

JanusGraph vs Dgraph: Which Graph Database Fits Your Workload
As data becomes more interconnected, graph databases have become a practical way to model and analyze relationships between entities. They make it easier to ask questions that are awkward in tables, like multi-hop influence paths, dependency chains, and “who is connected to what, and how.” With dozens of graph databases on the market, though, it can be hard to tell which one fits your workload best, especially since performance and operational tradeoffs depend heavily on query patterns, consistency requirements, and how you plan to deploy.
In this blog, we compare two popular open-source, distributed graph databases: JanusGraph and Dgraph. We’ll break down how they differ in data layout, supported query languages, consistency and replication models, and what kinds of workloads they’re best suited for. Then we’ll zoom out and look at where graph query engines like PuppyGraph can fit, especially for teams that want graph traversals on top of existing relational or lakehouse data without rebuilding their data stack.
What is JanusGraph?

JanusGraph is an open-source, distributed graph database designed to store and query very large property graphs. It is built for online transactional workloads that need fast traversals at scale, and integrates natively with the Apache TinkerPop stack, using Gremlin as its query language.
The project is under the Linux Foundation and is available under the Apache 2.0 license. It began as a fork of the Titan graph database, with a focus on continuing Titan’s scalable, backend-flexible approach under open governance.
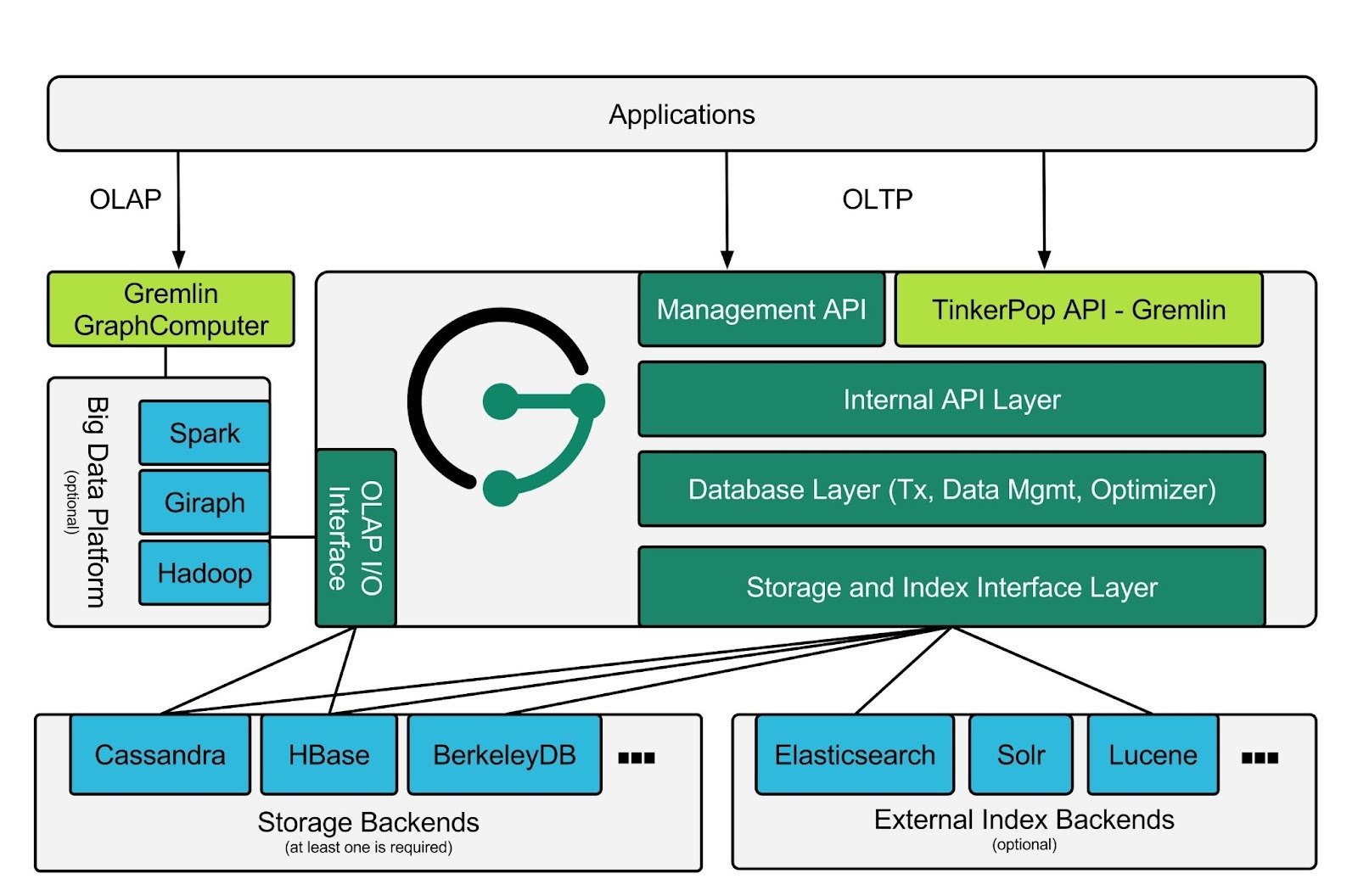
JanusGraph’s architecture is modular. It uses storage and indexing adapters between the graph engine and the underlying systems, coming with standard adapters for:
- Data storage: Apache Cassandra, Apache HBase, Google Cloud BigTable, ScyllaDB, BerkeleyDB
- Indexing: ElasticSearch, Apache Solr, Apache Lucene
JanusGraph is written in Java. Internally, it stores the graph as an adjacency list that maps well to the wide-column format used by backends like Cassandra and HBase. Each vertex’s adjacency list is stored as a row in the storage backend, keyed by the vertex ID, with edges and properties stored as cells within that row. This design keeps a node’s incident edges and properties compact, so traversals can read and update neighborhood data efficiently.
Key Features:
JanusGraph’s modular architecture decouples storage and indexing, so you can pair it with different backends depending on what you value. For example, HBase can favor stronger consistency and more complete reads, even if that increases timeouts under stress. Cassandra often favors availability and keeping the system responsive, even if some reads may be temporarily stale. External indexing backends are optional, but adding Elasticsearch or Solr unlocks geo search, numeric range queries, full-text search, and faster global lookups.
