

What is Graph Aggregation?
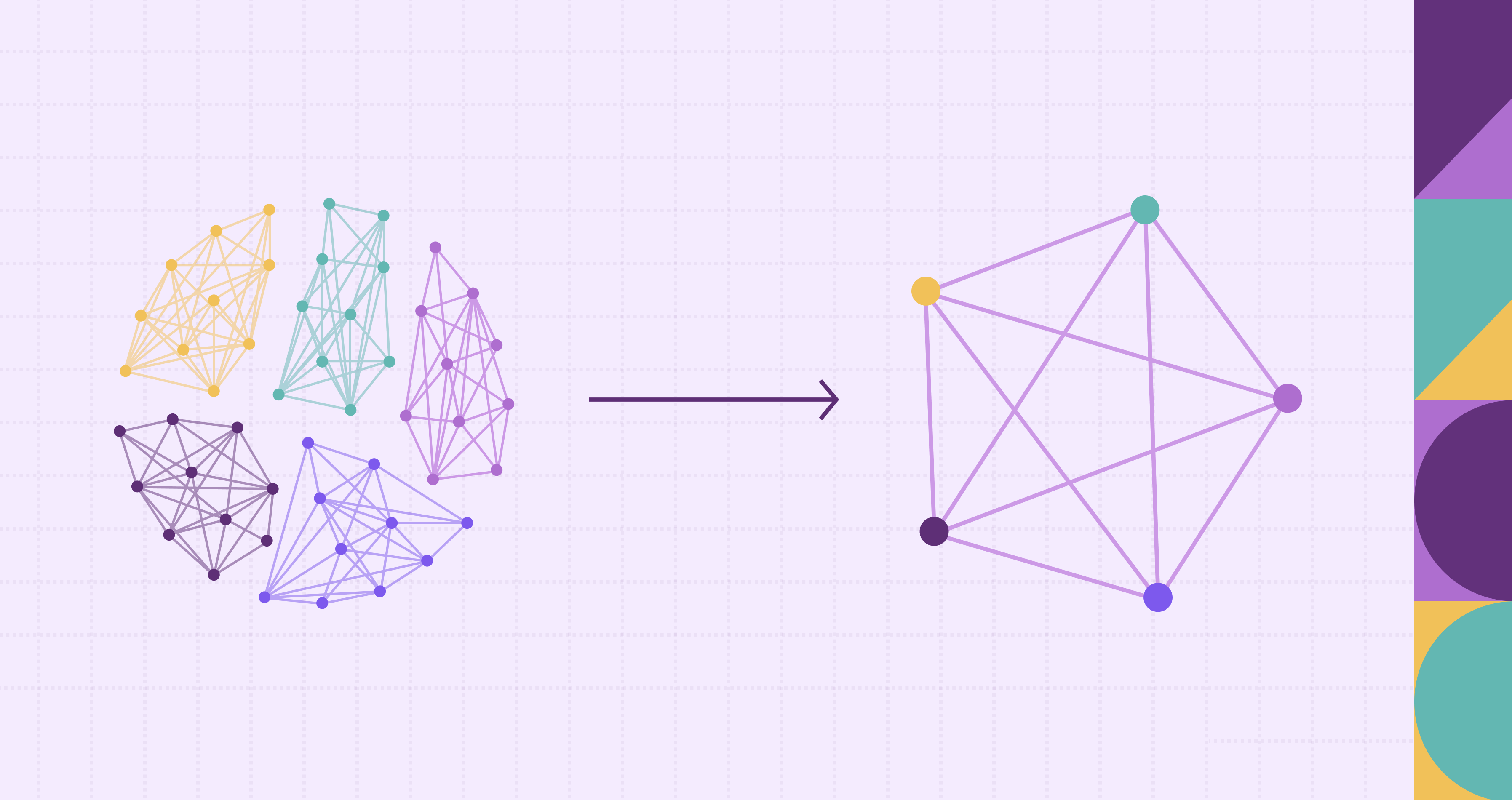
Graph data is increasingly pervasive across domains such as social networks, biological systems, knowledge bases, and transportation networks. Yet the rich connectivity that makes graphs powerful also makes them complex and challenging to analyze at scale. Graph aggregation emerges as a fundamental technique for summarizing this complexity, combining multiple nodes, edges, or substructures into simpler, more manageable representations while preserving essential information.
