

How to Build a SIEM System: Architecture & Tools

Security Information and Event Management (SIEM) systems have become a cornerstone of modern cybersecurity operations. As organizations generate massive volumes of logs from endpoints, servers, cloud workloads, and network devices, the challenge is no longer data collection but meaningful analysis. A SIEM system centralizes security data, correlates events, and provides actionable insights that help detect threats in real time.
This article explains how to build a SIEM system from scratch, focusing on architecture, tools, and design decisions rather than vendor marketing. You will learn what SIEM is, the core components involved, architectural patterns, and a detailed step-by-step process for building a functional SIEM using modern technologies. By the end, you will understand both the technical depth and practical challenges of operating a SIEM in production environments.
What Is SIEM?
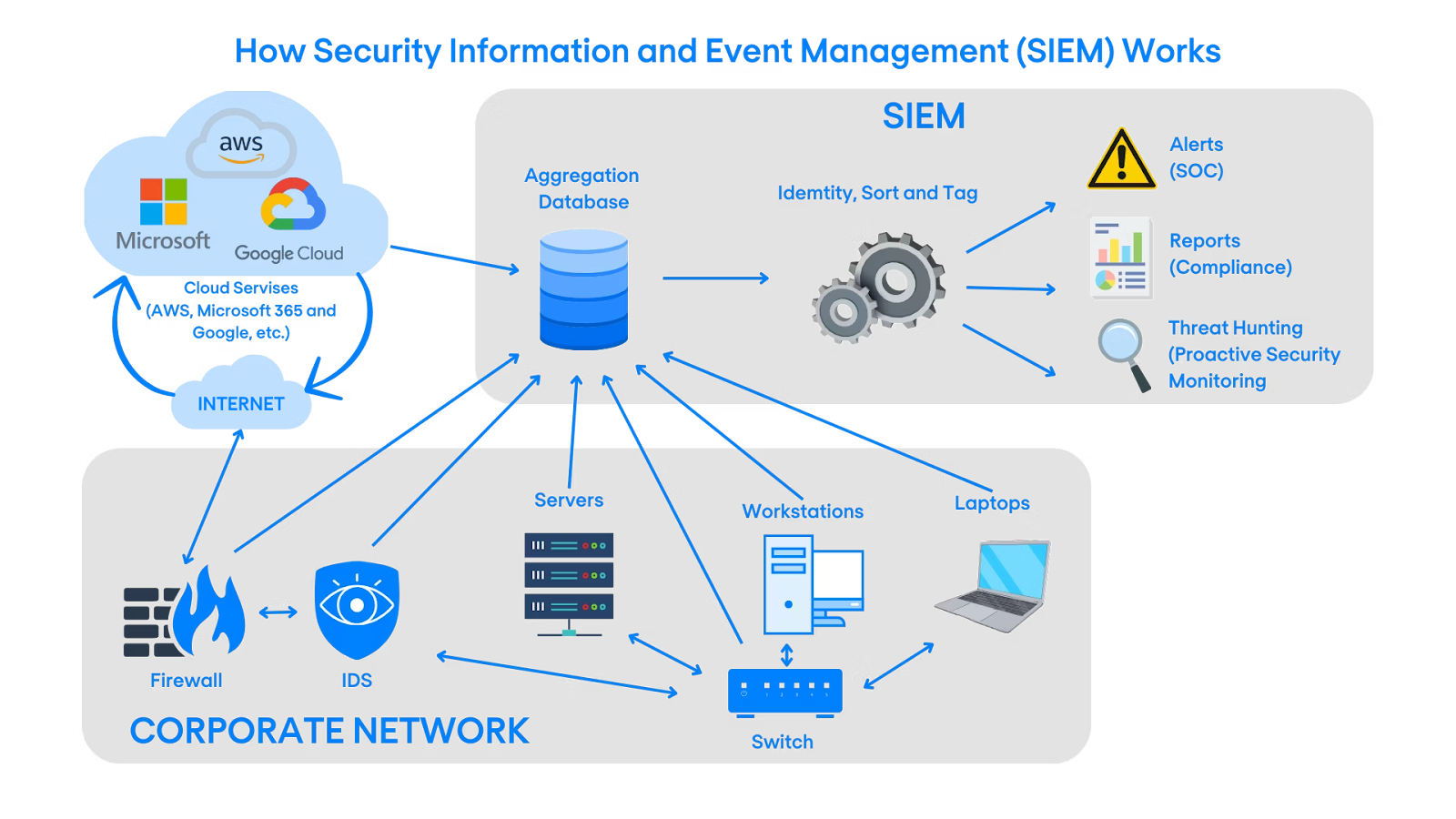
Security Information and Event Management (SIEM) is a technology framework that aggregates, normalizes, correlates, and analyzes security-related data across an organization’s IT environment. The primary goal of SIEM is to provide visibility into security events and support faster detection, investigation, and response to threats. Unlike standalone log management systems, SIEM platforms apply contextual intelligence to raw logs, transforming them into security insights.
