

Knowledge Graph vs Graph Database: Key Differences
Knowledge graphs and graph databases are often mentioned together, but they serve different roles in the data stack. A knowledge graph is the semantic layer that defines how entities and relationships are modeled, providing context and meaning. A graph database is the storage and query layer that manages the actual data and makes those relationships queryable. You can build a knowledge graph without relying on a graph database, and you can run a graph database without ever creating a knowledge graph. The overlap between the two often leads to confusion, since they are closely related but not interchangeable.
This blog will break down the distinction. We will discuss what a knowledge graph is, what a graph database is, compare them side by side, and explore how they can complement each other.
What is a Knowledge Graph?
A knowledge graph is a structured representation of information that captures entities and the relationships between them in a way that preserves context and meaning. Contrary to raw datasets or simple graph structures, a knowledge graph explicitly encodes what things are and how they relate, often through a shared vocabulary or schema. This makes the data both connected and interpretable.
A knowledge graph combines three elements:
- Entities, like customers, products, or assets
- Relationships such as owns, purchases, or regulates
- Semantics: the rules and definitions that clarify what those entities and relationships mean
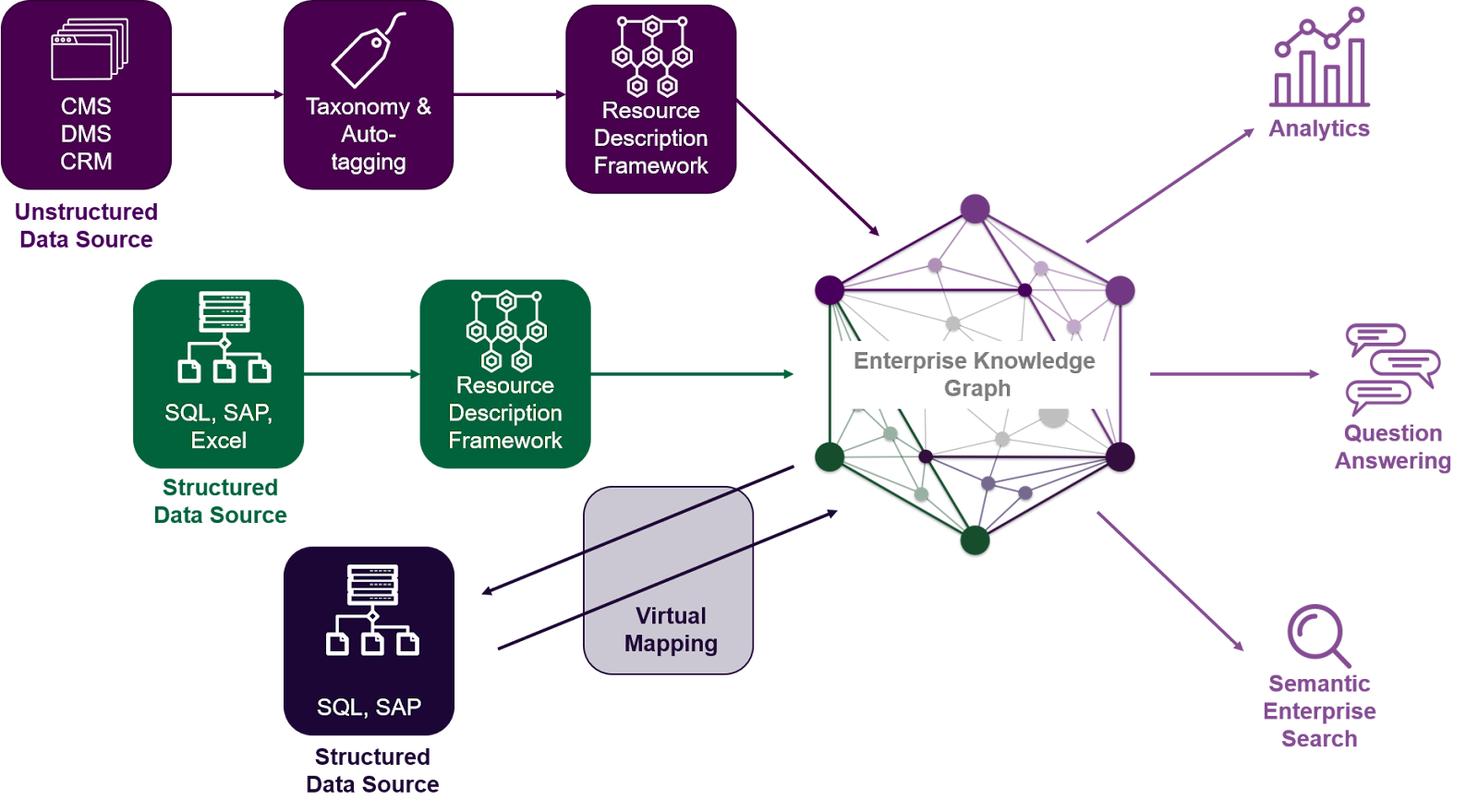
The defining feature of a knowledge graph is its ability to embed semantics and reasoning. It not only stores the fact that A is linked to B; it also specifies the type of connection and allows systems to infer additional relationships. For example, consider an ecommerce system knowledge graph:
- The customer placed the order
- The order contains certain products
- Those products belong to specific categories.
