

Palantir Ontology: Architecture & Benefits

If you've spent any time around enterprise data teams lately, you've probably heard "ontology" twice as often as you used to. The phrase comes up in AI agent pitches, in lakehouse roadmaps, in boardroom slides about digital twins. Most of the time, the reference point is the same one: Palantir Ontology, the operational layer at the heart of Palantir Foundry and AIP.
The marketing version is easy to paraphrase. The actual mechanics, less so. What does Palantir mean when they say "ontology"? How does it physically work? And why are data teams that have never touched Foundry still paying attention to it?
This post walks through Palantir Ontology end-to-end. Architecture, benefits, trade-offs, and how it fits next to the other semantic and knowledge-graph approaches you're likely already comparing.
What Is Palantir Ontology?
Palantir's own definition is the cleanest starting point. From the official Foundry documentation: the Palantir Ontology is "an operational layer for the organization" that "sits on top of the digital assets integrated into the Palantir platform (datasets, virtual tables, and models)" and contains "both the semantic elements (objects, properties, links) and kinetic elements (actions, functions, dynamic security) needed to enable use cases of all types."
Two phrases do most of the work there. Semantic elements describe your organization: the entities, their properties, and the relationships between them. Kinetic elements change it: the governed operations people and systems perform on those entities. The Ontology puts both under one security model, exposed through a single indexed and governed operational layer over the underlying data assets.
At the primitive level, you work with five building blocks:
- Object types are the schema definitions for real-world entities or events (employees, shipments, flights, incidents). An instance of an object type is a specific employee, shipment, or flight.
- Link types are schema-level relationships between two object types. A single link is one employee linked to one company.
- Action types are governed transactions that edit objects, properties, and links in one shot, including any side effects that fire on submission.
- Functions are server-side code that operates against Ontology objects within Foundry's governed execution environment. They can read properties, traverse links, and make edits, and they're typically invoked from actions or applications rather than running arbitrarily.
- Interfaces describe the shape of an object type and its capabilities, giving you polymorphism across different object types that share a common structure.
Capital-O "Ontology" always refers to Palantir's product. The lowercase concept (taxonomies of entities and relationships) has existed in philosophy and computer science for decades. Palantir's version is specific, proprietary, and tightly bound to Foundry.
Why Palantir Ontology Matters in Modern Data Systems
Most enterprise data stacks weren't designed for the workloads that now run on them. You have a warehouse, a lake, a handful of operational databases, and a mess of dashboards and ML pipelines built on top. Imagine that you have a table called shipment_events_v3 that exists, but it's unknown whether it captures what a business user calls a "shipment". This means that certain questions might not be easy to answer intuitively based solely on data and underlying schemas.
The shift toward AI agents has made that gap impossible to ignore. An LLM prompt like "which open orders are at risk of missing their SLA?" requires the system to know what an order is, which statuses count as "open", and which linked shipments, invoices, and exceptions matter. That's not a SELECT statement. It's a model of the business.
The Ontology is "designed to represent the complex, interconnected decisions of an enterprise, not simply the data." A table describes data. An object type describes something the business cares about. A link type describes a relationship that an analyst or an agent can reason about without reading DDL.
You see a similar pull in adjacent categories. Knowledge graphs, dbt Semantic Layer, Snowflake Semantic Views, Databricks metric views, GraphRAG architectures, and MCP-driven agents all chase the same goal: give machines and people a consistent, semantically meaningful representation of the world the data describes. Palantir has been doing it the longest and at the most opinionated end of the spectrum.
Two shifts are pushing this trend harder. The first is on the agent side: frameworks like LangChain, CrewAI, and Copilot Studio increasingly assume they can discover tools and entities through structured protocols, not just through free-text prompts.
The second is on the data side. Enterprise architects are seeing the cost of inconsistent semantics at scale: the same "customer" concept is defined four different ways across four dashboards, each producing a different number in a board deck. An ontology is one way to collapse that drift into a single model.