Through aggregation, one can compute global metrics, identify communities, compress redundant details, and enable faster analysis or downstream processing such as machine learning. In this article, we explore what graph aggregation is, why it matters, how it works, and the techniques involved. We also examine its essential role in modern graph neural networks (GNNs), highlight its benefits and limitations, and look ahead to future trends. The goal is to provide both a conceptual and practical understanding of graph aggregation, whether you’re a data scientist, researcher, or simply curious about graph analytics.
What is Graph Aggregation?
At its core, graph aggregation is the process of reducing or summarizing a graph’s structure or attributes by merging certain elements, nodes, edges, or subgraphs, in a mathematically or semantically meaningful way. Instead of working with every individual node or edge, aggregation allows us to treat groups of them as a single entity: for example, summarizing a social network’s entire community as one “super-node,” or collapsing multiple parallel edges between the same pair of nodes into a single weighted edge. The resulting aggregated graph is typically simpler, often smaller in size, and retains properties or statistics representative of the parts it summarizes.
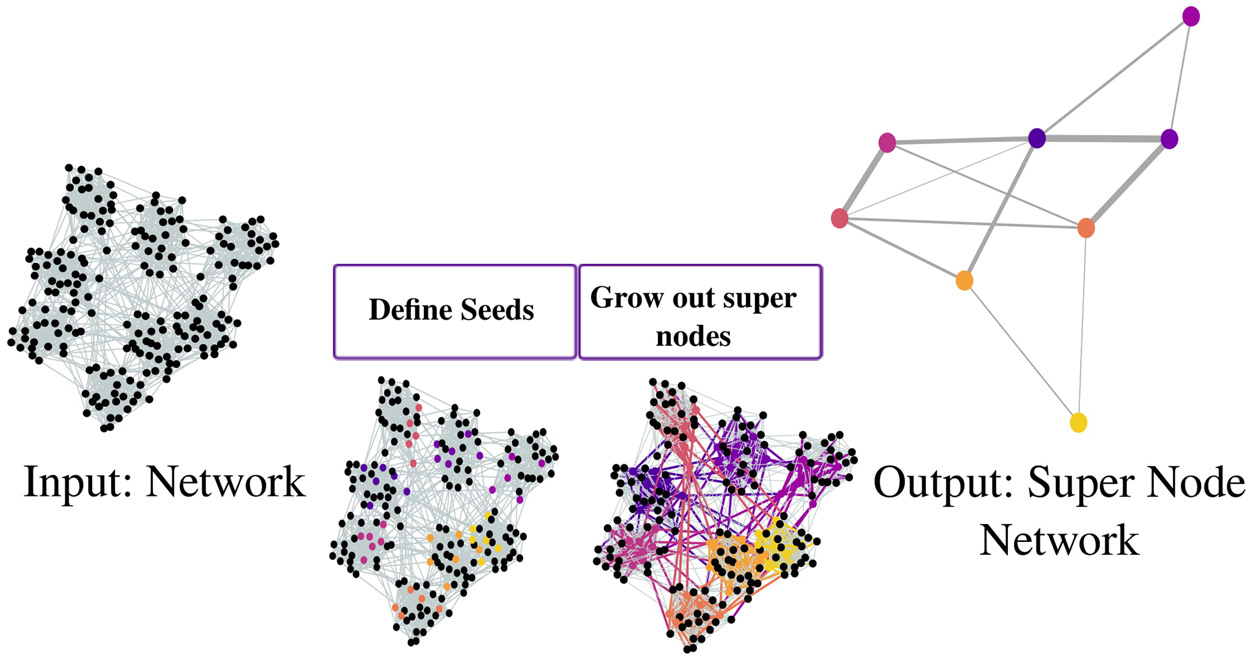
Graph aggregation is not just arbitrary merging. It is guided by criteria like node similarity, connectivity patterns, attribute values, or structural features. In some cases, aggregated entities are annotated with aggregated attributes: counts, averages, weights, or other summary statistics. This process helps analysts derive insights that would be difficult to see at raw graph scale, such as overall community interactions, connectivity bottlenecks, or aggregate flows. In short, graph aggregation is about compressing complexity while preserving insight.
Beyond mere simplification, graph aggregation is also a conceptual foundation for tasks like graph summarization, community detection, compression, abstraction, and coarsening. It enables working at different levels of granularity, from detailed node-level data to high-level summaries, which is particularly useful when dealing with very large graphs or when feeding data to machine learning models.