JanusGraph also supports both OLTP and OLAP workloads by combining real-time traversals with optional big data analytics. OLTP traversals run against the storage backend through Gremlin. For OLAP, JanusGraph can integrate with engines such as Spark, Giraph, or Hadoop via TinkerPop’s GraphComputer, translating graph analytics into distributed compute jobs that load the graph through an OLAP I/O layer and run algorithms like PageRank or connected components across the full dataset.
JanusGraph’s distributed design combines clustered storage backends with concurrent query processing. Its scalability and availability largely come from the underlying stores such as Cassandra, HBase, or Bigtable, which handle data sharding, replication, and fault tolerance. If your team already runs these systems in production, or is comfortable operating them, the learning curve to deploying JanusGraph is much lower because you are building on tooling and patterns you already know. On top of that, you can run multiple JanusGraph instances against the same storage and index backends so many Gremlin traversals can execute concurrently across the cluster. Together with external index backends and support for multi-datacenter deployments, this lets JanusGraph support very large graphs and a growing user base while staying responsive.
What is Dgraph?
Dgraph is an open-source, distributed graph database also available under the Apache 2.0 license, designed for low-latency queries and high throughput. It is commonly used for graph-backed applications like knowledge graphs and real-time relationship queries, and it ships with both a GraphQL API and its native query language, DQL, for more direct control.
On October 23, 2025, Istari Digital acquired Dgraph from Hypermode. Istari has said it is prioritizing the open-source and self-hosted Dgraph community, and that it does not plan to support Dgraph Cloud at the moment.
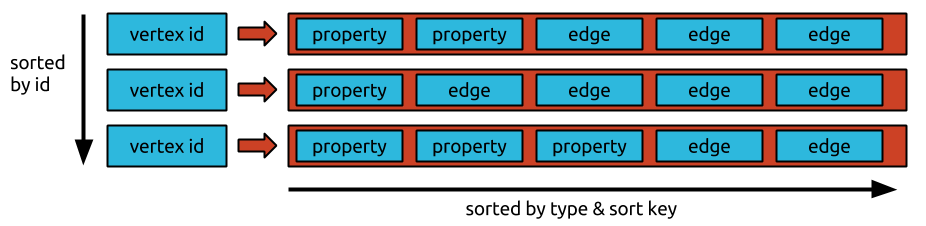
Dgraph is written in Go and uses BadgerDB as its underlying key-value store for persistent storage. Internally, Dgraph stores relationships in a triple-like form (subject–predicate–object) and organizes data into posting lists. A posting list contains all triples that share the same <subject, predicate> pair, and Dgraph stores that posting list as a single value in Badger, keyed by the subject and predicate. For example, having two kinds of predicates (relationships) like “access” and “has_security_group” will result in two shards.
