

Neo4j vs Redis: Key Differences
Choosing between Neo4j and Redis depends on your data structure and access patterns. Although both are considered NoSQL databases, they both solve fundamentally different problems. Neo4j is a graph database built for exploring relationships between connected entities. Redis is an in-memory data store built for fast key-value access and caching. Understanding how each database approaches data storage, querying, and performance helps you pick the right tool.
Neo4j stores data as nodes and relationships in a property graph model. The database optimizes for traversing connections between entities, making it useful for social networks, recommendation engines, and fraud detection. Redis stores data as key-value pairs in memory, supporting various data structures such as strings, lists, sets, and hashes. The database prioritizes speed over complex querying, making it useful for caching, session storage, and real-time analytics.
This comparison examines the technical differences between Neo4j and Redis across data models, querying capabilities, performance characteristics, and typical use cases. We'll cover when to use each database and how they fit into different application architectures. We'll also discuss PuppyGraph, which provides graph query capabilities directly on existing data without requiring a separate graph database.
What Is Neo4j?

Neo4j is a graph database that stores relationships as native records that directly reference their start and end nodes. The database uses index-free adjacency, where nodes maintain direct references to their relationship chains rather than relying on index lookups. This means traversal performance scales with the number of relationships you explore, not the total size of the dataset.
The data model consists of nodes, relationships, and properties. Nodes represent entities like people, products, or locations. Relationships are directed connections between nodes of a specific type. Both nodes and relationships can have properties as key-value pairs. For example, a Person node might have properties such as "name" and "age," while a KNOWS relationship between two Person nodes might include a "since" property indicating when they met.
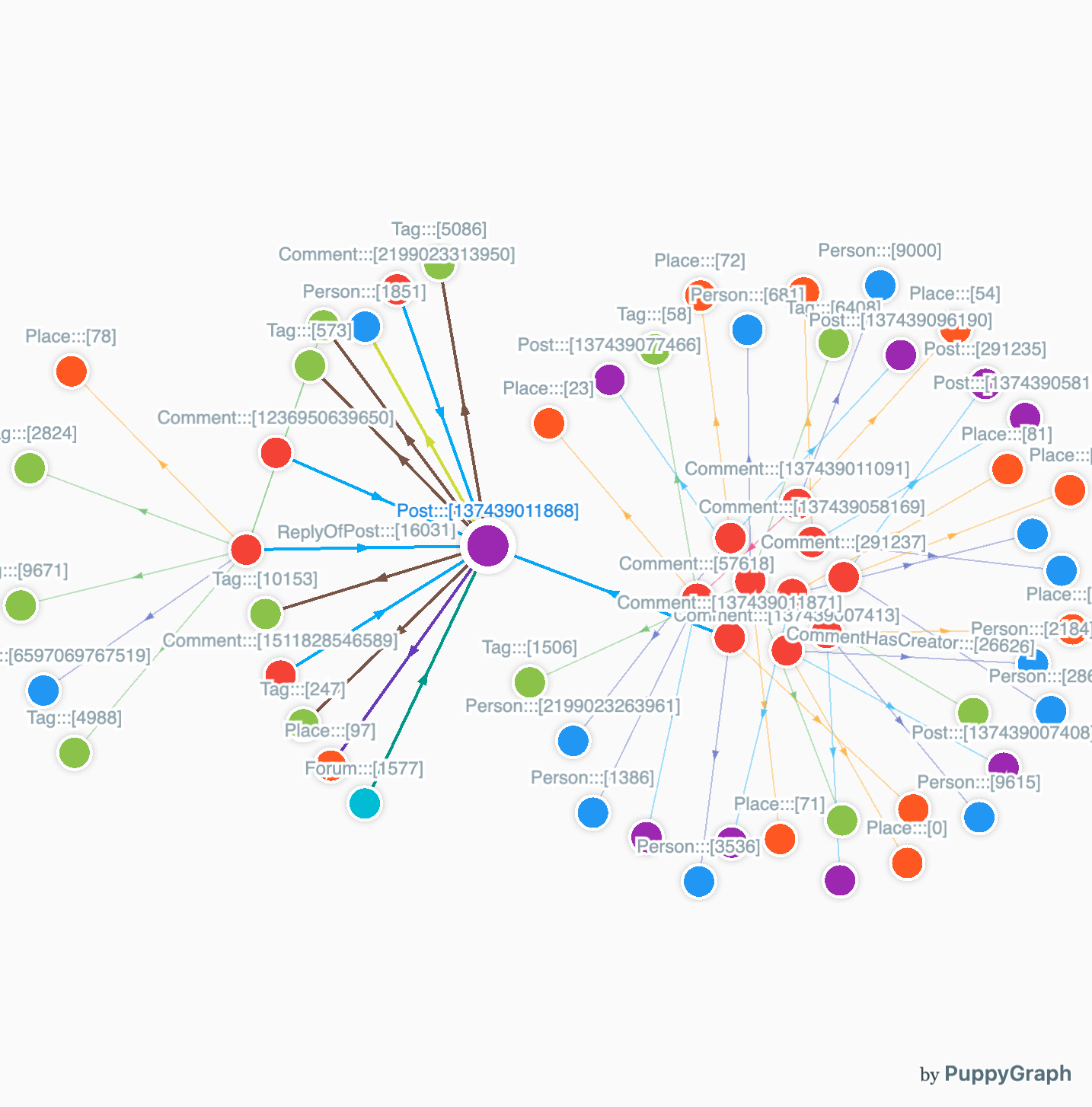
Neo4j uses Cypher as its query language. Cypher provides a pattern-based syntax for describing the shape of the data you want to find. A query like this finds all people that Alice knows:
MATCH (p:Person)-[:KNOWS]->(f:Person)
WHERE p.name = 'Alice'
RETURN fThe query planner automatically decides whether to use indexes or traverse relationships based on query structure.
The database supports ACID transactions with snapshot isolation and locking. When you modify data, Neo4j acquires write locks to prevent conflicts. The database maintains consistency through transaction logs that can be replicated across clusters. Neo4j Enterprise Edition supports clustering with a leader node handling writes and follower nodes serving reads.
Features
Index-Free Adjacency
