

FalkorDB vs Neo4j: Key Differences

Once you’ve chosen a graph database, and once data pipelines, schemas, and operational processes form around it, changing direction becomes expensive. That’s why it’s important to understand what different graph technologies actually optimize for before committing your data to them. And through the progressively increasing adoption of graphs in modern systems, AI workloads have dramatically changed how teams use graphs.
So in this article, we talk about FalkorDB and Neo4j. We discuss how each system represents graphs, executes queries, and fits into a production stack. In the end, you will be better-equipped to decide whether you need another database, or simply a better way to query relationships without affecting your existing stack and complete migration.
What Is FalkorDB?

FalkorDB is an open-source, in-memory property graph database designed primarily for AI- and machine-learning–driven applications. A strong focus of it remains on GraphRAG and agent-based retrieval workloads. It runs as a native Redis module and exposes a Cypher-compatible query interface for querying highly connected data at low latency.
FalkorDB represents graph structure using sparse matrices and evaluates graph operations through linear algebra. By dint of this design, executions stay predictable for multi-hop expansions and aggregate graph queries.
Key Features
Property graph model with sparse-matrix representation
FalkorDB implements a labeled property graph model with nodes, relationships, and properties. Internally, relationships are represented as sparse adjacency matrices, storing only existing edges. Multi-hop traversals translate into matrix operations, allowing neighborhood expansion and path computation to execute as vectorized operations.
GraphBLAS-based query execution
Execution of graph operations abide by the GraphBLAS standard; so graph algorithms map to linear algebra primitives like matrix multiplication and reduction. You can do broad graph exploration, aggregation, or repeated pattern expansion with higher performance and parallelizability.
openCypher-compatible query language
FalkorDB supports an openCypher-compatible query surface for defining and querying graph patterns. Queries express nodes, relationships, filters, and variable-length paths in a declarative form familiar to Cypher users. The language surface integrates graph traversal with attribute filtering and projection.
Redis-native, in-memory runtime
FalkorDB runs inside the Redis process and operates primarily in memory. It inherits Redis’s low-latency access model and persistence mechanisms, which includes append-only files and snapshotting. Clients connect using Redis protocols, which means graph operations coexist with other Redis-backed workloads.
Multi-graph and multi-tenant support
A single FalkorDB instance can host many isolated graphs. Each graph maintains independent schema and data; you can do multi-tenant or multi-workload deployments without separate database instances.
Vector similarity and secondary indexing
FalkorDB can do vector similarity search, full-text search, and range-based indexing in addition to graph traversal. These capabilities allow queries to combine structural relationships with embedding-based or attribute-based retrieval within a single execution flow.
Clustering and high availability
FalkorDB supports replication and clustered deployments for availability and scale. Read replicas and distributed configurations allow graph queries to scale horizontally, while write behavior follows Redis’s consistency and replication semantics.
Bulk ingestion and integrations
FalkorDB includes bulk loading tools for initializing graphs from CSV data. It also integrates with common AI and retrieval frameworks, enabling graph-backed retrieval and reasoning workflows to run close to the data.
What Is Neo4j?

Neo4j is a native property graph database for transactional, application-facing graph workloads. It stores data as nodes and relationships with properties on both, and uses the Cypher query language. Neo4j treats the graph as the primary storage abstraction, optimized for frequent updates and deep traversals on live data. The Enterprise Edition extends the core engine with clustering, routing, and consistency controls required for high-availability production deployments.
Key Features
Native property graph storage
Neo4j implements a native property graph engine where relationships are first-class records stored with direct references between nodes, a method called index-free adjacency. It allows traversal cost to scale with the size of the explored subgraph. Properties attach directly to nodes and relationships, circumventing joining layers during execution.
Cypher query language
Neo4j uses Cypher, a declarative pattern-matching language built specifically for graphs. Queries describe node–relationship patterns, variable-length paths, and filters intuitively and in a form that maps closely to traversal logic. Cypher supports read and write operations, subqueries, and graph projections within a single query model.
