

What Is GraphRAG Knowledge Graph?
.png)
As large language models power ever more powerful AI applications, a fundamental limitation remains: these models often treat information as disconnected text fragments. Even when enhanced with retrieval, via retrieval-augmented generation (RAG), they struggle with queries that demand relational reasoning, multi-step inference, or deep structural context. Documents are retrieved and concatenated, but relationships between entities, causal chains, hierarchies, dependencies, are lost in the flat text.
GraphRAG offers a powerful alternative by uniting traditional RAG with a structured knowledge graph. By representing entities, relationships, and ontologies in a graph layer, GraphRAG enables LLMs to reason over interconnected knowledge rather than isolated snippets. As a result, responses become more context-aware, logically consistent, and traceable. This article explores GraphRAG’s architecture, how it works, its advantages over classical RAG, and the practical tools that support building GraphRAG solutions for real-world applications.
What Is GraphRAG
GraphRAG is a hybrid retrieval-and-generation architecture that blends the strengths of embedding-based text retrieval with the structured reasoning afforded by knowledge graphs. Traditional RAG systems rely solely on vector-search to fetch relevant documents and feed them to an LLM, but GraphRAG enhances that by layering a graph retrieval channel that reflects the relational structure of knowledge. Instead of returning a flat collection of text passages, GraphRAG can fetch subgraphs, clusters of interconnected entities and relationships, and supply them alongside textual evidence.
For example, a query about “Supplier X and its downstream product impact” will not only retrieve documents mentioning the supplier, but also traverse a graph to locate which components Supplier X provides, which products use those components, and what regional distribution chains those products follow. The LLM receives both document context and a relational map, enabling reasoning that follows the structure of real-world dependencies.
GraphRAG represents a paradigm shift: retrieval becomes not just about what documents are relevant, but about how facts connect, turning a generative model into a knowledge-aware reasoning engine.
What Is a Knowledge Graph
A knowledge graph is a structured, semantic representation of information in which knowledge is encoded as nodes (entities), edges (relationships), and properties (attributes, metadata). Entities might be people, organizations, products, events, or abstract concepts; relationships capture how entities are related, for example, “supplies”, “authorOf”, “partOf”, “locatedIn”, or “precedes”.
Unlike traditional relational databases, which focus on rigid schemas and tabular data, a knowledge graph naturally encodes relationships, hierarchies, and networks. It allows flexible schema evolution: new entity types, relation types, and metadata can be introduced without restructuring existing tables. A public example of a knowledge-graph visualization can be found here:
Knowledge graphs shine when modeling domains where context, dependencies, and multi-hop relationships matter. They provide a semantic backbone that reflects real-world structure, enabling applications such as entity-centric search, complex network analysis, lineage tracking, causal inference, and reasoning across heterogeneous data sources. When merged with generative systems, they bring structure to otherwise unstructured text-based retrieval.
How GraphRAG Combines RAG and Knowledge Graphs
GraphRAG leverages a dual-channel retrieval architecture: one channel performs standard embedding-based text retrieval, while the other performs graph-based retrieval. The system then merges results from both channels into a unified context, which the LLM uses for generation. This hybrid pipeline captures both semantic similarity and relational structure.
