

LLM Knowledge Graph: Merging AI with Structured Data
.png)
Large Language Models (LLMs) have revolutionized artificial intelligence, offering unprecedented power in language generation and synthesis. However, relying solely on their internal knowledge base presents critical obstacles: factual inaccuracy, known as hallucination, and a lack of transparency.
To overcome this, organizations are turning to knowledge graphs. A knowledge graph is a structured network that maps real-world entities and explicitly defines the complex relationships between them, offering contextual insight that helps machines reason and understand complex scenarios.
Combining these two technologies, the LLM knowledge graph, or Graph Retrieval-Augmented Generation (GraphRAG), gives the LLM a trusted, verifiable external source of truth. This grounding is essential for building highly accurate, domain-specific (vertical) LLM agents capable of delivering reliable, auditable intelligence for specific business applications.
What is LLM Knowledge Graph
At its core, a knowledge graph is a structured representation of information, contrasting sharply with unstructured text or mere collections of isolated facts. It goes far beyond simply storing data, showing the interconnections among entities in a machine-readable form, providing the contextual understanding necessary for deep inference.
The LLM knowledge graph is a synergistic, hybrid framework that integrates the natural language processing capabilities of LLM with the explicit, verifiable, and structured knowledge stored in a knowledge graph. Before the LLM attempts to answer a user's question, it employs a hybrid retrieval strategy and queries the knowledge graph if needed. Powered by the knowledge graph, LLM can retrieve deterministic, verified facts to ground its response, ensuring a trusted result.
Critically, this process abstracts the intricacies of traditional database interactions: users no longer need to manually craft query language (such as Cypher, Gremlin and SPARQL). Instead, they can simply pose queries to the system in natural language.
Why Combine LLMs with Knowledge Graphs
Standalone LLM lacks deep domain-specific knowledge and can generate hallucinations, undermining their reliability in professional settings. On the other hand, knowledge graphs, while storing structured, factual data, require specialized query language, making them inaccessible to non-technical users.