ACID transactions
Neo4j provides fully ACID-compliant transactions for graph operations. Writes execute within transactional boundaries and become visible only after commit. This applies consistently across single-instance and clustered deployments for predictable behavior under concurrent access.
Cost-based query planning and execution
Neo4j includes a cost-based query planner that selects execution strategies based on available indexes, statistics, and query structure. The planner chooses traversal order, join strategies, and operator pipelines before execution. You can inspect query plans using EXPLAIN and PROFILE to understand runtime behavior.
Schema constraints and indexing
Although the property graph model is schema-optional, you can enforce explicit schema controls. These include uniqueness constraints, existence constraints, and type constraints on properties. Indexes accelerate node lookups and pattern matching and integrate directly with the query planner.
Clustering and replication (Enterprise Edition)
Neo4j Enterprise Edition supports clustered deployments with primary and secondary database roles. Writes route to a single leader per database and replicate synchronously to other primaries using the Raft protocol. Secondaries replicate asynchronously and serve read-only workloads. Each database operates as an independent Raft group.
Causal consistency
Neo4j supports causal consistency for read-after-write semantics. Clients can use bookmarks to make sure subsequent reads observe their own writes, even when reads execute on replicas. Routing logic in the drivers transparently coordinates this behavior.
Security and access control
In Neo4j Enterprise Edition, you get role-based access control with permissions scoped to databases, labels, relationship types, and procedures. Authentication integrates with external identity providers, and encrypted communication is supported through TLS.
Operational tooling
Neo4j has administrative tooling for database management, backup and restore, monitoring, and diagnostics. Metrics are exposed for external monitoring systems, and operational behavior remains consistent across standalone and clustered deployments.
FalkorDB vs Neo4j: Core Architecture Comparison
The following table compares these two solutions on storage models, execution schemes, consistency, and scaling mechanics.
When to Use FalkorDB
Graphs in AI inference paths (GraphRAG and agents)
Use FalkorDB when the graph sits directly inside AI or ML inference workflows, especially GraphRAG and agent memory. FalkorDB has been designed to assemble context quickly by combining relationship traversal with vector similarity and attribute filtering in one execution flow.
While both support AI, FalkorDB prioritizes inference-time retrieval, whereas Neo4j emphasizes durable state with integrated ML.
Low-latency, read-heavy graph retrieval
FalkorDB fits workloads dominated by read-heavy graph queries with tight latency budgets. Since it has an in-memory runtime and matrix-based execution it accommodates broad neighborhood expansion and aggregation; these are common in retrieval and recommendation-style queries.
You want to use Neo4j at selective, deep traversals with transactional guarantees. Consider if your queries fan out widely and latency sensitivity outweighs strict transactional semantics; then you will find FalkorDB’s execution model more natural and aligned.
Many small or isolated graphs
Choose FalkorDB when you need to manage large numbers of independent graphs within the same system. FalkorDB supports multi-graph, multi-tenant deployments with isolated schemas and data, befitting scenarios like per-tenant knowledge graphs or per-agent memory graphs.
Neo4j does support multiple databases, but the architecture and operational model usually assume fewer, larger graphs that act as primary application data stores.
Graphs as ephemeral or derived structures
FalkorDB works well when graphs are derived, regenerated, or updated frequently from upstream systems or models. Because it runs in memory and relies on Redis persistence mechanisms, it befits environments where the graph accelerates retrieval as opposed to serving as the system of record.
Neo4j is better suited when the graph itself is the authoritative store and must preserve strong transactional history and durability guarantees.
Redis-centric infrastructure
FalkorDB is the no-brainer option when your platform already depends heavily on Redis. FalkorDB integrates directly into Redis deployment, monitoring, and operational workflows. So you will reduce system sprawl and keep graph querying close to other low-latency data services by choosing FalkorDB.
On the other hand, Neo4j introduces a dedicated graph database stack with its own clustering, storage, and operational lifecycle.
When to Use Neo4j
Transactional graphs on the request path
Use Neo4j when the graph sits directly on the application request path and must support frequent reads and writes with strong consistency. There are systems where graph mutations are part of user-facing workflows; Neo4j’s ACID transaction model, write-ahead logging, and leader-based coordination make a strong case for those.