A high-level flow of GraphRAG looks like this:
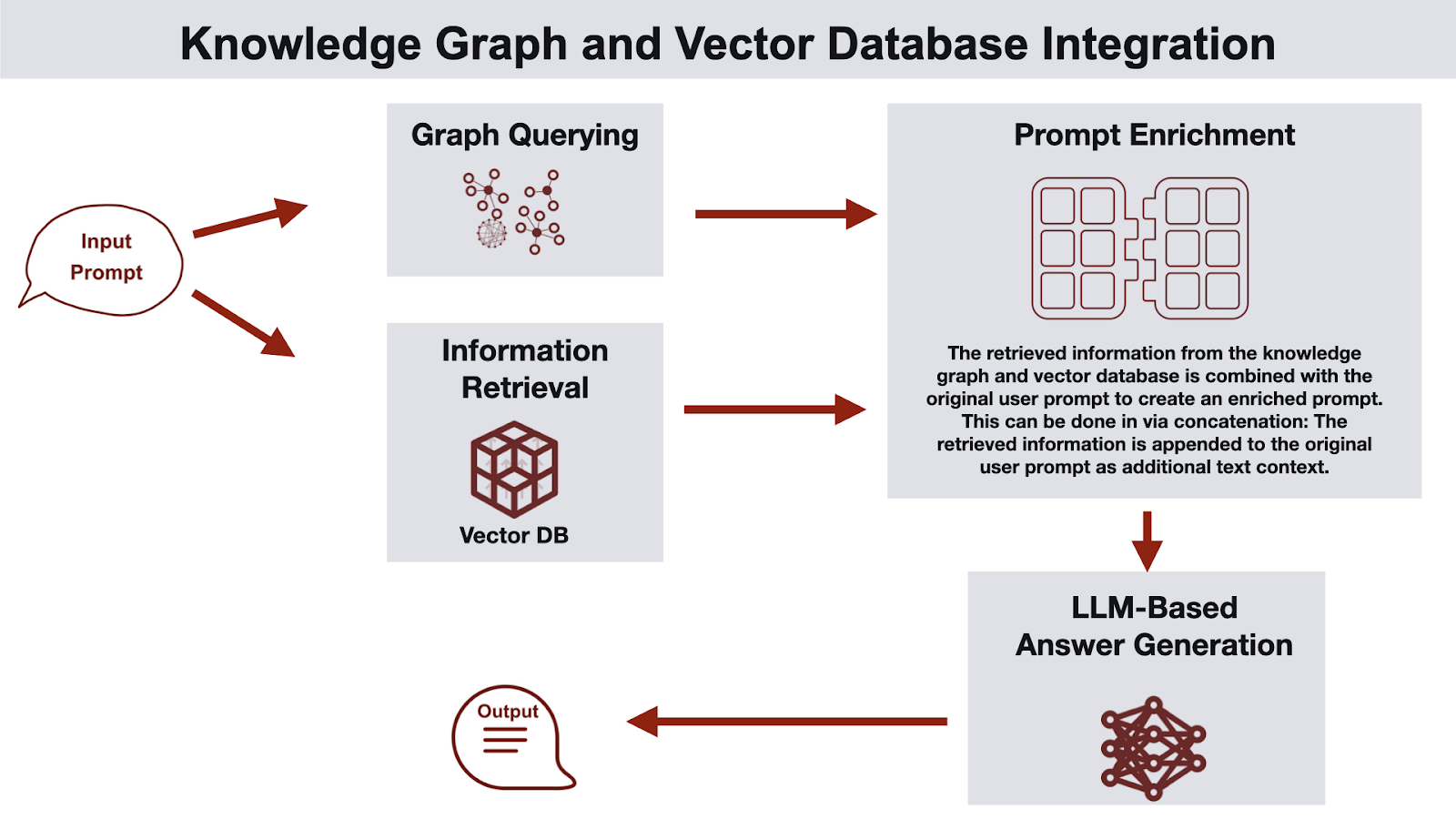
Upon receiving a user query, GraphRAG first embeds the query for semantic search and simultaneously performs entity linking to map mentions to graph nodes. The vector retrieval channel retrieves text passages; the graph retrieval channel extracts relevant subgraphs, neighbor nodes, multi-hop relationships, and metadata. A context merger then combines both text and structured data, constructing a prompt that includes documentary evidence plus relational context. The LLM consumes this rich prompt and generates answers with reasoning grounded in both content and structure.
This fusion allows GraphRAG to handle complex questions like “Which finished products will be impacted if Supplier A misses delivery this quarter and which alternate suppliers are compliant with new regulation X?”, blending textual records with graph-encoded supply-chain relationships.
Key Components of GraphRAG Architecture
The power of GraphRAG depends on a multi-moduled architecture. A typical GraphRAG system includes the following essential components:
Knowledge Graph Storage Module
This module holds entities, relationships, ontologies, and metadata. It uses graph databases (property graphs or RDF) such as Neo4j, Amazon Neptune, TigerGraph, or ArangoDB. The storage must support efficient traversal, indexing, and schema evolution.