Integrating knowledge graphs with LLM resolves these limitations. Knowledge graphs act as a trusted knowledge base to curb hallucinations and empower the development of vertical-domain models tailored to specific industries. Additionally, users can interact with the combined system via natural language, no technical expertise needed. This synergy merges LLM’s linguistic fluency with knowledge graphs’ accuracy, creating reliable, user-friendly AI tools for diverse professional scenarios.
How an LLM Knowledge Graph Works
The operational mechanism of an LLM knowledge graph system is centered on the GraphRAG pipeline, which leverages the LLM's language skills to interact with the graph's structural data. This process is executed in the following steps:
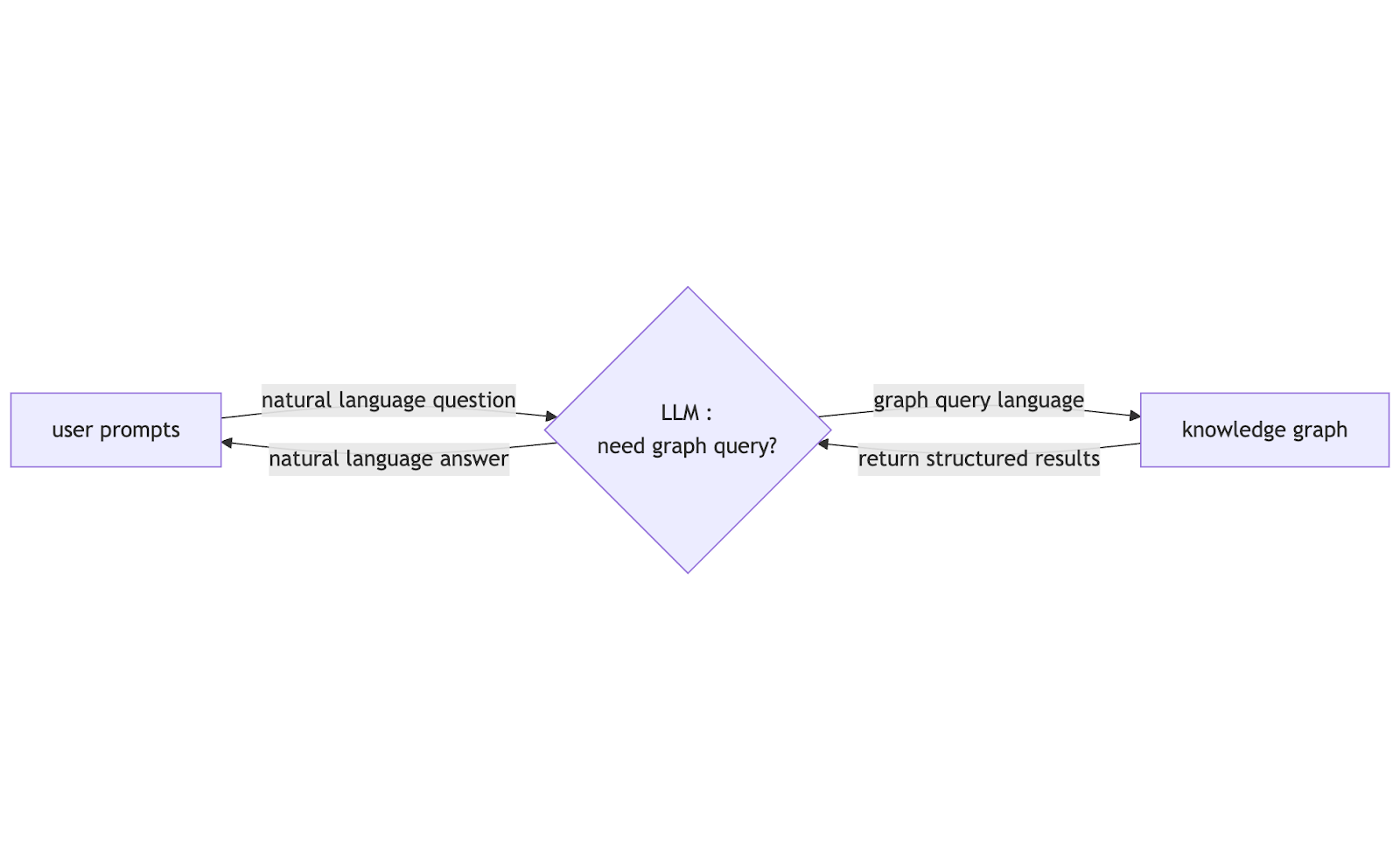
- Natural Language Processing and Hybrid Retrieval Strategy: The process begins when the user submits a natural language question. The system first analyzes the question, using a hybrid retrieval strategy to determine whether the question requires querying the structured knowledge graph.
- Formal Query Code Generation: If the system determines that accessing the structured data is necessary, the LLM is prompted to generate the precise formal query code. The LLM knowledge graph can read the graph schema (ontology, entity types, and relationships) and provide this information, along with the required query code style (e.g., Cypher or Gremlin), to the LLM as the system prompt. This contextual guidance significantly improves the quality and correctness of the formal query code.
- Query Execution and Result Return: The generated formal query code is executed by the knowledge graph engine. It efficiently performs structured traversal and multi-hop pathfinding across the graph, retrieving the exact, connected data points, and returns these structured results to the LLM.
- Synthesis and Final Answer Generation: The LLM receives the original question, along with the newly retrieved, verified, and structured results from the graph engine. It reads the deterministic results and uses its superior natural language generation capabilities to formulate a coherent, context-rich, and grounded final answer for the user.
Key Components and Architecture of an LLM Knowledge Graph
The LLM knowledge graph pipeline typically consists of: LLM interface, tool calling layer, the graph query engine and the data source.