Historically, SIEM evolved from two separate disciplines: Security Information Management (SIM), which focused on log collection and compliance reporting, and Security Event Management (SEM), which emphasized real-time monitoring and alerting. Modern SIEM systems combine both approaches, offering long-term storage, advanced analytics, and real-time threat detection in a single platform.
At its core, a SIEM ingests data from diverse sources such as firewalls, intrusion detection systems, identity providers, operating systems, applications, and cloud services. This data is then normalized into a common schema, enabling correlation rules and analytics to identify suspicious patterns. The result is a centralized “single pane of glass” for security monitoring, investigation, and compliance reporting.
Core Components of a SIEM
A SIEM system is not a single tool but a collection of tightly integrated components that work together to collect, process, and analyze security data. Understanding these components is essential before attempting to design or build a SIEM architecture. Each component serves a distinct function, and weaknesses in one area can undermine the entire system.
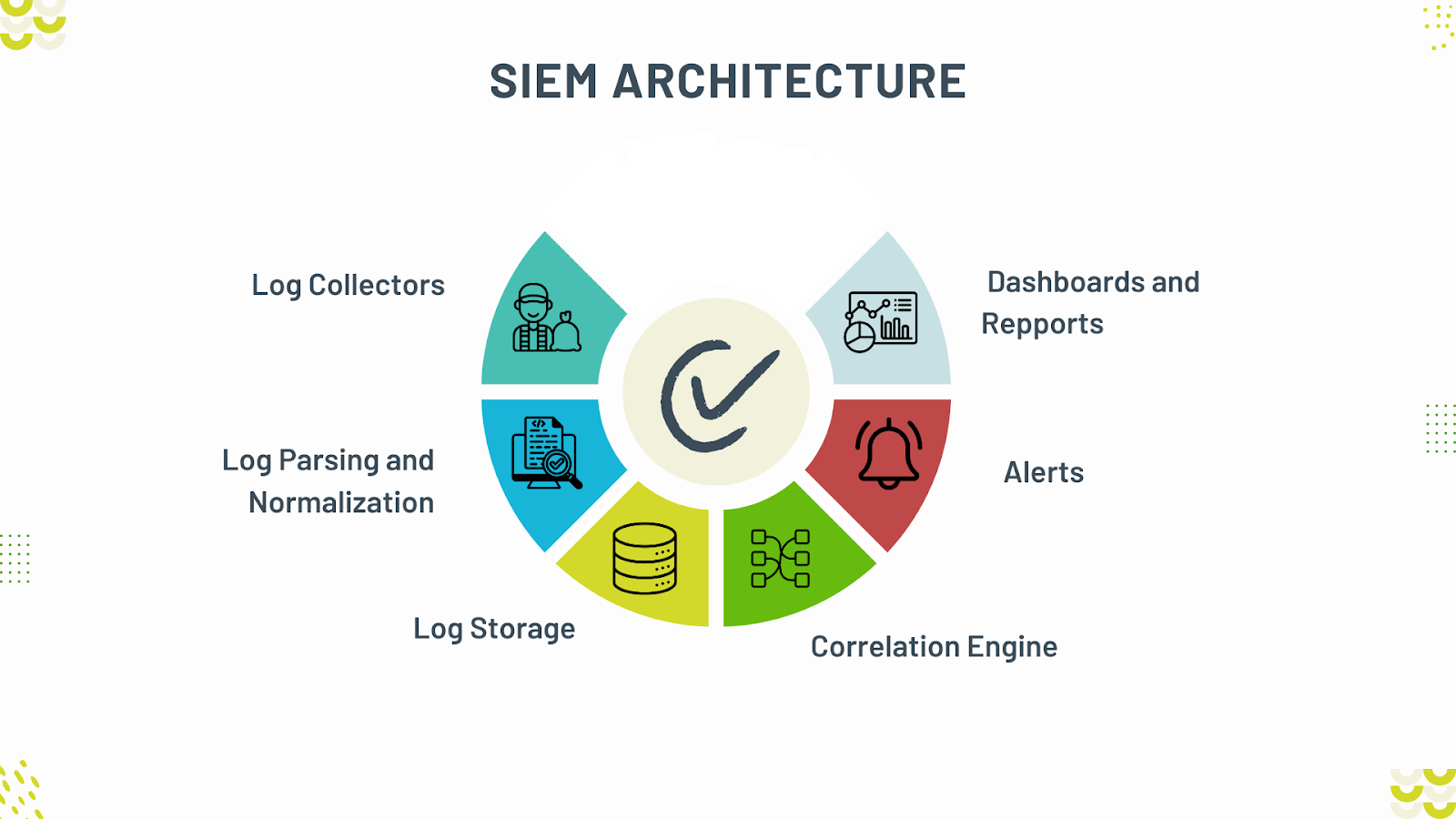
Log and Event Sources
Log and event sources are the foundation of any SIEM system. These include operating systems, applications, databases, network devices, security appliances, and cloud platforms. Each source produces logs in different formats, levels of detail, and frequencies. A well-designed SIEM strategy begins by identifying which sources provide the most security value and ensuring consistent data collection from them.
The challenge with log sources lies in diversity. Syslog messages from network devices differ significantly from Windows Event Logs or cloud audit logs. A SIEM must be capable of handling structured, semi-structured, and unstructured data while preserving the original context. The richness and accuracy of ingested data directly impact detection quality.