A Dgraph cluster consists of two kinds of nodes:
- Dgraph Alpha (data-serving nodes): Stores and serves graph data, and handles queries and mutations.
- Dgraph Zero (management nodes): Coordinates the cluster and manages tablet placement and rebalancing across Alphas.
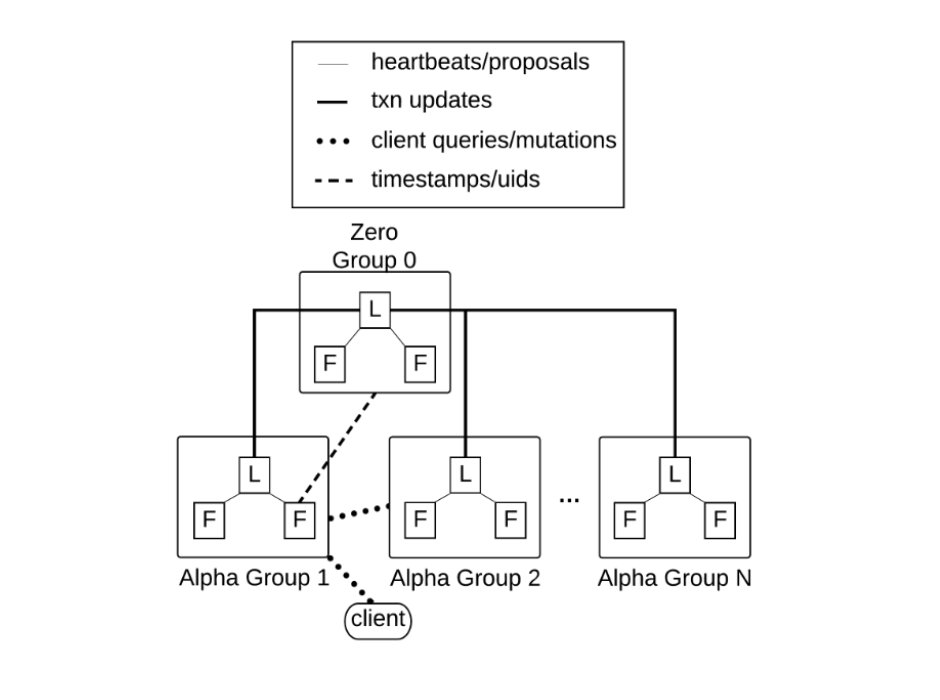
Data is automatically partitioned into tablets and distributed across Alpha nodes. Each Alpha node maintains a write-ahead log and supports multi-version concurrency control (MVCC), which enables ACID transactions and snapshot isolation.
Key Features:
Dgraph provides native GraphQL support alongside its own query language, DQL. This lets teams build and serve graph-backed application APIs without adding a separate GraphQL service. When you need more precise control or graph-specific operations, like @recurse for recursive traversals, you can use DQL directly. You can think of DQL as the database query language, similar in spirit to SQL, Cypher, or Gremlin, while GraphQL is the API layer that provides a controlled, schema-driven interface for accessing the database. Here’s what an example GraphQL query looks like:
query {
queryUser(filter: { name: { eq: "Alex" } }) {
name
email
friends {
name
location
}
}Dgraph is built for scalability and performance. It scales horizontally with a distributed cluster of Alpha and Zero nodes, and spreads data and query load across the cluster as you add more Alpha groups. Its predicate-based sharding groups data for a predicate into tablets, which can reduce cross-node work during joins and traversals compared to entity-based sharding. When a join step can be satisfied from a single predicate tablet, the engine can often complete that step with one RPC to the Alpha serving it, which helps keep latency low under concurrent load.
Dgraph ensures reliability in distributed deployments. It supports distributed ACID transactions with consistent reads and writes across the cluster, and relies on consensus (Raft) to coordinate replication and keep the system highly available during node failures. In practice, this gives teams transactional guarantees they can depend on while still operating at cluster scale.
JanusGraph vs Dgraph: Feature Comparison
When to Choose JanusGraph vs Dgraph?