Importance of Aggregation in Graph Data Analysis
Graph data can be extremely large and complex, making direct analysis difficult. Aggregation helps transform raw graphs into manageable and interpretable forms:
- Scalability: Aggregating nodes or edges reduces computational and memory costs. Instead of computing metrics on millions of nodes, algorithms can operate at the community or cluster level, making tasks like path-finding, clustering, and centrality analysis far more efficient.
- Abstraction & Interpretability: Social, biological, or information networks often contain millions of entities. Aggregation exposes macro-structures, communities, groups, or functional modules, making it easier to understand who interacts with whom and how different regions of the graph behave.
- Noise Reduction & Generalization: Real-world graphs contain noise, outliers, or transient links. Aggregation filters these effects by emphasizing stable, high-level patterns, improving tasks like prediction, anomaly detection, and behavior modeling.
- Multi-Scale Analysis: Aggregation allows analysts to shift between fine-grained and coarse-grained views. This is essential for domains like biology (cell interactions), transportation (city vs. neighborhood flows), and knowledge graphs (facts vs. ontology-level structure).
How Graph Aggregation Works
Graph aggregation reduces graph complexity by merging nodes, edges, or subgraphs based on structural, attribute, or semantic criteria. This process preserves essential information while simplifying analysis, enabling scalable, interpretable, and efficient operations.
- Structural Aggregation
Structural aggregation groups elements according to connectivity or topology. Techniques like community detection or graph coarsening collapse tightly connected nodes into single units, preserving dense clusters, hubs, and macro-level network patterns. This approach highlights structural organization and is especially useful for visualizations or large-scale analytics. - Attribute-Based Aggregation
Here, elements are clustered based on similarity of properties or metadata. For instance, social network users can be grouped by location, age, or interests. This allows analysts to identify trends, generalize insights, and capture attribute-level patterns across similar entities. - Semantic Aggregation
Semantic aggregation leverages domain knowledge to group nodes or edges. In knowledge graphs, “employee” nodes can be aggregated under their “company,” or academic papers clustered by topic. This produces interpretable summaries aligned with real-world meaning.
Combining the above strategies often yields the most informative results. One might first detect structural communities and then aggregate nodes by attributes or semantics within each community. Hierarchical aggregation produces multi-level summaries, allowing analysts to shift between detailed and high-level views, balancing compression and interpretability.
Types of Graph Aggregation Techniques
Aggregation methods can also be classified by their operational focus, guiding how graphs are summarized and analyzed:
- Grouping-Based Aggregation
Nodes or edges are clustered into “supernodes” or “superedges” based on structural or attribute similarity. Communities of tightly connected nodes can be collapsed into single units, with edges representing interactions between groups. This reduces computational complexity while preserving coarse-grained structure. - Bit-Compression–Based Aggregation
Graphs are encoded compactly to minimize storage or transmission costs. Compression can be lossless (exact reconstruction) or lossy (trading detail for efficiency). This approach is particularly useful for very large or streaming graphs, prioritizing storage and I/O efficiency over interpretability. - Influence-Based Aggregation
Instead of preserving every node or edge, influence-based aggregation abstracts how behaviors, information, or influence propagate across the network. This supports tasks like diffusion analysis, reachability estimation, and influence maximization, capturing dynamic patterns rather than static structure.
These techniques can be applied individually or combined hierarchically. For example, nodes can first be grouped structurally, then compressed, and finally analyzed for influence patterns. Such multi-level aggregation balances interpretability, efficiency, and behavioral insight.
Graph Aggregation with Graph Neural Networks
Traditional graph aggregation is largely rule-based, merging nodes or edges according to structural, attribute, or community-level heuristics. This produces intuitive, interpretable super-nodes, but relies on manual rules and struggles with heterogeneous or high-dimensional graphs.
Graph neural networks (GNNs) adopt a learning-driven approach. Nodes iteratively gather and integrate information from neighbors via message passing, updating feature representations. Aggregation becomes feature-driven: nodes are combined in pooling or readout steps based on learned embeddings rather than fixed rules. This captures both graph topology and attributes in a unified, task-relevant summary.
Building on this, many approaches introduce pooling, clustering, or coarsening modules to form higher-level units, super-nodes and super-edges, producing compact graph-level or multi-scale representations. Unlike traditional aggregation, these learned methods compress structure while preserving relevant information for downstream tasks like classification, prediction, or similarity search.