Log Collection and Ingestion
Log collection is the process of transporting data from sources to the SIEM platform. This often involves agents, forwarders, or APIs that securely transmit logs in near real time. Ingestion pipelines must be reliable, scalable, and fault-tolerant, as data loss can create blind spots in security monitoring.
Modern SIEM architectures often rely on message queues or streaming platforms such as Apache Kafka to decouple log producers from consumers. This design allows the system to absorb traffic spikes, buffer data during outages, and scale horizontally as log volume grows. Effective ingestion also includes timestamp normalization and basic validation to ensure data integrity.
Parsing and Normalization
Once logs are ingested, they must be parsed and normalized into a common data model. Parsing extracts relevant fields such as IP addresses, usernames, timestamps, and event types. Normalization maps these fields into a standardized schema, enabling consistent analysis across different log sources.
Without normalization, correlation becomes extremely difficult because the same concept may be represented differently across systems. For example, a user identity might appear as “username,” “user,” or “principal” depending on the source. Normalization resolves this inconsistency, allowing detection logic to operate at scale.
Storage and Indexing
SIEM systems require both short-term and long-term storage to support real-time detection and historical analysis. Storage layers must balance performance, cost, and retention requirements. Hot storage is optimized for fast search and analytics, while cold storage is used for long-term retention and compliance.
Indexing plays a critical role in SIEM performance. Properly indexed data enables rapid searches across massive datasets, which is essential for threat hunting and incident response. Technologies such as Elasticsearch, OpenSearch, and columnar data stores are commonly used to meet these requirements.
