

What Are GraphFrames?
GraphFrames is the DataFrame-native graph library for Apache Spark, built around the bet that graph queries belong inside the same Catalyst-planned DataFrame pipeline that runs the rest of a Spark job, rather than alongside it on a separate runtime the way GraphX does with RDDs. The interesting framing is that GraphFrames sits inside the Spark ecosystem but outside Spark core, which shapes both what it can rely on (the entire DataFrame and SQL stack underneath) and what it has to ship for itself (its own release cadence, its own algorithms, its own evolution away from its older RDD-based sibling).
This post covers what GraphFrames is and where it currently stands in 2026, the data model and execution style that distinguish it from non-graph Spark code, how its internals lower graph operations onto DataFrame joins and aggregate-message primitives, the API surface for constructing a graph, a worked motif-finding example, and where the library fits relative to GraphX inside Spark and to graph engines that query graph-shaped data directly out of existing tables.
What are GraphFrames?
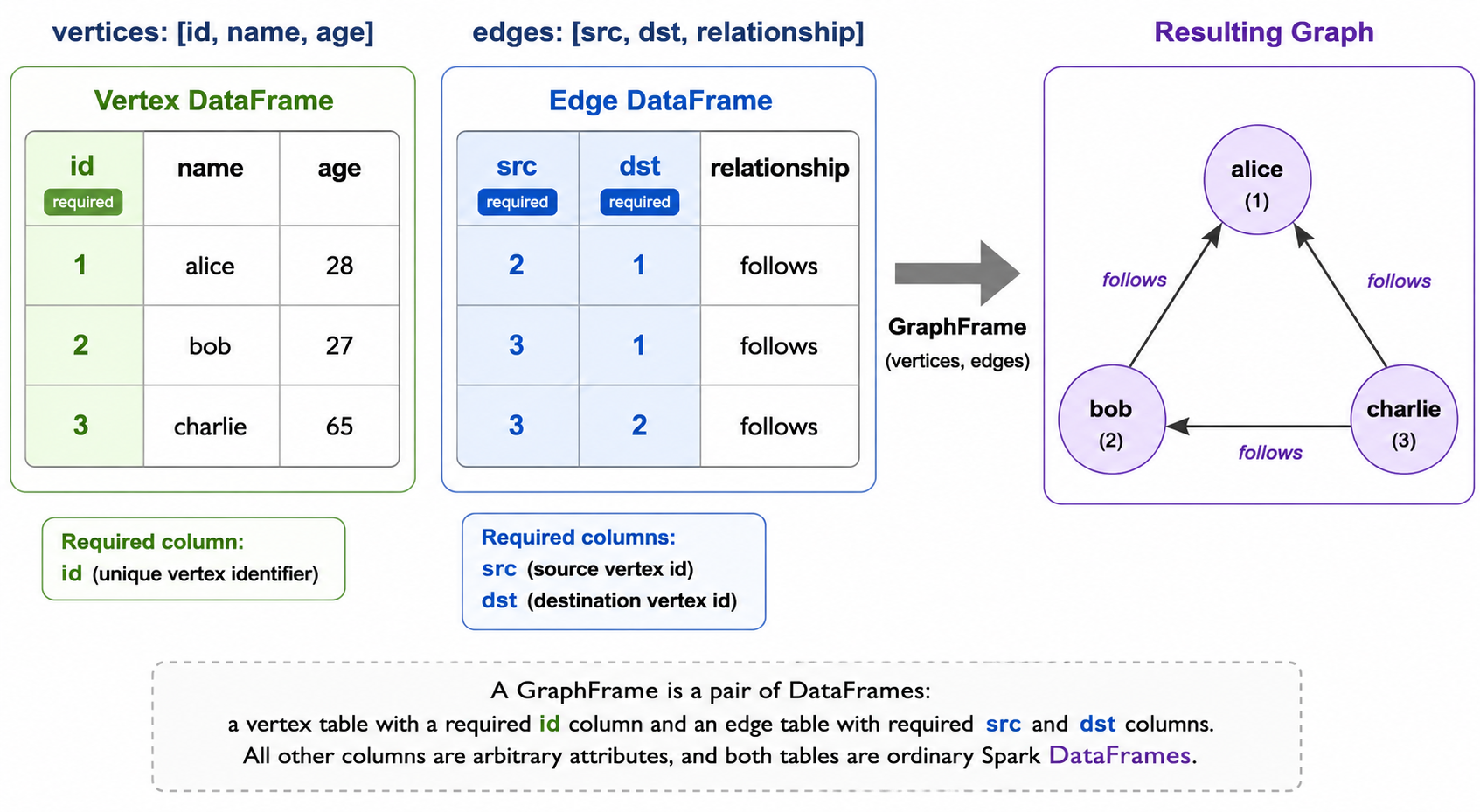
GraphFrames is a graph-processing package for Apache Spark, distributed separately from Spark itself and maintained primarily by Databricks contributors. It exposes a property-graph data model where a graph is a pair of DataFrames (a vertex DataFrame with a required id column and a typed edge DataFrame with required src and dst columns, both free to carry arbitrary additional attribute columns) and provides three things on top of that model: a set of graph operators (bfs, shortestPaths, subgraph-style filtering through DataFrame operations, aggregateMessages, and others), implementations of standard algorithms (PageRank, connected components, strongly connected components, label propagation, triangle count, shortest paths), and a motif-finding query language for declarative pattern matching over the graph.
