

Knowledge Graph vs Ontology : Know the Difference
As data volumes grow and systems become increasingly interconnected, organizations face a recurring challenge: how to represent knowledge in a way that is both machine-readable and meaningful to humans. Traditional databases excel at storing structured records, but they struggle to capture relationships, semantics, and evolving context. This limitation has led to the rise of semantic technologies, among which knowledge graphs and ontologies play central roles.
Although the terms are often used interchangeably, knowledge graphs and ontologies are not the same thing. They solve related but distinct problems, operate at different abstraction levels, and serve different purposes in modern data architectures. Confusing the two can lead to poor system design, unrealistic expectations, or underutilized semantic capabilities. Understanding how they differ, and how they complement each other, is therefore critical for architects, data engineers, and product leaders.
This article provides a comprehensive comparison of knowledge graphs and ontologies. We explore their definitions, structures, historical roots, and practical use cases. By the end, you will clearly understand when to use a knowledge graph, when an ontology is essential, and how the two can work together to power intelligent, context-aware systems.
What Is a Knowledge Graph?
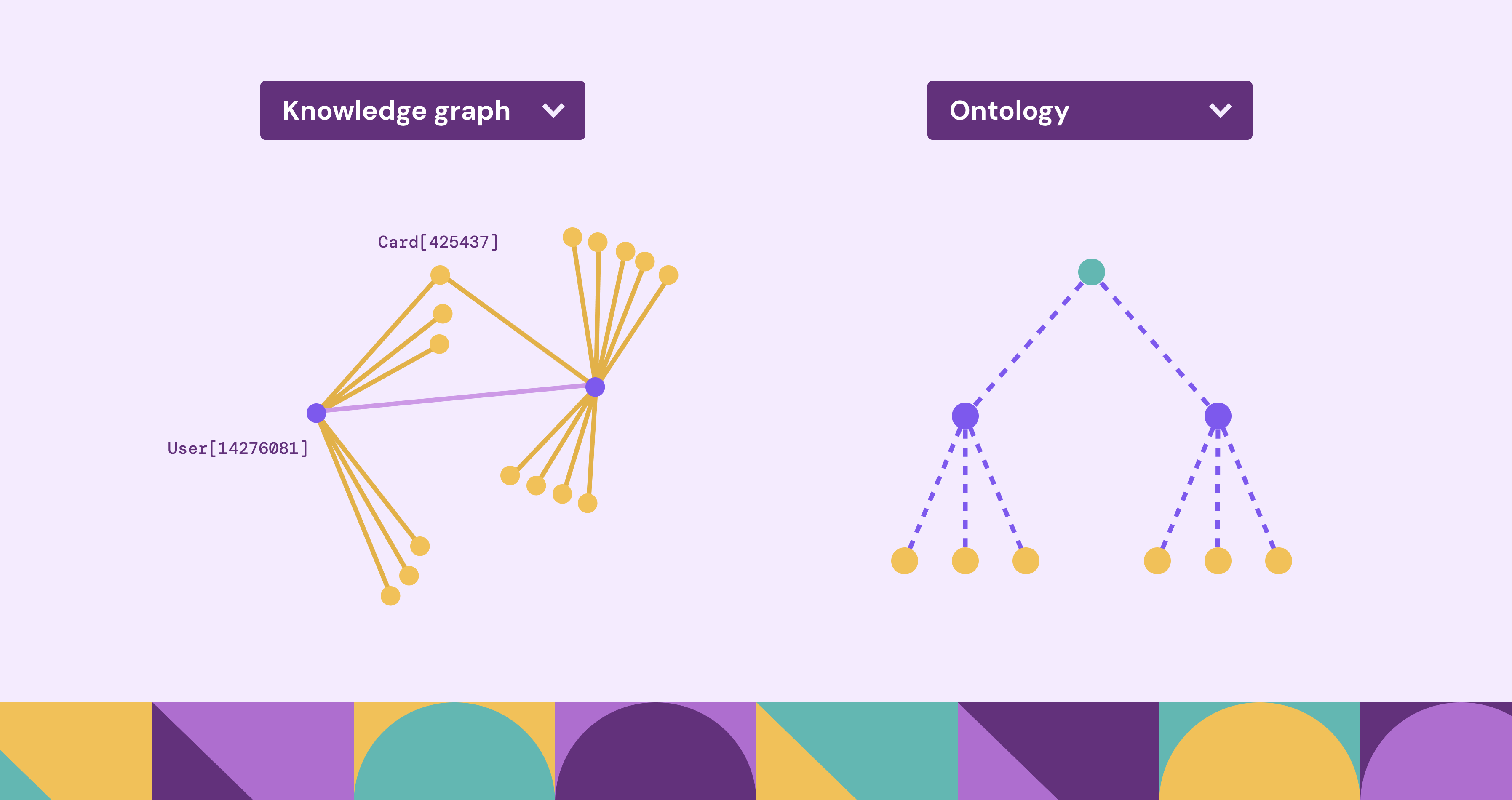
A knowledge graph is a graph-based data representation that connects real-world entities through explicitly modeled relationships. Nodes represent entities such as people, products, locations, or events, while edges represent relationships like ownership, membership, dependency, or interaction. Each node and edge can carry properties, allowing the graph to store both facts and contextual attributes.
