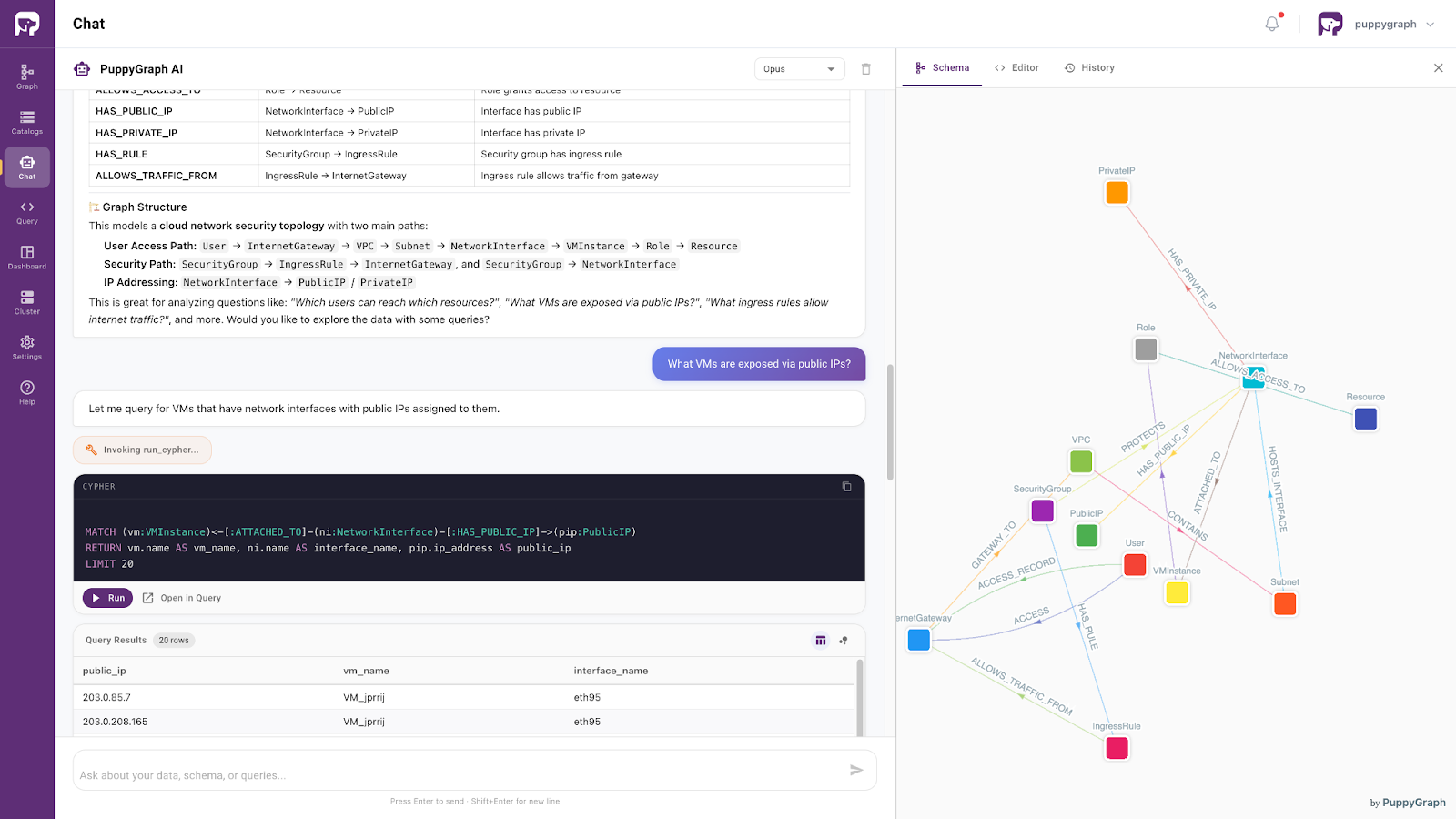
Powered by the same ontology-enforced foundation, this approach supports more precise, context-aware access to enterprise data. It allows AI systems to interpret user intent within a well-defined semantic framework and retrieve relevant information accordingly.
As a result, the lakehouse evolves from a passive storage platform into an active semantic foundation for AI, analytics, and next-generation autonomous agents.
Conclusion
In conclusion, the data lakehouse architecture represents a major evolution in modern data management by combining the scalability of data lakes with the governance and performance capabilities of data warehouses. Through unified storage, ACID transactions, metadata management, and distributed computing, lakehouses reduce infrastructure complexity while supporting analytics, real-time processing, and AI workloads within a single platform.
Beyond infrastructure optimization, the integration of semantic layers and ontology enforcement further enhances the value of lakehouse systems by improving data understanding, governance, and AI reliability. As organizations increasingly adopt AI-driven applications and autonomous agents, semantic-aware lakehouse architectures provide a strong foundation for accurate, context-aware, and scalable enterprise intelligence.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see how semantic graph access and ontology enforcement can transform your lakehouse into an AI-ready enterprise data platform.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install