The current release is 0.11.0, shipped in April 2026. The prior 0.9.3 release landed in September 2025; 0.9.2 earlier in 2025 marked the project’s return from a quieter maintenance period. Since 0.10.0 the package has used the io.graphframes namespace, replacing the older org.graphframes, and supports Spark 3.5.x and Spark 4.0.x. Documentation lives at graphframes.io. Bindings exist for Scala, Java, and Python, all first-class rather than only Scala with Java interop, which is the single largest practical reason PySpark-first teams pick GraphFrames over GraphX.
The relationship to GraphX is more layered than a clean replacement. From version 0.10.0 onward, GraphFrames maintains an internal fork of GraphX at org.apache.spark.graphframes.graphx, used to back algorithms that have not yet been reimplemented directly against DataFrame primitives. Newer releases progressively rewrite individual algorithms on DataFrame and aggregate-message foundations and shrink the fork’s surface; the trajectory is toward a self-contained DataFrame-native implementation, but the fork still does meaningful work in current releases. The common one-liner that GraphFrames is built on DataFrames is accurate but partial: the API is DataFrame-shaped, and an increasing share of the implementation is too, with a still-shrinking GraphX-shaped core underneath.
GraphFrames is also distinct from a graph database. There is no persistent graph store, no transactional model, no Cypher endpoint. The graph lives only for the lifetime of the Spark job that constructs it. Its role is graph computation and querying inside a Spark application, not graph storage.
In practical terms, GraphFrames is the option to reach for when the surrounding Spark pipeline is already DataFrame-based and likely written in Python. The graph is a pair of DataFrames, and most graph operations are lowered into ordinary DataFrame work that the rest of Spark already knows how to plan and execute, so the graph step fits into the pipeline without changing how the pipeline is written.
How GraphFrames work in Apache Spark
GraphFrames builds three things on top of Spark’s DataFrame machinery: a property-graph data type expressed as two DataFrames, a motif-finding query language for declarative pattern matching, and an aggregateMessages primitive for iterative algorithms.