Unlike traditional relational models, knowledge graphs are designed to reflect how information is naturally connected. This structure enables flexible querying, traversal-based exploration, and intuitive reasoning over complex domains. Knowledge graphs can integrate data from multiple heterogeneous sources, making them particularly suitable for environments where information is distributed, evolving, and loosely structured.
From a practical perspective, knowledge graphs are often implemented using property graph models or RDF-based representations. Query languages such as Cypher, Gremlin, or SPARQL allow users to express relationship-centric queries that would be difficult or inefficient in SQL-based systems. As a result, knowledge graphs have become a foundational technology for search, recommendation, analytics, and data integration.
Core Characteristics of Knowledge Graphs
A defining feature of knowledge graphs is their emphasis on instance-level data. They focus on representing concrete facts such as “Alice works at Company X” or “Dataset A is produced by Job B.” This makes them highly operational and immediately useful for applications.
Another important characteristic is schema flexibility. While some knowledge graphs enforce schemas, many allow partial or evolving schemas, enabling teams to add new entity types and relationships without costly migrations. This flexibility supports agile development and incremental knowledge discovery.
Knowledge graphs are also inherently query-driven. They are built to answer questions, support exploration, and reveal hidden connections. Their value often increases as more data and relationships are added, creating a network effect that amplifies insight over time.
Common Use Cases of Knowledge Graphs
Knowledge graphs are widely used across industries to solve relationship-centric problems. In search engines, they power entity understanding and rich search results. In e-commerce, they enable personalized recommendations by connecting users, products, and behaviors. In data platforms, they are used to model lineage, ownership, and impact analysis.
In enterprise environments, knowledge graphs are often applied to data catalogs, customer 360 views, fraud detection, and supply chain visibility. Their ability to unify disparate data sources into a coherent, queryable graph makes them particularly effective in complex organizational contexts where data silos are common.

What Is an Ontology?
An ontology is a formal, explicit specification of a shared conceptualization of a domain. Rather than representing individual facts, an ontology defines the types of entities, relationships, constraints, and rules that describe how knowledge in a domain is structured. It serves as a semantic blueprint that ensures consistency, clarity, and shared understanding.
Ontologies are typically expressed using formal languages such as OWL (Web Ontology Language) or RDF Schema. These languages allow the definition of classes, properties, hierarchies, and logical axioms. In graph-based data models, similar conceptual roles can also be played by the labels used in Labelled Property Graphs (LPGs): node labels and edge labels implicitly define entity types and relationship types, and can therefore be viewed as a lightweight or implicit form of ontology that constrains and organizes the graph structure.
Unlike knowledge graphs, ontologies emphasize meaning and semantics rather than raw data. They are designed to answer questions about what kinds of things exist and how they relate conceptually. In many systems, ontologies act as the foundation upon which data is modeled. They provide the vocabulary and rules that guide how instance-level information should be represented, interpreted, and reasoned about.
Core Characteristics of Ontologies
Ontologies are abstract and conceptual by nature. They define categories like “Person,” “Organization,” or “Dataset,” rather than specific individuals such as Alice or Company A. This abstraction allows ontologies to be reused across systems and datasets.