Correlation and Analytics
Correlation is the analytical heart of a SIEM system. It involves linking multiple events across time and sources to identify patterns that indicate malicious activity. Simple correlation rules might detect repeated failed logins followed by a successful one, while advanced analytics may involve statistical models or machine learning.
Effective correlation requires context, including asset criticality, user roles, and threat intelligence. By enriching events with contextual data, the SIEM can reduce false positives and highlight truly significant security incidents. Analytics capabilities often evolve over time as detection logic matures.
SIEM Graph
Traditional SIEM analytics primarily operate on events as independent records, using rules or statistical models to detect suspicious behavior. While effective for many scenarios, this approach becomes increasingly limited as attacks grow more complex and span multiple identities, hosts, networks, and cloud resources.
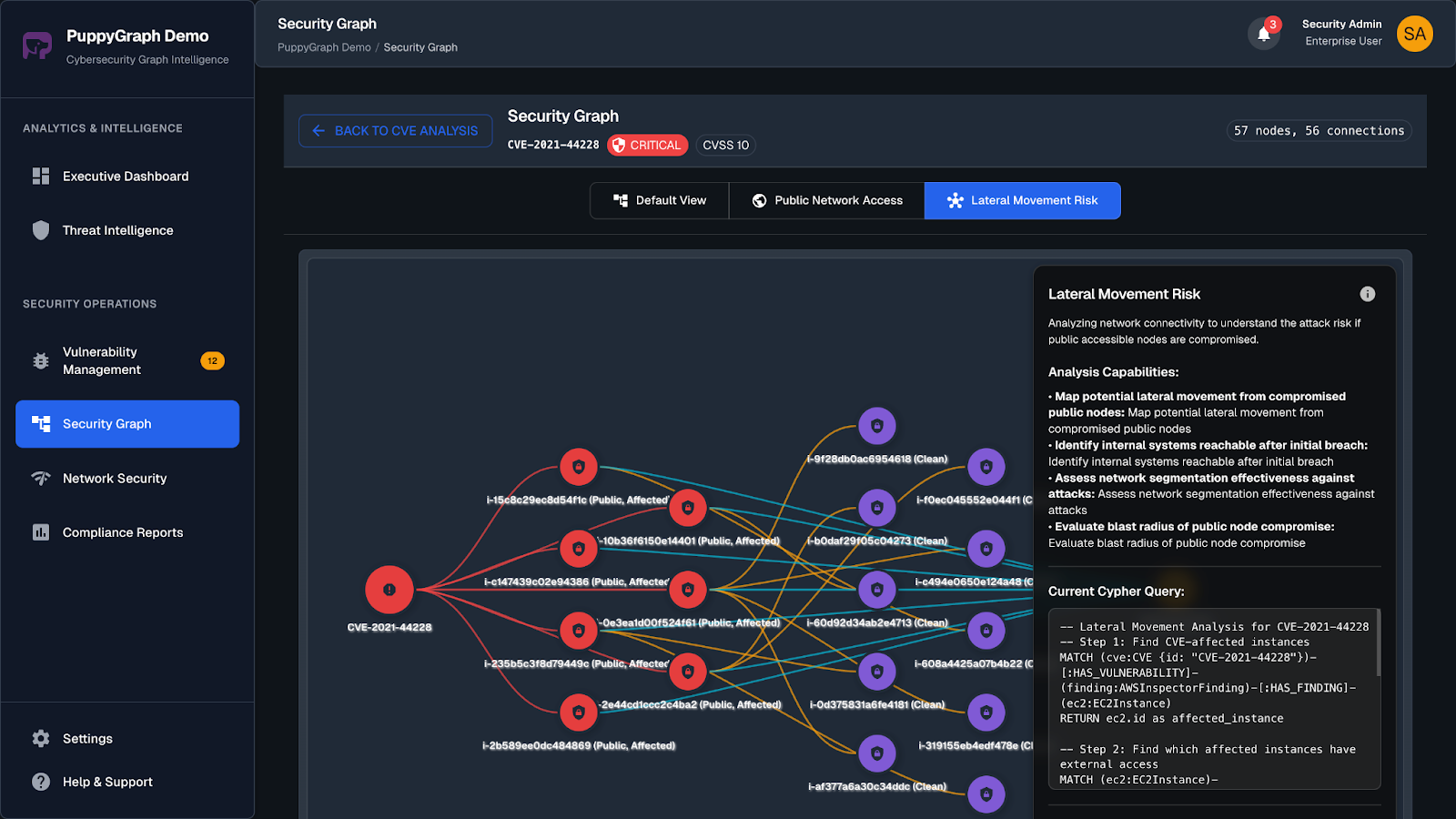
A SIEM Graph introduces a graph-based analytical layer that models security data as entities and relationships. In this model, users, devices, IP addresses, processes, services, and cloud resources are represented as nodes, while interactions such as logins, network connections, process executions, and API calls are represented as edges.
