

Knowledge Base vs knowledge Graph: Know the Differences
A knowledge base is a centralized, organized repository that collects and stores explicit knowledge, such as guides, FAQs, and policy documents, making information easily accessible and navigable for human users. In contrast, a knowledge graph represents a refined, graph-structured view of knowledge. It emphasizes relationships, context, and semantics, enabling machines to reason over data and support advanced use cases such as intelligent search, recommendation systems, and complex query answering.
Understanding how these two paradigms differ, and how they complement each other, is crucial for architects, data engineers, product managers, and decision-makers designing information systems. This article provides a comprehensive comparison of knowledge bases and knowledge graphs, explaining what each concept means, how they evolved, where they excel, and how to decide which one best fits your needs.
What Is a Knowledge Graph?
A knowledge graph is a highly structured representation of knowledge that organizes entities, their attributes, and relationships into an explicit graph data model. Instead of treating knowledge as unstructured text or loosely connected data, a knowledge graph enforces a clear schema and formalized relationships, enabling information to be stored, connected, and queried in a consistent and systematic way. Nodes represent entities or concepts, while edges encode well-defined relationships such as works for, is part of, or depends on.
Compared to more flexible or unstructured knowledge representations, knowledge graphs are more standardized and operationally efficient. They typically rely on specialized graph query languages (e.g., SPARQL, Cypher) and optimized graph databases, which allow complex queries, such as multi-hop traversal, aggregation, or relationship-heavy searches, to be executed with high precision and low latency. This makes knowledge graphs particularly suitable for scenarios where fast and accurate querying over complex relational structures is required.
However, this level of structure and formalism also introduces a knowledge barrier for human users. Effectively building, querying, and maintaining a knowledge graph often requires domain experts who understand the underlying schema, query language, and graph modeling principles. As a result, knowledge graphs may be less intuitive for non-expert users compared to free-text or document-based systems.
From a machine perspective, knowledge graphs are especially well suited for automated reasoning and system-level operations. They provide an explicit, queryable structure that machines can reliably traverse and manipulate, making them a strong foundation for applications such as Graph-based Retrieval-Augmented Generation (GraphRAG). In tasks involving complex relationships, large result sets, or aggregation queries, graph queries can return accurate results efficiently, often outperforming text-based retrieval approaches in both speed and structural correctness.
Structure and Data Model
Most knowledge graphs adopt graph data models such as RDF (Resource Description Framework) or labeled property graphs. In RDF, knowledge is stored as triples (subject, predicate, object), while property graphs allow both nodes and edges to carry properties. This structure supports flexible schema evolution: new entity types and relationships can be added incrementally without redesigning the entire system. Such flexibility makes knowledge graphs highly adaptable to changing or expanding datasets.
Semantics and Ontologies
Ontologies provide the conceptual backbone of a knowledge graph, defining entity types, relationships, and rules. By grounding data in an ontology, a knowledge graph can support reasoning and validation. For instance, if a dataset is produced by a job and that job belongs to a pipeline, the graph can infer that the dataset is part of that pipeline, even if this fact was never explicitly recorded. This semantic layer is essential for AI-driven use cases and for integrating heterogeneous data sources.
Typical Use Cases
Knowledge graphs are particularly effective in application scenarios where understanding complex relationships and contextual dependencies is critical, such as enterprise search, recommendation systems, and fraud detection. By modeling data as interconnected entities and relationships, knowledge graphs make it possible to capture rich semantics and reveal how different elements influence one another across domains.
Google’s Knowledge Graph is a representative example, connecting entities such as people, places, and events to provide search results enriched with contextual understanding rather than isolated facts. Building on this idea, GraphRAG further leverages knowledge graphs by combining structured relational data with large language models. Through graph-aware retrieval, GraphRAG enables more precise information grounding, stronger reasoning over relationships, and more contextually accurate generation.
What Is a Knowledge Base?