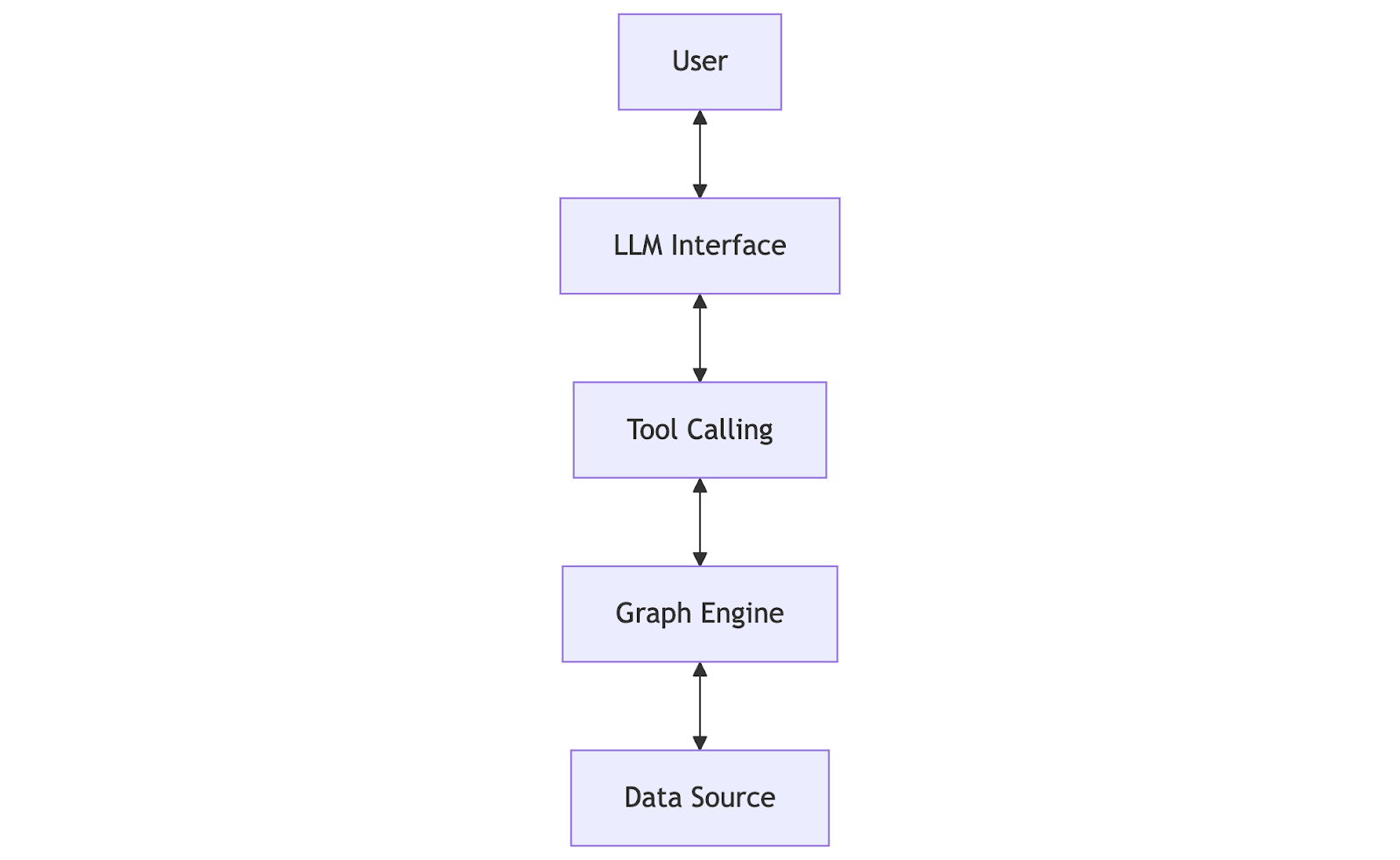
Functions and key characteristics of these key components are summarized in the following table:
Benefits of Using LLM Knowledge Graphs
The strategic use of knowledge graphs delivers profound and measurable benefits that resolve the most critical limitations of standalone LLMs:
- Effective Hallucination Mitigation: By grounding responses in a verifiable knowledge graph, the system drastically reduces the incidence of factual errors, fundamentally enhancing the trustworthiness of the output.
- Enabling Reliable Vertical Agents: The knowledge graph provides the necessary, relationship-rich enterprise context, dynamic data updates, and high accuracy required by specialized, domain-specific (vertical) LLM agents.
- Intuitive Natural Language Querying: The LLM enables users to ask questions in plain language rather than complex code. The automatic translation of the natural language question into a formal graph query democratizes access to deep, relational data analysis, making it accessible to a wide audience without specialized query language skills.
- Traceability: Since every response is built on a documented path of entities and relationships, the system can generate human-understandable explanations, allowing users to trace the reasoning, audit the data sources and verify the model's decision process.
Use Cases and Applications
The LLM Knowledge Graph paradigm is transforming high-stakes, data-intensive industries by enabling superior relational analysis and verifiable factuality across several critical domains:
- Fraud Detection: By analyzing transaction data, customer profiles, and risk signals within a graph context, the LLM knowledge graph system can connect multiple small transactions across accounts to reveal larger, previously hidden fraudulent schemes and enhance risk management.
- Cybersecurity: LLM knowledge graphs enhance cybersecurity by fusing contextual reasoning with structured threat data, enabling precise attack detection, rapid vulnerability mapping, and explainable risk mitigation.
- Scientific Semantic Search: LLM knowledge graphs excel at understanding specialized terminology via structured domain knowledge. It accurately deciphers users’ complex queries and retrieves analogous concepts, bridging semantic gaps to deliver precise, context-rich results for academic research.