By preserving relationships and temporal context, a SIEM Graph enables multi-hop reasoning across the environment. Analysts can trace attack paths, analyze lateral movement, and assess blast radius in ways that are difficult or impossible with flat, table-based queries alone. SIEM Graph complements existing correlation and analytics rather than replacing them.
Alerting and Response
Alerting mechanisms notify security teams when suspicious activity is detected. Alerts must be timely, actionable, and prioritized based on risk. Poorly tuned alerting leads to alert fatigue, which can cause critical threats to be overlooked.
Modern SIEM systems increasingly integrate with Security Orchestration, Automation, and Response (SOAR) tools. This integration enables automated workflows such as blocking IP addresses, disabling accounts, or opening incident tickets. The goal is to reduce mean time to detect (MTTD) and mean time to respond (MTTR).
Prerequisites Before Building a SIEM
Before building a SIEM system, organizations must assess their technical readiness, security maturity, and operational capacity. SIEM is not a plug-and-play solution; it requires ongoing investment in people, processes, and infrastructure. Skipping this preparation often leads to underperforming systems and wasted resources.
Clear Security Objectives
A successful SIEM implementation begins with clearly defined objectives. Organizations must decide whether the primary goal is threat detection, compliance reporting, incident response, or a combination of these. Each objective influences architectural decisions, data sources, and detection strategies.
Without clear goals, SIEM deployments often suffer from scope creep. Teams ingest excessive data without knowing how it will be used, increasing costs and complexity. Defining use cases upfront ensures that the SIEM delivers measurable value aligned with business priorities.
Skilled Personnel
Building and operating a SIEM requires specialized skills in security operations, data engineering, and system administration. Analysts must understand attack techniques, log semantics, and correlation logic. Engineers must manage ingestion pipelines, storage systems, and performance optimization.
Organizations without in-house expertise should plan for training or external support. SIEM systems are only as effective as the people who configure and monitor them. A lack of skilled personnel often results in poorly tuned detections and missed threats.
Infrastructure Readiness
SIEM platforms are resource-intensive, particularly in high-volume environments. Adequate compute, storage, and network capacity are essential to support log ingestion and analytics. Infrastructure planning should account for growth, redundancy, and disaster recovery.
Cloud-based deployments offer flexibility and scalability, but they also introduce new considerations such as data sovereignty and ongoing operational costs. On-premises deployments provide greater control but require significant upfront investment. Choosing the right infrastructure model is a critical prerequisite.
Governance and Data Policies
SIEM systems handle sensitive security and personal data, making governance and compliance essential. Organizations must define data retention policies, access controls, and privacy requirements before ingesting logs. These policies influence storage design and access management within the SIEM.
Clear governance also ensures accountability for tuning rules, responding to alerts, and maintaining system health. Without defined ownership and processes, SIEM platforms can quickly become unmanageable and ineffective.