Property graph as a pair of DataFrames. A GraphFrame is a wrapper around two DataFrames. The vertex DataFrame has a required id column and any number of additional attribute columns. The edge DataFrame has required src and dst columns referencing vertex ids, plus any additional attribute columns. Nothing about the schema beyond the required columns is fixed; the same GraphFrame machinery works for a social graph with (name, age) vertices and string edge labels, a financial graph with Account vertices and Transaction edges, or an infrastructure graph with Host vertices and NetworkFlow edges. Because the underlying tables are ordinary DataFrames, they can be read from Parquet, ORC, Iceberg, JDBC, or any other Spark-supported source, and they can be filtered, joined, or transformed with the full DataFrame API before being passed into the graph constructor.
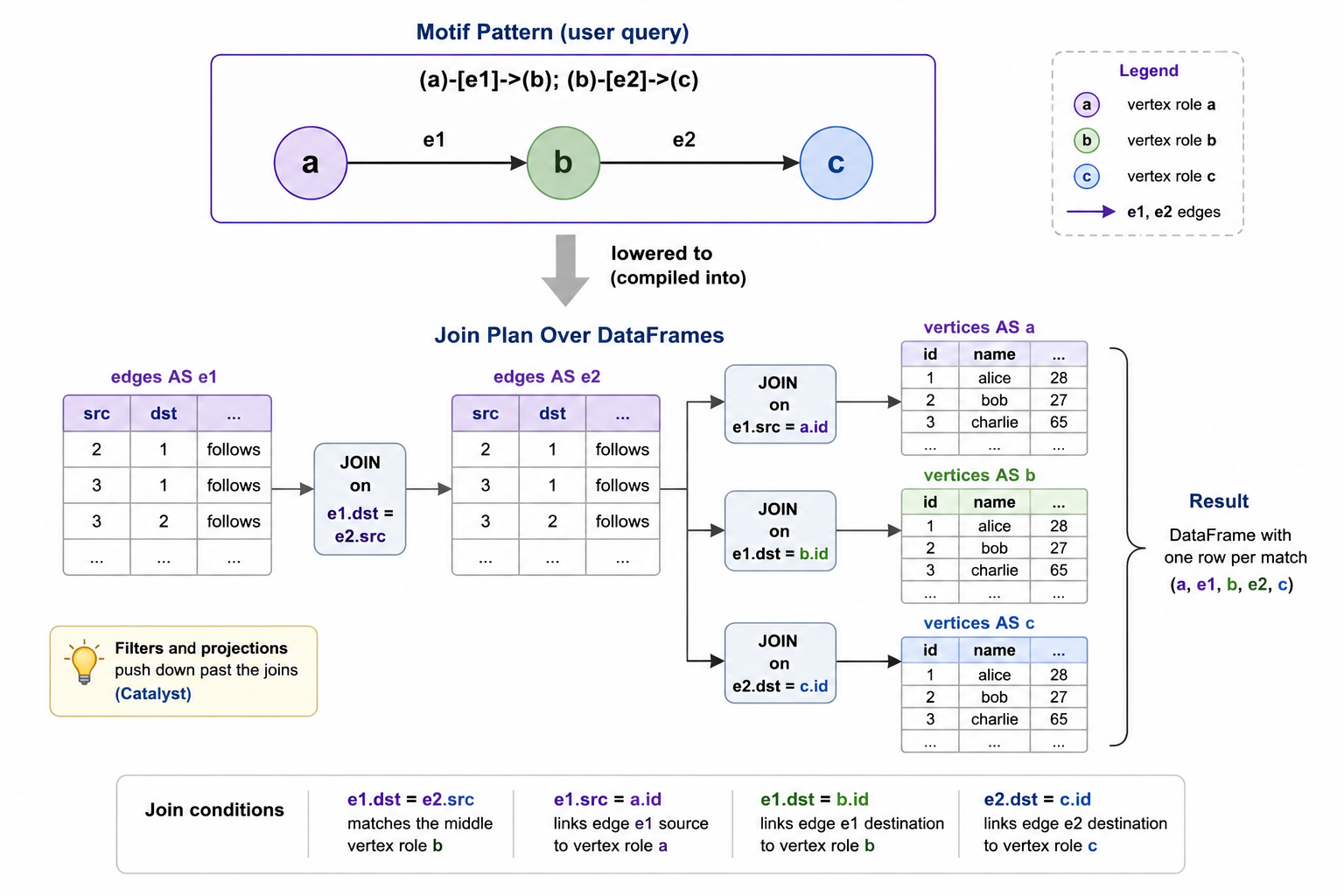
Motif finding. The distinctive query primitive is motif finding: stating a multi-hop pattern declaratively and getting back a DataFrame of all matches. Edges are written (a)-[e]->(b), multiple edges are separated by semicolons inside a single pattern string, named anonymous elements are allowed, and predicates are applied with ordinary DataFrame filter calls on the result. A two-hop or triangle query becomes a single declarative call rather than a chain of hand-rolled joins on the edge DataFrame.
