

OLTP vs OLAP: Key Differences, Use Cases & Comparison

Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP) are two fundamental approaches to data management that support different business needs. As organizations generate increasing volumes of data, selecting the appropriate database architecture becomes critical for maintaining operational efficiency and enabling data-driven decision-making. Although both systems manage and process data, they are designed for distinct workloads and performance objectives.
OLTP systems focus on handling large numbers of real-time transactions with high speed, reliability, and consistency, making them essential for operational applications such as banking and e-commerce. In contrast, OLAP systems are optimized for complex analytical queries across large historical datasets, supporting business intelligence, reporting, and strategic analysis. This article examines the key differences between OLTP and OLAP, including their architectures, performance characteristics, use cases, and how they can work together within modern data ecosystems.
What Is OLTP (Online Transaction Processing)?
OLTP, or Online Transaction Processing, refers to systems designed to process high volumes of short, real-time transactions. These transactions typically involve inserting, updating, deleting, or retrieving small amounts of data while maintaining accuracy and consistency. OLTP systems power day-to-day operational applications such as banking systems, e-commerce platforms, airline reservations, and customer relationship management tools.
An OLTP database prioritizes speed, concurrency, and reliability. Since thousands or even millions of users may access the system simultaneously, OLTP architectures are optimized for rapid response times and continuous availability. Transactions usually complete within milliseconds, ensuring smooth user experiences in interactive applications.
One of the defining characteristics of OLTP systems is adherence to ACID properties: Atomicity, Consistency, Isolation, and Durability. These guarantees ensure that transactions remain accurate even during system failures or concurrent operations. For example, when a customer transfers money between bank accounts, the system must debit one account and credit the other without errors or inconsistencies.
Popular OLTP databases include MySQL, PostgreSQL, Microsoft SQL Server, Oracle Database, and cloud-native systems such as Amazon Aurora. Many modern applications also use distributed transactional databases like CockroachDB or Google Spanner to achieve global scalability while preserving transactional integrity.
Because OLTP systems are highly normalized, they minimize data redundancy and optimize transactional efficiency. However, this structure is not ideal for analytical workloads involving large-scale aggregations or historical trend analysis. That is where OLAP systems become essential.
What Is OLAP (Online Analytical Processing)?
OLAP, or Online Analytical Processing, refers to systems optimized for complex analytical queries across large datasets. Unlike OLTP systems, which focus on operational transactions, OLAP systems are designed for reporting, business intelligence, forecasting, and decision-making.
OLAP databases typically store historical data collected from multiple operational systems. Analysts, executives, and data scientists use OLAP platforms to explore trends, identify patterns, and generate insights through multidimensional analysis. Queries often involve aggregations, joins, filtering, and calculations across millions or billions of records.
A common characteristic of OLAP systems is their multidimensional data model. Data is organized into dimensions and measures, enabling users to analyze information from different perspectives. For example, a retail company may analyze sales by region, product category, and time period simultaneously.
Unlike OLTP databases, OLAP systems are optimized for read-heavy workloads rather than frequent updates. They often use denormalized schemas such as star schemas or snowflake schemas to accelerate analytical queries. Data warehouses and data lakes commonly serve as OLAP environments.
Popular OLAP technologies include Snowflake, Google BigQuery, Amazon Redshift, ClickHouse, Apache Druid, and Microsoft Analysis Services. Modern cloud-based OLAP platforms provide massive scalability and support near real-time analytics for large enterprises.
The primary goal of OLAP is to support strategic decision-making. Businesses rely on OLAP systems for financial analysis, customer segmentation, sales forecasting, supply chain optimization, and operational reporting. Since these queries are computationally intensive, OLAP systems prioritize throughput and analytical efficiency over transactional speed.
OLTP vs OLAP: Key Differences Explained
Although OLTP and OLAP systems both manage data, their architectures and objectives differ significantly. Understanding these differences helps organizations choose the right technology for specific workloads.
The most fundamental distinction lies in workload type. OLTP systems support operational activities involving frequent, small transactions. OLAP systems support analytical activities involving large-scale queries across historical data. As a result, the performance optimizations for each system are entirely different.