How Palantir Ontology Works
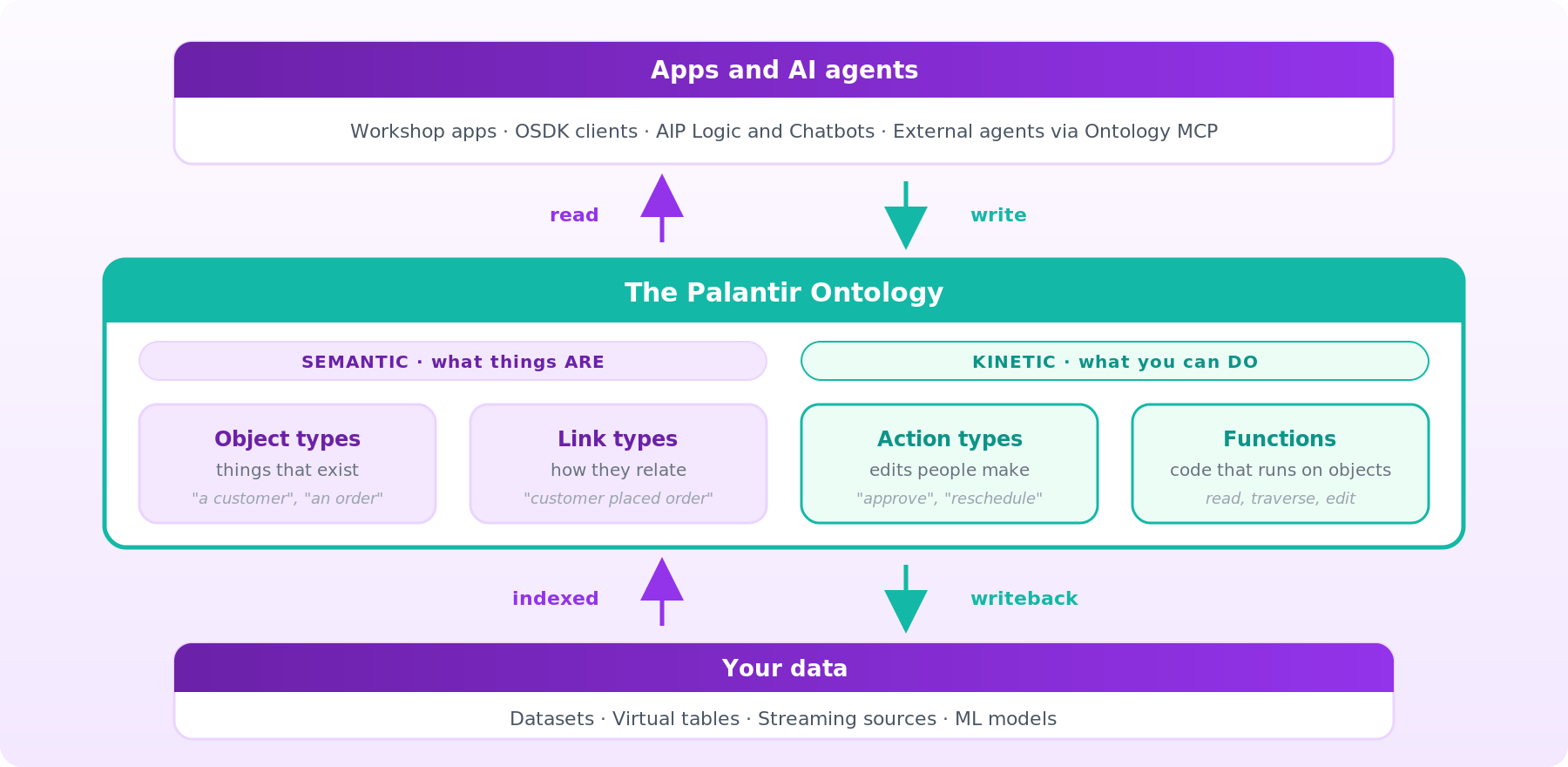
The key idea: the Ontology sits between applications and raw data as an operational control layer, holding both the model of your business and the operations that change it.
Under the hood, the Ontology is a microservices system, not a single database. Palantir describes it in the object-backend documentation as "a microservices architecture in which multiple services together comprise the Ontology backend." Five services do most of the work: OMS defines the model, Object Databases store indexed data, OSS serves reads, the Actions service applies writes, and Funnel orchestrates ingestion.
Ontology Metadata Service (OMS) defines what ontological entities exist: the object types, link types, action types, and other metadata that describe the model. OMS is the source of truth for structure.
Object databases store indexed object data optimized for fast retrieval, rather than serving as general-purpose queryable databases. This is where instances live once they've been indexed.
Object Set Service (OSS) serves reads. It's the service applications and services that they talk to when they search, filter, aggregate, or load objects.
Funnel (also called the Object Data Funnel) orchestrates writes. It reads from Foundry datasources and from user edits captured by the Actions service, then indexes everything into the object databases and keeps indexed data fresh as underlying sources change.