Another defining characteristic is formal semantics. Ontologies are designed to support logical reasoning, enabling machines to infer new knowledge from existing definitions. For example, if an ontology defines that every employee is a person, and Alice is an employee, a reasoner can infer that Alice is also a person.
Ontologies also emphasize shared understanding. They are often developed collaboratively by domain experts to ensure that terminology and relationships are interpreted consistently across teams, tools, and organizations.
Common Use Cases of Ontologies
Ontologies are widely used in domains where precision, interoperability, and reasoning are critical. In healthcare, they underpin standardized vocabularies for diseases, treatments, and procedures. In life sciences, ontologies describe genes, proteins, and biological processes. In enterprise settings, they support master data management and semantic integration.
Ontologies are also essential in the Semantic Web, where they enable data published by different organizations to be understood and combined meaningfully. By providing a shared semantic layer, ontologies reduce ambiguity and enable automated reasoning across distributed datasets.

How Is a Knowledge Graph Different from an Ontology?
The primary difference between a knowledge graph and an ontology lies in what they represent and how they are used. A knowledge graph represents concrete facts about specific entities and their relationships, while an ontology represents knowledge about the structure and meaning of those facts. In other words, a knowledge graph answers “what is happening,” whereas an ontology answers “what does it mean.”
Knowledge graphs are data-centric and instance-driven. They focus on concrete entities and relationships that can be queried directly by applications. Ontologies, by contrast, are model-centric and definition-driven. They provide the conceptual framework that ensures data is interpreted consistently and correctly.
Another important distinction is their role in reasoning. Ontologies are explicitly designed for logical inference, enabling systems to derive new knowledge based on formal rules. Knowledge graphs may support reasoning, but this capability often depends on whether they are linked to an underlying ontology or semantic schema.
Structural and Functional Differences
From a structural perspective, knowledge graphs tend to be larger and more dynamic than ontologies. They continuously evolve as new data is ingested, relationships change, and entities are added or removed. Ontologies, on the other hand, are relatively stable, as changes to core concepts and definitions can have wide-ranging implications.
Functionally, knowledge graphs are often optimized for performance and scalability, supporting real-time queries and analytics. Ontologies prioritize correctness and expressiveness, sometimes at the cost of computational efficiency. This trade-off reflects their different goals: operational insight versus semantic rigor.
Complementary, Not Competing Concepts
Despite their differences, knowledge graphs and ontologies are not mutually exclusive. In fact, they are often most powerful when used together. An ontology can define the schema and semantics that guide the construction of a knowledge graph, while the knowledge graph provides the data that brings the ontology to life.
In such architectures, the ontology acts as the semantic backbone, ensuring consistency and enabling reasoning, while the knowledge graph serves as the scalable, queryable data layer. This combination is common in enterprise knowledge platforms, semantic search systems, and advanced analytics solutions.
Knowledge Graph vs Ontology: Side-by-Side Comparison
This comparison highlights why choosing between a knowledge graph and an ontology is not about superiority, but about fitness for purpose.
A Brief History: Knowledge Graph and Ontology
The idea of representing knowledge in structured forms has a long history in computer science, but knowledge graphs emerged as a distinct and influential concept relatively recently. At their core, knowledge graphs model real-world entities and the relationships between them in a graph structure, enabling flexible querying, reasoning, and integration of heterogeneous data. While early database systems focused on tables and schemas, graph-based representations proved more natural for capturing complex, interconnected knowledge.
The modern rise of knowledge graphs was strongly influenced by advances in artificial intelligence, information retrieval, and large-scale data management. A major turning point came in 2012, when Google publicly introduced its Knowledge Graph, demonstrating how graph-based knowledge representations could significantly enhance search, question answering, and user experience. This milestone popularized the term “knowledge graph” and highlighted its practical value beyond academic research. Since then, knowledge graphs have become a core component of enterprise data architectures, supporting applications such as recommendation systems, data integration, intelligent assistants, and analytics.