OLTP workloads require low latency and high concurrency. For example, an online shopping platform must process thousands of orders simultaneously without delays. In contrast, OLAP workloads prioritize query complexity and analytical depth. A business analyst may run a query examining five years of sales data across multiple dimensions.
Data structure also differs substantially. OLTP databases use normalized schemas to reduce redundancy and ensure transactional consistency. OLAP systems use denormalized schemas to improve analytical query performance and reduce join complexity.
Another major difference involves update frequency. OLTP systems continuously insert and update records in real time. OLAP systems typically receive periodic data loads through ETL (Extract, Transform, Load) or ELT pipelines. This separation ensures analytical queries do not interfere with operational applications.
The users of each system are also different. OLTP systems primarily serve end users and operational applications, while OLAP systems serve analysts, executives, and data scientists. Consequently, OLTP queries are usually simple and predefined, whereas OLAP queries are exploratory and computationally intensive.
The following diagram illustrates the conceptual relationship between OLTP and OLAP systems:
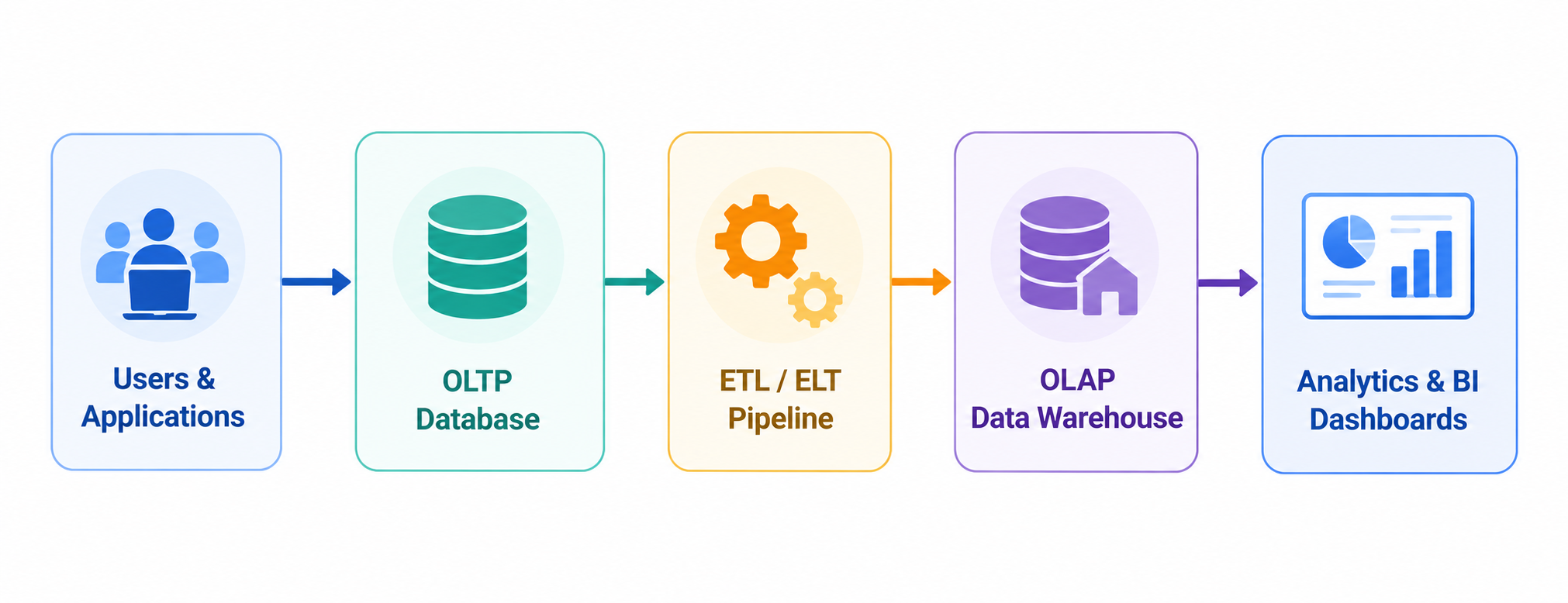
This architecture is common in modern enterprises, where transactional systems feed analytical platforms that generate business insights.