- Enterprise Knowledge and Complex Question Answering: It powers reliable internal systems, such as customer support tools and legal or compliance applications, ensuring consistent, verifiable answers across vast organizational data stores, unlocking the ability to answer complex, schema-intensive business questions.
- Healthcare: Mapping complex relationships between symptoms, diagnostic relations, and drug interactions, LLM knowledge graphs enable doctors to create personalized treatment plans that account for individual factors.
- Custom Personalization: In fields like e-commerce and media, knowledge graphs provide the necessary underlying structure for personalized and effective customer interactions. By analyzing these relational links, LLM can leverage the knowledge graph to deliver highly personalized and accurate product recommendations.
Challenges and Considerations
Despite the transformative benefits, deploying and maintaining LLM knowledge graph systems presents several significant challenges:
- Data Integration and Freshness: Knowledge graphs must be assembled from numerous, often diverse and independently developed, enterprise data sources. This often requires complex ETL processes to convert relational or unstructured data into a unified graph structure. This challenge is compounded by the difficulty of handling real-time data or knowledge updates, as continuous evolution is mandatory to ensure the system does not rely on outdated information.
- Query Translation Quality: While the semantic parser abstracts away complex query language, the quality of this translation is not always foolproof. If the LLM misinterprets the user's natural language question, it can generate an incorrect query statement. When this faulty query is executed against the graph database, it returns a deterministic, but factually wrong, result, requiring verification layers to prevent cascading errors.
- Operational Scalability and Query Performance: Enterprise knowledge graphs create big data challenges for query execution. Although specialized, the graph query engine can be slow for deep multi-hop queries across massive datasets. It is essential to continuously optimize query efficiency to maintain high performance and manage the overall operational cost at scale.
- Security and Privacy: Handling proprietary or sensitive enterprise data demands robust safeguards. For organizations leveraging cloud-based models, careful attention is warranted. Utilizing external or public LLMs may prompt considerations around data privacy and secure storage protocols.
Future of LLM Knowledge Graphs
The trajectory of the LLM Knowledge Graph paradigm is moving toward a highly flexible, accessible, and integrated ecosystem:
- Flexible Integration and SOTA Alignment: Future systems will emphasize a modular approach, allowing users to integrate with state-of-the-art (SOTA) LLMs and databases of their choice. This flexibility mitigates vendor lock-in risk and allows organizations to customize their stack, enabling users to choose what LLM or databases they use based on performance, cost, and security requirements.
- Enhanced Query Translation Accuracy: Research will continue to focus heavily on improving the LLM's coding skills, leading to near-perfect accurate query translation. Advances in training techniques and context-specific prompting will ensure the LLM reliably converts complex natural language into correct formal query, significantly reducing the risk of generating inaccurate results from faulty queries.
- Simplified Deployment and User-Friendly UI: The barriers to adoption will be lowered through simplified tooling and frameworks, making the systems easy to deploy. This includes offering robust, user-friendly UI components that visualize the graph, display the underlying query for verification, and abstract away infrastructure complexity, making powerful graph-based reasoning accessible to a wider audience within the enterprise.
Getting Started with LLM Knowledge Graphs
To explore practical implementation of an LLM knowledge graph, feel free to experiment with PuppyGraph RAG Chatbot Demo. First, let’s take an overview of PuppyGraph to set the context.
What is PuppyGraph

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.

Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
LLM Knowledge Graph: PuppyGraph RAG Chatbot Demo
Now it’s time to roll up our sleeves: deploy the PuppyGraph RAG Chatbot and explore how it operates in detail.
Launch PuppyGraph
The first step is to deploy and launch PuppyGraph. We can download the free Docker image, and follow the Launching PuppyGraph in Docker Tutorial. Before starting, make sure docker is available. Verify the installation by running:
docker versionNext, start a PuppyGraph container with the following command. It will download the PuppyGraph image if it hasn’t been downloaded previously.
docker run -p 8081:8081 -p 8182:8182 -p 7687:7687 -e PUPPYGRAPH_PASSWORD=puppygraph123 -e QUERY_TIMEOUT=5m -d --name puppy --rm --pull=always puppygraph/puppygraph:stableThis command maps port 8081 of the container to port 8081 on the host machine, which is the port for the PuppyGraph Web UI. Access the PuppyGraph Web UI at http://localhost:8081, and sign in with the default username (puppygraph) and password (puppygraph123).
Once the server is ready, we can connect PuppyGraph to our existing databases, here we click the “Use example schema/data” button and try the built-in example data Northwind.