Since meanings are encoded, the system can reason over them and maintain consistent interpretation across teams and applications.
Knowledge graphs can derive new facts from existing ones. For example, if a supplier provides a part, and a product includes that part, the knowledge graph can infer that the supplier indirectly contributes to the product itself. You don’t necessarily have to explicitly store these inferred relationships. You can discover them at query time, making the graph more powerful as it grows.
Knowledge graphs also emphasize flexibility and integration. By design, they can bring together information from multiple systems into a unified representation, even if those systems use different formats and identifiers. This makes them valuable in organizations where data lives across silos. For example, CRM systems, ERP platforms, and operational databases can all feed into the same graph, reconciled by shared semantics.
In other words, a knowledge graph, in addition to being a network of data points, acts as a framework of meaning. It translates raw connections into structured knowledge, which is why it often serves as the foundation for advanced analytics, AI systems, and enterprise data strategies.
What is a Graph Database?
A graph database is a data management system built to store and query information as nodes and edges rather than rows and tables. Nodes represent entities such as customers, orders, or products. Edges represent the direct relationships between them; for example, customer places order or order contains product. This structure makes it natural to model data that is highly connected and allows queries to follow relationships directly, rather than relying on complex joins across multiple tables.
Graph databases focus on traversal efficiency. In traditional relational systems, finding how two entities connect often requires scanning and joining across multiple tables. It becomes expensive as data grows. In a graph database, relationships are first-class citizens, so queries like “find all products purchased by customers who live in the same city” can be resolved by following connected paths. This design makes them especially powerful for real-time questions on highly connected datasets.
Another defining aspect of graph databases is their flexible schema. Unlike relational systems, they don’t require predefined table structures. You can add entities with different attributes, and introduce new relationships without disrupting existing data. This flexibility allows faster adaptation when business requirements change or new data sources need integration.
To measure performance in graph databases, we typically look at how quickly they can traverse relationships. Compared to bulk analytical systems, they excel at pathfinding queries, neighborhood lookups, and pattern matching. For example, in an order system, a graph database can quickly identify not just which customer placed an order, but also the chain of dependencies:
- The supplier
- The warehouse
- The shipping partner
Multi-hop queries like this demonstrate the advantage of treating relationships as native structures.
Graph databases are not monolithic. Some are optimized for transactional workloads (OLTP), where low-latency queries are critical. Others are tuned for analytical workloads (OLAP), designed for exploring large datasets and identifying broader patterns. Modern enterprise deployments often use a hybrid model that can handle both, depending on business needs.
The value of a graph database lies in the ability to make connections between data points fast, direct, and scalable. It’s an ability that underpins many enterprise systems, but which remains distinct from the semantic and reasoning capabilities of a knowledge graph.
Knowledge Graph vs Graph Database: A Side-by-Side Comparison
When to Use a Knowledge Graph?
A knowledge graph is most valuable when the goal is to bring meaning and context to data rather than just store or query it efficiently. It helps unify information from different sources under a shared semantic model, making it easier to answer complex questions and reason about relationships.
GraphRAG and Context-Aware Applications
Use a knowledge graph for AI applications like GraphRAG (graph-based retrieval-augmented generation), where outputs must be grounded and auditable. Typed entities and relationships ensure accurate data retrieval, reduce inaccurate AI outputs, and allow tracing the source of answers. Unlike vector-only stores, which lack semantic context, the knowledge graph’s semantic layer provides structure for consistent prompts, controlled context, and post-generation validation.