Relationships are stored as native records containing pointers to start nodes, end nodes, and adjacent relationships. When you traverse from one node to another, Neo4j follows these pointers directly without index lookups. Each hop requires reading a few records from disk or memory. Traversal time scales primarily with the number of relationships explored, regardless of the total number of relationships in the database.
Cypher Query Language
Cypher uses ASCII art syntax to represent graph patterns. Parentheses represent nodes and square brackets represent relationships. The language is declarative, so you describe what data you want rather than how to retrieve it. The query planner chooses execution strategies based on available indexes, relationship types, and estimated cardinalities.
Property Graph Model
Nodes can have multiple labels to classify their type. A single node could have labels like Person and Employee. Relationships are always directed with exactly one type, though you can query them in either direction. Properties on both nodes and relationships are stored as key-value pairs, with typed values such as strings, numbers, booleans, or arrays.
ACID Transactions
Neo4j provides full ACID semantics with write-ahead logging. Transactions acquire locks on nodes and relationships being modified. Concurrent reads see a consistent snapshot from when the transaction started. If two transactions try to modify the same node, one may be aborted due to lock contention (e.g., a deadlock or timeout).
Schema Flexibility
Neo4j doesn't require predefined schemas. You can create nodes with any labels and properties without declaring them first. Indexes and constraints are optional and can be added for query performance or data validation. This lets you iterate quickly during development, though it also means you can create inconsistent data if you're not careful.
Clustering and Replication
Neo4j Enterprise Edition uses a Core + Read Replica architecture. Core servers form a Raft cluster where one leader handles all writes. Followers replicate the transaction log and can take over if the leader fails. Read Replicas asynchronously pull updates from Core servers and handle read-only queries. Writes are coordinated through a single leader at any given time.
What Is Redis?

Redis is an in-memory data store that keeps the working dataset in memory (with optional persistence to disk) for fast access. The database uses a key-value model where each key maps to a value of a specific data type. Unlike traditional databases that store data on disk and cache frequently accessed items in memory, Redis keeps everything in memory by default and optionally persists snapshots to disk.
Keys are always strings, but values can be strings, lists, sets, sorted sets, hashes, bitmaps, hyperloglogs, or streams. Each data type has specific commands for manipulating it. For example, strings support GET and SET commands, while lists support LPUSH and RPOP for adding and removing elements. This data structure support makes Redis more versatile than simple key-value stores.