Choosing the Right Architecture
SIEM architecture determines how data flows through the system, how it scales, and how resilient it is under load. There is no single “correct” architecture; the best design depends on organizational size, log volume, and operational requirements. However, certain architectural principles apply universally.
Centralized vs. Distributed Architectures
Traditional SIEM systems often use a centralized architecture, where all logs are collected and processed in a single location. This approach simplifies management and correlation but can become a bottleneck as data volume grows. Centralized systems may struggle with latency and scalability in large environments.
Distributed architectures address these limitations by spreading ingestion, processing, and storage across multiple nodes or regions. This design improves resilience and performance but increases operational complexity. Distributed SIEM architectures are particularly well-suited for cloud-native and global organizations.
On-Premises, Cloud, and Hybrid Models
On-premises SIEM deployments offer maximum control over data and infrastructure. They are often preferred in regulated industries with strict compliance requirements. However, they require significant capital expenditure and ongoing maintenance.
Cloud-based SIEM solutions leverage managed services to reduce operational overhead and scale dynamically. They are ideal for organizations with fluctuating log volumes or limited infrastructure expertise. Hybrid architectures combine on-premises data collection with cloud-based analytics, offering a balance between control and scalability.
Data Pipeline Design
A robust SIEM architecture separates data ingestion, processing, and analytics into distinct layers. This separation improves scalability and fault tolerance. Message queues or streaming platforms act as buffers, ensuring that temporary outages do not result in data loss.
Pipeline design should also consider data enrichment and transformation stages. Enriching logs with asset information, user context, and threat intelligence early in the pipeline enhances detection accuracy. A modular pipeline allows components to evolve independently as requirements change.
In modern SIEM architectures, a graph-based analytics layer is often introduced after normalization and enrichment. Instead of duplicating data into a separate system, normalized SIEM data can be queried directly as a graph to support relationship-centric analysis such as attack path discovery and lateral movement investigation.
Step-by-Step: Building a Custom SIEM
Building a custom SIEM system involves a small number of tightly integrated stages, from defining detection objectives to enabling response. Each step should be implemented iteratively and refined as the system evolves.
Step 1: Define Use Cases and Detection Objectives
The foundation of a SIEM is a clear set of security use cases, such as brute-force attacks, lateral movement, data exfiltration, and privilege escalation. Each use case should specify what data is required, how detection will work, and what response is expected.
Clearly defined use cases prevent unnecessary data ingestion and ensure the SIEM focuses on high-impact threats. Additional use cases can be added over time as detection capabilities mature.
Step 2: Data Source Selection and Log Collection
Based on the defined use cases, identify and onboard the required data sources, including endpoints, network devices, identity systems, servers, and cloud platforms. Logs may be collected via agents, syslog, APIs, or event streams, depending on the source.
Log collection must be secure, reliable, and time-synchronized to support accurate correlation. A phased rollout helps control complexity and validate data quality early.
Step 3: Ingestion, Parsing, and Normalization
Collected logs are ingested through a scalable pipeline that handles buffering, validation, and load balancing. Streaming-based architectures are commonly used to support near-real-time processing.
Logs are then parsed and normalized into a common schema such as ECS or OCSF. Consistent field names and data structures are critical for effective correlation and analytics across diverse data sources.
Step 4: Storage, Correlation, and Analytics
Normalized data is indexed and stored according to performance, retention, and cost requirements. Index design should reflect common query patterns and detection needs.
Detection logic is implemented through correlation rules, behavioral analysis, and anomaly detection models. These analytics translate use cases into actionable detections and should be continuously tuned to reduce false positives.
Optional Step: Build a SIEM Graph for Advanced Investigation
Once normalized data and core detections are in place, organizations can model their SIEM data as a graph to support advanced investigations. This involves defining entity types such as users, hosts, IP addresses, and cloud resources, as well as relationship types derived from existing logs.
A SIEM Graph enables analysts to move beyond individual alerts and explore how events are connected across systems and time, significantly improving root-cause analysis and threat hunting effectiveness.