OLTP vs OLAP Comparison Table
The table below summarizes the key differences between OLTP and OLAP systems.
This comparison highlights why OLTP and OLAP systems are rarely interchangeable. Each is optimized for a fundamentally different category of workload.
How OLTP Systems Work
OLTP systems are engineered to support large numbers of concurrent transactions while ensuring consistency and reliability. Their architecture focuses heavily on transactional integrity and low-latency operations.
When a user submits a transaction, the OLTP system validates the request, updates the necessary records, and commits the transaction to the database. The system ensures that multiple users can access the same data simultaneously without conflicts or corruption.
The following diagram illustrates a simplified OLTP workflow:
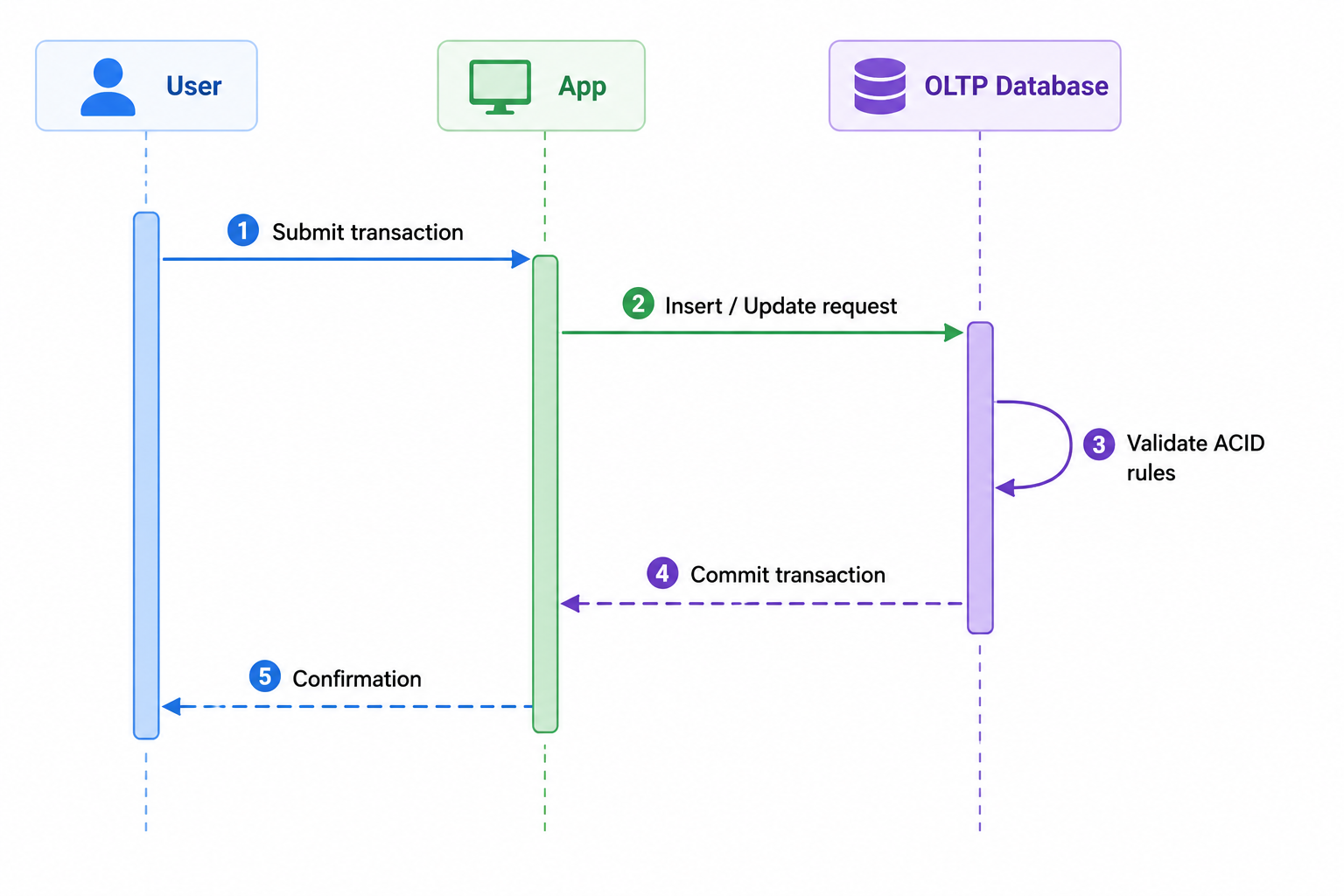
To support high concurrency, OLTP systems use locking mechanisms, indexing strategies, caching, and transaction logs. These components ensure that transactions execute quickly while preserving data consistency.