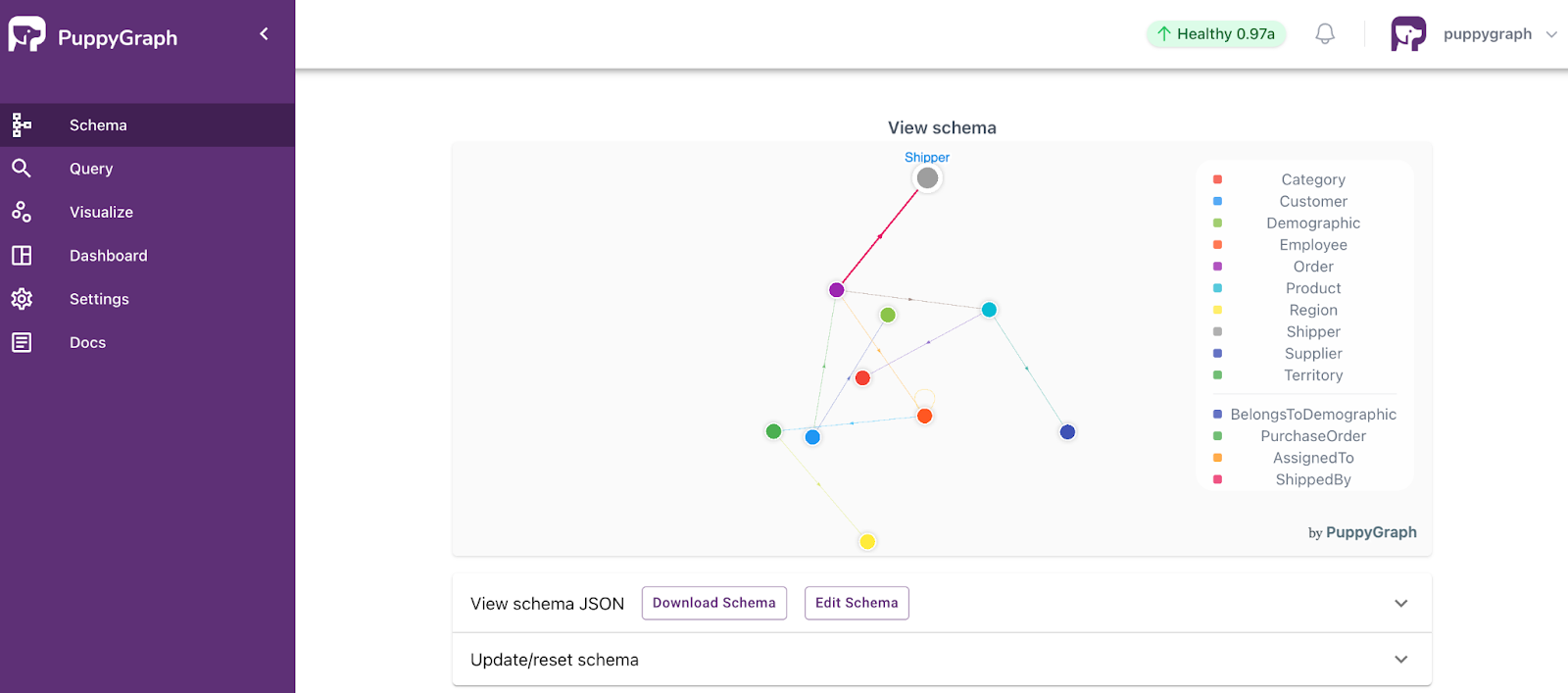
The Northwind database is a classic sample database originally created by Microsoft, containing business entities such as customers and orders, and is widely used in various database tutorials. Loading this sample graph, the page will visualize its schema.
Keep the PuppyGraph server running, let’s move on to the next step.
Install the PuppyGraph RAG Chatbot
We've got all the required resources ready and organized here. You’ll also find a detailed guide there to get you up and running smoothly.
First, clone the repository.
git clone https://github.com/puppygraph/puppygraph-python.gitNavigate to the demo directory.
cd puppygraph-python/apps/chatbotCreate a virtual environment and activate it:
python -m venv venv
source venv/bin/activate Next, install dependencies:
pip install -r requirements.txtCopy the .env.example file to .env:
cp .env.example .envEdit the .env file, put the API key here or set an environment variable ANTHROPIC_API_KEY.