Step 5: Alerting and Incident Response Integration
The final step is generating actionable alerts and integrating the SIEM with incident response processes. Alerts should include clear context, prioritization, and recommended next steps.
Dashboards, visualizations, and automated response playbooks help analysts investigate incidents efficiently. Regular reviews and exercises ensure the SIEM remains aligned with real-world operational needs.
What Are the Challenges
Building and operating a SIEM system presents numerous challenges that extend beyond technical implementation. Understanding these challenges helps set realistic expectations and informs better design decisions.
Data Volume and Noise
One of the most significant challenges is managing data volume. Modern environments generate terabytes of logs daily, much of which may be irrelevant to security. Excessive data increases costs and complicates analysis.
Noise reduction requires careful source selection, filtering, and tuning. Analysts must continuously refine what data is collected and how it is used. Achieving the right balance between visibility and manageability is an ongoing challenge.
False Positives and Alert Fatigue
Poorly tuned correlation rules often generate excessive false positives. Over time, analysts may begin to ignore alerts, increasing the risk of missed incidents. Alert fatigue is a common reason SIEM projects fail to deliver value.
Reducing false positives requires contextual enrichment, continuous tuning, and analyst feedback. Detection logic must evolve alongside the threat landscape and organizational changes. Quality is more important than quantity when it comes to alerts.
Performance and Scalability
As log volume grows, SIEM systems can experience performance degradation. Slow searches and delayed alerts undermine the system’s effectiveness. Scalability must be considered from the initial design stage.
Horizontal scaling, efficient indexing, and pipeline optimization are essential techniques. Regular capacity planning and performance testing help prevent unexpected bottlenecks. Scalability is not a one-time achievement but an ongoing requirement.
Cost Management
SIEM systems can be expensive to build and operate, particularly at scale. Costs include infrastructure, storage, licensing, and personnel. Without careful planning, expenses can quickly exceed budget.
Cost management strategies include selective data ingestion, tiered storage, and automation. Open-source tools can reduce licensing costs but may increase operational overhead. Organizations must weigh trade-offs carefully.
Skills and Maintenance
SIEM platforms require continuous maintenance, including rule updates, parser adjustments, and infrastructure management. This workload can strain security teams, particularly in smaller organizations.
Investing in training and documentation mitigates some of these challenges. Automation and managed services can also reduce operational burden. However, SIEM remains a long-term commitment rather than a one-time project.
How PuppyGraph can help
Building and maintaining a SIEM graph in complex, distributed environments can be challenging. Traditional methods often rely on ETL pipelines, duplicated storage, and manual mapping. PuppyGraph streamlines this process by constructing and querying the SIEM graph directly on top of your existing SIEM data stores and data lakes in real time, eliminating data duplication and reducing operational overhead.
With PuppyGraph, the SIEM graph is built from existing security data sources that describe events, assets, and relationships. Using a graph schema, identities, assets, and network activities are mapped to nodes, while interactions, attack paths, and dependencies are mapped to edges. Analysts can perform real-time, multi-hop investigations, such as lateral movement detection, blast radius assessment, and attack path exploration, directly on live source data, without requiring additional ETL or duplicated storage.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.


Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Security information and event management serves as the backbone for understanding and defending an organization’s digital environment, from endpoints and servers, through networks and cloud workloads, to alerts, incidents, and compliance reporting. By collecting, correlating, and analyzing security data, SIEM provides visibility into threats, supports faster investigation, and strengthens operational resilience. Implementing a SIEM can be complex in large, distributed environments, but the benefits in detection accuracy, response speed, and risk reduction make it essential.
PuppyGraph enables real-time SIEM graph construction and exploration without heavy ETL, connecting directly to existing databases and data lakes. It allows organizations to visualize and query security relationships across users, devices, networks, and applications, turning logs and events into actionable intelligence and supporting faster, informed threat response. Download the forever free PuppyGraph Developer Edition, or book a demo with our engineering team to see how you can build and explore your enterprise SIEM graph in minutes.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install