A knowledge base is a centralized, organized digital library of information, like FAQs, guides, and articles, designed for quick self-service access to answers, troubleshooting, and guidance, used by companies for customers (external) or employees (internal) to find solutions independently and improve efficiency. It acts as a single source of truth, reducing support requests and ensuring consistent information, often powered by search and sometimes AI for better responses.
Common Structures and Formats
Knowledge bases may be implemented as wiki-style platforms, providing articles and guides, FAQ and how-to sections, a searchable glossary of terms, extensive search tools, and interactive community forums. Information is organized hierarchically or categorically, often supplemented by metadata such as author, creation date, and topic. This organization makes knowledge bases highly human-readable and suitable for traditional search engines.
Knowledge Bases in Practice
Common examples include customer support portals that provide step-by-step guides and FAQs. Internally, organizations use knowledge bases to document policies, procedures, and best practices.
In the AWS ecosystem, knowledge bases are typically composed of content such as documentation, technical blogs, community forum posts, and FAQs. Such knowledge bases enable fast retrieval of standardized answers and also serve as the underlying data source for retrieval-augmented generation (RAG) question-answering systems used in customer service and support scenarios.
Strengths and Limitations
The main strength of a knowledge base is accessibility: humans can easily read and navigate its contents. It is simple to build, maintain, and scale for straightforward use cases. However, its limitation is that the data is not fully formalized: representing intricate relationships or performing precise, structured, aggregate queries can become challenging, especially when dealing with large volumes of data.

How Is a Knowledge Graph Different from a Knowledge Base?
Representation of Knowledge
A knowledge graph explicitly models entities, their attributes, and the relationships between them. It forms a network of interconnected facts where semantics emerge naturally from the connections. This structure allows machines to traverse the graph, discover patterns, and infer new knowledge beyond what is directly stored.
A knowledge base stores information as independent entries, documents, or records. It emphasizes human readability, organizing content in tables, text, or hierarchies. Relationships may exist but are usually implicit, making it harder for machines to reason or extract insights beyond keyword matching or manually encoded rules.
Querying and Retrieval
Knowledge graphs support graph-based query languages such as SPARQL or Cypher. These queries explore entity patterns, multi-hop relationships, and topological structures. As a result, knowledge graphs provide precise, structured answers for complex questions, enabling advanced search, recommendations, and reasoning that go beyond simple keyword retrieval.
Knowledge bases rely primarily on keyword searches, filters, and predefined queries. They excel in providing human-readable answers quickly but struggle with queries that require understanding relationships or context. Complex queries often return incomplete results, limiting their usefulness for automated reasoning or analytics.
Knowledge Base vs Knowledge Graph: Side-by-Side Comparison
Brief History: Knowledge Graph and Knowledge Base
During the 1990s, with the rise of enterprise information systems and intranets, organizations began digitizing manuals, procedures, and support documentation into centralized repositories. These early knowledge bases were largely static and document-oriented, relying on keyword search and manual curation. In the 2000s, web technologies and content management systems enabled larger-scale, continuously updated knowledge bases, particularly for customer support and internal operations.
At the same time, researchers explored ways to represent knowledge in interconnected forms, leading to semantic networks, ontologies, and early graph‑based representations. Projects like WordNet, DBpedia, and Freebase captured entities and their relationships to help machines understand meaning and context. These efforts culminated in Google’s Knowledge Graph (2012), which enhanced search results by recognizing real-world entities and their connections rather than relying solely on keywords. Knowledge graphs allow systems to perform reasoning, inference, and contextual queries that go beyond simple document or FAQ lookup.
Since the mid-2010s, both knowledge bases and knowledge graphs have continued to evolve. Knowledge bases have incorporated better search, automation, and AI-assisted content management, while knowledge graphs have become a core infrastructure for semantic search, recommendation systems, and data-driven AI. In practice, modern knowledge systems increasingly combine curated knowledge base content with graph-based representations, reflecting a convergence of document-centric and relationship-centric approaches to knowledge management.