# Anthropic API Key for text-to-cypher generation
ANTHROPIC_API_KEY=your_anthropic_api_key_here
# PuppyGraph Configuration
PUPPYGRAPH_BOLT_URI=bolt://localhost:7687
PUPPYGRAPH_HTTP_URI=http://localhost:8081
PUPPYGRAPH_USERNAME=puppygraph
PUPPYGRAPH_PASSWORD=puppygraph123
# Optional: Gradio Configuration
GRADIO_SERVER_PORT=7860
GRADIO_SERVER_NAME=0.0.0.0Make sure the PuppyGraph server is running, now we can start the chatbot.
python gradio_app.pyFor default settings, visit http://localhost:7860 for the chatbot Web UI.
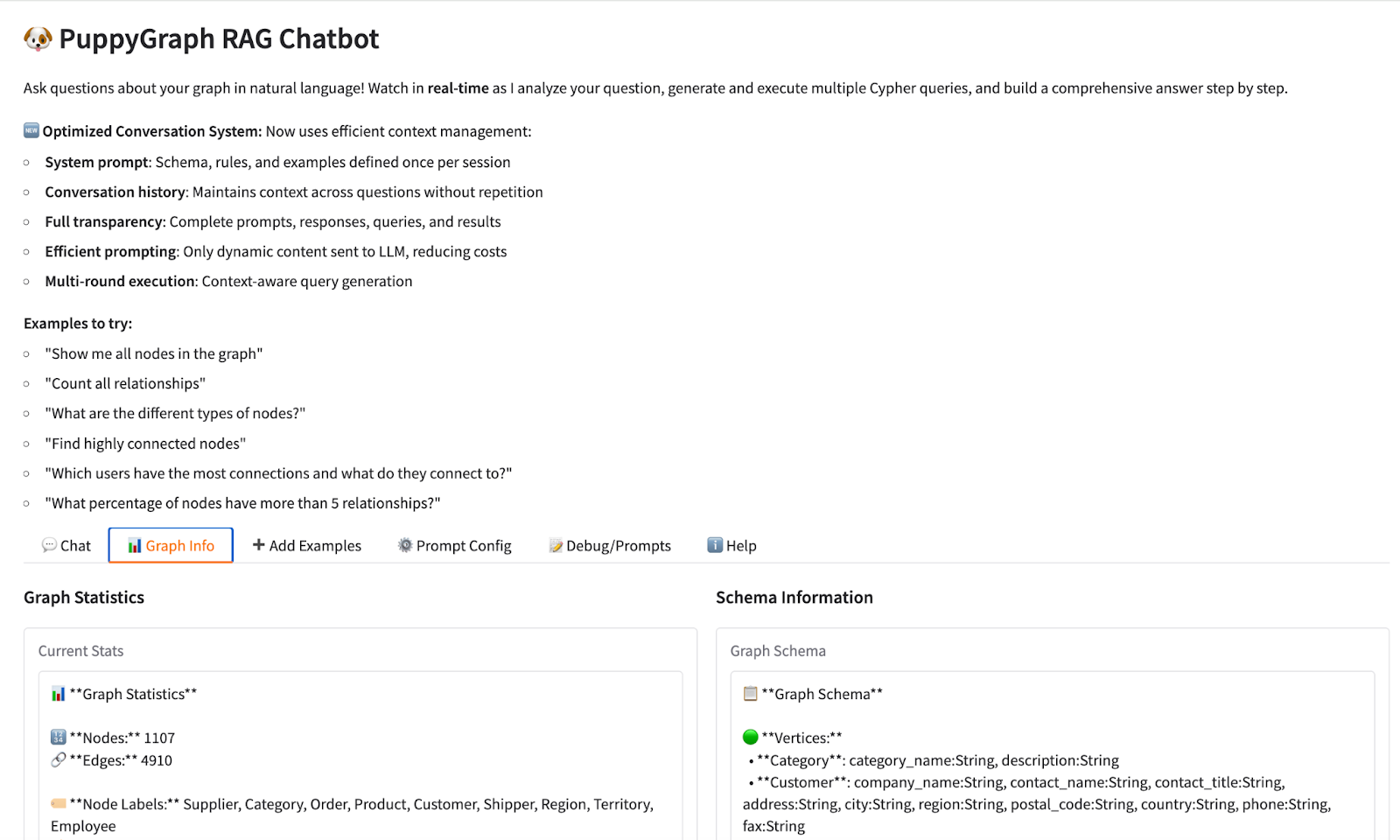
Graph Query in PuppyGraph RAG Chatbot Web UI
Navigate to the Chat column, we can start asking questions in natural language, and expect precise answers from the LLM knowledge graph.