Aggregate messages. Iterative algorithms like PageRank, label propagation, and single-source shortest paths share a structure where every active vertex sends a message along each outgoing edge, aggregates the incoming messages, and updates its own state. GraphFrames exposes this through aggregateMessages, which takes a per-edge specification of the messages to send to source and destination plus an aggregation function to combine messages incoming to each vertex. The result is a DataFrame keyed by vertex id, ready to be joined back into the vertex DataFrame for the next iteration.
The combined effect is that a GraphFrames program reads like ordinary DataFrame code with graph-shaped operators layered on top: construct a GraphFrame from two DataFrames, query it with motifs or operators, run an algorithm, write the resulting DataFrame back to wherever the rest of the pipeline consumes it. Nothing about the surrounding application has to change. The graph-shaped work is just a region of the job, and the region speaks the same language as the rest.
GraphFrames architecture explained
The interesting part of GraphFrames’s implementation is how it makes graph operations efficient on top of an abstraction (DataFrames) that was not originally designed with graphs in mind. Three internal mechanisms do most of the work.
Two DataFrames plus Catalyst. The vertex and edge DataFrames are kept as-is, partitioned and stored using whatever scheme the Spark session is configured for. Most graph operations then lower into joins between these two DataFrames and themselves: a one-hop traversal joins the edge DataFrame to the vertex DataFrame on src or dst, a two-hop traversal joins the edge DataFrame to itself, and so on. The optimization story is largely inherited from Catalyst, which means that filters get pushed down to the source, projections drop unused columns, and joins can be reordered by the planner based on statistics. The price is that GraphFrames lives entirely within the cost model of a DataFrame planner that does not know it is planning a graph traversal; the benefit is that the optimizer is the same one that already runs every other Spark stage in the job.
Motif finding lowered into joins. A motif like (a)-[e]->(b); (b)-[e2]->(c) is rewritten into a sequence of DataFrame joins on the edge and vertex DataFrames, with explicit equality predicates linking the named elements between edges. Anonymous edges ((a)-[]->(b)) collapse into the same shape with an unnamed join column. Repeated names refer to the same row, so a triangle motif (a)-[]->(b); (b)-[]->(c); (c)-[]->(a) ties the third edge back to the first vertex. The lowering is mechanical, and its cost is bounded by the cost of executing that sequence of joins, which is why motif queries scale well in the sparse-pattern regime but can become expensive when a pattern admits many intermediate matches that only a late predicate filters out. Predicates that apply to single vertices or edges should be expressed as DataFrame where clauses inside the motif, not after, so they push down past the joins.
Algorithms split between native and fork-backed. The set of built-in algorithms (PageRank, connected components, strongly connected components, label propagation, triangle count, shortest paths, breadth-first search) is the most visible part of the GraphFrames surface, and internally it is in transition. Algorithms that have been reimplemented on top of aggregateMessages and DataFrame operations run inside the same plan as the rest of the job. Algorithms still backed by the internal org.apache.spark.graphframes.graphx fork (a copy of the GraphX RDD-based code carried inside the GraphFrames package since 0.10.0) materialize the graph as RDDs for that algorithm, run the GraphX-style computation, and return the result as a DataFrame. The trajectory across recent releases has been to reduce the fork’s surface, and each new release typically retires a couple of fork-backed paths in favor of DataFrame-native ones.