Redis runs as a mostly single-threaded process that handles commands sequentially. This design avoids locking overhead and makes the behavior predictable. Commands execute atomically, so you don't need explicit transactions for single operations. For multi-command transactions, Redis provides MULTI/EXEC blocks that queue commands and execute them together.
Persistence options include RDB snapshots and AOF (append-only file) logging. RDB takes point-in-time snapshots of the entire dataset at configurable intervals. AOF logs every write operation, giving you better durability at the cost of larger files. You can use both methods together for a balance of performance and safety.
Features
In-Memory Storage
Unlike most database management systems, Redis stores all data in RAM, providing microsecond latency for most operations. Read and write operations complete in under a millisecond on average. This speed makes Redis useful as a cache in front of slower databases or as a primary store for data that needs immediate access. The tradeoff is that the dataset size is limited by available memory.
Multiple Data Structures
Redis supports strings for simple key-value storage, hashes for objects with multiple fields, lists for ordered sequences, sets for unique collections, and sorted sets for ranked data. Each structure has optimized commands. For example, sorted sets use skip lists internally to support O(log N) inserts and range queries.
Pub/Sub Messaging
Redis includes publish-subscribe functionality for real-time messaging. Clients can subscribe to channels and receive messages published by other clients. This works well for chat systems, notifications, or event broadcasting. Messages aren't persisted, so subscribers only receive messages published while they're connected.
Persistence Options
RDB snapshots write the entire dataset to disk at specified intervals. This is fast and produces compact files, but you can lose recent writes if Redis crashes between snapshots. AOF logs every write command, providing better durability. Redis can rebuild the dataset by replaying the log. You can configure Redis to fsync on every write, every second, or never, trading durability for performance.
Replication
Redis supports primary-replica replication, where replicas asynchronously copy data from a primary instance. Replicas can serve read queries to scale read capacity. If the primary fails, a replica can be promoted manually or automatically using Redis Sentinel. Replication is asynchronous, so replicas may lag behind the primary under heavy write load.
Lua Scripting
Redis supports Lua scripts that execute atomically on the server. Scripts can perform complex operations involving multiple keys without a network round-trip. The scripting engine is sandboxed and deterministic, ensuring that scripts produce the same results when replayed from AOF logs.
Clustering
Redis Cluster provides automatic sharding across multiple nodes. Data is distributed across hash slots, with 16,384 slots distributed across cluster nodes. Each key is hashed to determine its slot assignment. Cluster nodes communicate to handle requests and rebalance data when nodes are added or removed. Write operations go to the node that owns the key's slot. Reads are typically served by primaries, but replica reads are possible with the right client configuration.
Core Differences Between Neo4j vs Redis
The two databases offer very different capabilities in terms of architecture, performance, and query capabilities. Looking at the core differences side-by-side, here is how both platforms stack up:
When to Use Neo4j?
Neo4j works well when your application centers on relationships between entities. Here are the primary use cases:
Social Networks
Social networks are a natural fit because you need to traverse friend connections, recommend new connections, or analyze network clusters.
The database can efficiently execute queries such as "find friends of friends" or "find the shortest path between two people" via native graph traversal.
Fraud Detection
Fraud detection systems use Neo4j to identify suspicious patterns across connected entities. You can detect fraud rings by finding groups of accounts that share phone numbers, addresses, or payment methods.