FalkorDB favors fast retrieval and aggregation during inference. It does not aim to provide the same transactional guarantees or write semantics expected of a primary application database like Neo4j.
Deep, selective traversals over live data
Neo4j comfortably handles deep, selective traversals, as opposed to workloads with broad fan-out. And as discussed, by dint of its pointer-based storage, traversal cost stays proportional to the explored subgraph, supporting pathfinding, identity resolution, and relationship-centric business logic.
FalkorDB’s matrix-based implementation supports wide expansion and aggregation. But Neo4j more naturally aligns with narrow, highly selective paths.
Graphs as systems of record
Choose Neo4j when the graph itself is a long-lived system of record. Neo4j manages durability, schema constraints, indexing, and historical consistency within a dedicated database engine. It suits domains where the graph defines core application state instead of derived context.
FalkorDB treats graphs as runtime structures that accelerate retrieval. It fits best when the authoritative data lives elsewhere.
Schema evolution tied to application logic
Neo4j works well when schema evolves alongside application code. Labels, relationship types, and properties act as application-level contracts that can change iteratively without coordinating shared ontologies or downstream consumers.
Although FalkorDB supports flexible schemas, it assumes graphs are shaped to support retrieval workflows rather than to model long-term domain semantics.
Enterprise clustering and governance needs
Neo4j Enterprise Edition provides clustering, role-based access control, backups, and operational tooling designed for large, multi-team environments. These features support predictable behavior under failure and clear governance boundaries.
FalkorDB relies on Redis’s clustering and security model, which prioritizes simplicity and low latency over database-native governance features.
AI and ML Workloads
While Neo4j excels in transactional scenarios, it also offers strong support for AI and ML, including GraphRAG for context-aware generative AI and agentic systems through integrations like MCP and LangGraph. Use it when combining durable state with advanced reasoning, for example, in fraud detection or knowledge management, where evidence suggests it outperforms in accuracy and explainability.
Which Is the Better Fit: FalkorDB or Neo4j?
The right choice depends on how the graph participates in your system and what guarantees it must provide.
Choose FalkorDB When Retrieval Drives the System
Pick FalkorDB when the graph exists to assemble context for AI and ML workloads. Its in-memory, matrix-based implementation suits fast neighborhood expansion, aggregation, and vector-aware retrieval. Graphs behave as runtime structures as opposed to long-lived state, which fits GraphRAG, agent memory, and inference-time reasoning.
Choose Neo4j When the Graph Owns State
Choose Neo4j when the graph is a primary application datastore. If your graphs evolve continuously and sit on the request path, Neo4j’s native traversal, ACID transactions, schema constraints, and enterprise clustering will support that.
So to summarize, choose FalkorDB if most of these apply:
- The graph supports AI inference instead of application state.
- Queries are read-heavy, low-latency, and aggregation-oriented.
- Graphs are derived or frequently refreshed.
Choose Neo4j if most of these apply:
- The graph drives live application behavior.
- Writes and transactional guarantees matter.
- The graph acts as a long-lived system of record.
Why Consider PuppyGraph as an Alternative
FalkorDB and Neo4j are great choices when the graph is the datastore, either as an in-memory retrieval graph (FalkorDB) or a durable transactional system of record (Neo4j). But many teams already have their source-of-truth data in warehouses, lakehouses, or operational databases and only need graph traversal to analyze relationships across it. In those cases, the main cost is not writing Cypher, it’s building ETL pipelines, duplicating data into a separate graph store, and keeping everything in sync. That’s where PuppyGraph comes in.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.