Together, these three pieces let graph work sit inside an ordinary DataFrame plan instead of running alongside it as a separate runtime. GraphFrames gets Catalyst, the source-format ecosystem (Parquet, Iceberg, JDBC), and the full PySpark API in return. The cost is that the optimizer is graph-blind: it sees joins, not traversals, which is why pattern shape and predicate placement matter more here than in a graph-aware engine.
How to create a GraphFrame
GraphFrames gives a small set of ways to construct a graph, each suited to a different shape of input. The examples below use the Python API since first-class PySpark support is one of GraphFrames’s defining features; the Scala and Java APIs are structurally identical.
From explicit vertex and edge DataFrames. The default constructor takes the two DataFrames directly, requires the id / src / dst columns, and leaves the rest of the schema to the application.
from pyspark.sql import SparkSession
from graphframes import GraphFrame
spark = SparkSession.builder.appName("GraphFramesIntro").getOrCreate()
vertices = spark.createDataFrame([
("1", "alice", 28),
("2", "bob", 27),
("3", "charlie", 65),
], ["id", "name", "age"])
edges = spark.createDataFrame([
("2", "1", "follows"),
("3", "1", "follows"),
("3", "2", "follows"),
], ["src", "dst", "relationship"])
g = GraphFrame(vertices, edges)From edges alone. When the only meaningful information is the edge structure, the vertex DataFrame can be synthesized from the unique ids that appear as endpoints in the edge DataFrame, using ordinary DataFrame operations. This is the common pattern for raw edge lists that arrive without an explicit vertex table.
from pyspark.sql.functions import col
edges = spark.createDataFrame(
[("1", "2"), ("2", "3"), ("3", "4")],
["src", "dst"],
)
vertices = (
edges.select(col("src").alias("id"))
.union(edges.select(col("dst").alias("id")))
.distinct()
)
g = GraphFrame(vertices, edges)
From DataFrame-backed storage. Because the two inputs are ordinary DataFrames, any Spark-supported source works without further glue. A common production shape is to read vertices and edges from Parquet, Iceberg, or a JDBC source and hand them directly to the constructor.
vertices = spark.read.format("iceberg").load("warehouse.graph.users")
edges = spark.read.format("iceberg").load("warehouse.graph.follows")
g = GraphFrame(vertices, edges)Once a graph exists, attributes are reshaped with ordinary DataFrame transformations on g.vertices and g.edges, structural transformations are applied by filtering those DataFrames and reconstructing the GraphFrame, and aggregations across edges and their endpoints are expressed with aggregateMessages or motif finding. The constructors are the entry point. Almost all subsequent work is operator-level on DataFrames.