Ontologies are closely related to, and often embedded within, knowledge graphs. The concept of ontology has deep philosophical roots, originally referring to the study of being and existence. In computer science, ontologies emerged earlier, in the late 20th century, as part of artificial intelligence research on knowledge representation and expert systems. These efforts emphasized formal logic, shared vocabularies, taxonomies, and rule-based reasoning to describe domains in a precise and machine-interpretable way.
The connection between ontologies and large-scale knowledge representation became especially prominent with the rise of the Semantic Web in the early 2000s. Standards such as RDF, RDFS, and OWL were developed to enable interoperable, semantically rich data on the web. Ontologies provided the formal semantics, defining classes, properties, and constraints, while graph-based data models offered a natural structure for linking information across sources.
In contemporary systems, knowledge graphs often serve as the overarching framework, with ontologies playing a supporting but essential role. Ontologies supply the conceptual schema and semantic consistency, while knowledge graphs focus on scalable data integration, real-world entity modeling, and practical applications. Together, they reflect a convergence of ideas from philosophy, artificial intelligence, and web technologies, forming the foundation of modern semantic data systems.
Which Is Best: Knowledge Graph or Ontology?
Knowledge graphs and ontologies are not competing solutions but complementary components of the same ecosystem. Knowledge graphs excel at integrating large, heterogeneous datasets and representing relationships at scale, while ontologies provide precise domain concepts, shared vocabularies, and formal semantics that clarify meaning. Rather than replacing one another, they address different but interdependent aspects of intelligent system design: structure and connectivity on one side, conceptual rigor and semantic consistency on the other.
In practice, the most effective systems combine both. Ontologies supply the semantic foundation, defining concepts, relationships, and constraints, while knowledge graphs operationalize that foundation by instantiating it with real-world data. A knowledge graph without an ontology risks weak or ambiguous semantics, while an ontology without a knowledge graph often remains theoretical and disconnected from operational use. Modern intelligent architectures therefore succeed not by choosing between knowledge graphs and ontologies, but by integrating them to achieve systems that are scalable, data-rich, and meaning-aware.
Building Knowledge Graphs with PuppyGraph
In practice, modern knowledge graphs rarely consist of instance data alone. Most real-world systems combine instance graphs, which capture concrete entities and relationships, with ontology or schema-level definitions, which encode types, semantics, and structural constraints. A usable knowledge graph is therefore not one or the other, but the combination of both.
While this combined model is well understood conceptually, how to build it remains a major challenge. Traditional approaches typically require teams to design ontologies or schemas upfront, transform relational data into graph form through complex ETL pipelines, and load the resulting instance graph into a dedicated graph database. Schema evolution and instance data ingestion are tightly coupled, making iteration slow, costly, and operationally fragile.
PuppyGraph takes a different approach. Instead of materializing graphs through upfront modeling and ETL pipelines, it introduces a virtual graph layer over existing data systems, decoupling schema definition from data ingestion. The graph schema is defined declaratively in a lightweight JSON file that describes vertex types, edge types, and their mappings to underlying tables and keys. This makes graph modeling highly flexible: multiple graph models can be created from the same data source simply by defining different JSON schema files, allowing the same data to be interpreted through different semantic lenses.