Two consequences matter. First, the Ontology is a heavily materialized and indexed layer, rather than a purely federated query layer. Source data is indexed into object databases, so reads stay fast and consistent, with live pipelines and Change Data Capture (described in the architecture-center docs) keeping the indexed copy in sync. Second, the storage architecture has evolved across generations, with newer designs decoupling indexing from query serving so the system can scale horizontally more easily.
Writes flow through action types. When a user or agent submits an action, the Actions service applies the edit, any side effects fire, and the change commits. In legacy Object Storage V1 workflows, edited object state lives in a writeback dataset attached to each object type. In Object Storage V2, those datasets are replaced by optional materialized datasets for downstream consumption; the edits themselves are applied through Actions and indexed into the Ontology backend, not gated by a writeback dataset. Either way, the dataset that surfaces edits to the rest of Foundry is a first-class Foundry dataset, so it participates in lineage, governance, and downstream pipelines.
Palantir groups the full system into three conceptual layers: a Language (types, actions, logic), an Engine (reads, writes, batch mutations, and Change Data Capture for low-latency mirroring), and a Toolchain (SDKs, DevOps, and UIs).
Palantir Ontology vs Traditional Data Architecture
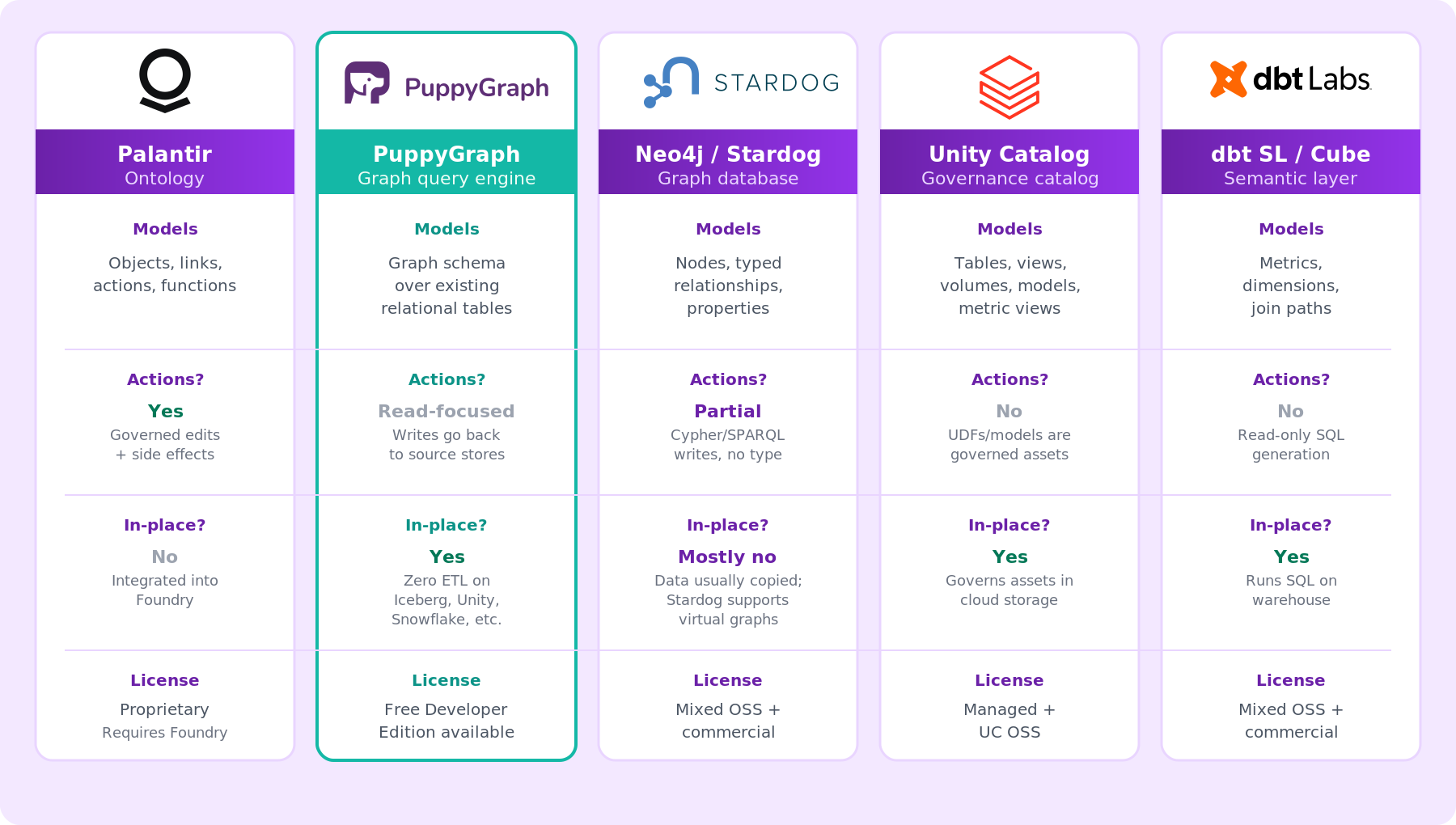
The key idea: each row of this matrix exists for a reason, but only Palantir bundles all of these concerns into one coherent platform, while the alternatives let you mix and match around your existing stack.