Embedding / Vector Store Module
Unstructured documents, PDFs, reports, logs, articles, are embedded into vectors using embedding models (e.g. Sentence-Transformers, OpenAI embeddings). These vectors are stored in scalable vector databases like Pinecone, Weaviate, Milvus, or pgvector-enabled systems to allow fast semantic search.
Entity Linking and Ingestion Module
New data is ingested through pipelines that perform named-entity recognition (NER), relation extraction, coreference resolution, and canonicalization. Extracted entities and relations are normalized and reified into the knowledge graph. This ensures the graph evolves as new information arrives, linking documents to entities and embedding textual context.
Graph Reasoning & Retrieval Module
When a query arrives, this component performs entity linking on the query, identifies relevant graph nodes, and runs graph algorithms, neighborhood search, multi-hop traversal, path-finding, subgraph extraction, filtering, ranking, perhaps community detection or temporal filtering. It extracts a subgraph that forms the structural context relevant to the query.
Context Fusion and Prompt Construction Module
This orchestrator merges retrieved text fragments and graph-derived structural context. It transforms graph triples or paths into natural-language “mini-facts,” summarizes subgraphs, resolves conflicts or redundancies, and assembles a coherent, balanced prompt. The merged context aims to provide both evidence (text) and structure (graph) without exceeding token limits.
LLM Generation Module
Finally, a large language model consumes the constructed prompt, rich with text and structural context, and generates a response. Because the prompt includes relationships, constraints, and entity context, the output becomes more logically consistent, grounded, and often includes reasoning or explanations referencing graph structure.
Some implementations also add a Feedback & Update Module, where user feedback or system validation triggers graph updates, adding new edges, correcting entities, or re-ingesting updated documents, enabling the knowledge graph to evolve over time.
How GraphRAG Works
GraphRAG processes a query through a structured, multi-step pipeline. It begins by interpreting the query with NER, entity disambiguation, and intent parsing, mapping mentions to canonical graph nodes while also embedding the text for vector retrieval. The system then runs dual-channel retrieval: vector search returns semantically relevant passages, while graph traversal gathers connected nodes, multi-hop relationships, and other structural contexts. Because the retrieved subgraph can be large, the system filters it by relevance, such as hop distance, relation types, or timestamps, and converts it into concise triples, summaries, or structured knowledge blocks.
Next, GraphRAG merges graph-derived facts with retrieved text, resolving conflicts using metadata like source credibility or recency. This produces a unified context that feeds into prompt construction, which includes both textual evidence and relational summaries. The LLM then generates an answer grounded in explicit structure rather than inference alone. Optionally, user or system feedback updates the knowledge graph by adding new entities, correcting relationships, or removing outdated information. This workflow turns retrieval into an active, knowledge-aware reasoning process.
Benefits of Using GraphRAG Knowledge Graph
A major advantage of GraphRAG comes from the universal expressiveness of knowledge graphs. Many types of domain knowledge, entities, relationships, hierarchies, workflows, supply-chain dependencies, regulatory requirements, causal chains, can be naturally represented as graph structures. Unlike free-form text, a knowledge graph encodes facts in a canonical, machine-interpretable form, making it easy to capture multi-hop context that would otherwise be scattered across documents. This structured backbone ensures that the model retrieves not only relevant information but the correct relational context surrounding it.
Graph-based retrieval also delivers higher accuracy than repeated vector searches in standard RAG. Instead of relying on multiple search rounds or heuristic chaining, which often introduces drift, inconsistent intermediate steps, or missing links, a graph query can directly compute the multi-hop relationships the question requires. When the structure is explicit, the system avoids guesswork: intermediate reasoning paths come from graph traversal rather than LLM hallucination. This leads to more reliable multi-step inference, fewer contradictions, and grounded explanations that consistently reflect underlying data.