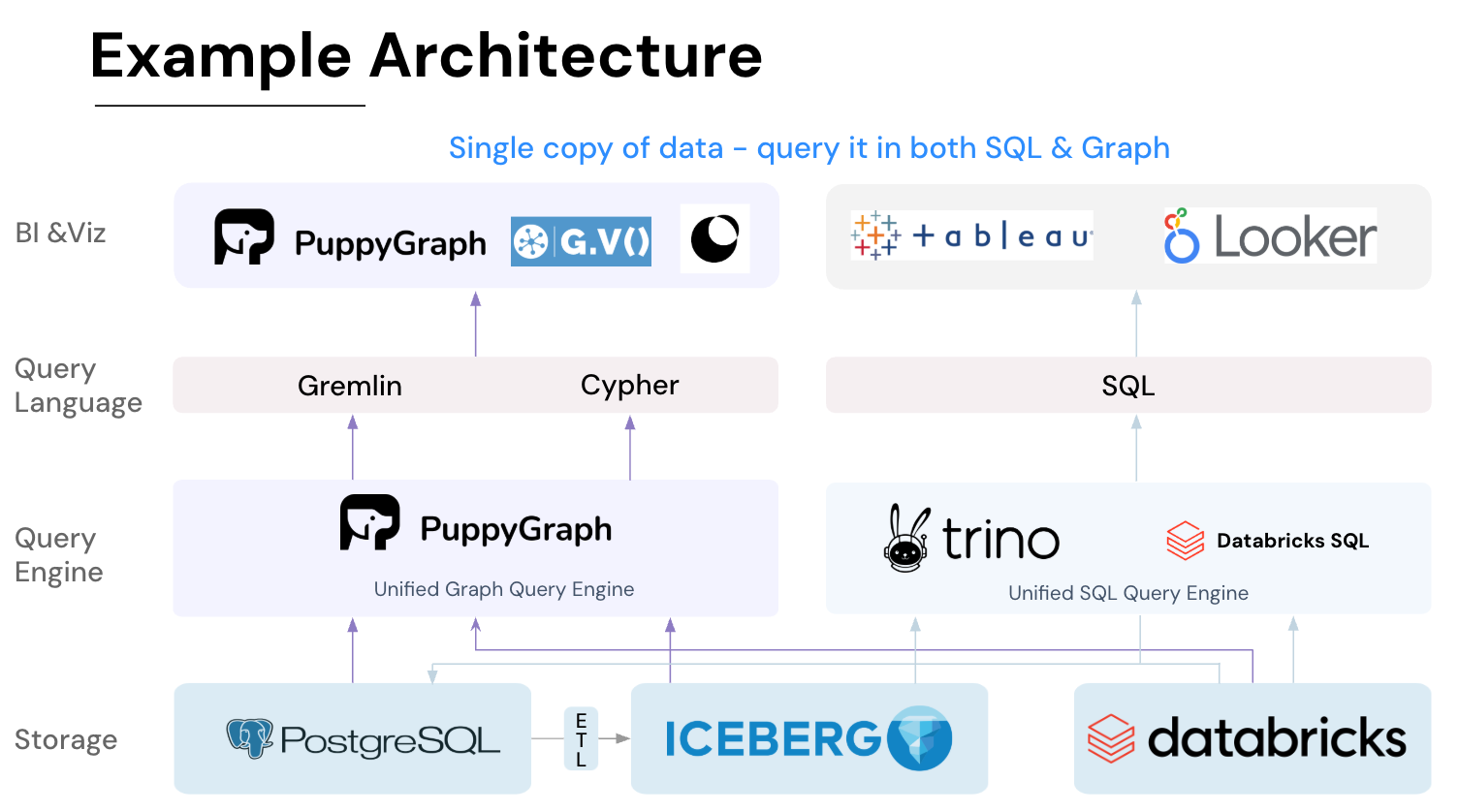
Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.