Most data architectures you'll encounter in the wild fall into one of four buckets. Palantir Ontology sits in a fifth category of its own. Here's how the landscape shakes out.
Traditional warehouse + BI stores tables, expresses relationships through foreign keys and joins, and pushes semantics into dashboards. No structured notion of an "object" or "action"; you have rows, columns, and reports.
Governance catalogs like Databricks Unity Catalog register tables, views, volumes, models, and functions in a three-level namespace. Unity Catalog supports primary-key and foreign-key constraints, but those constraints are currently informational and not strictly enforced by the engine in most configurations. Metric views bring metric definitions into the catalog. No action-type framework, no typed graph of entity relationships.
Semantic layers like the dbt Semantic Layer with MetricFlow, Cube, AtScale, and Snowflake Semantic Views define metrics and dimensions on top of warehouse data and generate SQL on demand. Great for consistent metric logic. They don't model writes, actions, or state changes.
Decoupled graph query engines are a newer pattern in the graph category, and they're where we spend our time. PuppyGraph is a graph query engine that natively integrates with Databricks Unity Catalog, Iceberg, Snowflake, BigQuery, and Postgres, and lets teams query the same tables through Gremlin or openCypher as a unified graph model.
In our framing, the graph schema acts as a schema-enforced model that functions similarly to an ontology layer; queries are validated against the graph schema before execution. The trade-off is different from Palantir's: no action types or workflow tier, but no proprietary data import either. For teams that want graph semantics on a lakehouse they already run, our virtual graph model is a fast way to add an ontology-style layer.
Knowledge graphs and graph databases like Neo4j, TigerGraph, Stardog, and Ontotext GraphDB model entities and relationships as a first-class property graph or RDF triple store. Stardog goes further with OWL ontologies and virtual graphs that federate to relational sources. None ship an opinionated "action type" abstraction with governed side effects or a bundled application tier, and most still involve copying or synchronizing data into the graph store, though some (such as Stardog and Ontop-based virtual knowledge graph approaches) support federation patterns.
The distinction that matters most for this comparison: Palantir bundles typed object + link + action + function primitives as a single governed surface coupled to an application layer. Few commercial platforms bundle all four in a single, tightly integrated system.
Role of Ontology in Palantir Foundry
Inside Foundry, the Ontology is the layer on which almost everything else depends. It's what OSDK compiles against, what Workshop apps read from, what AIP Logic functions write back to, and what's increasingly exposed to external agents through protocols like MCP.
The Ontology SDK (OSDK) is how code-first teams build applications on top. It supports TypeScript via npm, Python via pip or Conda, Java via Maven, and any other language through an OpenAPI spec. The generated SDK uses Ontology metadata directly, so property names and descriptions surface in your editor.
Workshop is Palantir's no-code application builder, and it reads and writes the Ontology natively. Analysts can build interactive apps on top of object types and actions without handwritten SQL.
AIP Logic is a no-code environment for LLM-powered functions that operate on Ontology objects. AIP Logic functions take inputs like Ontology objects or text and can return objects, strings, or make edits back to the Ontology. The same typed objects you define flow into prompts and back out as governed edits.
Benefits of Using Palantir Ontology
Palantir's own framing of the benefits is pitched at operational organizations, not data teams. A few claims stand out.
Shared language across the enterprise. The Ontology allows users to interact with the data using familiar, day-to-day terminology. For operational staff talking to engineers, that shared vocabulary removes a chunk of translation work.
Decision capture and compounding value. Because every action is committed through Foundry's governed write path and is indexed into the Ontology backend, user decisions become part of the data asset. Insights captured by one user feed the decisions of the next.
Economies of scale in integration work. Once data is mapped into the Ontology, new use cases are built on the same object types, link types, and actions. Application builders focus on the workflow, not on data wrangling.
Governed writes, not just reads. Action types give you a place to put validation and side-effect logic (notifications, audits, downstream system calls) that's enforced no matter which application submits the action. That's a real difference from most semantic layers, which stay read-only.