Finally, graph queries significantly improve efficiency. Many questions that would require large token budgets in text-only RAG, such as tracing dependencies, exploring neighborhoods, resolving lineage, or comparing related entities, can be answered through fast graph operations without injecting massive text blocks into the prompt. By letting the graph handle structure and the LLM focus on interpretation, GraphRAG reduces context size, cuts latency, and minimizes the risk of exceeding token limits. The result is a retrieval pipeline that is both more precise and more computationally efficient.
GraphRAG vs Traditional RAG
The benefits described above reveal a central pattern: when reasoning requires multi-hop context, dependency chains, or structural relationships, text-only retrieval forces an LLM to infer missing links, often leading to drift, contradictions, or inefficient prompt construction. GraphRAG avoids these pitfalls by making structure explicit. Instead of relying solely on semantic similarity, it retrieves “how facts connect,” providing the LLM with relational grounding. The table below summarizes the key differences and the underlying reasons behind them.
Tools and Frameworks Supporting GraphRAG
Today, a growing ecosystem of tools makes GraphRAG increasingly accessible. Key technologies and platforms include:
- Graph Databases: Neo4j, Amazon Neptune, TigerGraph, ArangoDB, for storing entities/relations and enabling efficient graph traversal and query operations.
- Vector Stores / Embedding Databases: Pinecone, Weaviate, Milvus, Elasticsearch with vector plugin, for scalable semantic search over large document collections.
- Extraction & Ingestion Pipelines: NLP tools such as spaCy and OpenIE, together with custom ETL pipelines, support entity recognition, relation extraction, canonicalization, and loading structured graph data.
- Graph + LLM Integration Frameworks:
- LangChain: supports hybrid retrieval strategies combining vector search and graph traversal.
- LlamaIndex (GPT Index): can integrate custom graph-retrievers for structured retrieval.
In addition, many cloud providers now offer managed services that bundle vector stores and graph databases, plus built-in libraries for prompt orchestration. This lowers the barrier for teams to deploy production-grade GraphRAG pipelines without deep in-house infrastructure expertise.
For developers, these tools mean GraphRAG is no longer a theoretical concept: it is an actionable architecture supported by mature, scalable technologies.
Why PuppyGraph
While GraphRAG provides a compelling framework for combining textual retrieval with structured reasoning, its practical effectiveness depends heavily on the underlying graph infrastructure. Traditional graph databases often require extensive ETL, complex schema design, and ongoing maintenance, which can slow down deployment and increase operational overhead. This is where PuppyGraph stands out: it delivers real-time, zero-ETL graph querying on existing relational and lakehouse data, allowing teams to implement GraphRAG pipelines quickly and efficiently without the typical costs and complexity of managing a separate graph database.

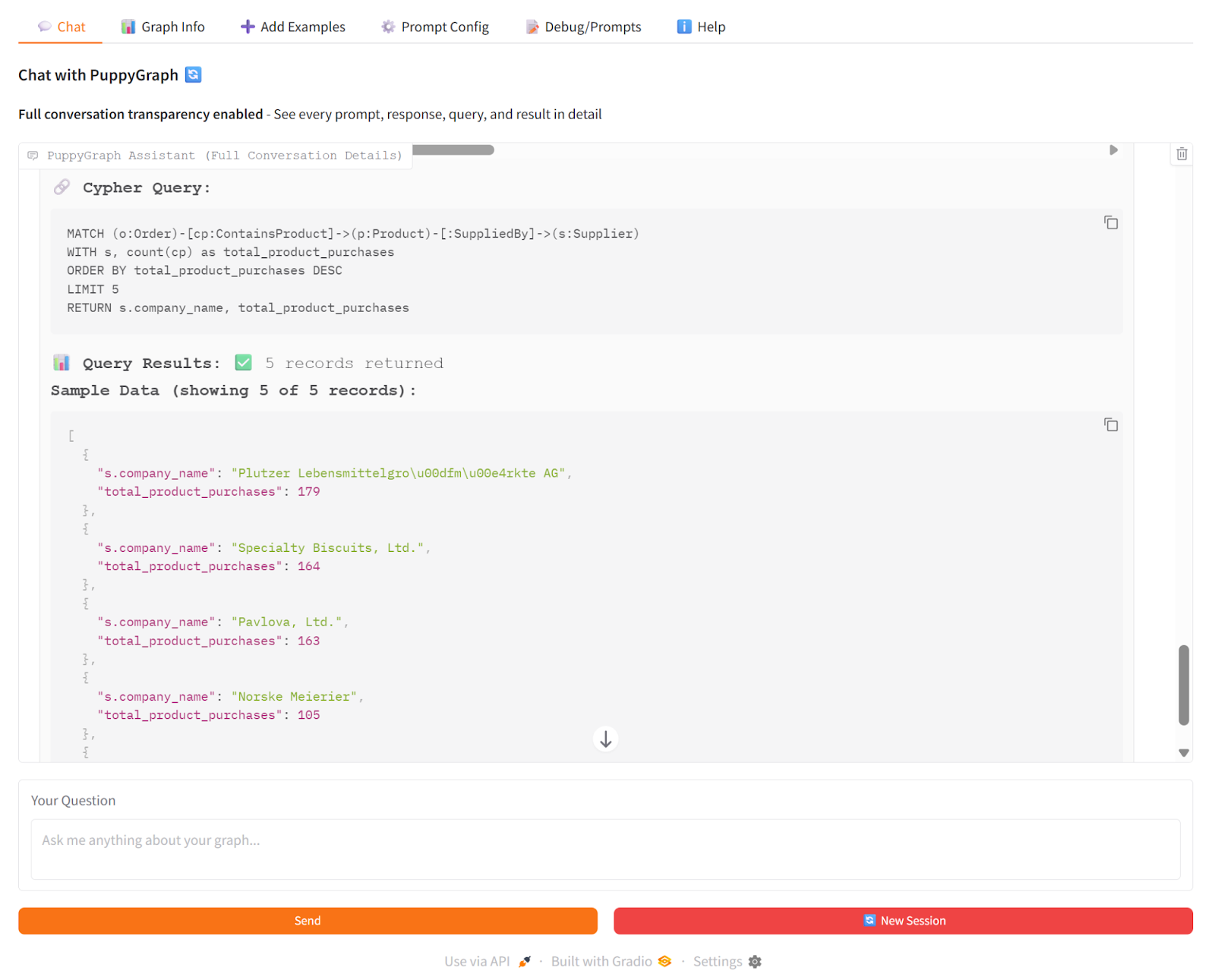
As an example of GraphRAG with PuppyGraph, we asked the PuppyGraph Chatbot: “Which suppliers are associated with the products that appear most frequently in customer orders?” The chatbot used PuppyGraph to traverse the knowledge graph in real time, following connections from products to suppliers and counting orders along the way. At the same time, it used vector search to pull relevant textual evidence from order records. The LLM then combined both sources to generate a clear answer showing top suppliers, their products, and total order counts.