Indexes are particularly important in OLTP systems because they accelerate point lookups and primary-key searches. However, excessive indexing can slow write performance, so database administrators carefully balance indexing strategies.
Most OLTP systems also use row-based storage because transactions typically access individual records rather than large datasets. Row-oriented databases optimize write efficiency and transactional speed.
Scalability presents another important challenge. Traditional OLTP databases scale vertically by increasing CPU, memory, and storage resources. Modern distributed OLTP systems increasingly support horizontal scaling across multiple nodes to improve resilience and global availability.
Because downtime directly affects business operations, OLTP systems often implement replication, failover mechanisms, and backup strategies to ensure high availability.
How OLAP Systems Work
OLAP systems are optimized for analytical workloads involving large-scale data aggregation and multidimensional exploration. Instead of processing millions of small transactions, OLAP systems process fewer but significantly more complex queries.
Data in OLAP environments is usually collected from multiple operational systems through ETL or ELT pipelines. The extracted data is transformed into analytical structures optimized for reporting and business intelligence.
A typical OLAP architecture looks like this:
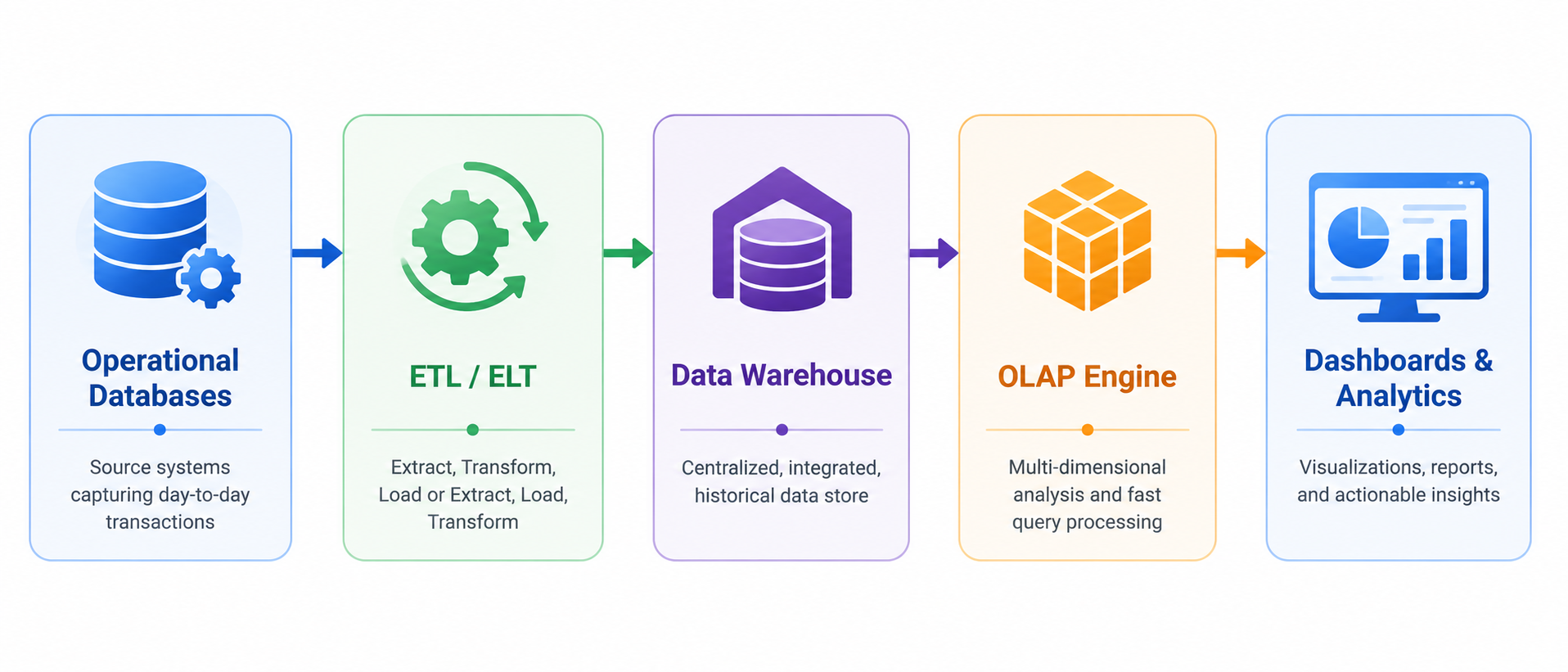
Unlike OLTP databases, many OLAP systems use columnar storage formats. Column-oriented storage significantly improves query performance for analytical workloads because queries often scan only a subset of columns across large datasets.