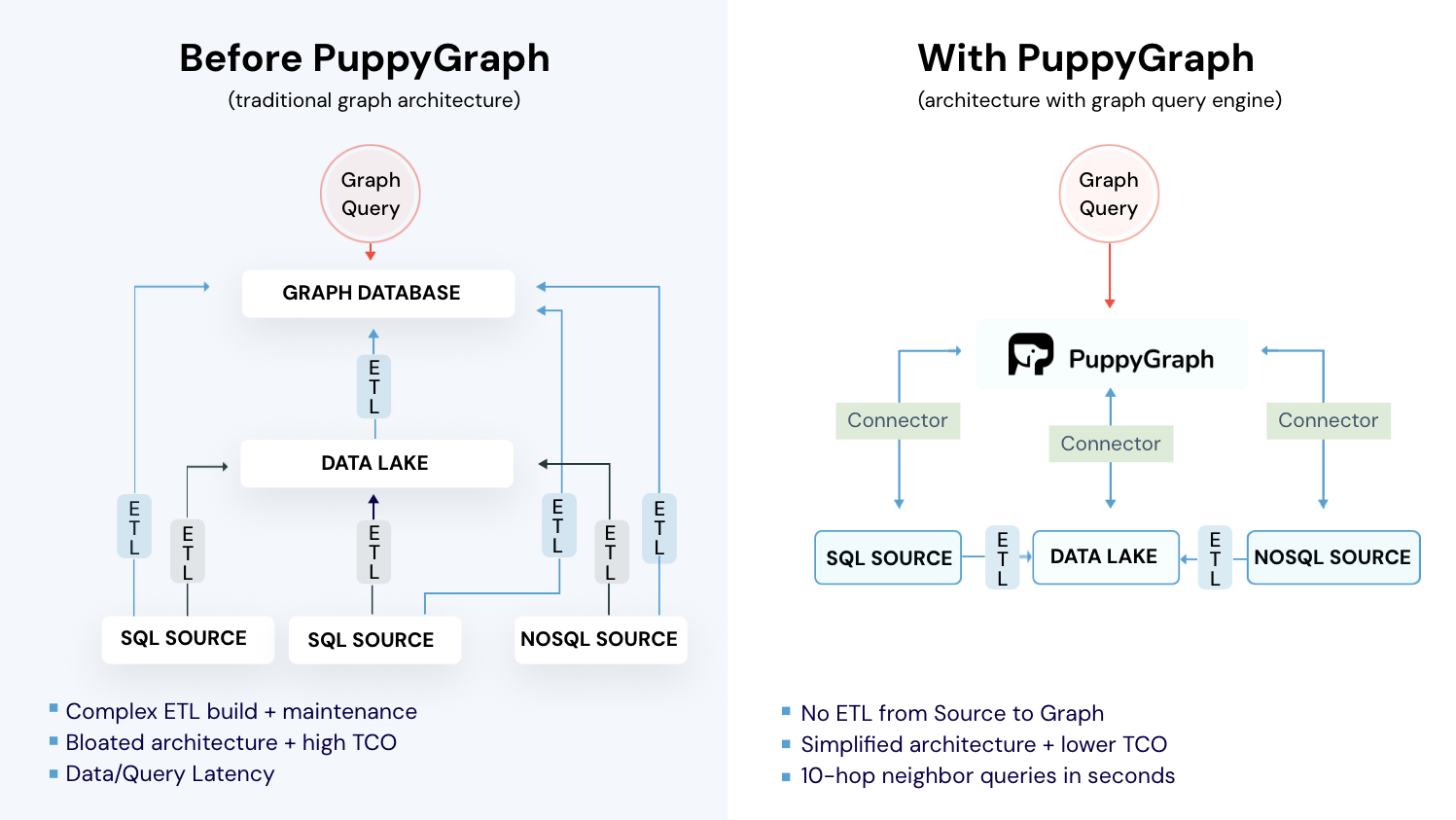
Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Teams usually run into trouble when they pick a graph solution before they’re clear on what the graph needs to do. Is it mainly for AI retrieval and assembling context at inference time? Or does the graph need to act as the system of record, with durable storage and transactional writes?
Each use case has tools that fit well on their own. But trying to make one system cover both usually creates drag: extra pipelines, duplicated data, stale copies, and slower iteration as new AI and analytics needs show up.
Start with your actual queries. If you do not need a stored graph, you may not need another database at all. You may just need better access to relationships in the data you already have. That’s where PuppyGraph fits: graph queries on top of your existing data, without the ETL overhead.
Want graphs without the ETL? Download our forever-free Developer edition or book a demo with the team.

Matt is a developer at heart with a passion for data, software architecture, and writing technical content. In the past, Matt worked at some of the largest finance and insurance companies in Canada before pivoting to working for fast-growing startups.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install