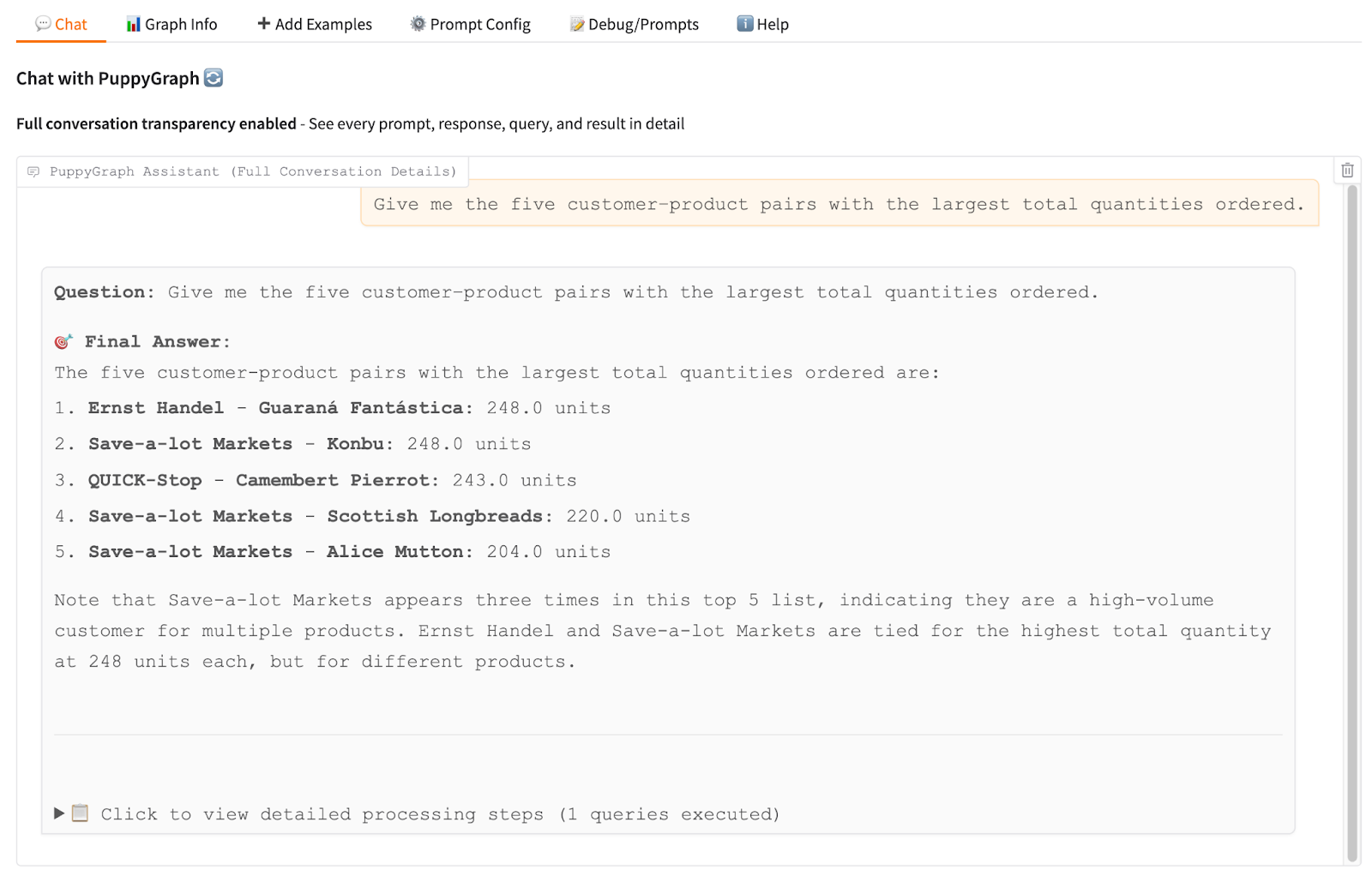
In the example, our question is to find the five customer–product pairs with the largest total quantities ordered. PuppyGraph RAG Chatbot gave us the answer but we may question its correctness. By expanding the full conversation details, we can check if the LLM tool has properly understood and generated the correct formal query code.