GraphFrames example with Apache Spark
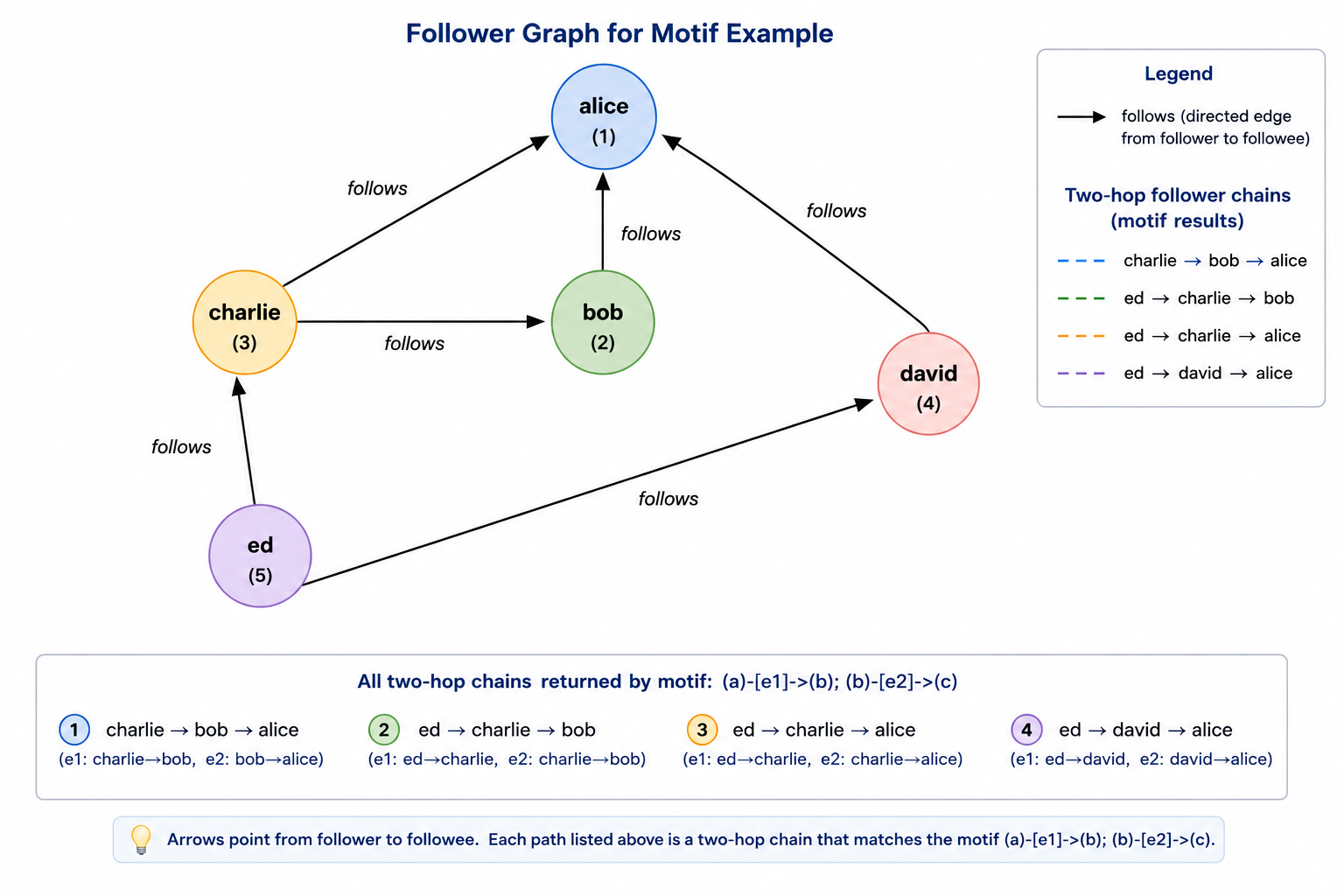
A short end-to-end example makes the pieces concrete. The following job builds a small follower graph, runs a motif-finding query to identify two-hop follower chains, and surfaces the result back as a DataFrame. Motif finding is chosen here over PageRank because it is the GraphFrames-distinctive API.