OLAP queries commonly involve operations such as:
- Aggregations
- Trend analysis
- Time-series analysis
- Data slicing and dicing
- Predictive modeling
Since analytical queries may process billions of rows, OLAP systems emphasize parallel processing and query optimization. Distributed query engines divide workloads across multiple compute nodes, enabling high-performance analytics at scale.
Another important feature of OLAP systems is multidimensional analysis. Analysts can explore data across dimensions such as geography, product category, customer segment, and time period. This capability enables businesses to uncover hidden relationships and make data-driven decisions.
Modern cloud-native OLAP platforms separate compute and storage resources, allowing organizations to scale analytical workloads independently. This elasticity has made cloud OLAP systems increasingly popular for enterprise analytics.
OLTP vs OLAP: Which One Should You Choose?
Choosing between OLTP and OLAP depends entirely on the workload requirements and business objectives. In practice, organizations rarely choose one instead of the other. Instead, they deploy both systems for different purposes.
An OLTP system is the right choice when applications require real-time transaction processing, high concurrency, and strict consistency guarantees. Industries such as banking, healthcare, telecommunications, and retail rely heavily on OLTP databases to support operational workloads.
For example, an online banking application needs immediate transaction processing with accurate account balances. Even a small inconsistency could create serious financial consequences. OLTP systems are specifically designed for this environment.
OLAP systems are more appropriate when organizations need analytical insights from large historical datasets. Companies using business intelligence dashboards, forecasting tools, or machine learning pipelines depend on OLAP infrastructure to support advanced analytics.
A retail company analyzing seasonal sales trends would benefit more from an OLAP platform than an OLTP database. Analytical systems enable rapid aggregation across years of historical data, which would be inefficient in transactional databases.
Several factors influence the choice between OLTP and OLAP systems:
Organizations should evaluate workload characteristics carefully before selecting database architectures. Using the wrong system for a workload often leads to performance bottlenecks and scalability limitations.
Can OLTP and OLAP Work Together?
In modern data architectures, OLTP and OLAP systems frequently work together as complementary components. Operational systems generate transactional data, while analytical systems transform that data into business insights.
This integration enables businesses to maintain high-performance applications while simultaneously supporting advanced analytics. The process usually involves moving data from OLTP systems into OLAP platforms through ETL or streaming pipelines.