A single permissioning surface. Roles are the central permissioning model and can be granted at the Ontology level or on individual resources. Palantir has also added object security policies with property-level controls inside the Ontology.
Challenges and Limitations of Palantir Ontology
The Ontology is powerful. It's also an opinionated, proprietary product with real trade-offs.
Platform lock-in is the big one. The Ontology lives inside Palantir Foundry. You can't adopt it without adopting Foundry, and you can't easily export an Ontology model and run it elsewhere. For organizations already on Foundry, fine. For anyone evaluating open standards or mixing vendors, it's a meaningful constraint.
Data must be integrated, not just referenced. The Ontology doesn't query your operational database or lakehouse in place. Data flows in through Foundry pipelines, gets indexed into object databases via Funnel, and lives as objects in the Ontology backend. That adds an integration step and a freshness consideration.
No cross-Ontology links. Links between entities across different ontologies are not supported. For teams with a federated model across business units, that matters.
Operational coupling to Foundry pipelines. Because object types, link types, and actions all map back to Foundry datasets and pipelines, changes upstream can cascade into Ontology behavior. That creates tight coupling between data engineering and application layers, and pipeline migrations need to be coordinated with Ontology owners.
Learning curve. Object types, link types, action types, functions, interfaces, roles, Ontology Manager, Workshop, OSDK, AIP Logic, AIP Chatbot Studio, Quiver, Vertex, Object Views, Ontology MCP. The vocabulary is extensive, and teams typically invest in training or rely on Palantir's own field engineers.
How to Build an Ontology in Palantir
Palantir's UI for modeling is Ontology Manager. The workflow most teams follow looks like this:
- Ingest data into Foundry. Connect sources, build pipelines, and register datasets, virtual tables, or models as the foundation for your object types.
- Create object types. In Ontology Manager, define primary keys, properties, and display configurations for each real-world entity or event you want to model.
- Declare link types. Define typed relationships between pairs of object types (employee-to-company, order-to-shipment, incident-to-asset).
- Configure action types. Specify the edits a user or system can make, the validation logic that gates them, and any side effects that fire on submission.
- Author functions. Write server-side logic against the Ontology in TypeScript, Python, or other supported languages. Functions can read objects, traverse links, and make edits. They're what you embed in actions, Workshop apps, and AIP Logic flows.
- Add interfaces where polymorphism helps. Use interfaces to share common shape and capabilities across related object types.
- Apply security. Configure roles and, for sensitive properties, object security policies with property-level visibility controls.
Once the model exists, consumers pick up: Workshop builds apps, OSDK generates typed client libraries, AIP Logic wraps LLM functions around objects, and Ontology MCP exposes selected resources to external agent frameworks. Live ML inference is wired in by publishing a wrapper function around a Foundry model deployment and invoking it from Workshop, Vertex, or other applications.
For teams taking a code-first approach, OSDK generation is usually the fastest path. Object types and action types defined in Ontology Manager become typed classes and method signatures in your IDE.
Conclusion
Palantir Ontology is best understood as an operational layer, not a database or a semantic view. It bundles schema (object types, link types, interfaces), behavior (action types, functions), and governance (roles, property-level policies) into a single coherent system, and then provides SDKs, low-code builders, and MCP endpoints on top. That integrated surface is what most catalogs, semantic layers, and graph databases don't offer in a single package. It's also what produces the trade-offs: you get the power of a unified model, but you adopt the platform to get it.
If your organization is already on Foundry, the Ontology is the layer everything else should build on. If you're not, the question becomes which parts of the Ontology model you actually need, and whether open-standards or decoupled approaches give you enough of it. Graph query engines like PuppyGraph provide a schema-enforced graph model that functions as an ontology layer directly over the tables in your lakehouse or warehouse, with no data movement required. Graph-native databases like Neo4j and Stardog cover entities and relationships, typically by copying data into the graph store (though some support virtual-graph federation patterns). Semantic layers like dbt's and Snowflake's cover metrics but not typed objects or writes.
We built PuppyGraph for exactly this gap: teams that want the semantic power of an ontology without importing their data into a proprietary platform. If you want to see how a graph-based ontology layer works on data you already have, spin up our free Developer Edition in Docker or book a demo, and we'll walk through a real schema on your own tables.

Matt is a developer at heart with a passion for data, software architecture, and writing technical content. In the past, Matt worked at some of the largest finance and insurance companies in Canada before pivoting to working for fast-growing startups.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install