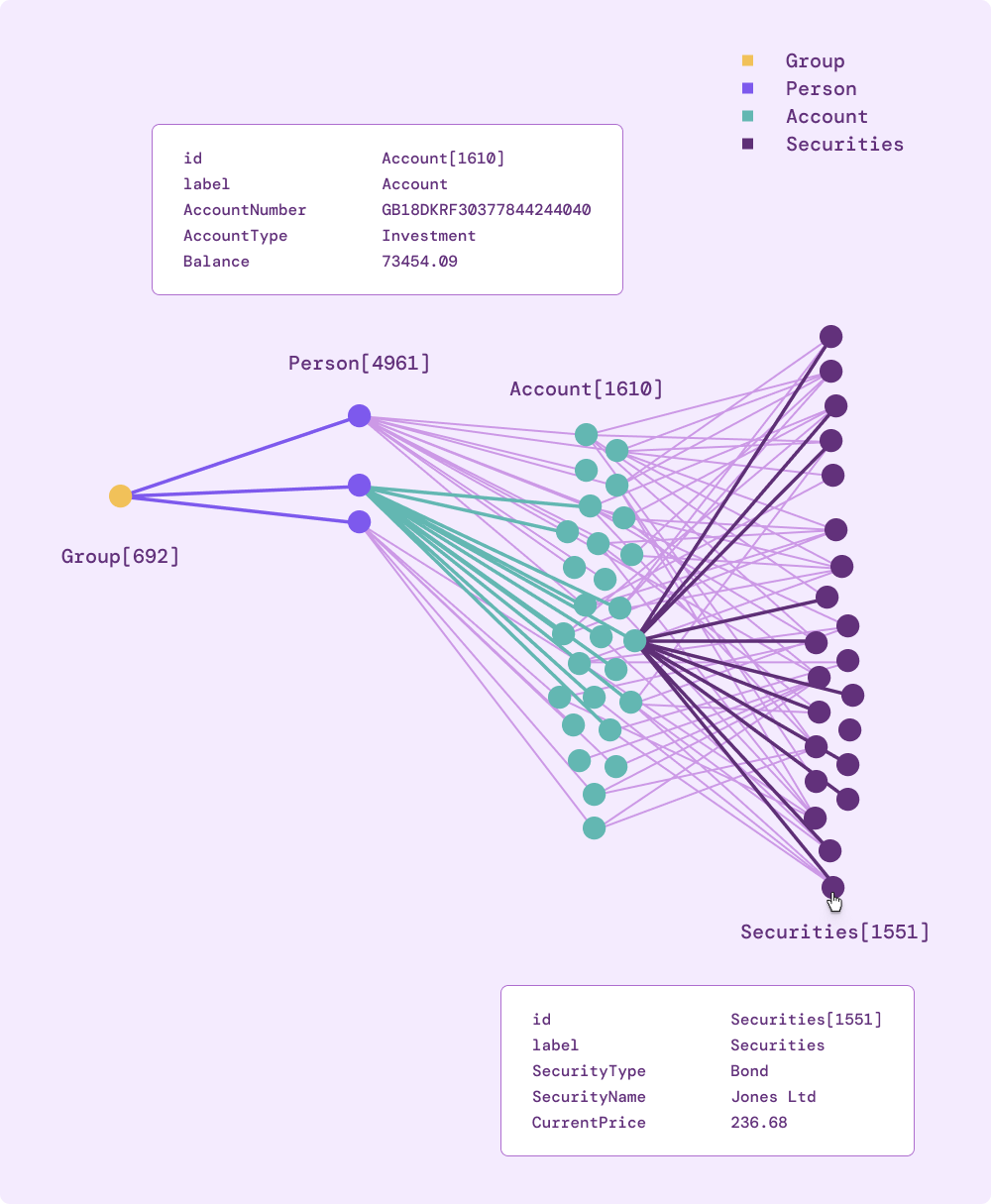
Graph queries make it simple to explore these connections to varying depths and apply pattern-matching rules. Insurance companies use this approach to spot coordinated claims, while banks identify linked accounts involved in money laundering.
Recommendation Engines
Recommendation engines benefit from Neo4j's ability to traverse relationships quickly. You can recommend products based on what similar users purchased, suggest connections based on mutual friends, or find content similar to what a user has engaged with. These queries require exploring multiple hops through the graph. E-commerce sites use graph-based recommendations to surface products through chains like "users who bought X also bought Y, and users who bought Y also bought Z."
Knowledge Graphs and Master Data Management
Knowledge graphs and master data management scenarios are well-suited to Neo4j because they involve complex hierarchies and cross-references between entities. You can model organizational structures, product taxonomies, or data lineage with nodes and relationships. Cypher makes it straightforward to query these structures without complex joins.
Enterprises use Neo4j to build 360-degree customer views by connecting data from CRM, support, billing, and product-usage systems. If you need graph capabilities but want to avoid migrating data into a separate graph database, PuppyGraph lets you run knowledge graph queries directly on your existing data sources.
Network and IT Operations
Network and IT operations use Neo4j to map dependencies between services, servers, and infrastructure components. When troubleshooting incidents, you can quickly identify which systems depend on a failing component and assess the blast radius of changes. DevOps teams query the graph to understand which microservices call each other and trace request paths through distributed systems.
When to Use Redis?