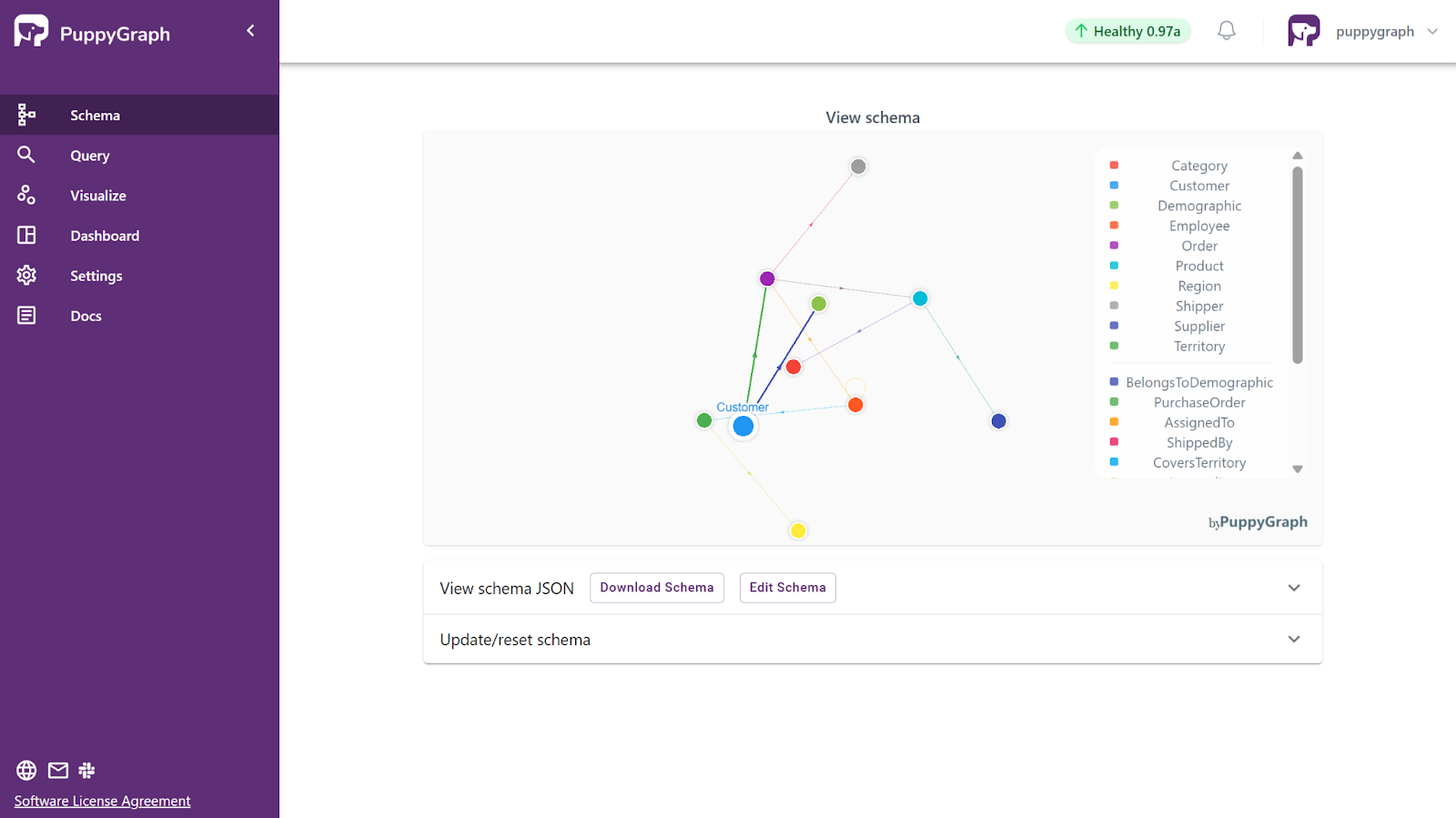
This schema-driven abstraction naturally extends to building knowledge graphs. The schema acts as a semantic layer that defines domain concepts and relationships explicitly, while graph queries operate directly on these semantics rather than on tables and joins. As a result, questions that reflect domain knowledge can be expressed as intuitive graph traversals, while the underlying data still remains relational. This separation between semantic modeling and physical storage enables knowledge graphs to be built and refined incrementally, without restructuring data or introducing complex pipelines.


PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.




Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Knowledge graphs and ontologies complement each other in modern semantic data systems. Knowledge graphs capture concrete entities and relationships, while ontologies define the conceptual framework that ensures consistency, semantics, and shared understanding. Combined, they enable intelligent applications that are both data-rich and meaning-aware.
Yet, implementing this combination has traditionally required heavy ETL processes, duplicated storage, and periodic graph refreshes, making real-time insight difficult. PuppyGraph overcomes these challenges by enabling zero-ETL, live querying of existing relational databases and data lakes. This approach decouples instance-level graphs from ontology definitions, allowing iterative modeling, high-performance queries, and reduced operational costs. PuppyGraph thus transforms knowledge graphs from static models into practical, production-ready systems that deliver real-time, scalable, and semantically grounded insights.
To see how knowledge graphs and ontologies can work together in practice, download PuppyGraph’s forever-free Developer Edition, or book a demo to explore how it operationalizes semantic models directly on your data.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install