from pyspark.sql import SparkSession
from graphframes import GraphFrame
spark = SparkSession.builder.appName("GraphFramesMotifs").getOrCreate()
vertices = spark.createDataFrame([
("1", "alice", 28),
("2", "bob", 27),
("3", "charlie", 65),
("4", "david", 42),
("5", "ed", 55),
], ["id", "name", "age"])
edges = spark.createDataFrame([
("2", "1", "follows"),
("3", "1", "follows"),
("3", "2", "follows"),
("4", "1", "follows"),
("5", "3", "follows"),
("5", "4", "follows"),
], ["src", "dst", "relationship"])
g = GraphFrame(vertices, edges)
chains = (
g.find("(a)-[e1]->(b); (b)-[e2]->(c)")
.filter("a.id != c.id")
.select("a.name", "b.name", "c.name")
)
chains.orderBy("a.name", "c.name").show(truncate=False)Running this against a local Spark gives:
+-------+-------+-----+
|name |name |name |
+-------+-------+-----+
|charlie|bob |alice|
|ed |charlie|alice|
|ed |david |alice|
|ed |charlie|bob |
+-------+-------+-----+The four rows are exactly the two-hop chains in the graph: charlie follows bob who follows alice, ed follows charlie who follows alice, ed follows david who follows alice, and ed follows charlie who follows bob. The filter("a.id != c.id") clause excludes degenerate cases where the chain loops back to its starting vertex; without it, any reciprocal pair of follows in the graph would also appear as a length-two chain ending where it started.
The motif string (a)-[e1]->(b); (b)-[e2]->(c) names three vertices and two edges, ties the middle vertex b across the two edges by reusing the name, and is interpreted by GraphFrames as a request for every assignment of vertices and edges in the graph that satisfies the pattern. The result is a DataFrame with one column per named element (a, e1, b, e2, c), each column carrying the corresponding row from the vertex or edge DataFrame. The select then picks out the human-readable fields. The expressivity gain over hand-rolled DataFrame joins is most visible once the pattern grows: a triangle, a three-hop chain, or a star pattern is the same shape of query, with the lowering into joins handled by GraphFrames rather than the user.
Advantages of GraphFrames
The case for GraphFrames is largely a case for the DataFrame substrate and the languages and integrations that come with it.
First-class Python support. GraphFrames exposes its full API in Python, Scala, and Java, with no second-class subset. For teams whose Spark code is mostly PySpark, this is the deciding factor, because GraphX has no first-class Python binding and reaching it from PySpark requires Scala interop that most teams do not want to maintain.
DataFrame and Spark SQL integration. Because the vertices and edges are ordinary DataFrames, the surrounding pipeline can use the full DataFrame API and Spark SQL on them directly. Filters, joins with non-graph DataFrames, aggregations, and writes to Parquet, Iceberg, JDBC, or Delta all work without an extra adapter. Catalyst plans the work, including filters pushed down into the underlying source. Visualization, ad-hoc analysis with display() in notebooks, and downstream ML pipelines all consume the result without re-encoding.
Motif finding as a declarative pattern language. Stating a multi-hop pattern as (a)-[e1]->(b); (b)-[e2]->(c) and letting GraphFrames lower it into joins is more expressive than writing the equivalent join chain by hand. It also reads at the level of intent, which is what a reader of the code can recover months later. For pattern-shaped questions (chains, triangles, stars, fan-out / fan-in), this is the API that justifies the library on its own.
Active maintenance and a contemporary release cadence. GraphFrames is currently on 0.11.0 (April 2026), shipped through 0.9.2, 0.9.3, 0.10.0, and 0.11.0 over the past year and a half. The package’s namespace has been modernized to io.graphframes, Spark 4.0.x is supported alongside 3.5.x, and an active program is moving algorithms off the internal GraphX fork and onto DataFrame-native implementations. In a category where several once-prominent peers have entered maintenance mode or been retired, that cadence is itself a point in GraphFrames’s favor.
Taken together, these are also the reasons GraphFrames is the lower-friction choice whenever the broader pipeline is DataFrame-based, the language is Python, or the queries are pattern-shaped. Motif finding has no direct counterpart in GraphX. The Python API has no counterpart at all. The integration with Spark SQL and Catalyst is structurally tighter than GraphX’s, which lives one layer below in the RDD API. None of this makes GraphX obsolete, but it does explain why most Spark-shaped graph work that starts fresh in 2026 starts with GraphFrames.
Limitations of GraphFrames
GraphFrames inherits some constraints from its substrate and faces a few of its own.