Many organizations implement hybrid architectures such as the following:
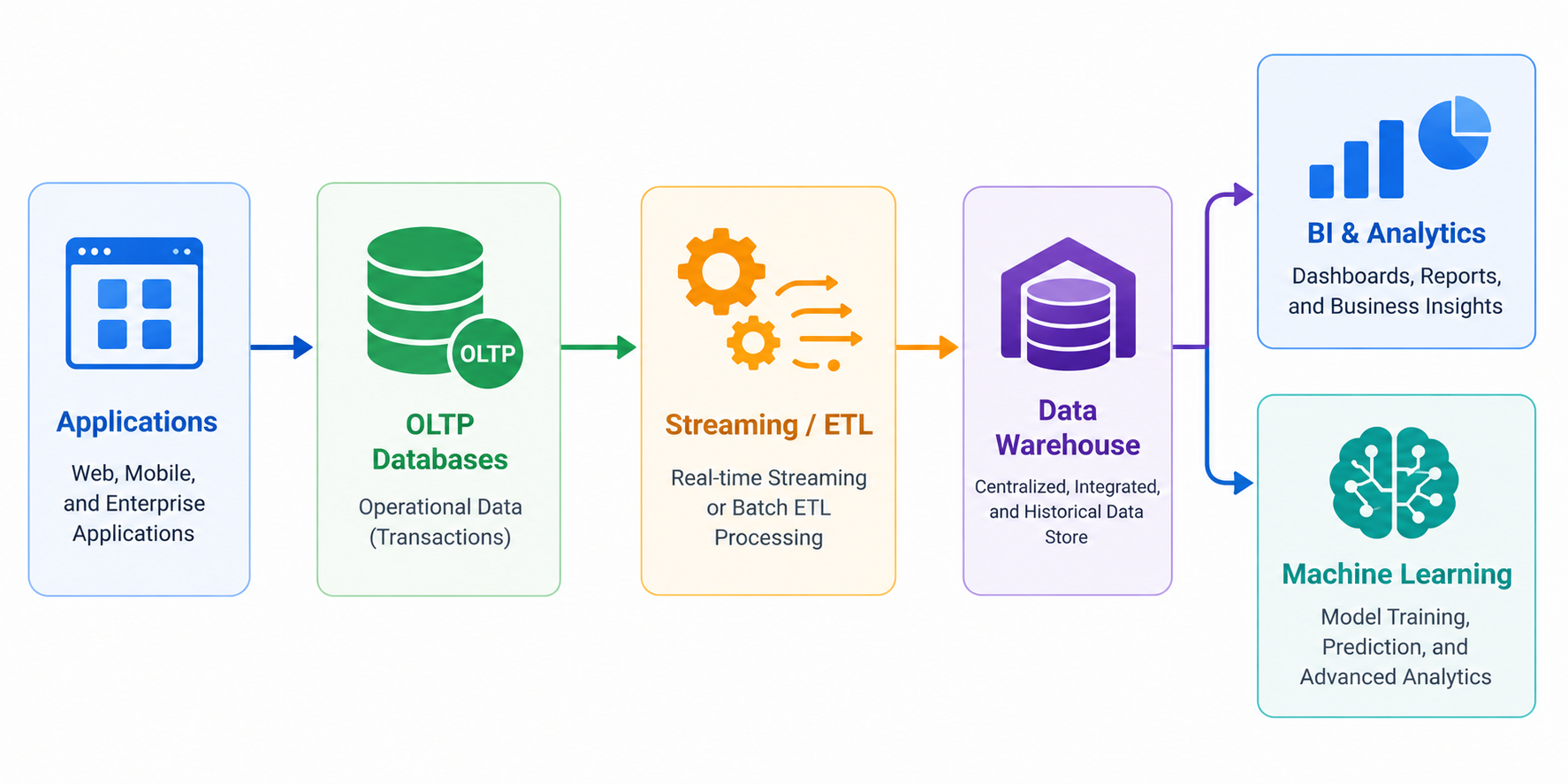
This separation provides several important advantages. Operational workloads remain isolated from analytical queries, preventing reporting jobs from slowing customer-facing applications. At the same time, analytical platforms can optimize storage and compute resources for large-scale processing.
The rise of real-time analytics has also blurred the boundaries between OLTP and OLAP systems. Technologies such as HTAP (Hybrid Transactional and Analytical Processing) attempt to combine transactional and analytical capabilities within a single platform.
HTAP systems enable businesses to analyze operational data in near real time without moving data between separate environments. This approach is increasingly valuable for applications such as fraud detection, recommendation engines, and real-time personalization.
However, fully converged systems still face engineering tradeoffs because transactional and analytical workloads have fundamentally different optimization requirements. As a result, many enterprises continue using specialized OLTP and OLAP systems connected through modern data pipelines.