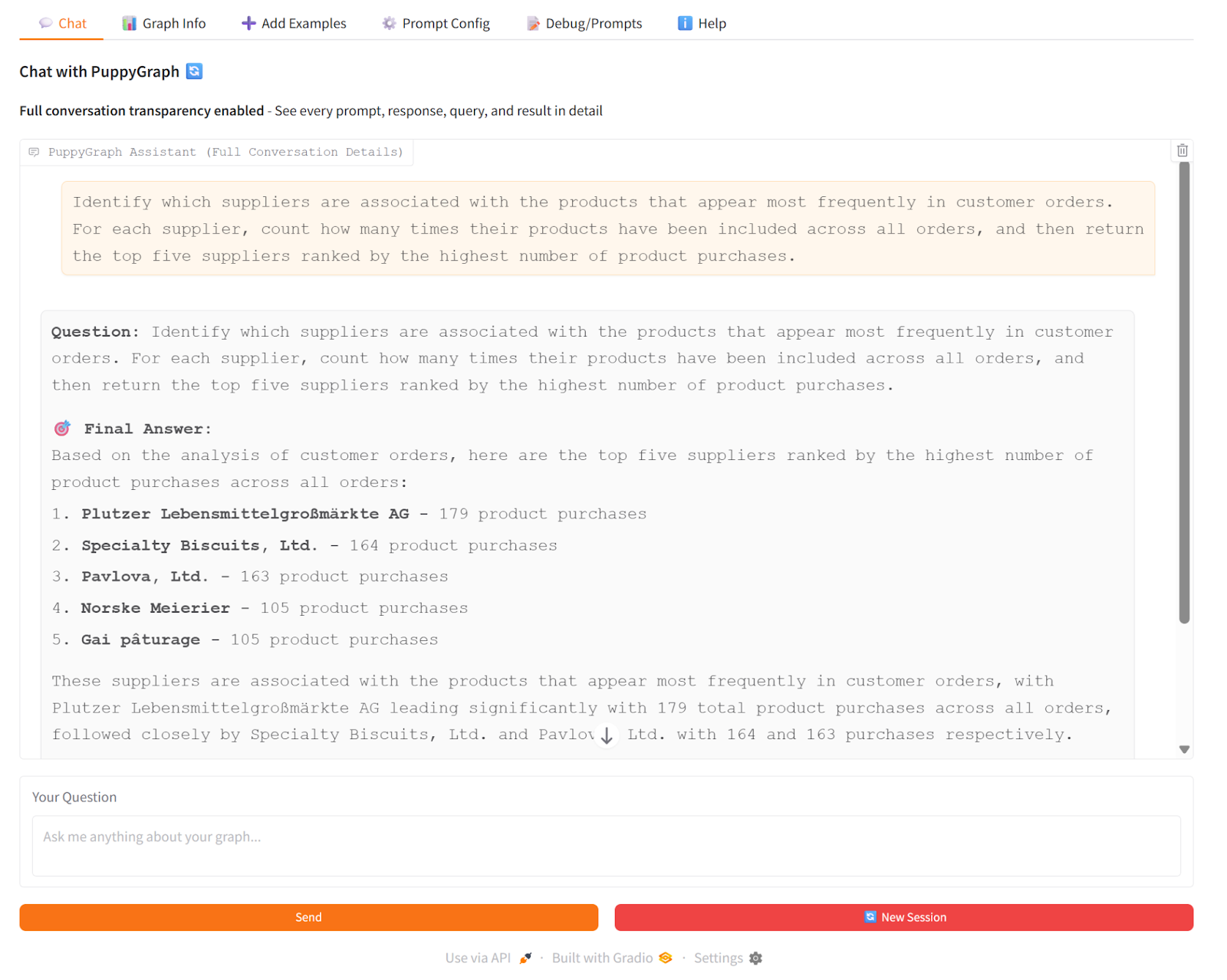
This shows how GraphRAG works: PuppyGraph provides the actual graph traversal and multi-hop relationships, so the chatbot’s answers are grounded in real connections rather than just inferred from text.
PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.

Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
GraphRAG represents a significant evolution in retrieval-augmented generation: by integrating knowledge graphs directly into the retrieval pipeline, it transforms generative AI from text-based mimicry into structured, reasoning-aware intelligence. This hybrid architecture allows LLMs to access not only semantically relevant information but also explicit multi-hop relationships, dependency chains, and relational context. The result is higher accuracy, reduced hallucination, more efficient prompt usage, stronger logical consistency, and full traceability, qualities critical for enterprise-grade, mission-critical applications.
While GraphRAG introduces complexity in graph construction, maintenance, and system orchestration, the expanding ecosystem of graph databases, vector stores, integration frameworks, and managed cloud services makes implementation increasingly viable. For teams aiming to operationalize GraphRAG in real time, PuppyGraph provides a practical solution: querying existing relational and lakehouse data directly without ETL, enabling live subgraph retrieval, multi-hop reasoning, and seamless integration with text-based evidence. Explore the forever-free PuppyGraph Developer Edition or book a demo to see how it brings GraphRAG pipelines to life on your data.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install