Which Is Best: Knowledge Base or Knowledge Graph?
When the focus is on providing human-readable documentation or enabling search, a knowledge base is sufficient and cost-effective. In contrast, for situations that require handling complex relationships, integrating across domains, or performing precise machine-driven queries, a knowledge graph is more suitable. Knowledge graphs are particularly effective at producing accurate query results and supporting reasoning over structured relationships. In practice, organizations often use both together. This hybrid approach leverages the strengths of both paradigms while acknowledging their trade-offs.
PuppyGraph in Real-Time Knowledge Graphs
Building a usable knowledge graph is often a major bottleneck for organizations. Traditional graph databases typically require complex ETL pipelines, manual schema design, and ongoing maintenance, making it difficult to deploy graph-based solutions quickly. PuppyGraph addresses these challenges by enabling real-time graph querying directly on existing relational and lakehouse data, without the need for ETL or data duplication. This allows teams to construct knowledge graphs rapidly, transforming existing structured data into a connected, machine-readable representation suitable for advanced analytics and reasoning.
PuppyGraph also excels at powering AI-driven applications such as Chatbots. By connecting a Chatbot to a knowledge graph, the system can traverse entities and relationships dynamically, enabling natural-language queries that exploit rich semantic context. For example, in a GraphRAG (Graph + Retrieval-Augmented Generation) pipeline, PuppyGraph can provide multi-hop reasoning over product, supplier, and order relationships, while a vector-based search retrieves relevant textual evidence. The LLM then combines these sources to generate precise and contextually grounded answers.
Importantly, Chatbots built on GraphRAG are flexible: they can be connected not only to a knowledge graph but also to a traditional knowledge base. During execution, the Chatbot can simultaneously reference both sources, drawing structured insights from the graph and factual information from the knowledge base, to answer user queries comprehensively. This hybrid approach ensures that natural language queries are answered accurately, whether the relevant information resides in relationships modeled in the graph, textual knowledge in the base, or both.
For instance, in PuppyGraph Chatbot, with the Northwind dataset loaded, when querying: “Which suppliers are associated with the products that appear most frequently in customer orders?”, the Chatbot uses PuppyGraph to follow connections from products to suppliers and count orders in real time. Simultaneously, vector search retrieves textual records related to these orders. The LLM synthesizes both sources to provide a precise answer showing top suppliers, their products, and total order counts.
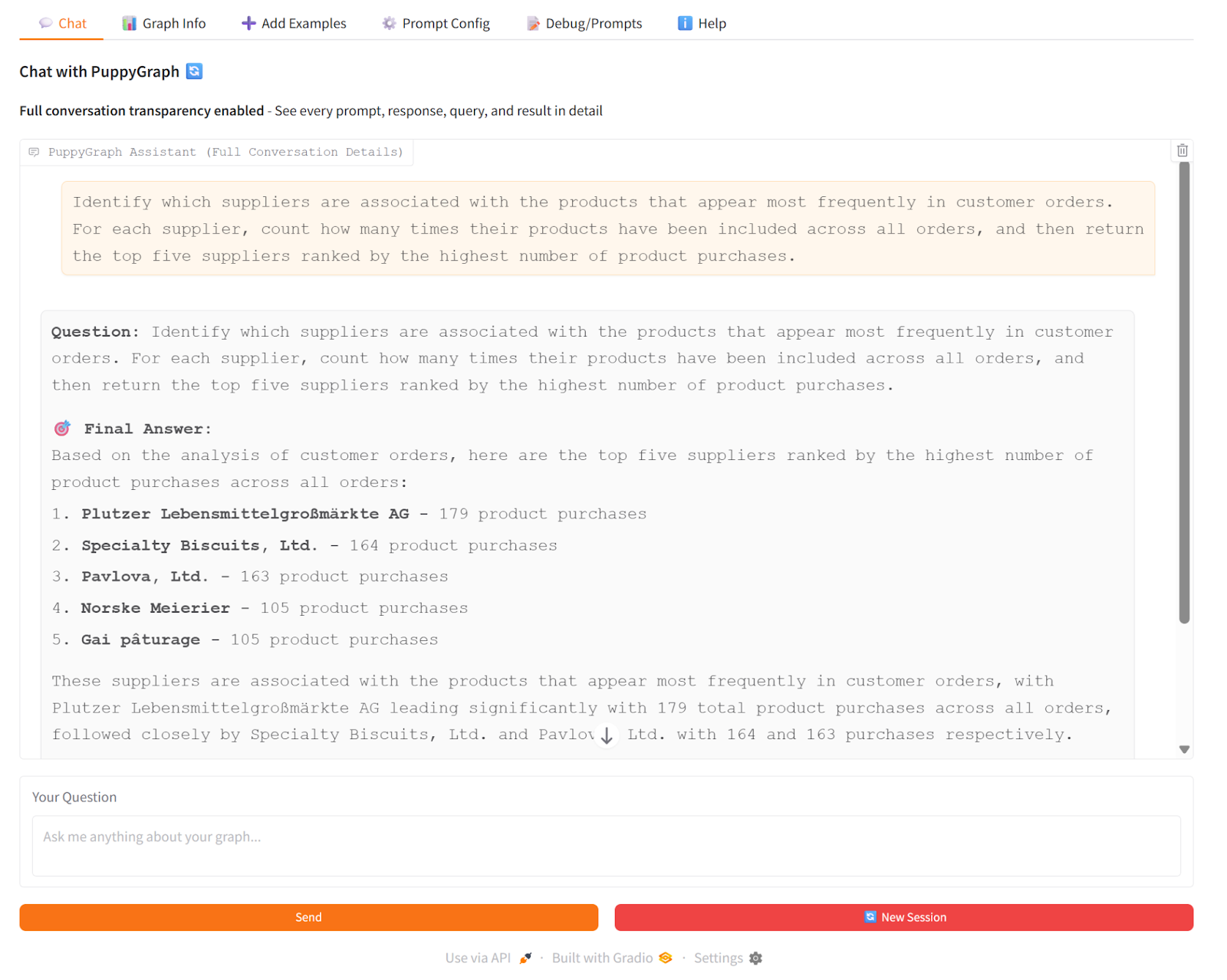
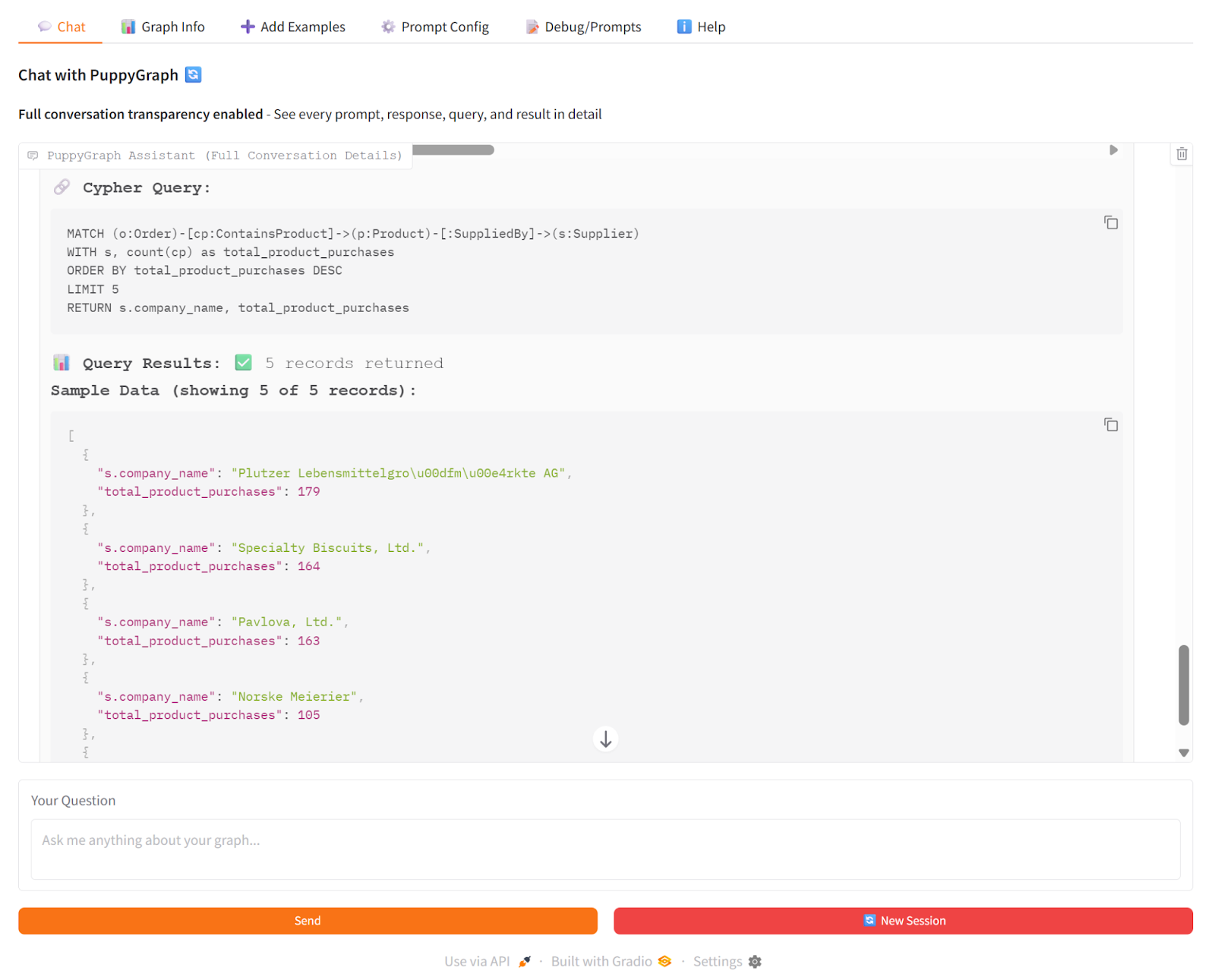
This approach highlights PuppyGraph’s unique value: it enables teams to construct and leverage knowledge graphs efficiently, while also supporting hybrid reasoning with knowledge bases, all within natural-language interfaces powered by modern LLMs.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.




Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Knowledge bases and knowledge graphs fulfill complementary roles in modern information management. Knowledge bases provide human-friendly access to explicit knowledge, making them ideal for documentation, FAQs, etc. Knowledge graphs, on the other hand, capture entities, relationships, and semantics, enabling machines to reason, infer, and deliver context-aware insights. Many contemporary applications, including intelligent search, recommendation systems, and AI-driven analytics, benefit from integrating both paradigms.
PuppyGraph extends this concept by combining knowledge graphs and knowledge bases in a unified platform. PuppyGraph Chatbot enables natural-language queries that leverage both structured relationships and textual knowledge. This hybrid reasoning supports multi-hop traversal, semantic understanding, and precise answers that reflect both explicit facts and inferred connections. By eliminating ETL pipelines and data duplication, PuppyGraph makes real-time, ontology-driven knowledge graphs practical at scale, turning interconnected data into actionable intelligence while supporting flexible, AI-powered applications.
For hands-on exploration of hybrid reasoning and knowledge graphs, you can try PuppyGraph’s forever-free Developer Edition, or book a demo to see how it operationalizes semantic models and unifies knowledge bases with graphs across your existing data.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install