Beyond OLTP and OLAP: Adding Semantics to Modern Data Systems
Choosing the right database architecture is only the first step. Even when organizations successfully deploy OLTP systems for operational workloads and OLAP platforms for analytics, another challenge remains: making data easier to understand, govern, and access consistently, especially for AI-driven applications.
This challenge becomes increasingly visible in modern enterprise environments where transactional systems, analytical warehouses, and data lakes coexist. Many organizations already store their most critical business data in SQL databases such as PostgreSQL, MySQL, Oracle Database, and cloud-native analytical platforms. These systems provide strong consistency, scalability, and mature operational tooling, but their schemas often reflect physical storage design rather than business meaning.
Tables, foreign keys, and joins describe how data is stored, but not always what the data actually represents. As organizations scale across multiple OLTP and OLAP systems, business meaning often becomes fragmented across schemas, pipelines, and application logic. A semantic layer helps address this gap.
The Role of a Semantic Layer
A semantic layer sits above existing databases and exposes business concepts directly, such as Customer, Order, Product, or Transaction. Instead of forcing applications or AI systems to reason through raw tables and joins, the semantic layer provides a higher-level logical model aligned with business meaning.
This allows developers, analysts, and AI agents to work with data more naturally without changing the underlying OLTP or OLAP infrastructure. It also creates a more consistent way to access information across operational and analytical environments.
Ontology and Ontology Enforcement
At the core of many semantic layers is an ontology: a formal definition of entities, relationships, and rules across the enterprise data environment.
An ontology defines:
- what entities exist,
- how they relate to one another,
- and what relationships are valid.
For example, a Customer may place an Order, an Order may contain a Product, and a Supplier may provide that product.
Ontology enforcement ensures that queries and updates across databases respect these rules. Whether data originates from operational systems, analytical platforms, applications, or AI agents, operations can be validated against the semantic model to prevent inconsistent or logically invalid relationships.
Why It Matters: From Semantic Fog to Agentic Clarity
Without a semantic layer, complexity often shifts into application code and data pipelines, making systems harder to maintain as organizations grow.
For AI systems, this challenge becomes even greater. Large language models and autonomous agents can become trapped in semantic fog: navigating inconsistent schemas, ambiguous joins, and unclear relationships across transactional and analytical systems. This can lead to operations that are syntactically correct but logically wrong.
An AI agent may successfully generate a query or connect two entities, yet create a relationship that does not exist in the real world.
Ontology enforcement acts as a semantic guardrail, ensuring that AI-generated reads and writes follow a validated model of how data entities interact. This reduces silent failures and improves trust in automated systems.
It also creates a valuable feedback loop for self-correction. Instead of returning only technical database errors, ontology-aware systems can provide structured semantic feedback explaining why a query or update violates business logic. This allows AI systems to refine their behavior through iteration and gradually learn the rules of the data environment over time.
Data Access with AI Assistants
Moving beyond traditional database access patterns, PuppyGraph provides a graph-based way to access and query existing SQL data as connected knowledge without requiring organizations to migrate everything into a native graph database.
This enables developers and AI systems to explore existing OLTP and OLAP data through graph-style reasoning and relationship-aware retrieval.