Redis excels in scenarios where speed and simplicity are priorities. Here are the primary use cases:
Caching
Redis excels as a cache layer in front of slower databases. When your application repeatedly queries the same data, Redis can store results in memory and serve them in microseconds instead of milliseconds. This reduces load on primary databases and speeds up response times. Cache invalidation strategies range from simple TTLs to more complex cache-aside or write-through patterns. Common caching scenarios include database query results, API responses, computed data, and rendered HTML fragments.
Session Storage
Web applications can store user sessions in Redis for fast access across multiple application servers. The data is temporary, doesn't require complex queries, and needs to be fast.
Redis's automatic expiration through TTLs makes session cleanup automatic. Storing sessions in Redis also enables stateless application servers that can be scaled independently.
Real-Time Analytics and Leaderboards
Real-time analytics and leaderboards use Redis sorted sets. Gaming applications can maintain leaderboards by storing player scores in sorted sets and querying for top players or a player's rank. The sorted set data structure handles both inserts and rank queries efficiently. Social apps use similar patterns for trending content, most active users, or recent activity feeds.
Message Queuing and Pub/Sub
Redis works for lightweight message passing between services. While Redis isn't a full-featured message queue like RabbitMQ or Kafka, it works well for simple pub/sub scenarios where message durability isn't critical.
Redis Streams provide more durability for applications that need it. Microservice architectures use Redis pub/sub for event broadcasting and simple service-to-service coordination.
Rate Limiting
Rate limiting is often implemented with Redis. You can use atomic increment operations to count requests per time window and reject those that exceed the limit. The atomic operations ensure accurate counting even under concurrent load. APIs use this pattern to enforce quotas per user or prevent abuse through request throttling.
Which is best? (Neo4j vs Redis)
Neo4j and Redis serve different purposes, so "best" depends entirely on your workload. Neo4j is a specialized graph database where relationships are central to your queries. Redis is a general-purpose in-memory store for fast access to various data structures.
Choose Neo4j When
Use Neo4j when your queries primarily traverse relationships, and you have lots of connected data. If you find yourself writing complex SQL joins to explore connections, or if your queries need to explore variable-depth relationships, Neo4j handles these patterns naturally. The database is built for questions like "how are these entities connected" or "what patterns exist in this network."
Choose Redis When
Use Redis when querying data requires speed as the top priority, and when queries are simple. If you need microsecond latency for key lookups, Redis delivers. The database works well for caching, counters, real-time analytics on small datasets, and temporary data storage. Redis excels at simple access patterns but struggles with complex queries across multiple keys.
Using Both Together
You can use both databases together. Many applications use Redis as a cache layer in front of Neo4j to speed up frequently accessed graph data. Redis handles hot data with immediate access requirements while Neo4j stores the complete graph for complex traversals. This combination balances speed and query capability.
When to Consider PuppyGraph
If you need graph query capabilities but want to avoid the operational overhead of maintaining a separate graph database, this is where PuppyGraph's graph query engine offers the best of both worlds. It connects to your existing databases and data lakes, letting you run graph queries without data migration.

PuppyGraph is the first and only real-time, zero-ETL graph query engine on the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing the cost, latency, and maintenance hurdles of traditional graph databases.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the need to rely on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata-driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.




Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Neo4j and Redis are specialized databases built for different workloads. Neo4j focuses on graph data and relationship queries through native graph storage and Cypher query language. Redis prioritizes speed through in-memory storage and simple key-value access patterns.
Choose Neo4j for applications where relationships drive your business logic, and queries need to traverse connections between entities. Choose Redis for applications that need fast access to temporary or cached data with simple lookup patterns.
Beyond traditional databases, PuppyGraph provides graph query capabilities without requiring data migration and a separate database system. PuppyGraph connects to your existing databases and data lakes, letting you run graph queries on data where it already lives. This means you can explore relationships in your data without the operational overhead of maintaining a separate graph database.
To see how it works, get started with PuppyGraph's forever-free Developer edition. You can also book a free demo to explore graph capabilities on your existing data. For more technical comparisons and use cases, visit the PuppyGraph blog.

Matt is a developer at heart with a passion for data, software architecture, and writing technical content. In the past, Matt worked at some of the largest finance and insurance companies in Canada before pivoting to working for fast-growing startups.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install