Not part of Spark core. GraphFrames ships separately from Spark and has to be added explicitly as a dependency on every cluster and every notebook environment that uses it. Spark releases and GraphFrames releases are independent, so compatibility is documented per release pair rather than guaranteed by colocation. GraphX, in contrast, is part of every Spark release. For environments where adding packages is friction (locked-down internal platforms, restricted clusters), this gap matters more than the technical comparison suggests.
Motif costs scale with pattern shape. Because a motif lowers into a sequence of DataFrame joins, the cost of a query is the cost of executing those joins. Sparse patterns with selective predicates are inexpensive; patterns with many intermediate matches that only a late filter eliminates are not. Patterns longer than three or four edges, patterns that admit many cycles, and patterns where predicates apply only to the final result rather than to intermediate elements are the cases where users typically have to think about cost. Pushing predicates inside the motif rather than after it is the first lever.
Still graph-as-job, not graph-as-store. The graph exists only for the lifetime of the Spark job that constructs it. There is no transactional model, no continuous query, no graph index that survives across jobs, no low-latency point-traversal API. Every run reconstructs the graph from its source tables. For analytical workloads this is appropriate; for any workload that needs millisecond-latency graph traversal from a live application, GraphFrames is not the right shape.
No first-class label or edge-type concept. The data model GraphFrames exposes is a property graph, not a labeled property graph. Vertex and edge “types” are encoded as ordinary columns on the two DataFrames and filtered with predicates inside motifs, so label-based queries are predicate filters rather than indexed lookups. Engines built around the labeled property graph model that backs openCypher and Gremlin treat labels as a first-class concept and can use them in planning.
GraphFrames is one way to run graph workloads on data that lives in tables; another is to leave the data where it is and put a graph query engine in front of it. PuppyGraph takes the second route. Used in production by teams at Palo Alto Networks, Datadog, and Netskope, it connects directly to SQL warehouse and lakehouses, defines a labeled property graph schema over the existing tables where labels and edge types are part of the schema rather than ordinary columns filtered inside motifs, and answers openCypher and Gremlin queries against the graph. The tables stay the source of truth and are read in place: no ETL into a separate graph store, no Spark cluster between the data and the query, no graph to reconstruct at the start of every run. The cut is workload as much as architecture. The standard graph algorithms (PageRank, connected components, label propagation) are available on both sides; what differs is what each is built around. GraphFrames is built around batch graph processing inside a Spark job, with motif finding and aggregateMessages over a graph the job assembles as its primary surface. PuppyGraph is built around graph querying, with full Cypher and Gremlin against data in the warehouse as its primary surface and the same algorithms callable from inside those queries. A workload that wants PageRank over a freshly assembled DataFrame graph belongs in GraphFrames; a workload that wants to traverse relationships across lakehouse tables interactively belongs in a query engine over those tables.
Conclusion
GraphFrames takes the DataFrame API seriously enough to express graph queries and algorithms inside it, with motif finding and aggregateMessages as the two primitives that justify the abstraction. Its data model is a pair of DataFrames; its execution rests on Catalyst plus an aggregate-message primitive; its algorithm catalog is in the middle of moving from a vendored GraphX fork onto DataFrame-native implementations. For Spark-shaped graph work in 2026, especially in PySpark and especially when the queries are pattern-shaped, it is the natural starting point.
GraphFrames is also one option among several. Within Spark, GraphX is the older sibling, RDD-based, Scala-only, and built around the Pregel API for custom iterative programs rather than declarative motifs. Beyond Spark, graph query engines that read directly from existing warehouses and lakehouses occupy a different point in the design space, oriented toward interactive Cypher and Gremlin traversal rather than batch graph processing inside a Spark job.
Try the forever-free PuppyGraph Developer Edition and book a demo with the team to see how Cypher and Gremlin queries over warehouse and lakehouse tables, with no graph-specific ETL, fit alongside a GraphFrames-based step.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install