Complex Integration and Evolving Schemas
Use a knowledge graph to integrate data from diverse sources (e.g., Salesforce, SAP, event streams) into a unified model without requiring identical schemas. Unlike graph databases, which focus on structural connections, knowledge graphs use a shared vocabulary to reconcile entities, allowing definitions to evolve without disrupting downstream applications. This flexibility absorbs changes in data sources while maintaining a consistent, unified view.
Knowledge Discovery and Analytics
Use a knowledge graph when provenance and justification are critical, such as for regulatory reporting or audits. Unlike graph databases, which often track provenance externally, knowledge graphs explicitly link facts to their source, timestamp, and responsible party (e.g., tracking data lineage in financial compliance). Policies can then govern how facts combine, ensuring defensible decisions.
Semantic Data Representation and Reasoning
Use a knowledge graph when interpreting facts is as critical as storing them, such as inferring concepts like “eligible patient” in healthcare or “conflicted transaction” in finance. Unlike graph databases, which store relationships without inherent semantics, knowledge graphs centrally encode rules for reasoning, ensuring consistent interpretation across applications.
When to Use a Graph Database?
Graph databases shine in use cases when you need to store, query, and analyze highly connected data with a focus on performance and flexibility, rather than semantic meaning. Unlike knowledge graphs, which prioritize context and reasoning, graph databases excel at efficiently handling relationships and traversals, making them ideal for applications requiring fast, complex queries over interconnected data.
Path-Centric Queries
Use a graph database when your application requires analyzing paths or patterns in connected data, such as finding the shortest path, detecting cycles, or identifying clusters. For example, in a social network, a graph database can quickly find mutual friends or recommend connections by traversing "friend" relationships. Unlike knowledge graphs, which focus on semantic relationships (e.g., "is-a"), graph databases prioritize structural patterns, using query languages like Cypher or Gremlin for efficient path-based queries.
Real-Time Performance
Choose a graph database when low-latency, high-throughput queries are critical, especially for transactional or analytical workloads. For instance, in e-commerce, a graph database can power real-time product recommendations by traversing user purchase histories and product relationships. Unlike knowledge graphs, which may trade speed for semantic accuracy, graph databases leverage native graph storage (e.g., index-free adjacency) to deliver predictable performance for multi-hop queries.
Scalable Transactional and Analytical Workloads
Choose a graph database when your application requires scalability for both transactional and analytical workloads. For instance, in logistics, a graph database can optimize delivery routes (analytical) while processing real-time shipment updates (transactional). Unlike knowledge graphs, which scale through modular vocabularies, graph databases use partitioning and replication to handle large-scale data, ensuring high performance across distributed systems.
Flexible and Evolving Data Structures
Opt for a graph database when you need a flexible, schema-on-read approach to handle evolving or unpredictable data structures. For example, in fraud detection, a graph database can model dynamic relationships between transactions, accounts, and devices without requiring a rigid schema. Unlike knowledge graphs, which rely on governed vocabularies, graph databases allow applications to adapt quickly to new data types or relationships, with validation handled at the application level.
Application-Driven Data Management
Use a graph database when governance and semantics are handled by the application, not the database. For example, in a recommendation engine, the application defines how nodes (e.g., users, items) and edges (e.g., purchases, ratings) are interpreted, while the graph database focuses on fast storage and retrieval. Unlike knowledge graphs, which enforce a centralized vocabulary, graph databases offer flexibility, with governance managed by application teams or database policies.
Can You Use Them Together?
Sure! Knowledge graphs and graph databases complement each other, combining semantic meaning with efficient querying. A graph database can store a knowledge graph, or their outputs can integrate in a system, leveraging the strengths of both.