GNN-based aggregation is flexible and adaptable. Learnable aggregators adjust to data and tasks, and hybrid methods can integrate structural and semantic information, which is valuable for heterogeneous graphs. Challenges remain, including potential information loss, higher model complexity, reduced interpretability, and scalability issues. Yet, GNN aggregation provides an end-to-end, differentiable framework that complements traditional methods, unifying structure, attributes, and learning objectives in graph summarization.
Node‑Level, Edge‑Level Aggregation and Graph Reduction
As we dig deeper into graph aggregation, three practical strategies stand out: node-level, edge-level aggregation, and graph reduction. Each simplifies the graph in a different way while preserving essential information.
- Node‑level aggregation groups nodes into “supernodes” based on similarity, connectivity, or structural roles. Tightly connected communities collapse into single entities, and edges between them become superedges. This preserves macro-level patterns like clusters, hubs, or community structure. Node-based aggregation is ideal for visualization or exploratory analysis, letting analysts grasp the overall network organization without being overwhelmed by individual nodes.
- Edge‑level aggregation merges or summarizes edges instead of nodes. Multiple interactions between the same pair of nodes, or edges with similar properties, are collapsed into weighted or virtual edges. This reduces redundancy in dense regions and clarifies relational patterns. Edge-level aggregation is especially useful for networks with repeated interactions or high edge density, enabling faster computation and highlighting link-level dynamics without altering the node set.
- Graph reduction simplifies the graph by selectively removing less important nodes or edges, producing a smaller, more manageable structure. Decisions about what to keep are based on metrics like importance, weight, or frequency. This approach works well for massive or streaming graphs, preserving critical connectivity while discarding less relevant details. Graph reduction provides a lean approximation that supports faster analysis and downstream tasks.
These three strategies offer flexible ways to manage graph complexity. Choosing the right approach, or combining them, allows analysts to transform large, intricate networks into concise, interpretable, and actionable summaries.
Benefits of Graph Aggregation
Graph aggregation offers several compelling advantages for graph analytics, visualization, and machine learning.
- Scalability and Efficiency: Aggregation condenses large graphs into manageable summaries, making algorithms feasible on limited hardware and speeding up queries by reducing the number of nodes and edges traversed.
- Interpretability: Aggregated graphs highlight high-level structures, communities, and interactions, reducing noise and outliers, aiding human analysis, reporting, and decision-making.
- Data Reduction: Summarizing repeated or high-frequency interactions compresses storage needs while retaining essential trends, useful for historical or frequently queried data.
- Machine Learning Robustness: Aggregation of neighborhoods or subgraphs helps generate generalizable representations, reducing overfitting and capturing stable structural or attribute patterns.
- Multi-scale Analysis: Aggregation allows shifting granularity from global overviews to detailed sub-community views, supporting flexible analysis in complex networks like disease spread, traffic, or knowledge graphs.
PuppyGraph: A Graph Query Engine
For many graph analytics tasks, rule-based aggregation, like grouping nodes by attributes, merging edges, or summarizing communities, can be expressed with graph queries. Analysts define aggregation rules and compute summaries without manually handling raw graphs, but executing these efficiently on large, multi-source datasets remains challenging.
PuppyGraph solves this by acting as a real-time graph query engine atop relational databases and data lakes. It allows users to perform rule-based aggregation directly on live data, compute super-nodes and merged edges, and explore communities interactively. This reduces overhead, avoids data duplication, and enables scalable, multi-hop analysis across billions of edges.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.

Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Graph aggregation is a powerful technique for simplifying complex, large-scale graphs into meaningful summaries by grouping nodes, merging edges, or selectively simplifying subgraphs, making analysis more scalable, interpretable, and efficient. Traditional rule-based aggregation merges elements according to predefined criteria, while modern approaches like graph neural networks explore learning-driven aggregation to adaptively capture patterns across nodes and edges. Whether for visualization, storage efficiency, community analysis, or generating embeddings, graph aggregation bridges raw graph data and actionable insights.
For teams looking to leverage the power of graph aggregation with graph queries on your raw data, PuppyGraph enables seamless, zero-ETL aggregation on your existing data, supporting multi-hop queries, dynamic summaries, and analytics-ready graph representations. Explore the forever-free PuppyGraph Developer Edition or book a demo to see how it can transform your data into actionable insights through advanced graph aggregation pipelines.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install