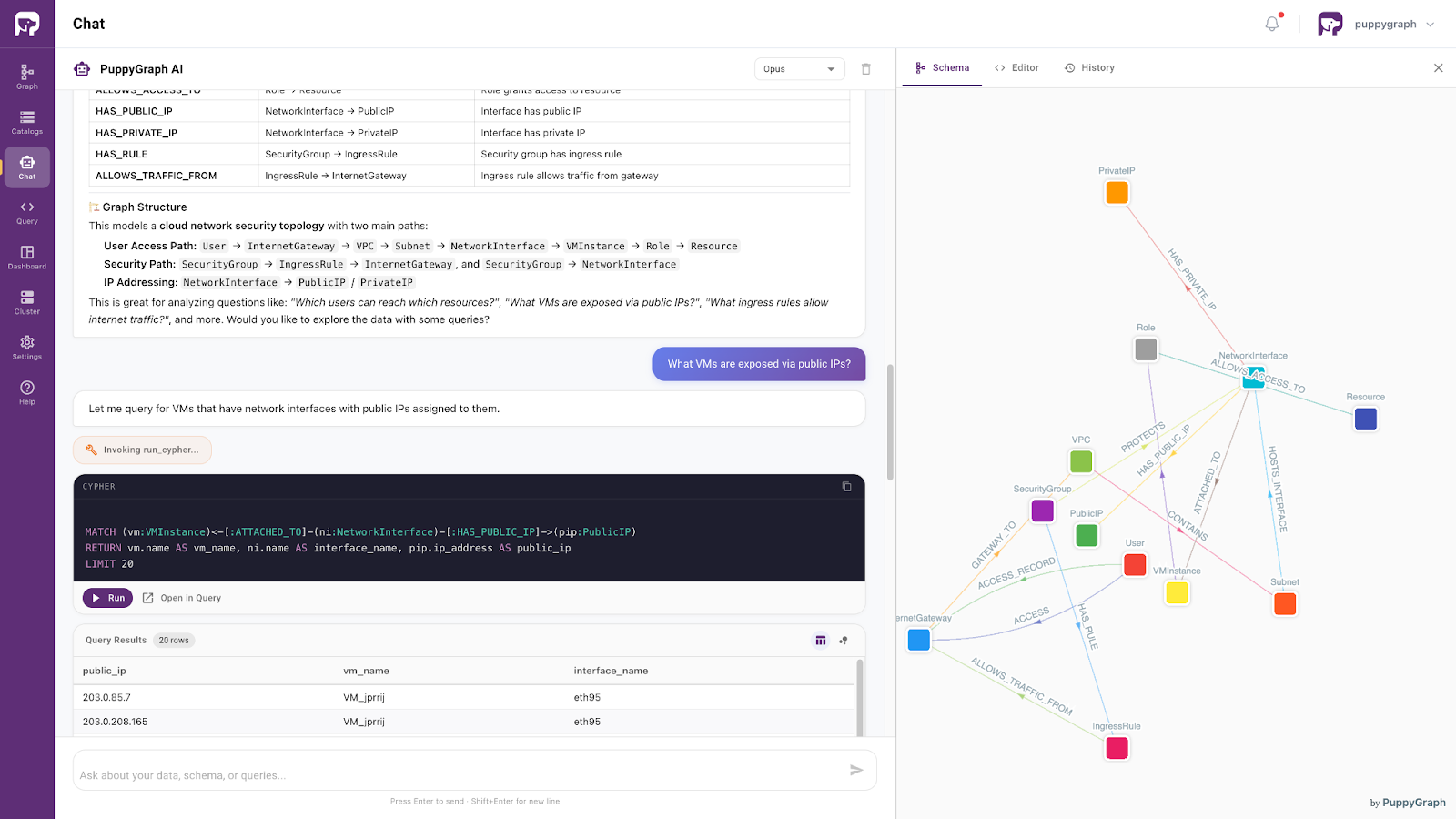
Figure: PuppyGraph AI assistant handling natural language questions
Powered by the same ontology-enforced foundation, this approach supports precise, context-aware access to enterprise data. It allows AI systems to interpret user intent within a well-defined semantic framework and retrieve relevant information accordingly.
As a result, enterprise data evolves from a passive storage layer into an active semantic layer: one that preserves consistency while enabling more reliable search, analytics, and next-generation AI agents.
Conclusion
OLTP and OLAP serve distinct but complementary roles in modern data architectures. OLTP systems are optimized for real-time transactional workloads, emphasizing speed, consistency, and reliability, while OLAP systems support complex analytical queries that enable reporting, forecasting, and strategic decision-making. Understanding their differences in workload patterns, schema design, and performance objectives is essential for selecting the right solution for specific business requirements.
As organizations continue to expand their data ecosystems, OLTP and OLAP increasingly operate together, connected through modern data pipelines and enhanced by semantic technologies. Semantic layers and ontology enforcement help bridge the gap between data storage and business meaning, improving data accessibility, governance, and AI-driven applications. By combining transactional efficiency, analytical power, and semantic understanding, enterprises can build more intelligent, scalable, and trustworthy data platforms.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see how ontology-enforced graph access transforms existing OLTP and OLAP data into AI-ready knowledge.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install