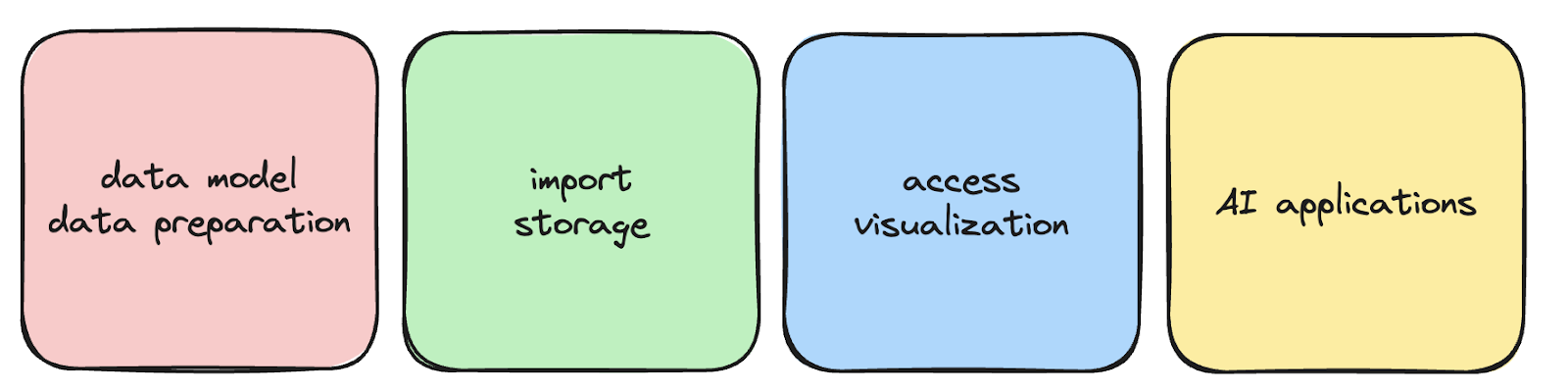
Data Model and Preparation
A knowledge graph begins with defining the entities, relationships, and semantics that matter to your domain. This model ensures that concepts such as “customer,” “order,” or “supplier” have consistent meaning across applications. A graph database then provides the physical layer where these nodes and edges are instantiated, so queries can follow the model efficiently.
Data Integration and Storage Import
Knowledge graphs often draw from many different systems — CRM, ERP, logs, or external sources. The graph database acts as the storage engine where the imported data is represented as connected structures. By aligning these records with the semantic model, the knowledge graph preserves meaning while the database handles persistence and indexing.
Access and Visualization
Once stored, the combined system supports access through graph query languages like SPARQL, Cypher, or Gremlin. The knowledge graph ensures that queries are interpreted in the right context, while the database executes them quickly. Visualization tools then expose these results in intuitive graph views, making it easier for analysts and engineers to navigate complex relationships.
AI Applications
The synergy becomes most visible in AI and analytics. The knowledge graph grounds entities and relationships with semantics, allowing reasoning and inference. The graph database supplies the fast traversal engine that retrieves paths and patterns. Together they support tasks such as GraphRAG, fraud detection, or threat investigation, where both context and performance matter.
Bonus: Knowledge Graph Powered By PuppyGraph

Traditional knowledge graphs often rely on a graph database as the backend. This requires moving or duplicating data into the graph database through ETL pipelines, which introduces delays, maintenance overhead, and data governance challenges. PuppyGraph removes these barriers with its real-time, zero-ETL graph query engine.
Instead of migrating data into a specialized store, PuppyGraph connects to sources including PostgreSQL, Apache Iceberg, Apache Hudi, BigQuery, and others, then builds a virtual graph layer over them. Graph models are defined through simple JSON schema files, making it easy to update, version, or switch graph views without touching the underlying data.
The knowledge graph semantics, including your ontology, vocabularies, and business rules, remain defined at the model layer. PuppyGraph then interprets that schema to run graph queries (in openCypher or Gremlin) directly against the source systems. This ensures:
- One copy of data: no synchronization issues or redundant storage between your warehouse and a graph database.
- Multiple graph views: since schemas are metadata-defined, you can maintain different logical knowledge graphs over the same source tables, each tailored for a use case such as compliance, fraud, or cybersecurity.
- Scalability at lakehouse scale: PuppyGraph is designed to handle petabyte-level datasets and deep, multi-hop queries, which are common in reasoning tasks.
- Integration with AI: by grounding entities and relationships with semantics while still allowing high-performance retrieval, PuppyGraph makes knowledge graphs more effective with GraphRAG and PuppyGraph MCP server.
This approach aligns with the broader shift in modern data stacks to separate compute from storage. You keep data where it belongs and scale query power independently, which supports petabyte-level workloads without duplicating data or managing fragile pipelines.


PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.

Getting started is quick. Most teams go from deploy to query in minutes. You can run PuppyGraph with Docker, AWS AMI, GCP Marketplace, or deploy it inside your VPC for full control.
Conclusion
Knowledge graphs and graph databases address different needs: one encodes meaning, the other delivers fast queries over connected data. Used together, they combine context with performance. Some projects need only one, but many benefit from both. With PuppyGraph, you can achieve the advantages of a knowledge graph without duplicating data into a separate database, making graph analytics faster and simpler to adopt.
You can start experimenting right now with the forever-free PuppyGraph Developer Edition. Then book a free demo to explore how it scales in your environment.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install