The kind of workload you’re running has a big impact on the right graph database choice. Choose Dgraph when your workload is dominated by high-concurrency, low-latency application queries with predictable, moderate-depth traversals. It tends to fit well as a serving layer for graph-backed apps and knowledge graph lookups, where most queries are a few hops with filters and you want consistent response times under load. Choose JanusGraph when you expect more custom traversal logic and varied query shapes, especially multi-step Gremlin traversals that benefit from careful schema, indexing, and partitioning choices. It is also a strong fit when you plan to mix real-time traversals with analytics jobs through GraphComputer.
The operational tradeoff comes down to where you want the complexity to live. Dgraph is more self-contained as a distributed database, so the day-to-day work is mostly about running and tuning the Dgraph cluster. JanusGraph’s scalability and reliability come largely from its storage and index backends, which can be a big advantage if your team already has experience operating Cassandra or HBase and wants more control over the stack. The flip side is that JanusGraph deployments often involve more moving parts, especially if you add external index backends like Elasticsearch or Solr.
Ecosystem fit often becomes the deciding factor once performance and operations look “good enough” on both sides. Dgraph’s native GraphQL support is attractive when you want the database to sit directly behind application APIs, with DQL available for deeper, graph-specific querying. JanusGraph is built on Apache TinkerPop and queried via Gremlin, which can reduce lock-in at the query layer and make it easier to reuse traversal code and tooling across graph systems and backends.
Which One is Right for You?
If you’re deciding between JanusGraph and Dgraph, the fastest way to get to an answer is to look at your constraints and what you want to optimize for.
If you want the database to sit directly behind application APIs, with a clean GraphQL interface and predictable query shapes, Dgraph is usually the simpler fit. It’s built for distributed serving, and it tends to do best when most queries are moderate-depth traversals and you’re scaling throughput by adding nodes. If your team already builds APIs in GraphQL, that learning curve is even smaller. When you need more fine-grained control than GraphQL typically provides, you can drop down to DQL to express more graph-specific query logic directly.
If your team needs flexibility in how the graph layer is deployed and tuned, JanusGraph is often the better choice. Its modular architecture does mean there are more moving parts, but it’s a strong fit when you want Gremlin for portability, you already operate backends like Cassandra or HBase, and you’re willing to invest engineering time in schema, indexing, and partitioning to fine-tune performance. Teams with existing Gremlin experience, or familiarity running Cassandra and HBase clusters, usually ramp faster.
Ultimately, both JanusGraph and Dgraph are strong options. They’re open-source, distributed graph databases that can scale to large datasets and high query volumes when deployed and tuned well. The choice usually comes down less to “which one scales” and more to how you want to scale: Dgraph as a more integrated distributed system with GraphQL-first workflows, or JanusGraph as a modular, backend-driven stack where scaling and behavior depend heavily on the storage and indexing systems you pair it with.
Why Consider PuppyGraph as an Alternative
Even if JanusGraph and Dgraph are strong open-source options, both still push you toward a separate graph stack with a lot of moving parts. You have to stand up and operate a dedicated graph datastore, keep data flowing into it, and then tune it as your schema and workloads evolve.
On top of that, running intensive graph analytics often introduces a second layer of complexity. JanusGraph has a more established integration path for OLAP workloads through TinkerPop’s GraphComputer and Hadoop-Gremlin, but you are still relying on a separate big data engine like Spark or Hadoop to run those jobs. With Dgraph, you get graph-specific query features like recursion and shortest-path style queries in DQL, but large-scale iterative algorithms typically end up running outside the database as Spark jobs after exporting or moving the data. That’s where PuppyGraph steps in.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.

Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
JanusGraph and Dgraph are distributed graph databases with two very different design philosophies. Dgraph feels like an integrated system built to serve graph-backed applications with a GraphQL-first workflow, while JanusGraph feels like a graph layer you shape around the storage and indexing infrastructure you already trust.
But if what you really want is graph insight, not a new datastore, the bigger theme is that both paths often lead to operating a separate graph system. Instead, graph query engines like PuppyGraph might be more suitable for the job. PuppyGraph runs graph queries directly on your existing relational databases and lakehouse tables with zero ETL and no data duplication, so you can keep one copy of data while still asking multi-hop questions in real time.
Interested in running graph analytics directly on your data? Download PuppyGraph’s forever-free PuppyGraph Developer Edition and start running graph queries on your existing data stores. You can also book a demo with the team and see how it fits in with your tech stack.

Jaz Ku is a Solution Architect with a background in Computer Science and an interest in technical writing. She earned her Bachelor's degree from the University of San Francisco, where she did research involving Rust’s compiler infrastructure. Jaz enjoys the challenge of explaining complex ideas in a clear and straightforward way.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install