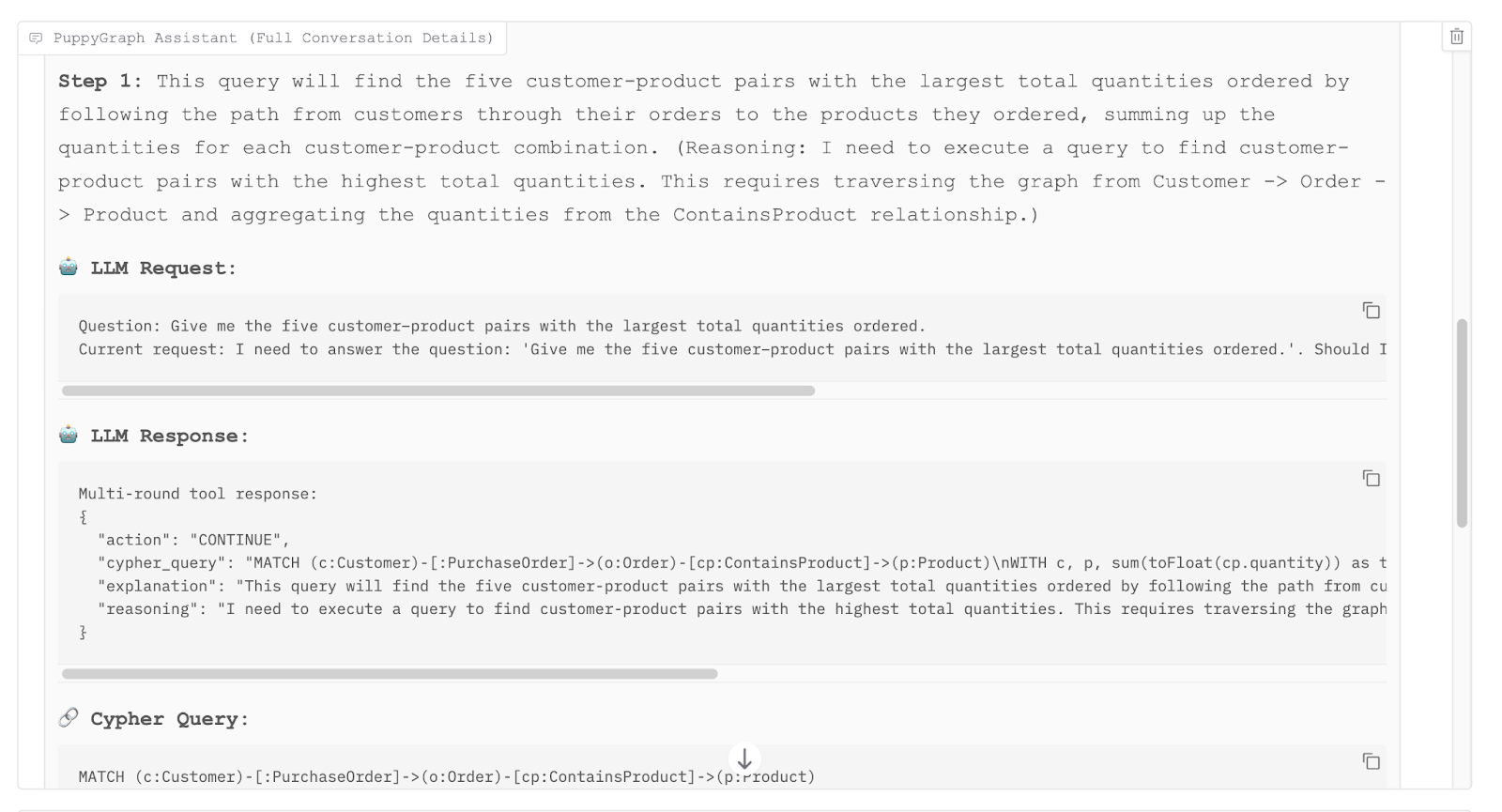
By tracing the execution process of the large language model tool, we found that it traverses the graph relationships from customers through orders to products to aggregate the total item quantities. It then ranks these combinations to isolate the top five pairs, ultimately completing the response to our question.
Conclusion
The LLM knowledge graph is a necessary architectural evolution that fundamentally addresses the risks and limitations of purely parametric AI systems. By leveraging the graph structure for verifiable grounding, deterministic multi-hop reasoning and explicit traceability, it successfully solves the "last mile" problem of enterprise AI: translating raw language capability into reliable, actionable business intelligence.
PuppyGraph is a powerful graph query engine, supporting various databases with zero-ETL. Integrated with LLM, you can immediately build your own LLM knowledge graph with PuppyGraph RAG Chatbot. Ready to give it a spin? Check out our github repository for a free trial.
For the standalone PuppyGraph, try our forever free PuppyGraph Developer Edition or book a demo.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install